Blended Diffusion for Text-driven Editing of Natural Images 논문 리뷰
[CVPR 2022] Blended Diffusion for Text-driven Editing of Natural Images

입력값으로 ‘이미지 + Mask + Text prompt’를 추가하면 Mask 부분만 text prompt에 맞게 자연스럽게 inpainting 해주는 모델입니다. 기존 Inpainting 모델과 어떤 점이 다른지, 왜 제목은 blended diffusion 인지 자세히 알아보도록 하겠습니다.
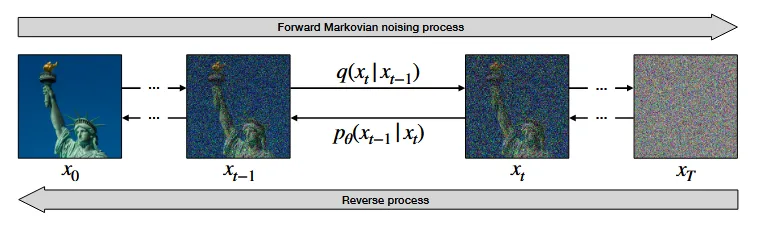
해당 글을 읽기전에 Denoising Diffusion Probabilistic Model(DDPM) 모델에 대해서 알고 있어야합니다. DDPM은 원본 이미지 에서 노이즈를 추가하는 Froward Process를 거쳐 로, Reverse Process를 거쳐 다시 를 예측하는 과정입니다.
DDPM 간단한 논문 리뷰: https://velog.io/@guts4/Basic-Generative-Model-DDPMhttps://velog.io/@guts4/Basic-Generative-Model-DDPM
Method
Notation
x: image / d: text prompt / m: binary mask / $\hat{x}$: modified image
우리의 목표는 마스크 부분만 text prompt에 맞고, 마스크를 제외한 부분은 기존 이미지와 동일하게 유지 되는 것을 원합니다. 그리고 마스크에 생성된 이미지는 seamless(경계 부분이 두드러지지 않은) 한 결과를 원합니다.
Local CLIP-guided diffusion
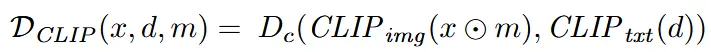
Guidance를 활용해서 mask 부분에 대한 인페인팅 결과의 이미지 임베딩 $CLIP_{img}(x⊙m)$와 text prompt의 텍스트 임베딩 $CLIP_{txt}(d)$의 코사인 유사도를 기반으로 local editting을 진행합니다.
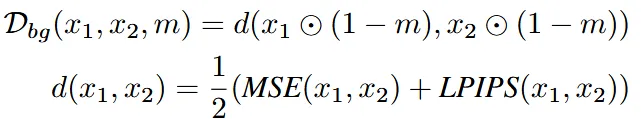
위의 과정은 mask 부분에 대해서 text prompt에 맞게 생성하는 부분만 존재하기 때문에, mask를 제외한 부분은 원본 이미지()과 일치하도록 하는 부분도 추가합니다. 해당 부분은 MSE, LPIPS loss를 사용해서 최대한 픽셀 값이 일치하도록 설정합니다.
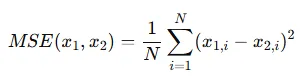
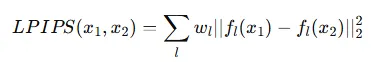
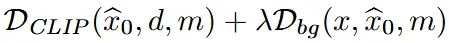
최종적으로 mask 부분을 수정하는 과 mask를 제외한 부분을 보존하는 를 통해서 loss 값이 구성 됩니다.

알고리즘은 위와 같습니다. 는 classifier guidance를 통해서 수정된 이미지이고, 이후 Augmentation(이후 설명 예정)을 진행한 후 이전에 설명한 loss term을 진행합니다.

이와 같이 Inpainting을 진행할 경우 생기는 문제점은 위와 같습니다. λ가 작을수록 mask부분에 대한 inpainting 결과는 text prompt(a dog)에 대해서 좋은 결과를 생성하지만 원본 이미지가 망가지고, λ가 클수록 원본 이미지는 잘 보존 되지만 text prompt의 결과는 반영되지 않습니다.
Text-driven blended diffusion
Background preserving blending
마스크 부분만 text prompt에 맞게 수정하면 배경은 수정되지 않을 것으로 기대했지만, 실제로 많은 부분이 바뀌는 것을 결과를 통해 확인할 수 있었습니다.
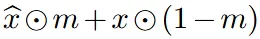
그러면 마스크부분을 text prompt에 맞게 수정한 이미지를 마스크에 대해서 위의 수식처럼 해당 부분만 crop해서 사용하고, 나머지 부분은 원본을 사용하면 되지 않을까? 하지만 이렇게 사용할 경우 경계 부분에 대해서 seamless 한 결과가 나옵니다.
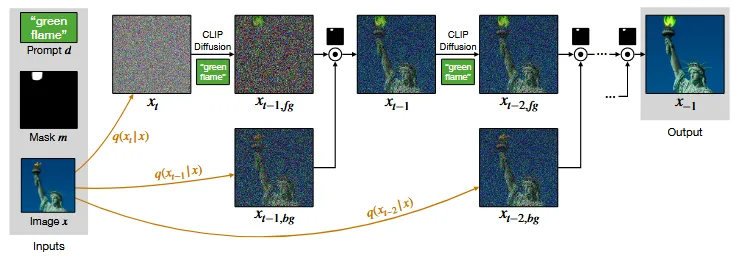
이를 극복하기 위해서 1987년 논문 Laplacian pyramid을 참조해서 2개의 서로 다른 노이즈 레벨의 diffusion process를 섞으려고 합니다.
위의 그림처럼 이전에 설명한 CLIP Diffusion을 사용해서 마스크 부분에 대한 inpainting을 진행해서 노이즈를 제거한 와 원본 이미지에서 t-1 시점의 노이즈 만큼 추가된 를 생성합니다.
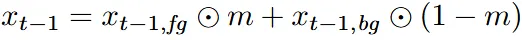
그리고 위의 수식처럼 foreground 부분은 mask와 픽셀 곱을, background 부분은 mask를 제외한 부분과 픽셀곱을 취해서 t-1시점의 이미지를 얻습니다.

Blended diffusion의 알고리즘은 위와 같습니다. 복잡한거 전혀 없이 foreground 부분은 text prompt에 맞게 수정하고, mask를 제외한 부분은 노이즈를 추가하고 1 step 제거하는 과정만 진행해서 2개를 더해줍니다.
Extending Augmentation
현재 를 예측하는 과정이 Classifier guidance를 기반으로 설계 되었기 때문에, Classifier guidance의 문제점인 Adversarial example 현상이 나타납니다. 이는 특정 class로 분류하기 위해서 diversity가 줄어 드는 현상입니다.
위의 현상을 극복하기 위해서 denoising 과정의 중간 단계에서 Augmentation을 진행했습니다.

(1)번 결과가 Augmentation을 진행하지 않은 기법, (2)가 Augmentation을 진행한 결과입니다.
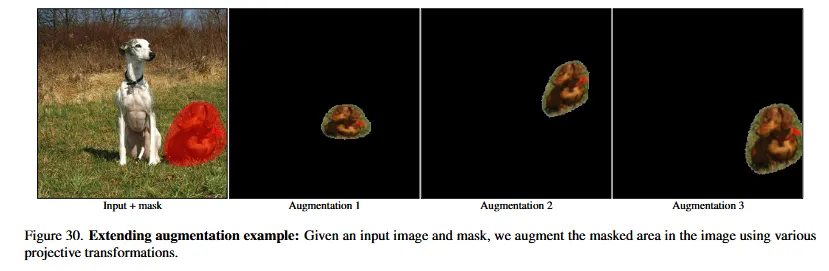
참고로 Augmentation은 마스크와 마스크에 해당하는 이미지 부분 둘다 동시에 적용됩니다.
Result

당연히 기존 모델들보다 성능이 더 잘 나옵니다.
Limitation
- Inference time: DDPM을 기반으로 설계 돼서 한 이미지당 30초가 걸립니다.
- 설명은 안했지만 DDPM은 동일한 입력과 seed라도 서로 다른 결과를 도출합니다. 따라서 여러번의 결과중 가장 좋은 결과를 사용하는 Result ranking 방식을 사용했는데, 이러면 당연히 더 많은 시간이 소요될 것 입니다.
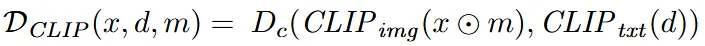
- 또한 result ranking의 랭킹을 결정하는 요소의 부적절함을 지적했습니다. 위의 수식을 통해서 랭킹을 매기는데, 마스크 부분만 고려하기 때문에 배경에 대해서 평가하지 못합니다.

3번 limitation의 그림인데, text prompt로 rubber toy를 넣었을 때 위와 같은 3가지 문제점이 발생할 수 있습니다. (Text prompt: Rubber toy)
- Partial Object: Rubber toy의 일부만 생성 되어서 부적절하지만, CLIP score는 높아서 높은 랭킹을 차지 합니다.
- Typographic Bias: rubber toy의 텍스트에 편향돼서 텍스트가 들어갔지만 높은 랭킹을 차지 합니다.
- Missing & Unnatural shadows: 물체가 존재하지 않거나, 그림자만 있어도 rubber toy로 인식되는 경우가 있는데 이는 부적절한 결과임에도 높은 랭킹을 차지 합니다.
Appendix
DDIM

위와 같은 알고리즘으로 DDIM을 진행할 수 있지만

(Text prompt: a shiny ball, a rock, green hills) 100 step기준으로 비교할 때 DDPM의 성능이 더 좋기 때문에, 굳이 DDIM을 쓸 이유가 없었습니다.
