PointInverter: Point Cloud Reconstruction and Editing via a Generative Model with Shape Priors[2023 WACV]
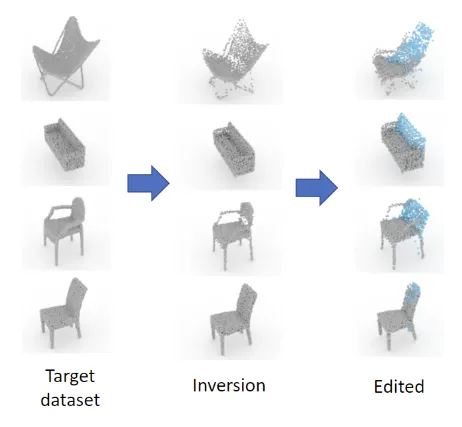
3D GAN이 새로운 모델을 생성하는 것은 잘하지만, 기존 데이터들을 gan의 latent space로 보내는 과정은 잘 못하기 때문에 수정하는 것은 못합니다. 어떻게 3D point ccloud를 latent space로 잘 보내서 기존에 하지 못한 수정 과정을 진행했는지 자세히 살펴보도록 하겠습니다.
Related Work
GAN Inversion
GAN Inversion은 이미지를 생성한 GAN의 잠재공간으로, 다시 기존 데이터를 되돌려 넣는 과정입니다. 이미지를 latent space로 보내게 되면 stylegan같은 모델로 latent를 수정해서 내가 원하는 스타일을 입힐 수 있기 때문에 원본 데이터를 latent space로 종종 보냅니다. Inversion 방식은 크게 optimized 방식과 learning 방식이 있습니다.
Optimization 방식은 각각의 이미지에 대해서 projection function을 학습해서 최적의 결과를 도출합니다. 해당 과정으로 도출된 latent의 성능은 좋지만, 시간이 오래걸린다는 단점이 존재합니다.
Learning 방식은 미리 encoder를 학습해서 빠르게 latent를 도출할 수 있지만, 성능이 안좋다는 단점이 존재합니다.
3D Domain
Point Cloud에 대해서 GAN Inversion한 논문은 많지 않지만, tree-GAN을 이용해서 GAN inversion을 진행한 하나의 논문이 존재합니다. 해당 논문은 reconstruction 하는 퀄리티만을 중요하게 여겼지만 해당 논문에서는 point cloud의 order(순서)도 고려하도록 설계 했습니다. SP-GAN을 통해서 order까지 고려한 point cloud inversion을 통해서 reconstruction의 성능도 개선하고 editing도 가능하도록 설계 했습니다.
Background

SP-GAN은 sphere(구)로부터 원하는 형태의 point Clouds(P)를 생성하는 것을 목표로 합니다.
Generator G는 sphere → point cloud를 생성하는 과정을 진행하고, Discriminator D는 G가 생성한 point cloud와 학습하는 진짜 데이터에 대해서 real과 fake를 구분하는 과정을 진행합니다.
학습과정은 N개의 point cloud를 갖고 있는 sphere S()에 대해서 각 점에 random gaussian noise 를 추가한 prior latent code 를 생성합니다.
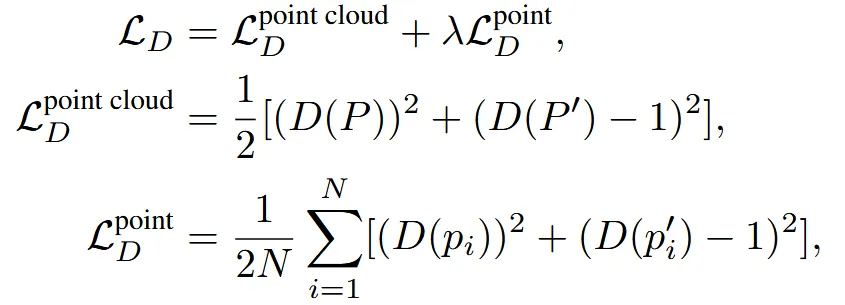
Discriminator는 2가지 loss로 이루어졌습니다. 전체 point cloud의 진위 여부를 나타내는 와 각각의 point에 대한 진위 여부를 판단하는 입니다.
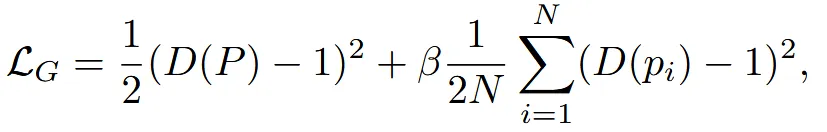
Generator는 위와 같이 discrimator를 속이기 위해서 학습됩니다.
SP-GAN은 point clouds를 생성할 수 있을 뿐만 아니라, 구와 생성된 point cloud 각각의 점들에 대한 대응 관계도 학습할 수 있습니다.
Our Method
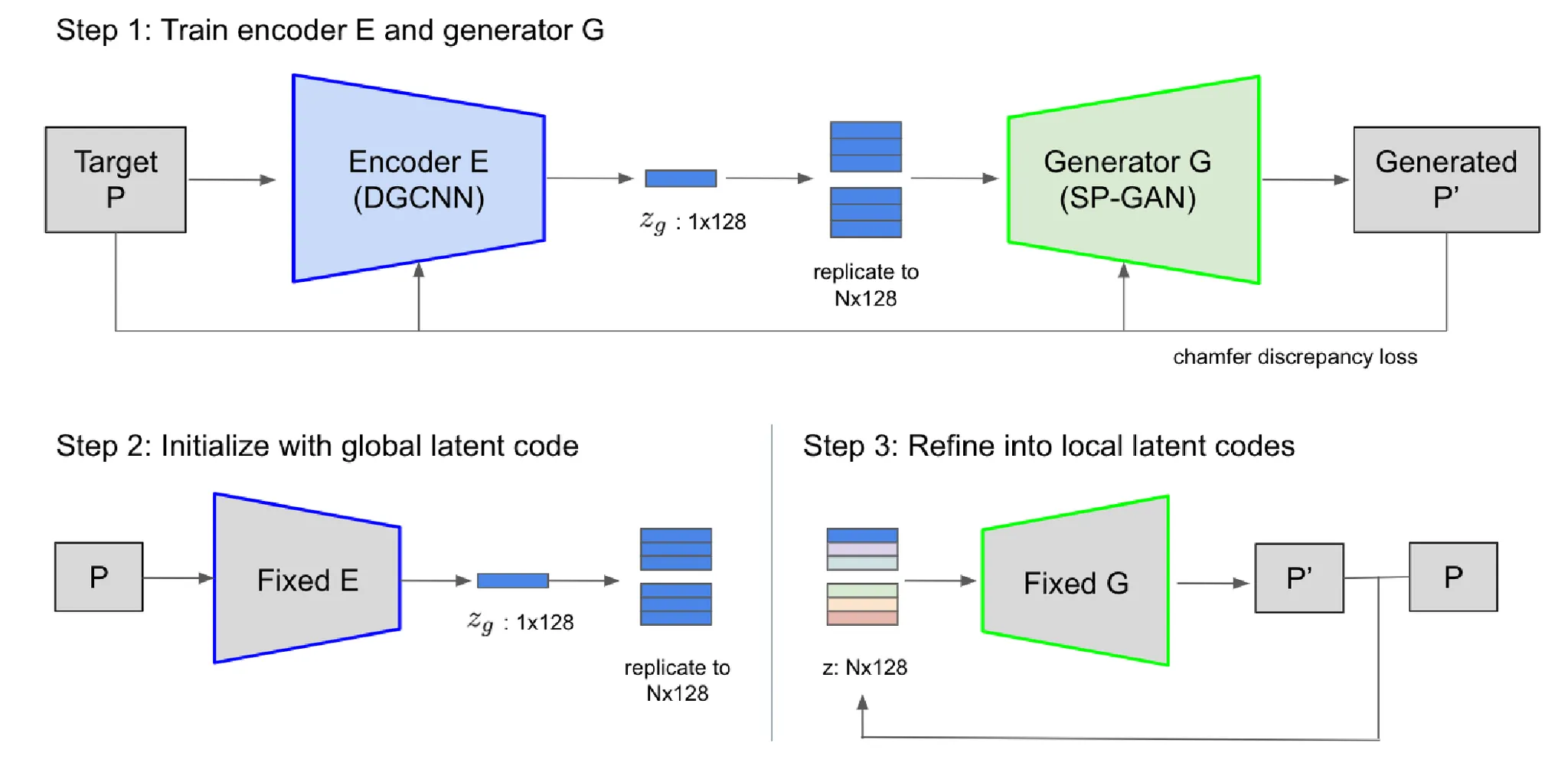
해당 논문의 목표는 입력 point cloud를 SP-GAN을 통해서 각 점에 대응하는 관계까지 알 수 있는 latent space로 보내는 과정을 학습하는 것입니다. 모델은 point cloud를 latent space로 보내는 Encoder와, SP-GAN의 Generator로 구성됐습니다.
모델은 3단계로 구성됩니다. 첫번째로 Encoder와 Generator를 학습하고, 두번째로 point cloud의 ordering을 학습, 마지막으로 latent를 refine하는 과정으로 진행됩니다.
Step 1: Global latent code
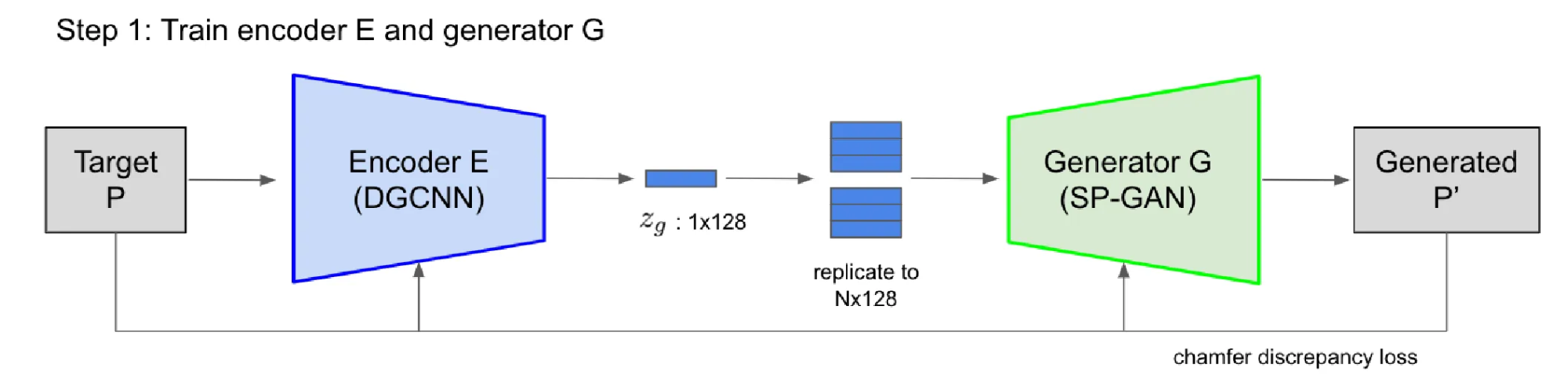
해당 단계에서는 입력 point cloud를 encoder를 통해서 global latent space로 보내고, 이를 다시 generator로 복원하는 과정에서 사용되는 encoder와 gnenerator를 학습하는 것입니다.
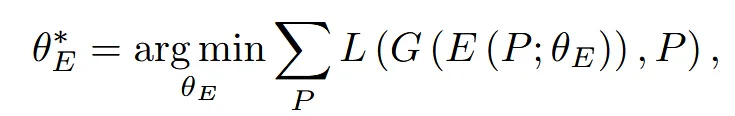
Gnerator는 SP-GAN 모델을 사용하고 고정시킨채 처음에는 Encoder를 위와 같은 식으로 학습합니다. 즉 입력 point cloud를 encoder → generator를 거친 후에 생성된 결과와 초기 point cloud의 차이를 줄이는 것입니다.
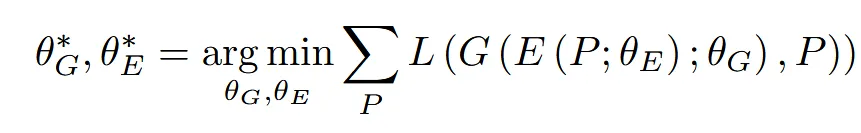
이후에 Generator모델도 학습시키기 위해서 위에 식에서 Generator의 파라미터만 학습하도록 수정합니다.
Encoder architecture
Image domain에서 GAN inversion을 수행할 때, Encoder로서 Discriminator의 마지막 feature layer를 활용하는 경우가 종종 있습니다. 하지만 Discriminator는 진위 여부를 판별하는 목적으로 학습되기 때문에, 생성에 필요한 입력의 전체적인 표현력이 부족할 수 있습니다.
반면, 사전학습된 DGCNN은 point cloud의 지역적 구조와 전체 모양 정보를 모두 잘 포착하도록 설계되어 있습니다. 실제로 DGCNN의 출력 feature를 pooling하여 사용했을 때, 보다 우수한 성능을 얻을 수 있음을 저자들은 실험을 통해 확인했습니다.
Loss functions
Point cloud의 geometry와 density가 보존될 수 있도록 Chamfer discrepency(CD)를 loss로 선택했습니다.
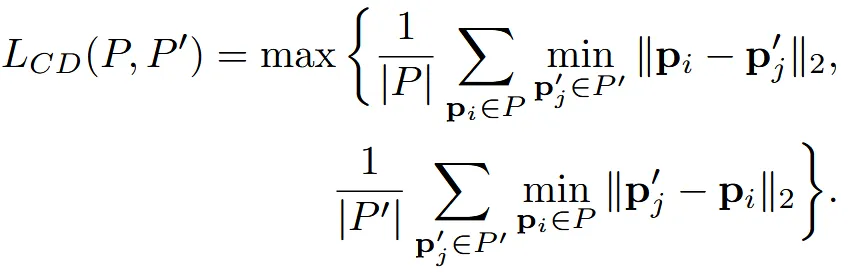
위의 식에서 P는 입력 point cloud, P’는 생성된 point cloud입니다.
Step 2: Point ordering
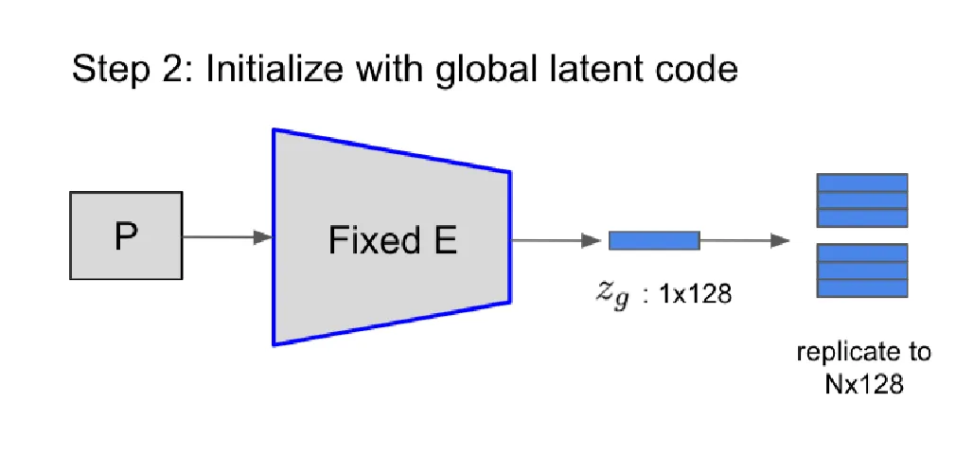
Step1에서 생성한 global latent code만으로는 detail한 부분들을 수정하는데 제한이 있습니다. Local latent code를 생성하는 간단한 방식은 encoder가 각각의 point cloud에 대해서 학습하는 것입니다 하지만 해당 방법은 ponit cloud의 순서가 바뀌면 소용이 없고, overfitting의 위험성이 존재합니다.
따라서 Step1에서 생성된 global latent code 를 point cloud 개수 N개만큼 복제한 후 이를 local latent code의 초기값으로 설정한 후 step3에서 이를 optimizae합니다.
Step 3: Local latent codes
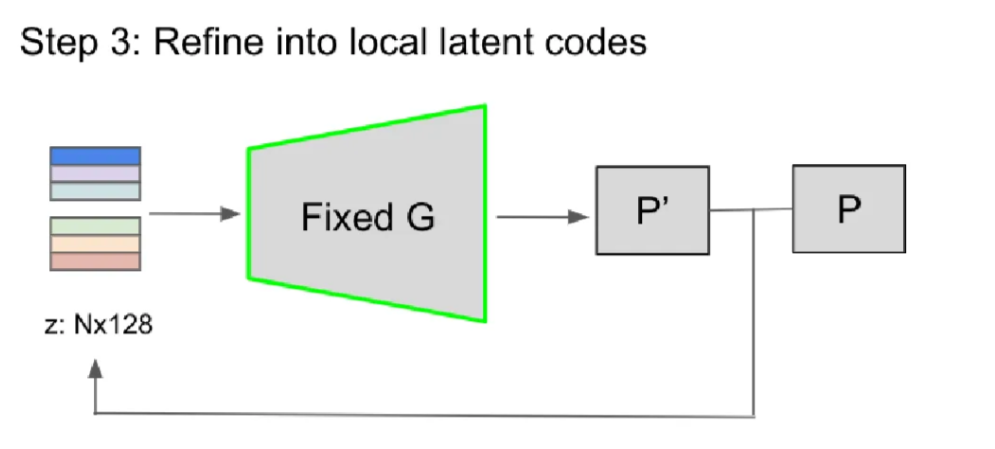
Step2에서 복제한 global latent code에 대해서 generator G를 고정시킨 후 latent를 수정하면서 원본 point cloud와 유사하게 학습합니다.
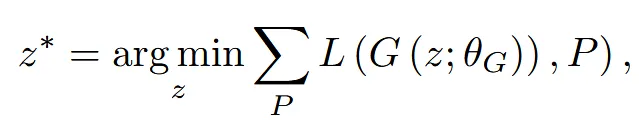
수식은 위와 같습니다.
Experiments

수정하고 싶은 부분을 segment 한 뒤, 해당 영역에 속하는 local latent code에 노이즈의 수치를 조절합니다. 변경된 latent code를 generator에 통과하면 변경된 결과가 나옵니다.
