Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures 논문리뷰
논문 링크
Summary
큰틀은 Text-to-3D입니다. 하지만 Shape-guided(Sketch-Shape, Latent-Paint)방식이라는 기본적인 틀을 제공해주는 방식을 사용해서 생성했습니다. 즉 입력값이 Text만 들어가는 것이 아니라 기본적인 틀도 같이 들어가는 형태입니다.
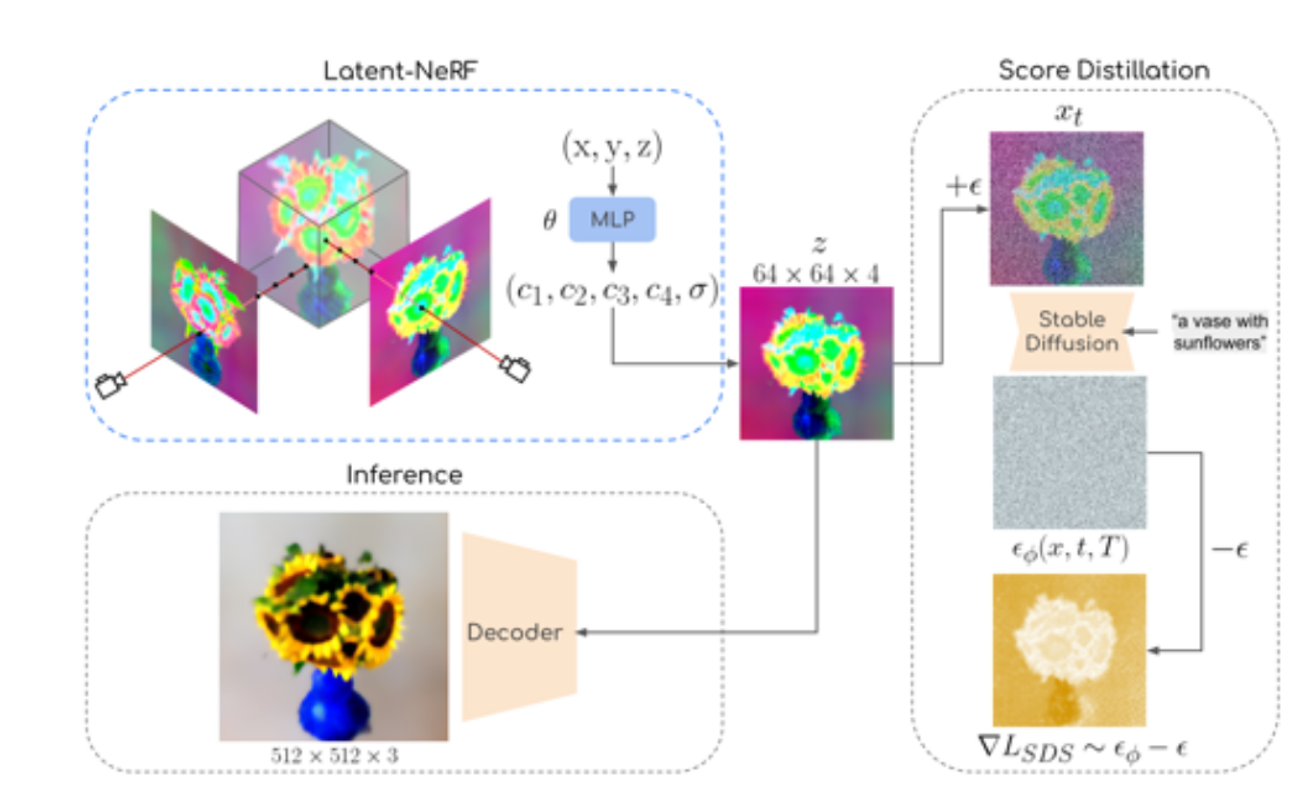
모델의 구조는 다음과 같습니다.
- Latent-NeRF
- 기존 NeRF모델들의 출력값은 Color + density 값입니다.
- 하지만 Latent-NeRF의 출력값은 pseudo-color channels(c1, c2, c3, c4) + density 입니다.(각 채널은 64x64 high resolution image)
- Latent-NerF의 출력값인 latent vector를 통해서 LDM(Stable Diffusion)을 학습합니다. 이때 Score distillation Loss를 이용해서 노이즈를 학습합니다.
- 최종적으로 학습된 latent vector를 디코더에 입력해서 최종 RGB 이미지를 생성합니다.

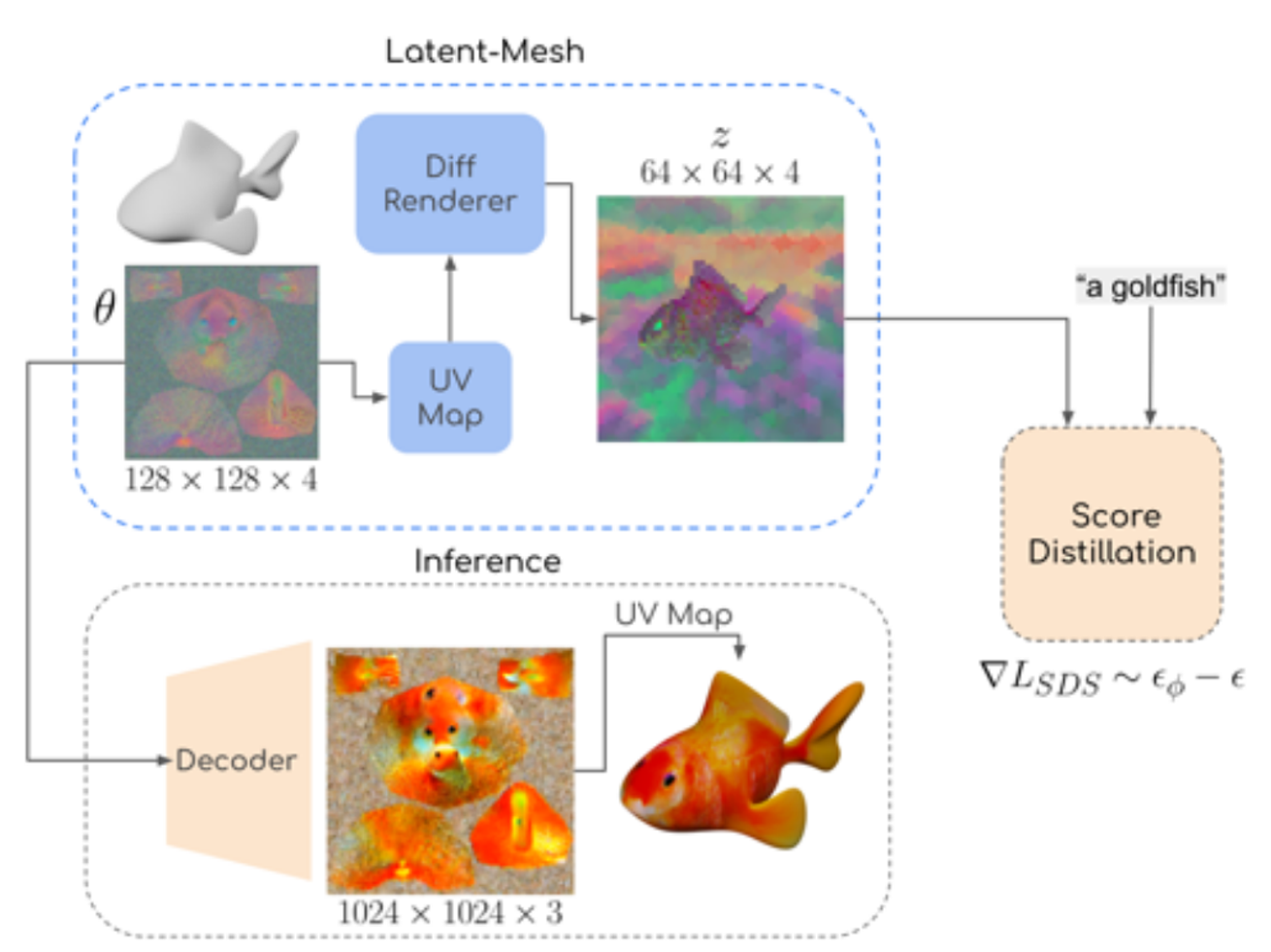
- Shape-guided
- Sketch-Shape Guidance
- 기본적인 3D 형태를 제공해주고 해당 형태를 기반으로 학습이 진행된다.
- Blender라는 software 툴을 이용해서 사용자가 직접 그려야됩니다.
- Latent-Paint of Explicit Shapes
- UV texture mapping을 위한 latnet vector(128x128x4)를 학습시킵니다.
- UV Texture map은 Mesh에 포함되거나, XAtlas와 같은 sofrware를 이용해 생성합니다.
- 최종적으로 latent vector를 디코더를 통과시켜 UV Map을 3D object에 적용시킵니다.
- Sketch-Shape Guidance
해당 논문은 Stable Diffusion 모델에서 방향을 지정한 이미지 생성에서 한계를 보인다는 점과, seed 값을 변경할 때 결과가 많이 달라진다는 점을 한계로 뽑았습니다.
하지만 처음으로 score distillation 방법을 LDM에 적용하고, Shape-guided(Sketch-Shape, Latent-Paint)방식을 생성 모델에 적용한점 마지막으로 NeRF를 latent-space에서 적용하는 등 새로운 방식을 제안했습니다.
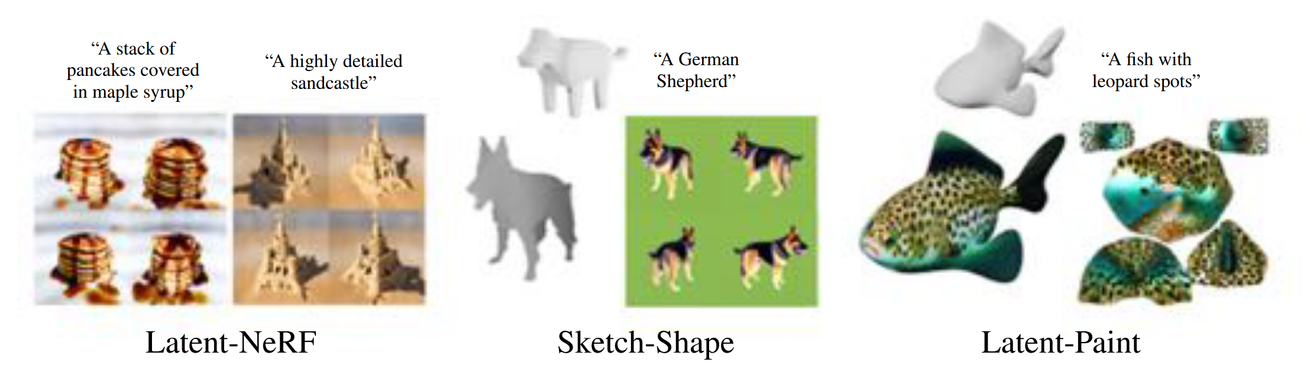
Abstract
최근 Text-guided image generation은 급속도로 발전중입니다. NeRF모델을 이용해서 3D object를 생성한 score distillation 논문도 나왔습니다. 이 논문에서는 score distillation을 기반으로 계산 효율성과, publicly available를 위해서 Latent Diffusion Model을 적용했습니다.
NeRF는 이미지 공간에서 작동하므로, 텍스트 기반의 Score Distillation을 적용하려면 매번 latent space로 인코딩해야 하는 비효율적인 과정이 필요했습니다. 이를 생략하기 위해서 NeRF를 latent space로 보내는 Latent-NeRF를 제시했습니다.
Latent-NeRF에 대해서 가이드를 제시하기 위해서 우리가 원하는 object의 추상적인 형태를 제공하는 Sketch-Shape를 사용했습니다.
이러한 text와 shape guidance가 성능을 높였고, latent score distillation이 3D mesh에 성공적으로 적용된다는 것을 확인했습니다.
Introduction
Abstract에 나온 부분들에 대해서 조금더 구체화 한 내용들입니다.
Text-guided image generation는 Langae-Image model과 Diffusion model의 발전으로 엄청난 성공을 이뤘습니다. 최근 연구에서는 2D Diffusion 모델에서 직접적으로 Score Distillation 기법을 사용하여 NeRF로 3D 오브젝트를 생성하는 방법이 제안되었습니다.
기본적으로 Text-to-3D generation 모델들은 unconstrained(구속되지 않은) 방식으로, 특정 3D 구조를 명확하게 정의하거나 강제할 수 있는 능력이 부족할 수 있습니다. 따라서 해당 논문에서는 shape-guidance(Sketch-Shape, Latent-Paint)를 통해서 특정한 형태로 제약하는 방식을 사용합니다.
Latent-Paint: 3D Mesh에서 직접 텍스처를 생성하고 색칠하는 방법으로, 텍스처 맵을 latent space에서 표현하고, 가이드 Gradient를 통해 Mesh의 표면에 텍스처를 적용합니다.(추후에 추가 설명)
Latent-NeRF 모델은 NeRF 모델과 Latent Diffusion Model(LDM)에 기반합니다.
추가적으로 기존의 score distillation가 2가지 차이점이 존재했습니다.
- NeRF의 RGB space를 기반으로 작동했다면, Latent-NeRF모델은 latent space에서 작동하도록 수정했습니다. 이를 통해 각 가이드 단계마다 RGB 이미지를 latent space로 인코딩하는 부담을 줄일 수 있습니다.
- Latent-NeRF를 훈련한 후, 이를 다시 일반적인 NeRF로 쉽게 변환할 수 있습니다. 이를 통해 RGB 공간에서 더 정교한 수정을 수행할 수 있습니다. (Linear layer 추가)
Related Work
3D Shape Generation
가장 쉬운 학습 방법은 직접 3D Shape에 적용하는 방식입니다.
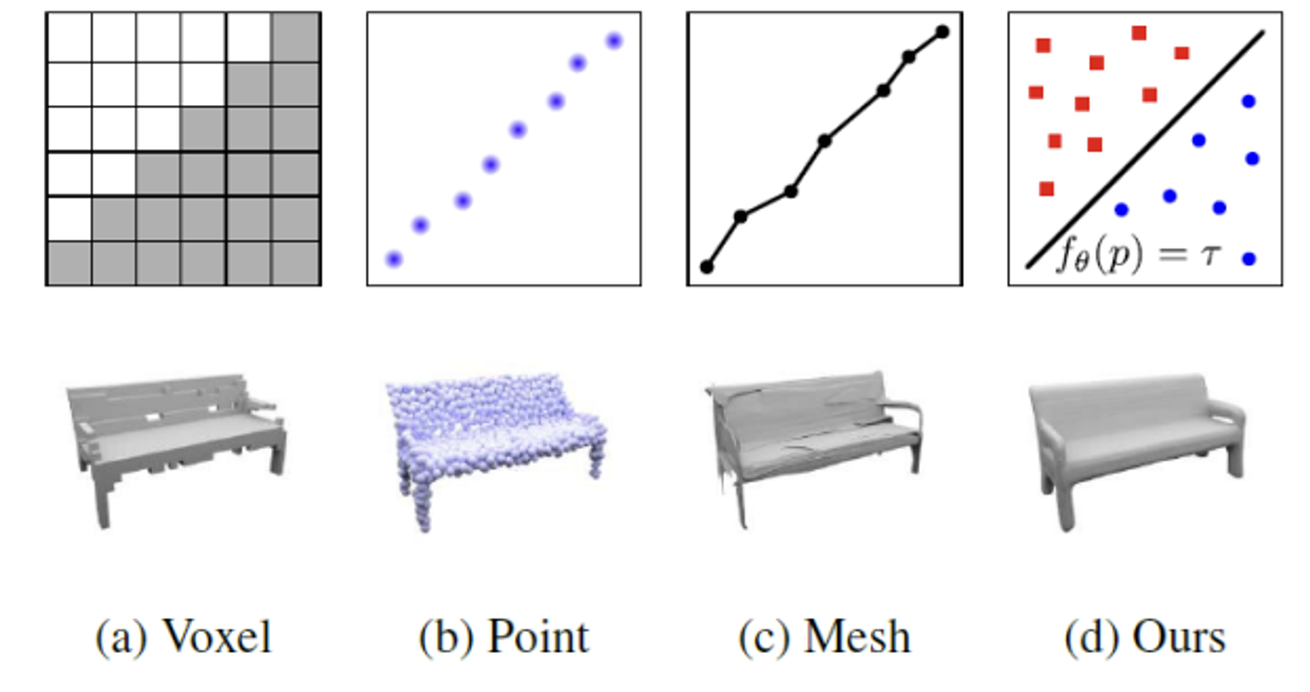
해당방식에는 위와같은 4가지 경우가 있습니다. (Ours =Implicit Representation)
Voxel: 3차원 공간을 grid로 나눴을 때 각각의 공간을 차지하는가 차지하지 않는가(0 or 1)
Point: grid없이 점들의 집합으로 나타내는 것
Mesh: 표면이 어떻게 생겼는가를 표현하는 것
Implicit Representation: 객체의 경계면을 기준으로 값을 a와 b로 나누는 것. 그 기준은 함수를 이용해서 구하는 것
하지만 위와 같은 3D Shape을 직접적으로 얻는 것은 힘듭니다.
따라서 2D 이미지를 이용해서 3D를 생성하는 분야도 발전했습니다.
예를들어서, GET3D에서는 2개의 생성기를 사용하여 3D 형태와 텍스처 필드를 생성합니다. 이를 위해 2D 이미지 데이터를 사용해 adversarial training을 수행합니다.
Text-to-3D with 2D Supervision
Language-Image 모델의 발전으로 Text-to-3D 분야도 발전되고 있습니다.
CLIP-Forge: 2개의 요소로 구성되어 있습니다. 첫번째는 implicit autoencoder conditioned on shape codes 두번째는 normalizing flow model
Text2Mesh: CLIP을 통해 초기 Mesh를 최적화하여 3D Mesh의 색상화와 기하학적 fine-tuning을 수행합니다.
CLIP-Mesh: CLIP-Mesh는 초기 구형 Mesh를 텍스트 프롬프트에 맞게 최적화하여, 텍스트 프롬프트에 따라 3D Object의 색상과 형태를 조정합니다.
DreamFields: CLIP을 사용하여 3D Object를 안내하지만, 삼각형 Mesh 대신 NeRF를 사용해 3D Object를 표현합니다.
DreamFusion: DreamFusion은 사전 학습된 2D Diffusion 모델을 사용하여 텍스트 기반 3D Object 생성을 최초로 제안했습니다. 이 방법은 NeRF와 결합하여 3D Object를 생성하는데, Score Distillation 손실을 통해 이를 구현합니다.
Neural Rendering
NeRF 모델은 novel view synthesis 모델로서 새로운 뷰에서 보는 이미지를 생성할 수 있습니다. 이 모델은 3D Reconstruction에서도 많이 사용됩니다.
Method
Preliminaries
latent diffusion model (LDM)
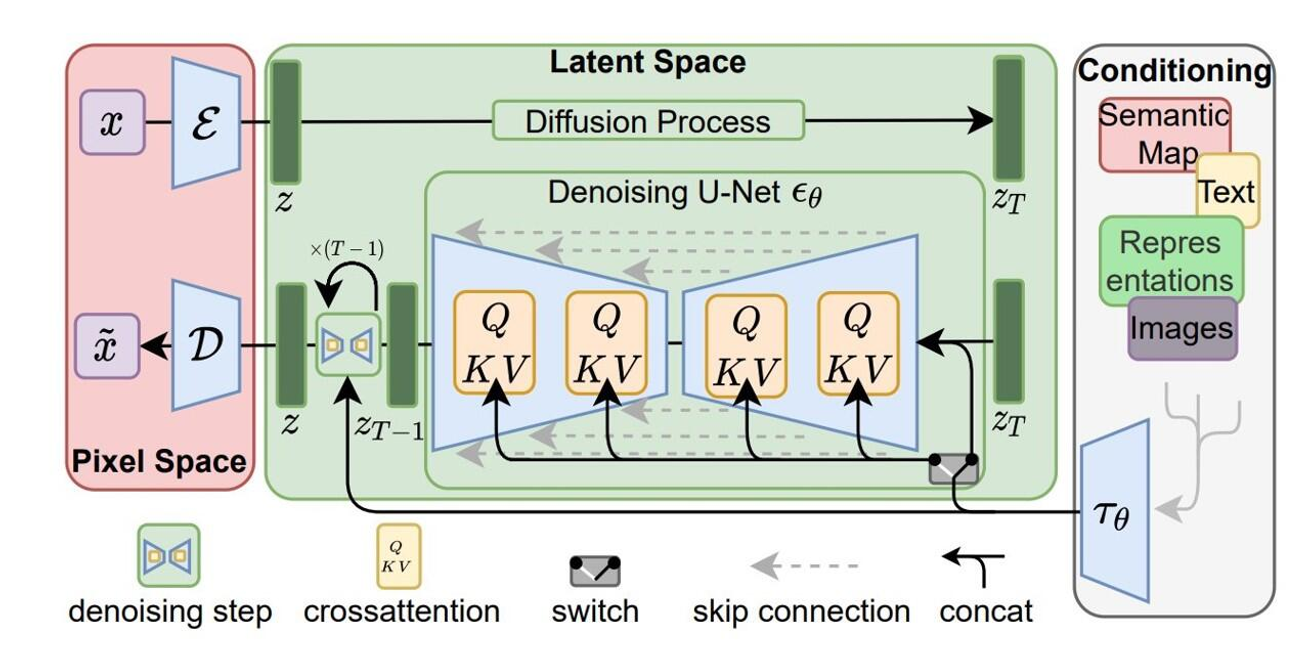
기존의 Diffusion 모델에서는 고해상도 이미지 자체에서 노이즈를 추가했다면, latent diffusion model들은 이미지를 Encoder를 통해서 latent space(z)로 보내고 이를 기반으로 Diffusion 모델을 사용하는 것을 말합니다.
우선 autoencoder를 통해서 입력 이미지를 latent space(z)로 보내고 이를 다시 이미지로 복원하는 과정을 진행합니다.
다음으로 DDPM을 이용해서 위에서 생성된 latent space(z)값을 학습합니다.
이를 통해서 더 빠르게 학습을 진행할 수 있고, 성능도 더 좋아졌습니다. 대표적인 예로는 Stable Diffusion 모델(위의 사진)이 있습니다.
Score Distillation
Diffusion 모델 자체를 통해 backpropagation하는 대신, Diffusion 모델이 제공하는 노이즈 예측 결과를 이용해 손실을 계산합니다. 이는 DreamFusion에서 나온 방식으로 해당 모델에서는 Imagen에 적용했습니다. NeRF를 통해 생성된 이미지에 노이즈를 더해가면서 예측을 진행하는 방식입니다.
작동 방식은 아래와 같습니다.
우선 노이즈가 추가된 이미지()를 생성합니다.
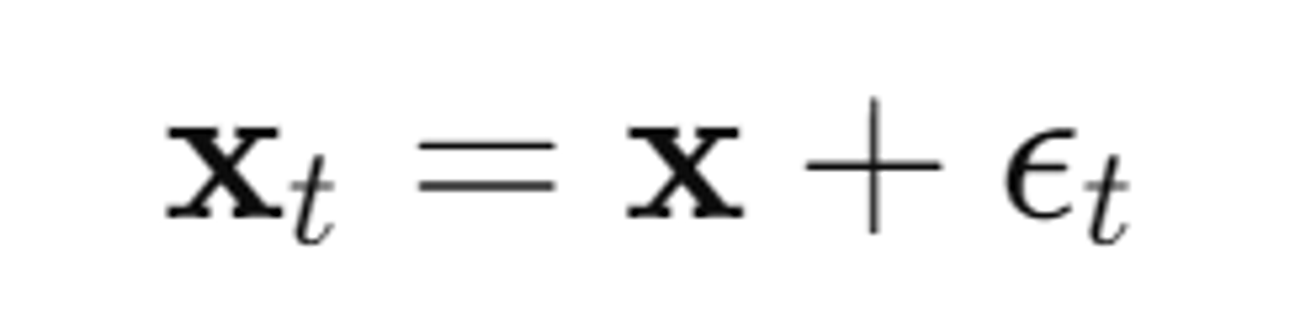
- : 시간 단계 t에서 노이즈 ϵt가 추가된 이미지
- : 원본 이미지(생성된 이미지)
- : 시간 단계 t에서 노이즈를 추가하는 함수 Q(t)의 출력값
다음으로 SDS loss의 Gradient를 계산합니다.
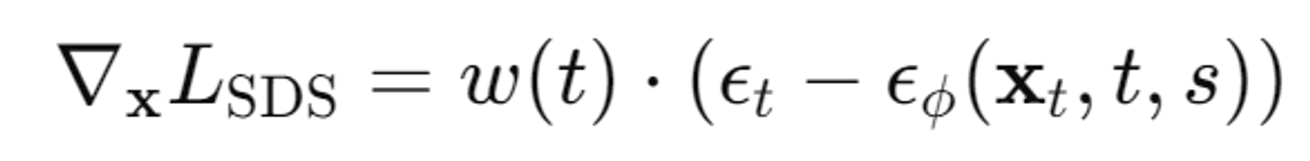
- : 손실 함수 LSDS의 그래디언트(즉, 각 픽셀별 손실의 변화율)
- w(t): 시간 단계 t에 따른 가중치 함수. 이 함수는 특정 시간 단계에서 손실에 더 큰 영향을 주거나 줄이는 역할
- : 이전 단계에서 추가된 실제 노이즈
- : 사전 학습된 DDPM 모델이 예측한 노이즈. 이 모델은 입력 이미지 xt, 시간 단계 t, 텍스트 프롬프트 s를 기반으로 노이즈를 예측
기존 DreamFusion에서는 RGB space(Imagen)에서 적용했다면 해당 논문에서는 latent space(Stable Diffusion)에서 적용한 방식이 차이점입니다.
Latent-NeRF
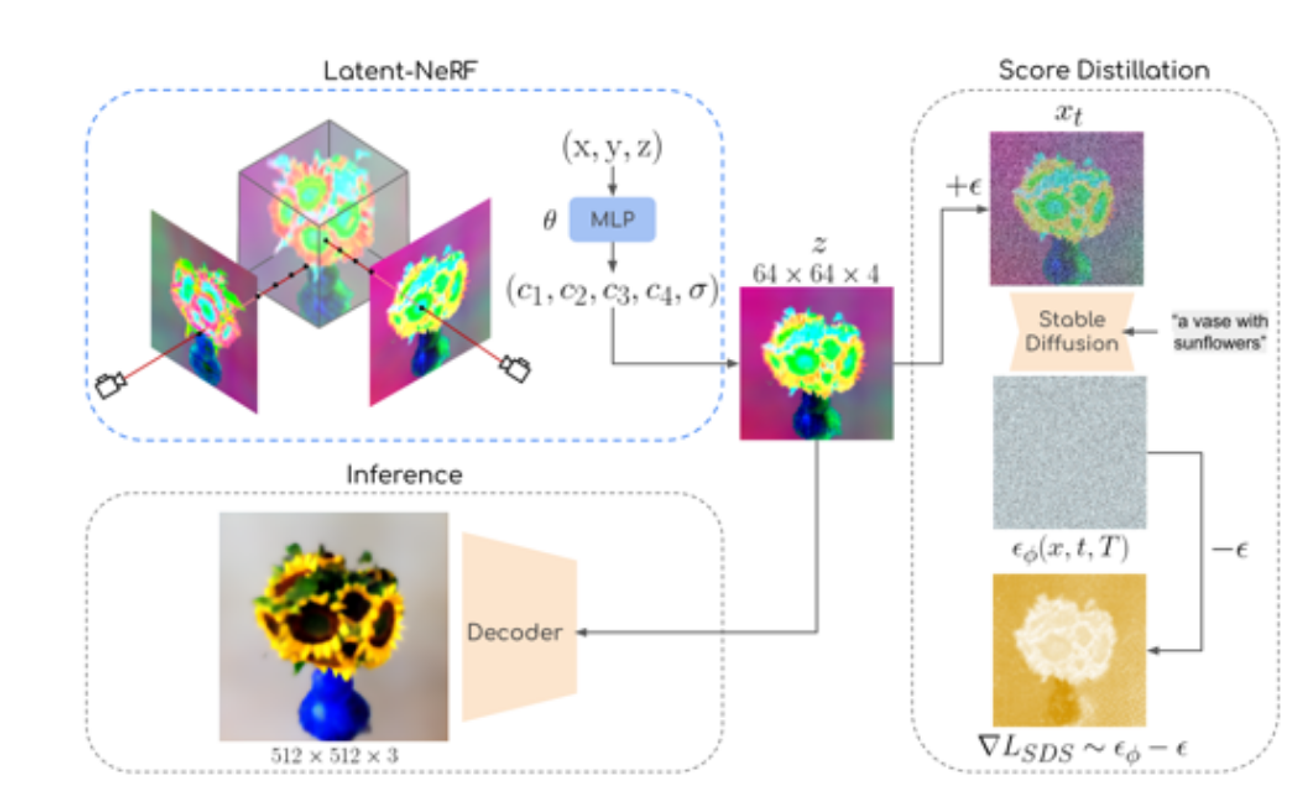
모델 작동 순서 요약
- 입력 좌표 (x, y, z)가 MLP에 입력됨.
- MLP는 이 좌표를 기반으로 네 개의 잠재 채널과 볼륨 밀도를 예측.
- 이 정보는 잠재 공간 Z에서 64x64 해상도의 이미지로 변환됨.
- Score Distillation: 노이즈가 추가된 이미지가 Stable Diffusion 모델을 통해 노이즈 제거 학습을 진행함.
- 손실 계산: 예측된 노이즈와 실제 노이즈의 차이를 이용해 NeRF 모델을 학습.
- 추론(Inference): 학습된 잠재 공간 이미지를 디코더에 입력해 최종 RGB 이미지를 생성.
NeRF를 이용한 latent space vector(z) 추출
원래의 NeRF 모델은 입력 좌표를 넣었을 때 해당하는 점의 color(R,G,B)값과 density값을 나타내어서 4D-vector를 출력합니다. 하지만 Latent-NeRF에서는 동일한 입력 좌표를 넣지만 출력값으로 pseudo-color channels(c1, c2, c3, c4)와 density를 출력하도록 합니다. 앞의 4차원 pseudo color channels의 값이 Stable Diffusion의 입력 이미지 64x64x4가되는 것입니다.
- 개인적으로 궁금한 부분: pseudo color channels를 출력하는 MLP와 기존 MLP는 동일할까?



위의 코드는 latent-NeRF의 공식 github 코드입니다. 코드를 완벽하게 보지는 않았지만 위의 코드들을 통해 추론해본 결과 layer의 수가 3개입니다. 기존의 NeRF MLP의 경우 8개의 layer로 density를 예측하고 추가로 2개의 layer를 사용해서 Color를 예측하는데, 만약 위의 코드를 이해한 제 생각이 맞다면 layer의 수가 확연히 줄어든 것을 알 수 있습니다. 개인적으로 이러환 과정은 64x64라는 어느정도 큰 resolution을 갖고 있기 때문이라고 개인적으로 생각하고 있습니다.
Text Guidance
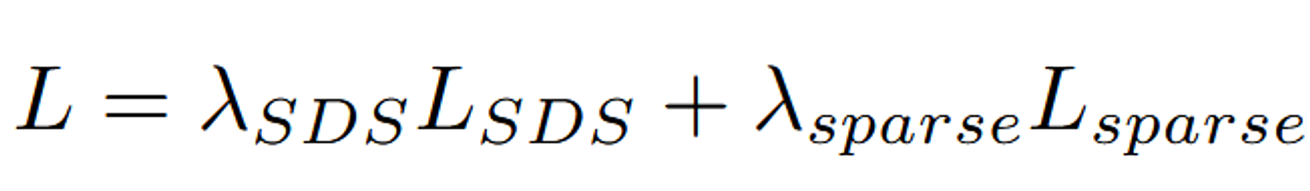
우선 부분은 위에서 Score Distillation 부분에서 자세히 설명했기 때문에 넘어가겠습니다. 간단히 언급하자면 텍스트 프롬프트를 기반으로 생성된 노이즈를 예측하면서 학습이 진행되는 과정입니다.
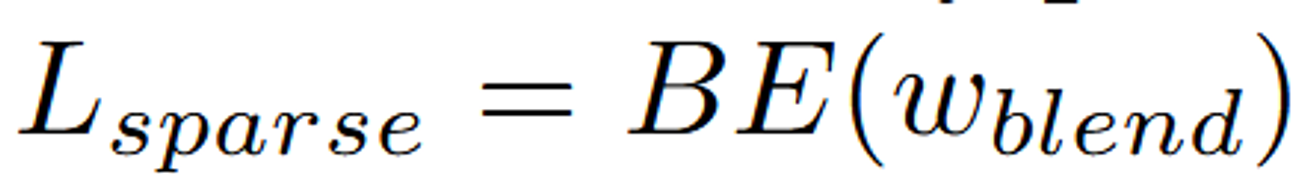
는 모델이 객체와 배경 사이의 경계를 보다 명확하게 만들도록 유도하는 역할을 합니다.
Sparse Loss는 주로 Binary Entropy를 기반으로 합니다. 이는 모델이 출력하는 마스크의 불확실성(즉, 마스크가 명확하지 않거나 일관성이 없는 경우)을 벌하는 방식으로 작동합니다.
: 여기서 wblend는 배경과 객체가 혼합된 마스크를 나타냅니다. Sparse Loss는 이 마스크가 불확실하거나 혼합된 부분을 벌주어, 모델이 명확하게 정의된 객체와 배경을 생성하도록 유도합니다.
Binary Entropy vs Binary Cross Entropy
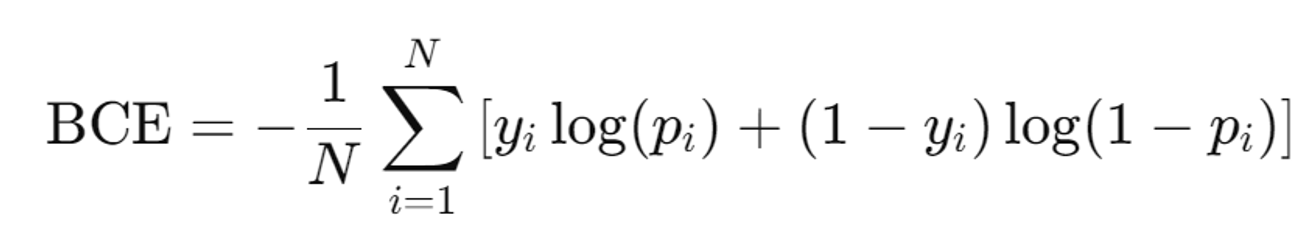
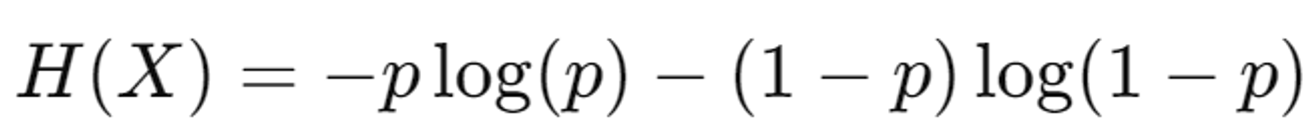
2가지의 혼동이 있을거같아 위에 간단히 수식을 적어뒀습니다. Binary Entropy가 조금더 큰 범주라고 생각하시면됩니다.
RGB Refinement
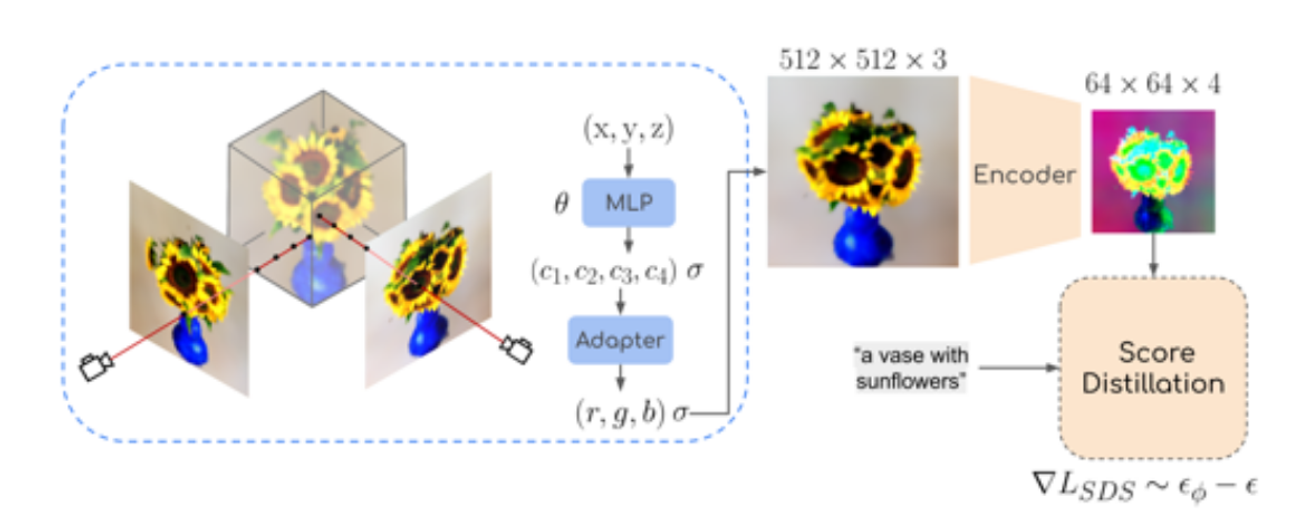
현재 NeRF 모델 자체가 기존의 Color 예측하는 형태가 아닌 4가지 latent vector를 예측하도록 되어있으므로 초기 Rendering된 이미지를 생성할 때 Adapter를 추가해줘야 됩니다.

Adapter를 위와 같은 형태로 linear layer를 initializing해주고, 이를 기반으로 finetuning이 진행됩니다.
Sketch-Shape Guidance
Sketch-Shape Guidance는 Latent-NeRF의 생성 과정을 더욱 구체화하고 제어하기 위한 방법으로, 간단한 3D 형태(구, 상자, 원기둥 등)를 사용하여 복잡한 객체의 대략적인 윤곽을 정의하는 방식입니다. 이 방식은 Latent-NeRF의 결과가 주어진 텍스트 프롬프트와 더 잘 일치하는 새로운 디테일과 Geometry를 생성할 수 있도록 하면서도, 출력되는 occupancy(밀도)가 이 간단한 3D 형상과 일치하도록 유도합니다.
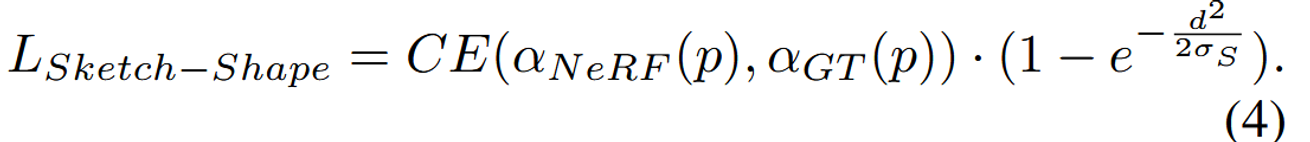
- CE: 크로스 엔트로피 손실(Cross Entropy Loss)을 의미합니다.
- αNeRF(p): NeRF에서 예측된 점 p의 밀도를 나타냅니다.
- αGT(p): Sketch-Shape에서의 기준 밀도(ground truth)를 나타냅니다.
- d: 점 p가 표면에서 떨어진 거리를 나타냅니다.
- S: 이 제약의 유연성을 조정하는 하이퍼파라미터입니다.

- 개인적인 의문: 이러한 기본적인 윤곽은 어떻게 설정할 수 있을까?
Evaluation부분에 나오는데 Blender라는 software 툴을 이용해서 사용자가 직접 그려야된다고 언급됐습니다. 따라서 inference를 할 때도 사용자가 Blender를 통해서 기본적인 윤곽을 그려야되는것 같습니다.
Latent-Paint of Explicit Shapes
일단 Latent-Paint of Explicit Shapes의 과정을 설명드리기전에 UV 텍스처에 대해서 먼저 알아보고 가겠습니다.
UV 텍스처 맵은 3D 모델의 표면을 2D 평면으로 펼친 것을 말합니다.
3D 모델의 각 점 (x, y, z)는 2D 텍스처 맵의 좌표 (u, v)와 연결됩니다. 여기서 "U"와 "V"는 2D 평면의 텍스처 좌표를 나타내며, "X", "Y", "Z"와 구분하기 위해 사용됩니다.
이 UV 맵은 텍스처(이미지 또는 색상 정보)를 3D 모델에 정확하게 적용하는 데 사용됩니다.
작동원리
- 3D 모델의 언래핑(Unwrapping):
- 3D 모델의 표면을 2D 평면으로 펼치는 과정을 언래핑(Unwrapping)이라고 합니다.
- 이 과정을 통해 모델의 각 부분이 2D 평면 상에서 어떻게 배치될지를 결정합니다. 예를 들어, 구 모양의 3D 객체를 2D로 펼치면, 여러 개의 원 또는 부채꼴 모양이 될 수 있습니다.
- 텍스처 적용:
- 언래핑된 2D 평면에 텍스처(이미지 또는 색상 정보)를 그려 넣습니다. 이 텍스처는 3D 모델의 표면에 매핑됩니다.
- 텍스처의 각 부분은 UV 맵의 해당 영역에 매핑되며, 최종적으로 3D 모델이 렌더링될 때, 이 텍스처가 모델 표면에 정확하게 적용됩니다.
- 텍스처 맵핑의 중요성:
- UV 텍스처 맵을 잘 설정하면 텍스처의 왜곡을 최소화하고, 모델의 표면에 자연스럽게 텍스처를 적용할 수 있습니다.
- 이를 통해 3D 모델의 외관이 더 사실적이고 자연스럽게 보이도록 만들 수 있습니다.
해당 모델에서 사용하는 UV 텍스처 맵은 2가지 방법으로 만들 수 있습니다. 첫번째로는 이미 입력 Mesh에 UV 텍스처 맵이 존재하는 경우입니다. 두번째로는 XAtlas와 같은 software를 이용해서 UV 텍스처 맵을 자동으로 생성하게 하는 경우입니다.
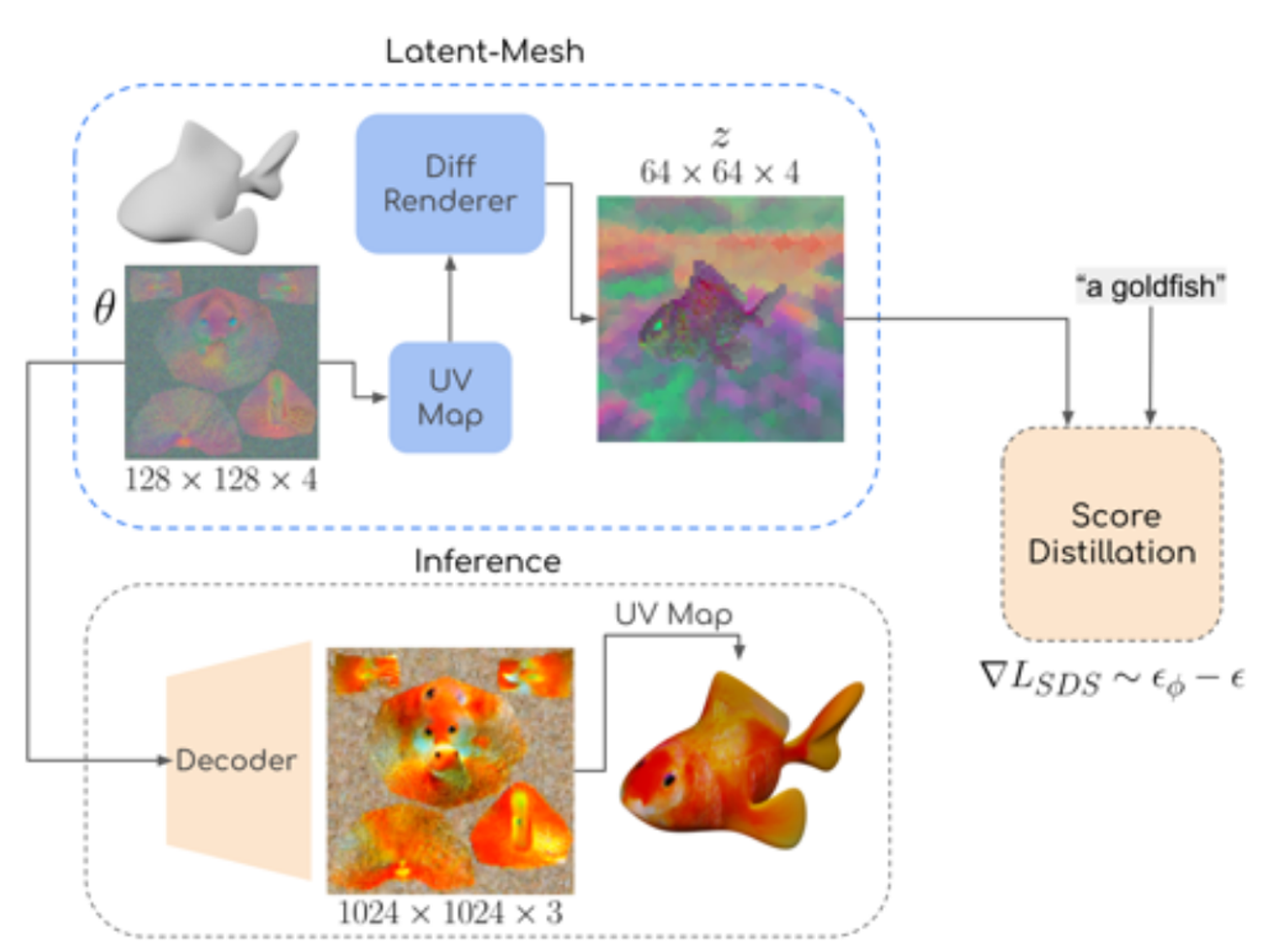
이제 다시 논문으로 돌아와서 어떻게 UV 텍스처 맵을 적용할 수 있는지 설명해드리겠습니다.
텍스처를 생성하기 위해, H × W × 4 크기의 랜덤 latent 텍스처 이미지를 초기화합니다. 이 이미지의 크기(H와 W)는 텍스처의 세부 수준(정밀도)에 따라 선택할 수 있으며, 논문에서는 이 값을 128로 설정했습니다.
Score Distillation 과정
- 각 Score Distillation단계에서, Mesh를 Differentiable Renderer(미분 가능한 Rendering)를 사용해 렌더링하여
64 × 64 × 4크기의 feature map을 얻습니다. 이 map은 초기화된 latent 텍스처 이미지에 의해 가상 색상(pseudo-colored) 처리됩니다. - 그런 다음, 이 특징 맵에 대해 Score Distillation Loss을 적용합니다. 이 Loss는 Latent-NeRF에서 적용된 것과 동일한 방식으로 계산됩니다. 하지만 NeRF의 MLP 파라미터가 아닌, deep texture image를 최적화하기 위해 loss를 back-propagation합니다.
최종 RGB 텍스처 이미지 생성
- 최종적으로, latent 텍스처 이미지를 Stable Diffusion의 Decoder를 통해 한 번 통과시켜, 고해상도의 RGB 텍스처 이미지를 생성합니다. 이 과정에서 더 큰 크기의 고품질 RGB 텍스처 이미지가 얻어집니다.
Evaluation
Text-Guided Generation
결과 설명에 앞서 정말 인상깊었던 점은, Single V100 15분이 걸린다는 점이었습니다. RGB-NeRF가 30분, DreamFusion이 1.5시간 4개의 TPU를 사용했다는 점을 감안하면 놀라운 시간 감소입니다.

위의 결과를 통해서 다양한 시점에서의 결과가 동일하게 잘 나왔다는 것을 나타내고 있습니다.

논문에서는 DreamFusion을 제외한 모델들 보다는 성능이 좋다.
DreamFusion이 해당 모델보다 성능이 좋은 이유는 LDM이 아닌 Imagen을 써서라고 언급했다. 하지만 이에 대해서 publicly되지 않아서 비교하지 못했다고 한다.

위의 사진을 통해서 RGB refinement의 성능을 입증하고 있습니다. 디테일한 부분을 조금더 잘 표현했다고 설명하고 있습니다.

위의 사진은 Textual Inversion을 통해서 Style을 추가한 방법을 나타낸 것입니다.
Textual Inversion은 특정 이미지나 스타일을 텍스트 토큰으로 학습시켜, 이후 텍스트 프롬프트에서 이를 반영할 수 있도록 하는 기술입니다. 예를들어서 왼쪽 사진의 고양이를 넣고 이에 대한 단어로 정말 말도안되는 단어(edjoaieutoi)를 생성한 후 해당 단어에 왼쪽 고양이의 style을 학습시켜두는 방법입니다. 완벽하게 적용되지는 않았지만 고양이의 형태와 특히 몸통의 색은 어느정도 반영된 것을 알 수 있습니다.
Sketch-Shape Guidance


위의 결과를 통해서 동일한 기본적인 윤곽(스케치)를 입력했을 때, 서로 다른 텍스트 프롬프트를 넣어도 최종적인 형태는 기본적인 윤곽과 비슷하게 생성되는 것을 보여줍니다.
Latent-Paint Generation

비교를 위해서 UV 텍스처 맵은 XAtlas에 의해 자동 생성되도록 했습니다.
UV 텍스처 맵이 없는 경우 XAtlas를 통해 자동 생성하고, Mesh에 이미 존재하는 경우 해당 UV 텍스처 맵을 사용하는 것입니다. UV 맵을 사용하는 것이 텍스처의 세밀함을 유지하고 다른 응용 프로그램과의 호환성을 높이는 데 더 유리합니다.
Limitations
- Prompt Tweaking(DreamFusion에서 사용한 방법으로 텍스트 프롬프트에 특정 방향(예: "front", "side")을 추가한 것)과 같은 기법을 사용해도 모든 객체에서 성공적이지 않을 수 있으며, Stable Diffusion 모델 또한 방향을 지정한 이미지 생성에서 한계를 보일 수 있습니다.
- 결과가 무작위성을 띄기 때문에, 동일한 설정으로도 결과물이 달라질 수 있습니다. 이로 인해 결과의 일관성을 유지하는 것이 어려울 수 있습니다.
Conclusion
- 해당 논문에서 처음으로 score distillation 방법을 LDM에 적용했습니다.
- 다음으로 Shape-guided(Sketch-Shape, Latent-Paint)방식을 생성 모델에 적용했습니다.
- 가장 중요한 부분으로는 RGB-space가아닌 latent-space에서 NeRF를 작동시킨 점입니다.
