[SIGGRAPH 2023] Blended Latent Diffusion
Blended Diffusion 논문 리뷰: https://velog.io/@guts4/Blended-Diffusion-for-Text-driven-Editing-of-Natural-Images-%EB%85%BC%EB%AC%B8-%EB%A6%AC
기존의 Blended Diffusion 모델은 mask 영역만 denoising을 하는게 아니라 원본 이미지에도 노이즈를 추가해서 함께 denoising을 함으로서 seamless한 자연스러운 Inpainting 결과를 생성했습니다.
하지만 느린 reference time, 동일한 seed에도 서로 다른 결과, result ranking의 부적절성 이라는 한계점이 존재했고, 이를 극복하기 위해서 Blended latent Diffusion 모델이 나왔습니다.
Method
Blended Latent Diffusion
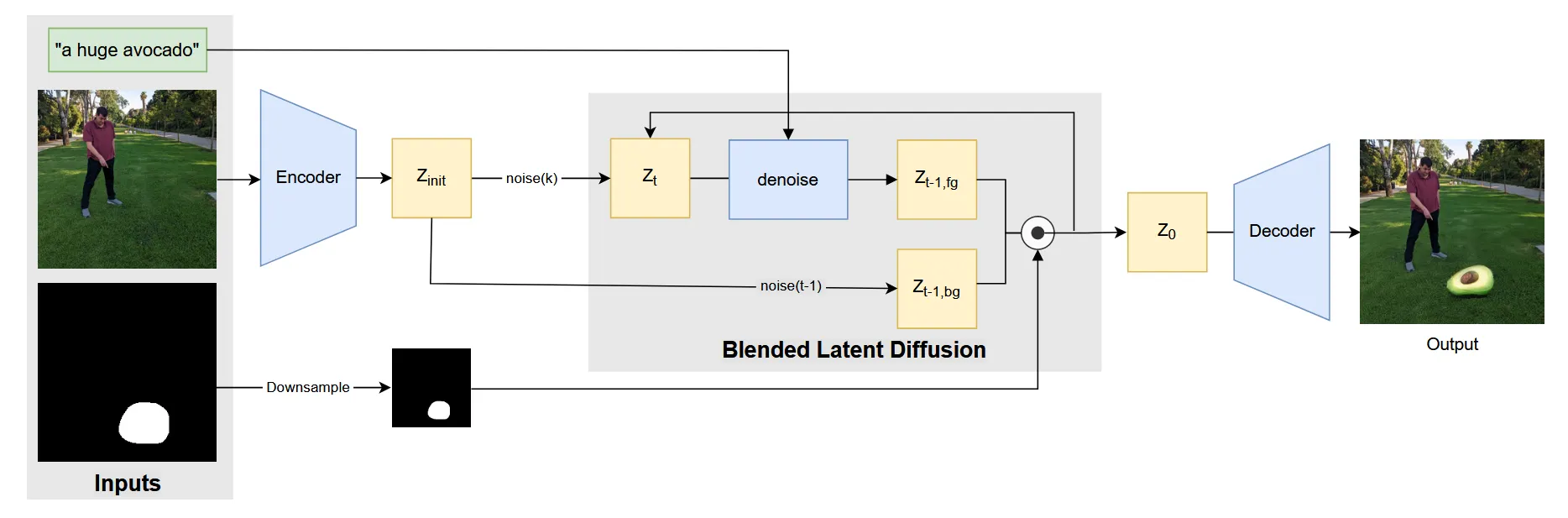
핵심 차이점은 latent space로 보내서 denoising을 진행하도록 바꾼 점입니다. Encoder를 통해서 이미지 임베딩 z를 생성하고, mask의 크기도 이에 맞게 downsampling 합니다. 이후에 blended diffusion 처럼 foreground 부분에 대해서는 text prompt와 함께 1 step denoise, background에 대해서도 해당 시점의 노이즈를 추가해서 2개를 합친 결과가 다음 step의 결과가 됩니다. 최종적으로 Decoder를 통해서 inpainting된 결과를 얻습니다.
알고리즘

장점
Faster inference : 차원이 낮으니까 시간도 더 적게 걸릴 것이고, LDM 모델 자체에 text condition 부분이 존재하기 때문에 CLIP-loss gradients를 계산하지 않아서 시간이 한번 더 단축 됩니다.
Avoiding pixel-level artifacts

위의 사진과 같이 픽셀 기반 blended diffusion(c)는 artifacts가 발생하지만, blended latent diffusion은 픽셀기반이 아닌 decoder로 나중에 이미지를 생성하기 때문에 이러한 현상이 사라진 것을 확인할 수 있습니다.
Avoiding adversarial examples
동일한 그림이라도 하나의 픽셀만 바꿔서 class의 분류가 달라지는 adversarial example 문제가 blended diffusion에서는 존재했습니다. 하지만 픽셀 기반의 학습이 아니라 latent space에서 학습을 하는 blended latent diffusion 모델은 이러한 문제가 발생하지 않습니다.
Better precision : 더 좋은 결과!
단점

Imperfect reconstruction : 저차원으로 보내기 위해서 VAE의 Encoder와 Decoder를 사용했는데, 이 과정에서 background 이미지가 정확하게 재현 되려면 VAE의 성능이 중요합니다. 따라서 원본 이미지를 사용한 기존 blended diffusion에 비해서 성능이 떨어질 수 있습니다. 위의 사진을 보면 VAE를 통해서 원본 이미지를 복원한 결과(a)가 좋지 않아서, 최종적인 결과(b)에서 원본 이미지의 성능이 좋지 않은 결과가 나타납니다.
Thin masks : 얇은 mask의 경우 downsampling을 하면 더 얇아지므로 거의 소멸되는 결과가 나타날 수 있습니다.
Background Reconstruction
방금 설명한 한계점 중 Imperfect reconstruction 부분을 해결하려면 어떻게 해야할까요?
원본 이미지 픽셀 사용

단순히 background 부분을 원본 이미지로 사용하면 될거 같지만, 이전 blended diffusion에서도 언급한 것처럼 seamless한 현상이 발생할 것 입니다. 심지어 latent diffusion model을 통해서 생성된 forground와 원본 이미지를 붙인다면 위의 사진처럼 더 부자연스러울 것 입니다.
Poisson blending 방식 사용

이를 해결하기 위해서 이미지 경계를 자연스럽게 합성하는 Possion blending이라는 방식을 사용했지만, 여전히 원본 색감을 유지하지 못 한다는 한계점이 존재합니다.
Latent optimization 방식 사용
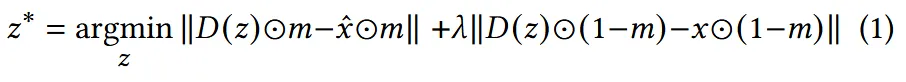
GAN inversion literature에서 사용되는 방식으로, latent space의 원본 이미지를 복구할 때 위의 수식처럼 MSE loss를 이용해서 원본 이미지와 최대한 유사하게 학습하는 방식을 추가하는 방식이 latent optimization 입니다.

위의 결과처럼 latent optimization은 원본을 잘 복구하긴 했지만, 이빨이 완전히 매끈해지는 over-smoothing 현상이 발생합니다.
Weights optimization 방식 사용
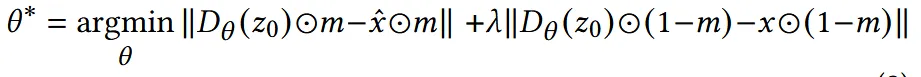
Over-smoothing 현상을 방지하기 위해 기존 연구에서 Decoder의 가중치 부분을 특정 이미지에 맞게 fine-tuning을 진행하는 연구들이 있었고, 해당 방식을 사용해서 원본 이미지를 생성하도록 진행했습니다.

이렇게 되면 원본이미지의 고주파 영역까지 잘 예측하고, over-smoothing 현상이 감소합니다.

결과적으로 mask를 제외한 영역은 원본 이미지와 최대한 유사한 방식으로 보존할 수 있게 됐습니다. 위의 사진을 확대하면 기존에 intial prediction 방식을 사용하면 사람의 얼굴이 바뀌는 등 주변 환경이 변했지만, weight optimization을 진행한 After reconstruction의 결과 사람의 얼굴이 보존되는 것을 확인할 수 있습니다.
Progressive Mask Shrinking
이전에 언급된 2번째 단점으로 얇은 mask의 예측이 어렵다는 점입니다.

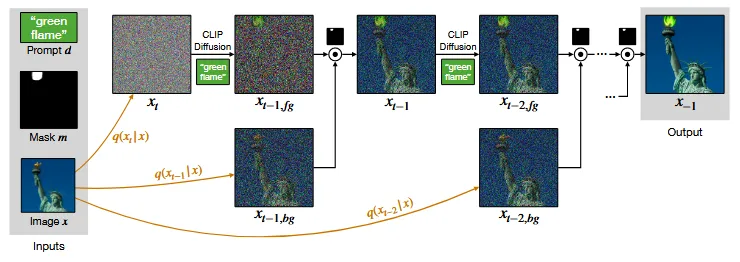
맨위의 그림이 기존 방식인데, 작은 마스크를 사용했을 때도 초기에는 ‘fire’라는 text prompt를 입력했을 때 불을 잘 생성했습니다. 하지만 원본이미지와 blending 될수록 작은 마스크들은 inpainting을 잘 하지 못했습니다.
이를 극복하기 위해서 progressive mask shrinking 방식을 사용합니다. 아래에 보이는 것처럼 초기에는 큰 마스크를 사용하고, 점점 크기를 줄여가면서 마지막에 원래의 mask 크기를 사용하는 방식입니다.

하지만 정말 디테일한 (예: 초록 팔찌) 요소들은 잘 생성을 하지 못하는 것을 위의 그림을 통해서 확인할 수 있습니다.
Prediction Ranking
이 부분은 기존과 동일하게 CLIP embedding의 코사인 거리를 통해서 Top-k 개를 선택하는 방식을 사용했습니다.
Result

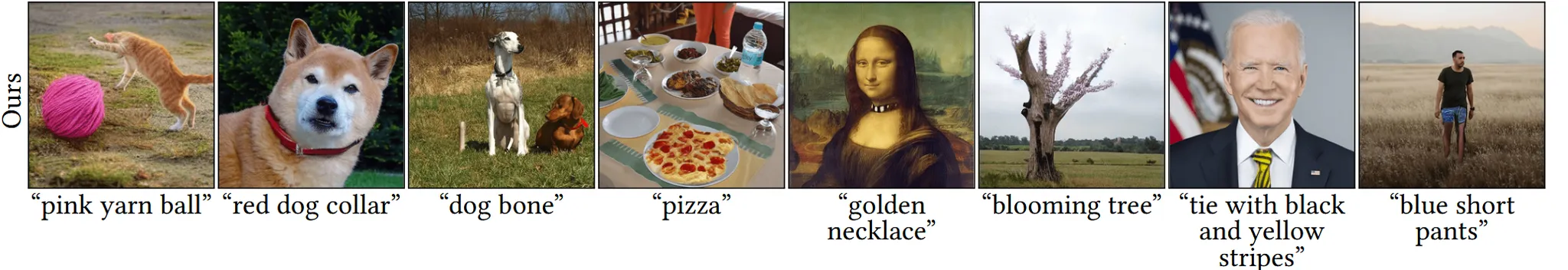
사실 사진 결과만 보면 blended latent diffusion이 더 좋다라고 명확하게 말할 수는 없지만, 어쨌든 시간 단축이라는 단점은 해결했기 때문에 더 좋아진 모델이라고 말할 수 있습니다.
Limitations
시간을 단축했지만.. 여전히 A10 GPU에서 1분 이상 소모됩니다.

또한 이전에 발생한 top-ranking에서 발생한 문제가 위의 그림처럼 동일하게 나타납니다.
