CLIP-Mesh: Generating textured meshes from text using pretrained image-text models 논문 리뷰
논문링크
Summary

해당 논문의 큰틀은 Text-to-3D로 Text 프롬프트를 입력하면 이에 해당하는 3D asset을 생성하는 연구입니다. 하지만 배경을 고정하거나, Texture map, normal map, vertices 중 일부를 고정하고도 진행할 수 있기때문에 Object-3D-editing 분야라고도 할 수 있습니다.
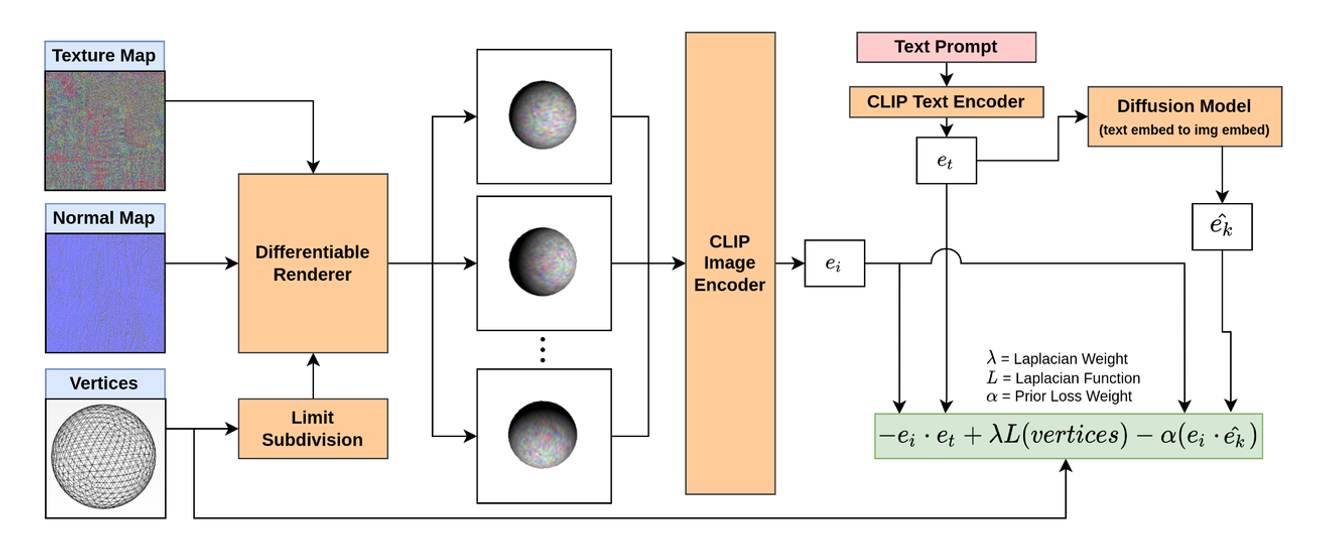
모델 학습 과정
- Vertices는 Loop Subdivision를 통해서 Mesh를 생성합니다.
- Vertices + Normal Map + Texture Map을 통해서 생성된 3D object를 미분가능하게 Rendering합니다.
- 렌더링된 이미지를 CLIP의 이미지 인코더를 통해서 를 얻습니다
- Text Prompt 역시 CLIP의 텍스트 인코더를 통해서 를 얻습니다.
- 를 입력으로 받은 Diffusion Model을 통해서 를 얻습니다.
- 와 의 코사인 유사도 계산, 와 의 코사인 유사도 계산, 그리고 Laplacian Regularizer을 통해서 학습이 진행됩니다.
Conclusion
해당 논문에서 개인적으로 Contribution이라고 생각했던 부분은 아래와 같습니다.
- CLIP의 텍스트 임베딩값을 Diffusion 모델의 입력으로 넣고 출력값을 CLIP의 이미지 임베딩값과 코사인 유사도를 계산한 방법
- render augmentations과 text에서 image로의 임베딩 prior 모델을 사용해서 성능을 개선한 점입니다. 특히 물체의 위치를 중앙에 두지 않는 Reposition Shape의 경우 성능을 10%나 증가시키는 중요 요소로 작용합니다.
Abstract
해당 논문은 zero-shot generation 3D model 입니다. texture map과 normal map의 변형을 통해서 3D asset을 얻습니다. 기존까지 연구들이 Stlye을 바꾸는 곳에 치중되었다면 이 연구는 texture와 shape을 생성하는 mesh 파라미터를 직접 optimization 합니다.
Introduction
게임, 가상현실, 영화같은 분야에서 3D model은 중요한 역할을 합니다. 현재 대부분의 3D asset들은 polygonal mesh, point clouds, voxel grids or implicit functions를 이용해서 구현합니다. 하지만 이 방식들은 software에서 사용할 때 mesh로 변환해야합니다. 이때 추가적인 computation cost와 좋지 않은 변환들이 발생할 수 있습니다.
이상적인 방법은 입력한 Text를 기반으로 3D asset을 생성하는 것입니다. 하지만 데이터셋이 부족한 것이 이 부분의 한계입니다. Shapenet과 CO3D 데이터셋이 존재하지만 50개의 카테고리밖에 없습니다. Imagenet-21k가 21000개의 카테고리가 존재하는 것에 비해 턱없이 부족한 수 입니다.
최근 4억개의 이미티-텍스트 페어로 학습된 CLIP 모델이 발표 됐습니다. 따라서 해당 모델을 3D 이미지를 Projection시켜서 사용할 것입니다. 하지만 이 방식을 그냥 사용하게 된다면 불충분한 제약으로 인해서 tangled(얽힌) and noisy mesh가 생성될 것 입니다.
이에 첫번째로 regularization loss와 mesh를 부드럽게 하기 위한 limit subdivision을 사용할 것입니다.
다음으로 여러 Rendering Augmentation을 사용하여 Optimization 과정이 Shape 정보를 충분히 활용할 수 있도록 합니다.
마지막으로, Text 프롬프트에 따라 CLIP 이미지 임베딩을 생성하는 사전 학습된 Diffusion prior 모델을 도입하여 결과를 더욱 개선합니다.
논문의 Contribution은 다음과 같습니다.
- 미분가능한 Rendering 방식을 사용해서 zero-shot text guided generation을 만들었습니다.
- Texture map과 Normal map을 이용해서 직접 mesh를 생성했습니다.
- Loop subdivision의 한계를 implicit regularizer를 사용해서 극복했습니다.
- render augmentations과 text에서 image로의 임베딩 prior 모델을 사용해서 성능을 개선했습니다.
RELATED WORK
Text 기반 2D 이미지 생성 및 변형
- CLIP 모델 활용: StyleCLIP, VQGAN-CLIP, GLIDE와 같은 연구들은 사전 학습된 이미지 생성 모델을 Text 프롬프트를 통해 원하는 결과로 조정하는 데 성공했습니다.
Text to 3D
- 아직 많이 발전되지 않은 분야입니다.
- GAN을 이용해서 시도한 연구가 있었지만, zero-shot학습이 아니고 충분한 양의 3D 모델과 Text 설명이 매칭된 데이터셋이 부족하기 때문에 한계가 있습니다.
- CLIP-Forge: Text와 3D 모델이 짝지어진 데이터셋을 요구하지 않고, 3D 모델만을 사용하여 인코더와 디코더를 훈련합니다. 이후 CLIP을 사용해 디코더의 생성을 안내합니다. 하지만 이역시 데이터셋의 부족과 meshes나 textures를 생성하지 못하는 한계가 있습니다.
- Text2Mesh:기존 Mesh의 각 Vertex를 최소한으로 수정해 색상과 모양을 변화시키는 문제를 다룹니다.
- Dreamfields: NeRF model을 이용해서 zero-shot text guided generation을 제안했습니다. 이 모델은 우리 모델과 다르게 직접적으로 mesh를 생성하지 않습니다. 또한 threshold값을 사용자가 설정하는데 이 값은 trade off를 야기합니다.
Method
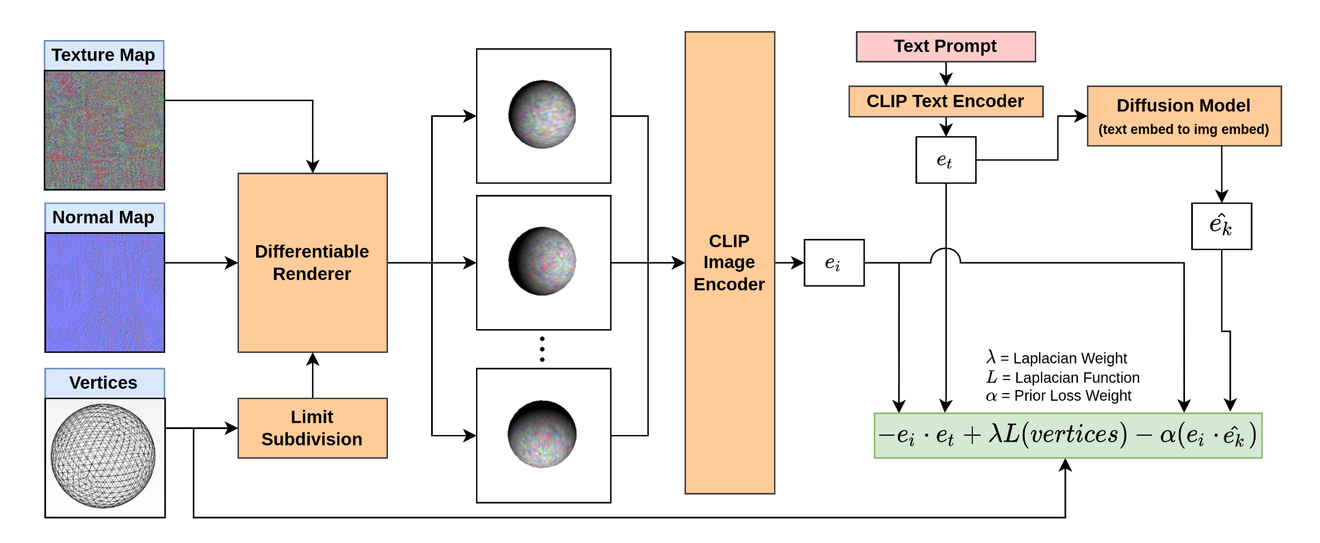
모델 학습 과정
- Vertices는 Loop Subdivision를 통해서 Mesh를 생성합니다.
- Vertices + Normal Map + Texture Map을 통해서 생성된 3D object를 미분가능하게 Rendering합니다.
- 렌더링된 이미지를 CLIP의 이미지 인코더를 통해서 를 얻습니다
- Text Prompt 역시 CLIP의 텍스트 인코더를 통해서 를 얻습니다.
- 를 입력으로 받은 Diffusion Model을 통해서 를 얻습니다.
- 와 의 코사인 유사도 계산, 와 의 코사인 유사도 계산, 그리고 Laplacian Regularizer을 통해서 학습이 진행됩니다.
학습 과정에대해서 하나하나 자세히 설명해드리겠습니다.
3D model을 3가지 형태로 표현할 수 있다.
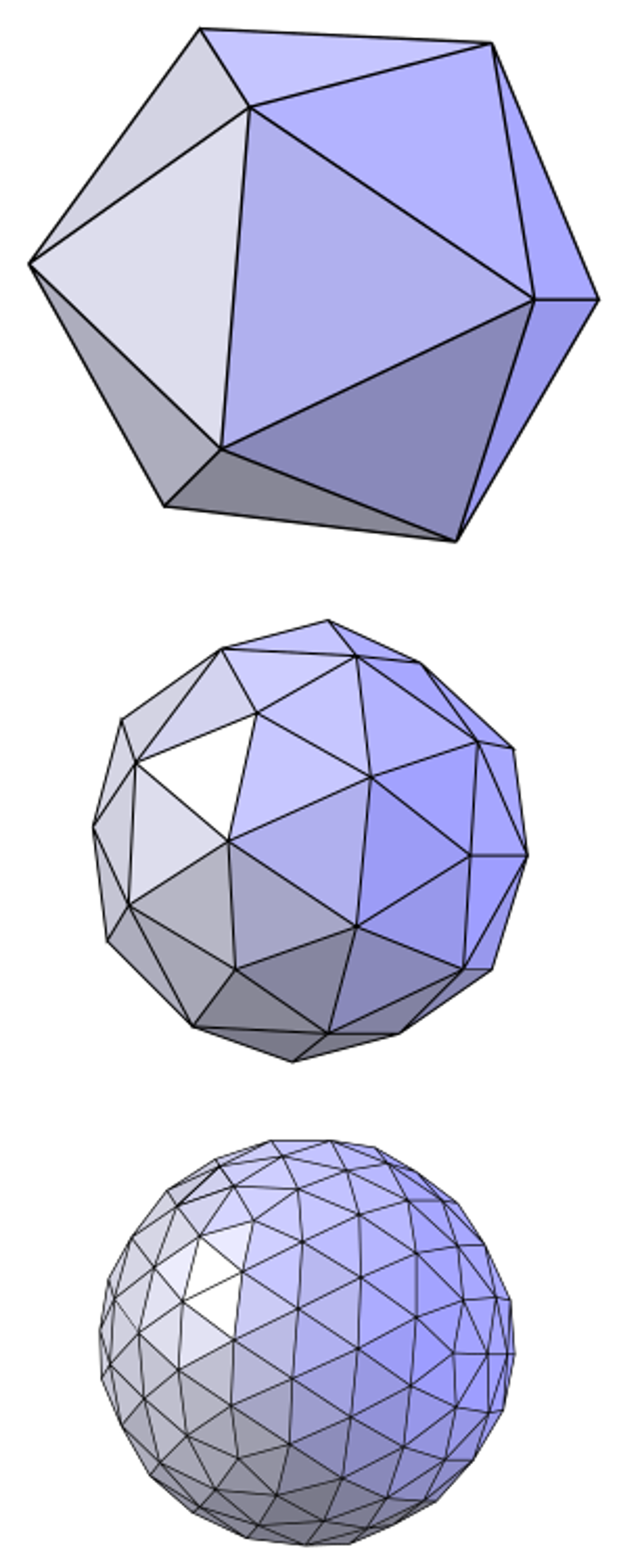
- 3D mesh: 의 점들을 사용해서 Loop Subdivision Surface를 생성합니다. Loop Subdivision Surface는 위의 사진처럼 점점 더 부드러운 표면을 만들기 위해 정점을 반복적으로 분할하여 생성됩니다.
- Texture Map: Mesh의 표면을 덮는 색상을 나타냅니다. 텍스처 맵을 사용하면 기하학적 모양과 외관을 분리하여 각각 독립적으로 조정할 수 있습니다.
- Normal Map: 표면의 세부적인 질감을 표현하며, 빛이 표면에 닿는 방식에 영향을 줍니다.
initial Control Mesh: 3D 모델링에서 기본이 되는 정점들과 그 정점들을 연결하는 면들로 구성된 초기 상태의 mesh
Limit surface: 여러 번의 subdivision 과정을 거친 후에 얻어지는 매우 부드러운 표면
initial Control Mesh → (Loop Subdivision Surface를 이용해서) → Limit surface 이 과정은 differentiable(미분 가능)하다. 이렇게 mesh를 생성하는 과정은 Implicit Regularizer(명시적으로 추가된 것이 아닌, 알고리즘이나 과정 자체에 내재된 규제 역할)을 하고 Triangle Inversion (삼각형 뒤집힘) 방지한다.
Differentiable Renderer(R)를 사용하여 3D 모델을 다양한 카메라 각도에서 2D 이미지로 렌더링합니다. 이 과정에서 mesh의 표면, texture, normal map이 반영됩니다.
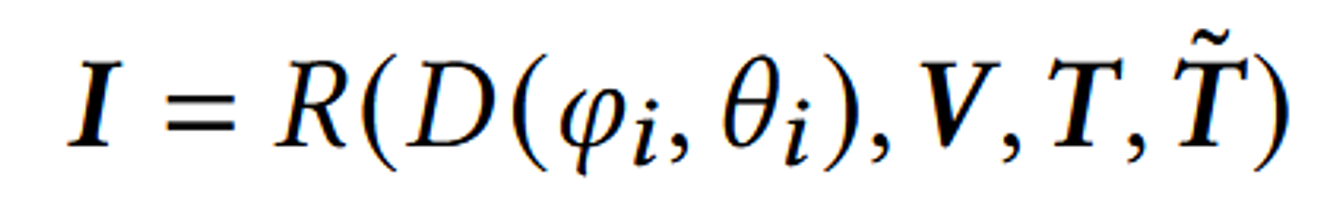
D(φₑ, θₑ):
- D는 카메라의 위치와 방향을 결정하는 뷰 매트릭스 또는 카메라 파라미터를 나타냅니다.
- φₑ와 θₑ는 각각 카메라의 방위각(azimuth angle)과 고도각(elevation angle)을 나타내는 변수입니다.
V,T,T̃:
- V,T,T̃는 각각 Vertex(정점), Texture map, Normal map을 나타냅니다.
Using CLIP
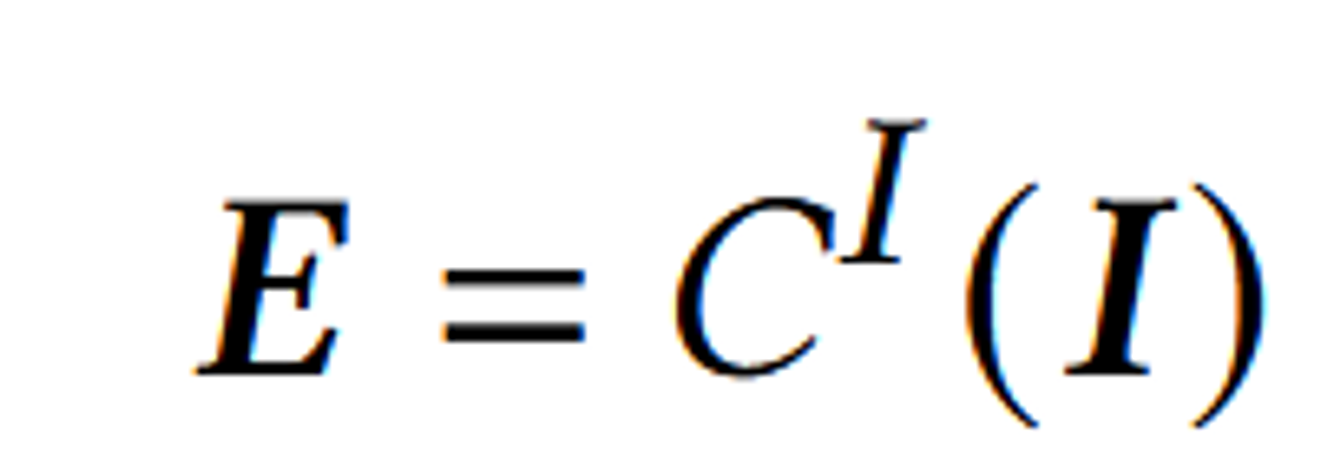
이후 렌더린된 이미지는 CLIP 이미지 인코더()를 통해서 E로 나타냅니다.
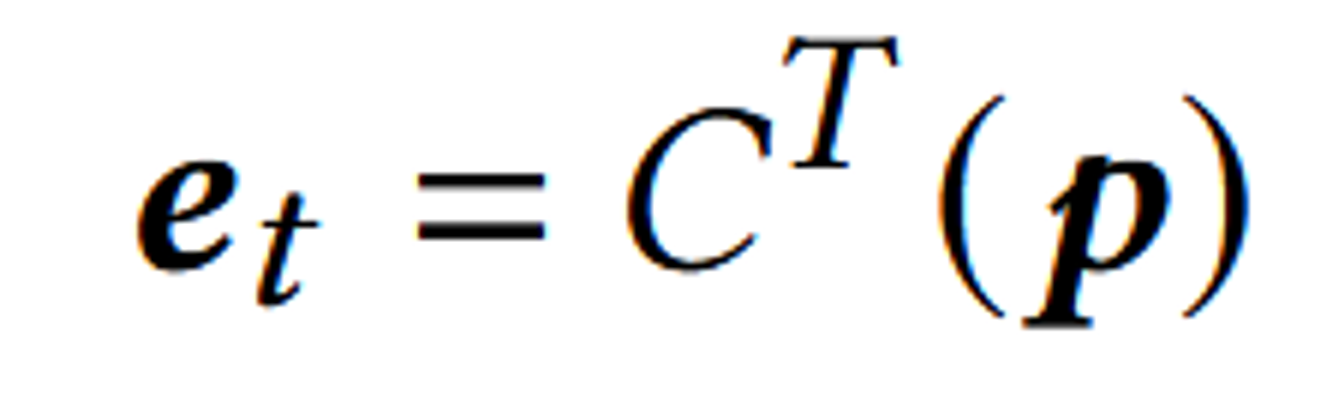
입력된 Text 프롬프트 역시 CLIP의 Text 인코더()를 통해서 로 나타냅니다.
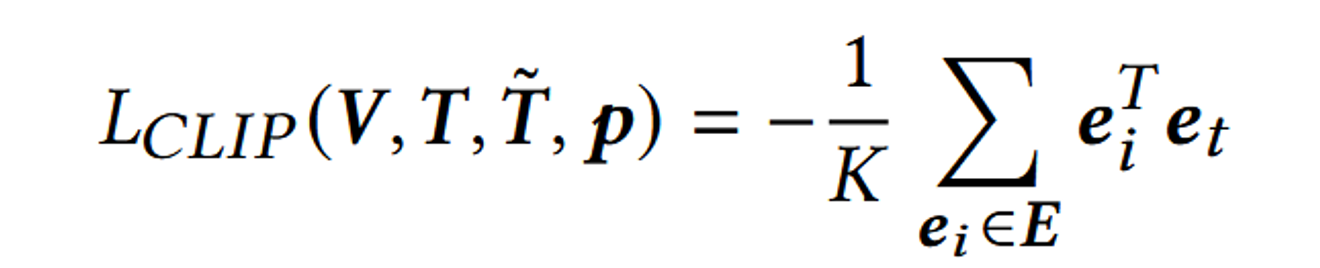
위의 CLIP Loss는 결론적으로 코사인 유사도를 기반으로 이미지 임베딩과, 텍스트 임베딩 값을 계산합니다.
Laplacian Regularizer
Mesh의 각 정점(vertex)이 그 주변의 이웃 정점들과 얼마나 일관된 위치에 있는지를 측정하여, mesh가 최적화 과정 중에 불규칙하게 변형되는 것을 방지합니다.
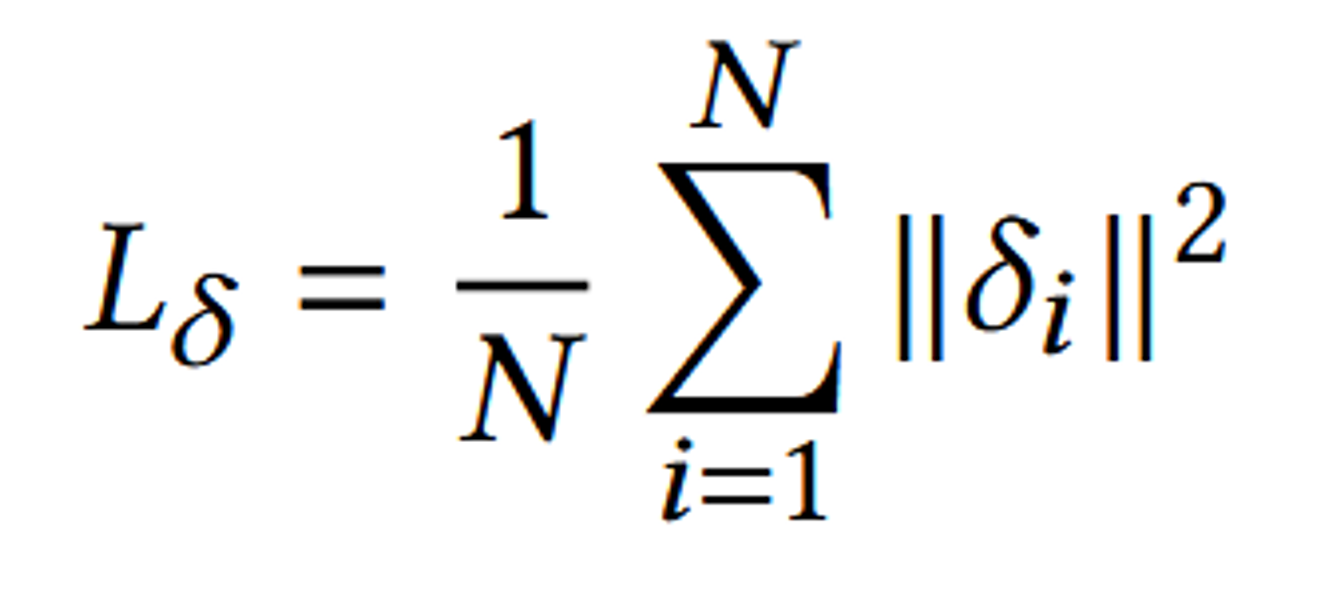
- Laplacian Operator ():
- :
- 이 수식은 정점 가 주변 이웃 정점들 의 평균 위치에서 얼마나 벗어나 있는지를 나타냅니다.
- 여기서 는 정점 의 one-ring neighbors (즉, 바로 인접한 이웃 정점들)의 집합입니다.
- 이 수식을 통해 얻어지는 값 는 라플라시안 값으로, 정점 의 위치가 이웃 정점들로부터 얼마나 "평균적으로" 벗어나 있는지를 나타냅니다.
- :
- Laplacian Regularizer ():
- :
- 이 수식은 모든 정점에 대한 라플라시안 값을 계산하여 그 제곱합을 구한 뒤, 이를 전체 정점의 수 N으로 나누어 평균을 구합니다.
- 결과적으로, 이 정규화 항은 정점들이 그 이웃들과 얼마나 일관된 위치에 있는지를 나타내는 값을 최소화합니다. 즉, 메쉬의 표면이 가능한 한 부드럽게 유지되도록 합니다.
- :
Diffusion Prior
입력값: 텍스트 임베딩 : CLIP의 텍스트 인코더에서 추출된 임베딩 값
출력값: 이미지 임베딩 : Diffusion Prior가 생성한 이미지 임베딩 값
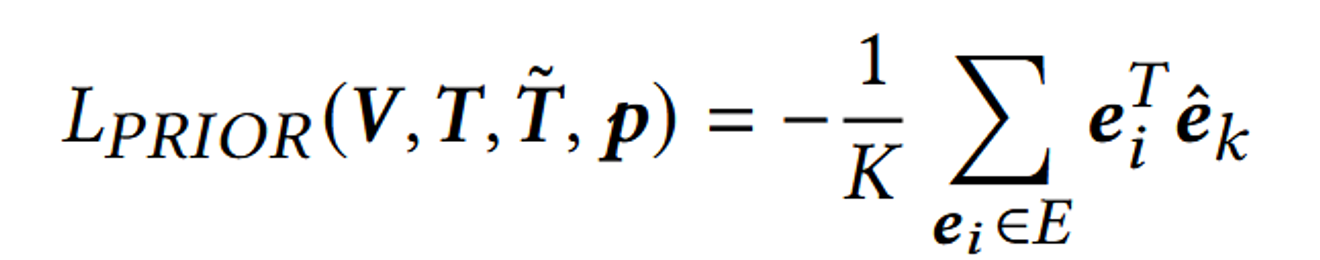
Diffusion의 출력된 결과와 CLIP의 이미지 인코더의 출력값에 대해서도 코사인 유사도를 계산합니다.
왜냐하면 Diffusion의 출력값 역시 텍스트 임베딩 값을 기반으로 만들었기 때문에 CLIP의 이미지 임베딩값과 유사하므로 코사인 유사도를 기반으로 학습할 수 있습니다.
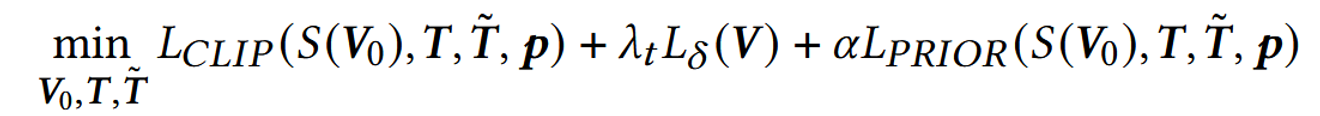
최종적인 Loss는 다음과 같습니다.
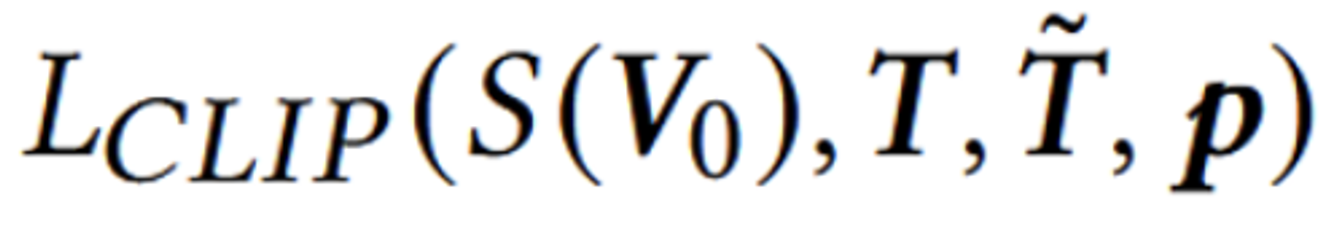
- CLIP을 기반으로 텍스트 임베딩 값과 이미지 임베딩값을 코사인 유사도 기반 학습
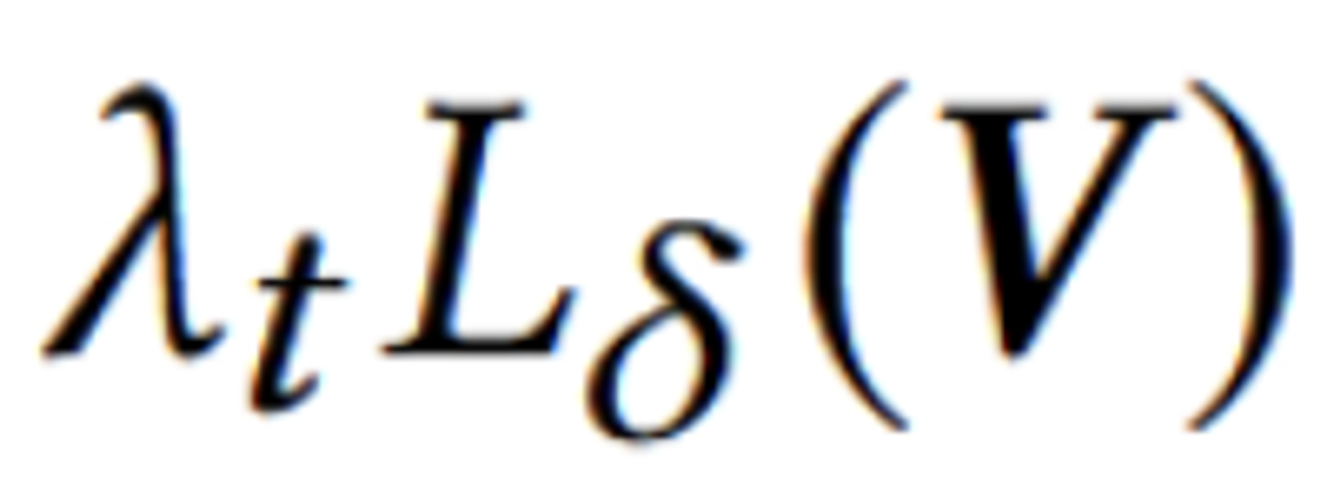
- Laplacian Regularizer를 이용해 mesh가 최적화 과정 중에 불규칙하게 변형되는 것을 방지
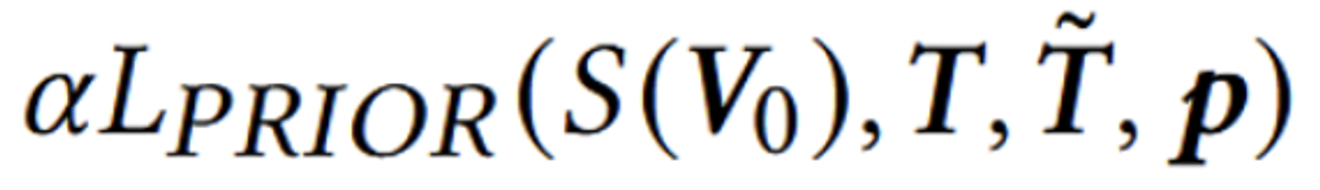
- Diffusion의 출력값과 CLIP의 이미지 인코더를 통과한 이미지 임베딩 값의 코사인 유사도 기반 학습
Practical Considerations and Implementation Details
시작 정점의 개수: 600개
Texture map: 512x512 resolution의 random값으로 시작
normal map: 512x512 resoultion의 uniform blue image로 시작
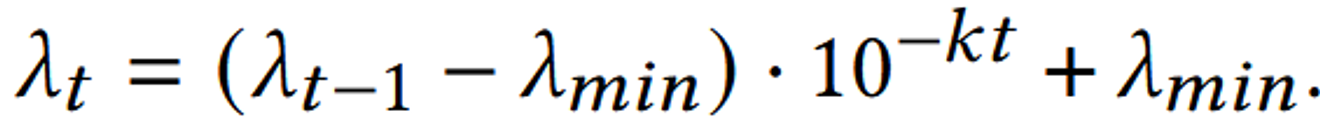
Laplacian Regularizer의 λ는 decay(점점 줄어들면서) 진행
Texture bias 문제 해결
CLIP과 같은 Visual Recognition 모델들은 이미지의 모양보다 텍스처에 집중하는 경향이 많습니다.
→ 카메라 뷰를 생성하는 과정에서 randomization을 추가
무작위 뷰 생성
- 카메라의 시야각(field of view)을 무작위로 30도에서 60도 사이에서 선택합니다.
- 카메라와 객체 사이의 거리도 3.0에서 7.0 사이에서 무작위로 변경합니다.
randomization을 추가함으로서 카메라의 줌 인/아웃 효과를 유도하며, 결과적으로 텍스처보다 형상의 변화를 강조하도록 만듭니다.
Rendering Resolution
실험을 통해서 512x512 이미지를 만들고 이를 CLIP의 이미지 224x224로 변경하는 것이 성능이 더 좋다고 밝혔습니다. 더 높은 해상도에서 렌더링하면, Anti-Aliasing에 의해 더 많은 픽셀들이 영향을 받게 되고, 이로 인해 그래디언트 노이즈가 감소합니다.
Random Augmentations
렌더링된 이미지의 배경이나 객체의 위치에 의존하지 않고, 객체 자체의 모양과 텍스처에 집중하도록 하기 위해 Random Augmentations를 진행합니다.
랜덤 배경의 예시
- Gaussian Noise: 이미지에 랜덤한 노이즈를 추가하여 배경을 복잡하게 만듭니다.
- 단색(Solid Color): 배경을 단순한 단색으로 설정합니다.
- Random Color Checkboard Pattern: 배경을 무작위로 색칠된 체크보드 패턴으로 만듭니다.
객체 위치의 랜덤 오프셋
- 목적: 객체가 항상 이미지의 중앙에 위치하지 않도록 무작위로 위치를 조정합니다.
- 이유: 객체가 항상 같은 위치에 있으면 CLIP 모델이 그 위치에 의존하여 손실을 최소화하려고 할 수 있습니다. 이를 방지하고, 객체의 모양이 어떠한 조건에서도 일관되게 유지되도록 하기 위함입니다.
RESULTS AND EVALUATIONS
Single Object Generation

랜드마크에 대해서 텍스트 프롬프트를 입력으로 사용해서 나온 결과입니다. CLIP의 이미지 인코더로 사용한 모델은 ViT/B-32 입니다.

Dream Fields 모델과의 결과의 차이를 보여주는 그림입니다. 위에 줄에 있는 그림들이 Dream Fields이고 아래 줄에 있는 그림들이 CLIP-Mesh의 결과입니다. Dream Fields와 비교할 때 해당 모델에 많은 리소스가 필요하기때문에 CLIP의 이미지 인코더를 ViT-B/16
Complex Modeling Scenarios
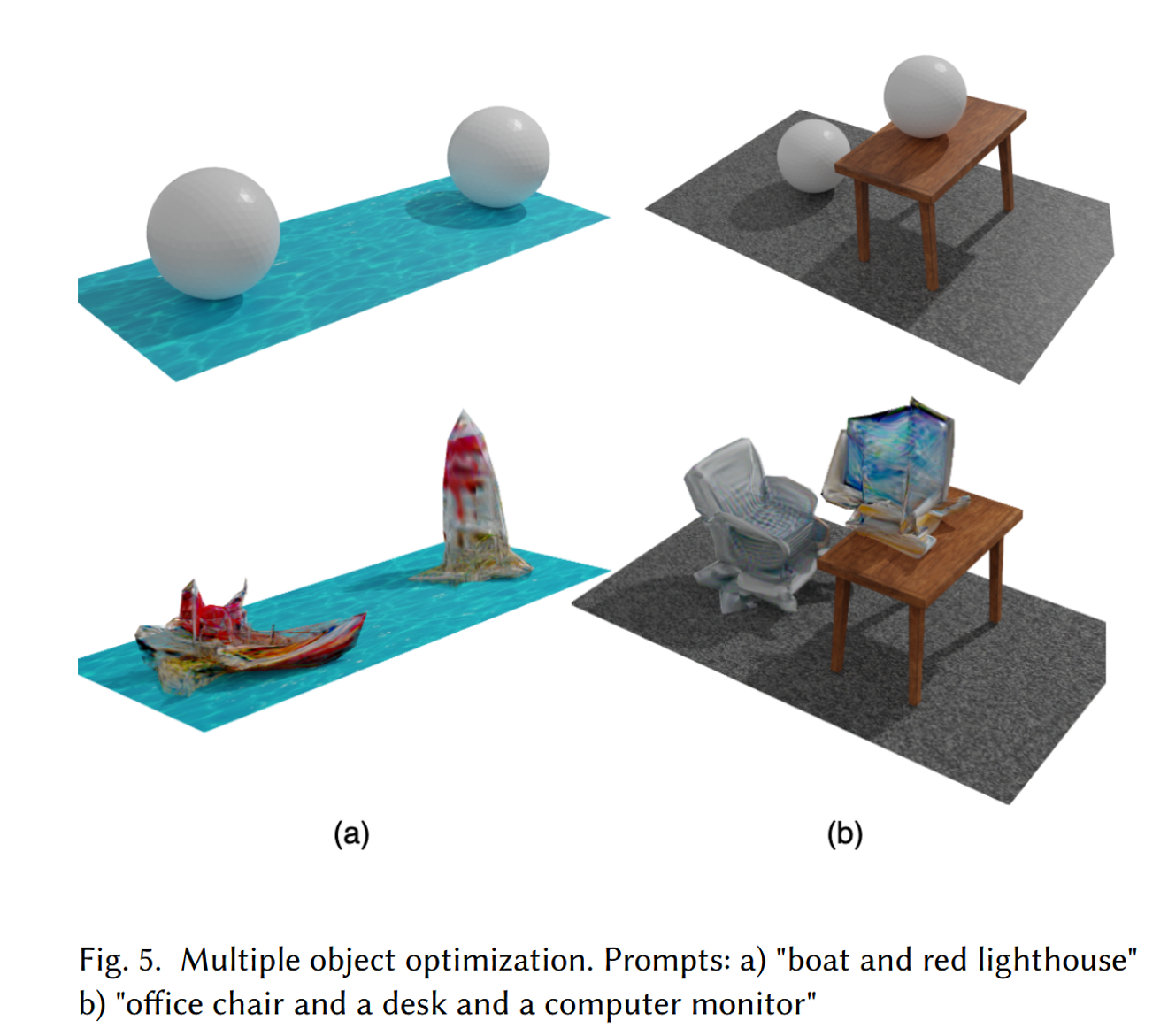
해당 그림에서 위에 있는 부분들의 배경(바닥에 있는 물, 시트, 테이블)의 Vertices나 texture는 고정해두고, Sphere(구)에 대해서만 학습을 진행해서 나온 결과들입니다.
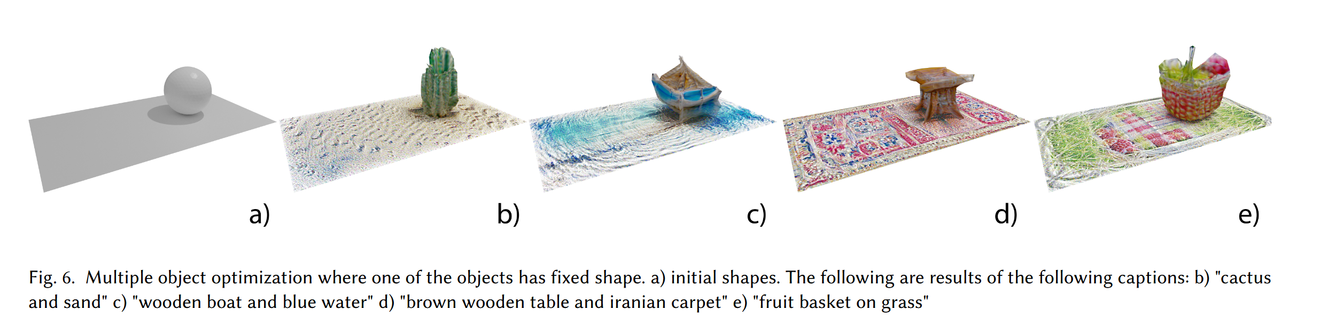
위 사진은 배경의 noramal map과 texture map만 학습하게 했을 때의 결과입니다.(즉 Vertices는 고정)
Quantitative Evaluation
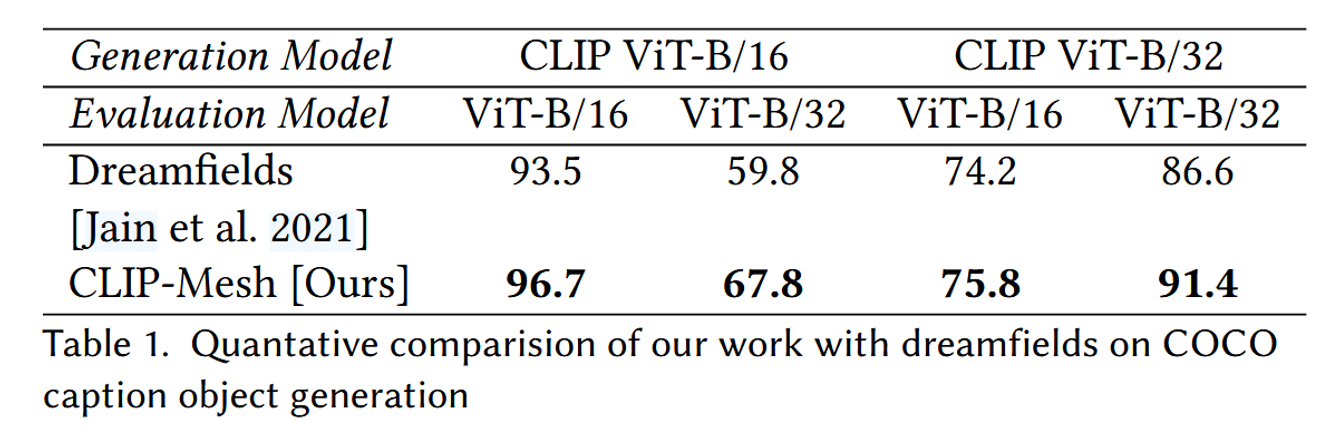
Dream Fields 논문과 CLIP-R precision score(생성된 이미지와 텍스트 설명 간의 일치도를 정량적으로 측정하는 지표)에 대해서 비교를 했습니다.
해당 비교에서 Diffusion prior는 사용하지 않은 결과입니다. 사용하지 않은 이유는 Diffusion Prior를 훈련할 때 사용된 데이터셋에 CLIP ViT-B/32 임베딩만 포함되어 있어 CLIP ViT-B/16 모델을 지원하는 Prior를 훈련할 수 없기 때문입니다. 그럼에도 성능이 더 높은 것을 확인할 수 있습니다.
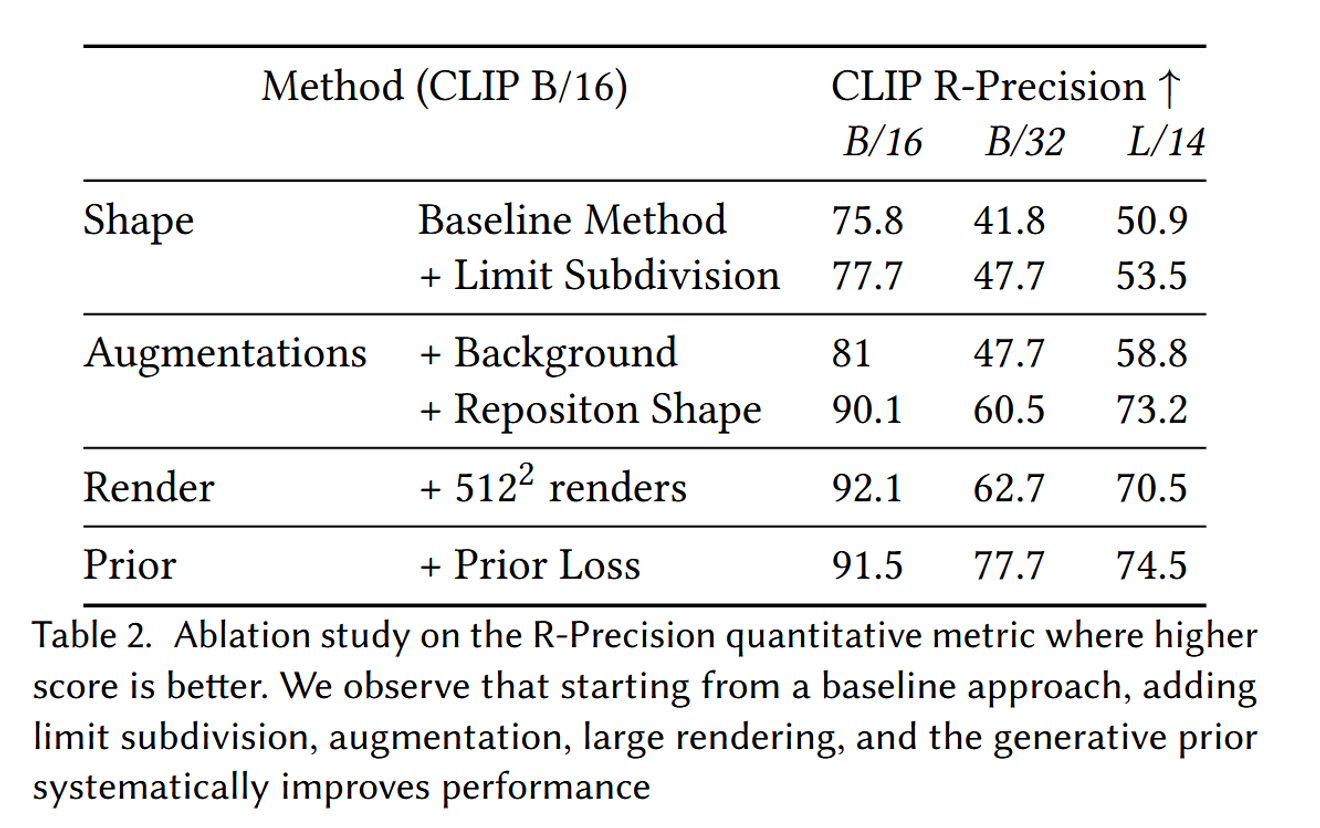
해당 표는 Ablation study를 나타냅니다. 모든 학습 방식을 추가할 때마다 성능이 추가되는 것을 확인할 수 있습니다. 여기서 주의깊게 봐야될 점은 Augmentation에서 물체의 위치를 가운데에 두지 않는 Reposition Shape을 추가했을 때 성능이 10% 이상 증가한 것입니다. 또한 Vit-L/14의 경우 렌더링할 때 사이즈를 512x512로 한 후 224x224로 변환하는 과정이 오히려 성능을 감소시킨 점입니다.
CONCLUSIONS, LIMITATIONS AND FUTURE WORK
Limitations
- Genus
- Genus는 3D 형상의 구멍의 수를 나타냅니다. 예를 들어, 도넛 모양의 객체는 하나의 구멍을 가지고 있어 종수가 1인 반면, 구형은 구멍이 없기 때문에 종수가 0입니다.
- 이러한 Genus의 값이 초기 템플릿 mesh의 종수에 따라 결정된다는 문제점입니다.
- 이를 해결하기 위해서 transparency channel을 적용해 객체의 일부를 보이지 않게 하여, 사실상 구멍을 추가하거나 제거하는 효과를 얻을 수 있다고 했습니다. 하지만 이 역시 임시적인 해결책일 뿐이며 근본적인 조작이 필요하다고 언급했습니다.
- CLIP 모델의 한계
- CLIP 모델 자체가 2D 이미지를 기반으로 학습된 모델이다 보니 의도하지 않은 불필요한 요소들이 3D 메쉬에 투영될 수 있습니다. 이러한 현상을 artifacts라고 표현했습니다.
- 예를 들어, 피라미드를 생성할 때, 피라미드의 측면에 작은 사람들의 형상이 나타나거나, 에베레스트 산을 생성할 때, 산의 측면과 꼭대기에 "Everest"라는 텍스트가 나타납니다.
- 이러한 문제를 해결하기 위해서 CLIP ViT/B-32 모델처럼 더 큰 모델을 사용하면 완화된다고 했지만 이 역시 근본적인 해결책은 아닙니다.
