CameraHMR: Aligning People with Perspective [2025 3D Vision]

2D 이미지에 있는 사람들에 대해서 정확한 부피의 3D human 정보를 얻을 수 있는 CameraHMR 논문에 대해서 리뷰해보도록 하겠습니다.
논문에서 진행한 점은 크게 2가지 입니다.
- 다양한 사람 데이터셋을 확보해서 2D 이미지의 정확한 filed of view(FOV) 구하기
- DenseKP라는 네트워크를 통해서 몸 전체 표면의 138개의 키포인트 검출
Method
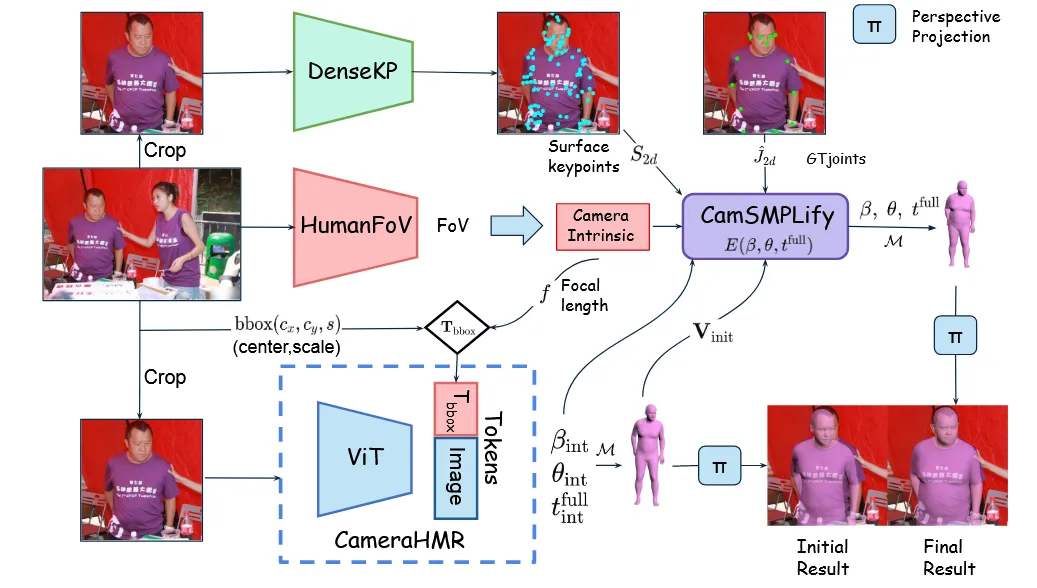
Preliminaries
3D 정보가 2D로 투영될 때 3가지 가정을 기본으로 시작합니다.
- 렌즈 왜곡 없음
- 이미지 중심 = 카메라 중심
- R = I(회전이 없음)
다음으로 이미지를 측정할 때 focal length 값 대신 fov를 사용합니다. 실제로 같은 focal length 값을 갖더라도 fov 값에 따라서 물체의 크기가 바뀌기 때문입니다. 논문에서 사용하는 값은 수직(vertical) fov(υ)입니다.
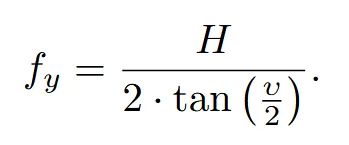
Focal length()는 fov(υ)와 이미지의 높이(H)로부터 위의 수식을 통해서 얻을 수 있습니다.
SMPL: 사람이 취할 수 있는 다양한 포즈와 체형을 수학적으로 표현하는 3D 모델
- θ: 관절의 회전 → 사람의 자세
- β: 체형에 대한 고유값(10차원 벡터) → 사람의 몸매
- 6890개의 Vertices & K개의 주요 관절 위치 추출
HumanFoV
입력 이미지는 HxWx3의 차원을 갖고 있습니다. 이 이미지를 256x256 정사각형으로 비율을 유지하면서 resize하기 위해서 작은 변의 길이를 256으로 맞추고, 큰 변은 비율을 유지하면서 줄인 뒤 zero-padding 합니다. 이렇게 입력 이미지의 형태를 통일 시켜서 더 정확한 fov를 예측할 수 있도록 합니다.
정규화된 이미지는 HRNet을 통해서 feature로 변환되고, feature는 MLP를 통해서 vertical fove()으로 변환됩니다.
FoV 값을 덜 예측하는 것은 3D 포즈에 별로 큰 문제가 없지만, 과도하게 예측할 경우 3D 결과가 망가집니다.
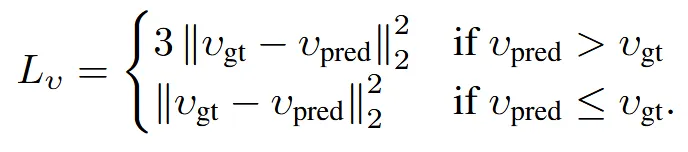
따라서 위와 같은 loss function으로 과도하게 예측했을 경우 3배의 패널티를 주게 loss를 설계 했습니다.
Epoch 16 & 64 batch size & learning rate & Adam & augmentation(flipped horizontally with a probability of 0.2)
CameraHMR
3D 사람 예측(HPS)는 ResNet → HRNet → ViT처럼 모델 구조가 점점 진화할수록, 더 정밀한 3D 예측이 가능해졌습니다. 해당 모델에서는 ViTPose를 backbone으로 사용했습니다. 이는 HMR2.0에서 사용한 backbone과 동일합니다.
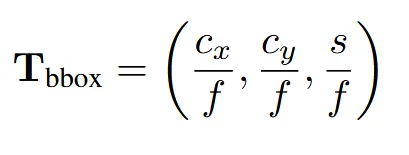
이미지에 대한 정보뿐만아니라 추가적으로 FoV 정보와 bounding box를 추가로 입력합니다. CLIFF에서 사용한 것처럼 위의 가 추가적인 입력으로 들어갑니다. f는 focal length, 와 는 bounding box, s는 scale을 의미합니다. 여기서 bounding box는 training 시에는 ground truth가 존재하고, inference시에는 detectron2를 사용해서 추출합니다. Focal lenth도 마찬가지로 training시에는 ground truth가 존재하고, inference시에는 HumanFoV 결과를 이용합니다.
CamSMPLify
4DHumans dataset에서 기존의 방법에서 여러가지 정확한 카메라 정보가 반영된 full perspective 기반으로 업그레이드 됩니다. 해당 데이터셋에는 COCO, MPII, AI Challenger, AVA 데이터셋이 합쳐져있습니다. AVA 데이터셋의 경우 화면 비율이 가로로 과장된 경우가 많기 때문에, 논문에서 가장한 fx = fy 조건을 깨트립니다. 따라서 AVA 데이터셋은 제거했습니다.
Camera Intrinsics
실세계의 이미지들은 intrinsic camera parameter의 ground truth를 갖고 있지 않습니다. 이러한 정보 없이 3D body를 2D keypoints에 매핑하기는 어렵습니다. 해당 논문에서는 HumanFoV를 통해서 fov 값을 얻을 수 있고, 수식을 통해서 이에 대응하는 focal length도 얻을 수 있습니다. 따라서 모든 데이터에 대해서 카메라 파라미터들을 통해서 더 정확한 결과를 얻을 수 있습니다.
Surface Keypoints(DenseKP)
기존 4DHumans 데이터셋은 17개의 2D 관절 위치만 제공하므로, 몸 전체의 곡면이나 형태를 정밀하게 표현하기에는 한계가 있습니다. 이러한 한계를 극복하기 위해 논문에서는 DenseKP라는 모델을 새로 개발하여 138개의 조밀한 표면 키포인트(dense surface keypoints)를 예측합니다. DenseKP는 합성 데이터셋인 BEDLAM과 AGORA를 활용해 학습되며, 다양한 체형과 정확한 3D 주석 정보를 포함한 데이터를 기반으로 합니다.
DenseKP의 백본으로는 ViTPose가 사용되며, 입력은 사람 중심으로 잘라낸 256×256 크기의 이미지 crop입니다. 키포인트의 ground truth는 SMPL 메쉬의 총 6890개 vertex 중에서 곡률이 큰 부분(high-curvature regions)을 우선적으로 138개만 선택(down-sampling)하여 생성됩니다. 이러한 선택은 COMA 방식을 참고하여, 체형을 잘 표현할 수 있는 주요 구조적 특징을 보존하도록 합니다.
모델은 예측한 키포인트와 ground truth 간의 L2 손실 함수를 기준으로 학습되며, 학습된 DenseKP는 4DHumans 전체 이미지에 적용되어 dense 키포인트를 생성합니다. 이후 SMPLify는 기존의 17개 관절 정보와 함께 이 138개 키포인트를 사용하여, 더 정밀하고 사실적인 3D 피팅을 수행할 수 있게 됩니다.
Initialization
초기값이 중요하기 때문에 BEDLAM + AGORA를 이용해서 CamerHMR을 학습합니다. 이후 이 모델로 4DHumans 데이터에 대한 초기 포즈, 체형, 위치를 생성합니다.
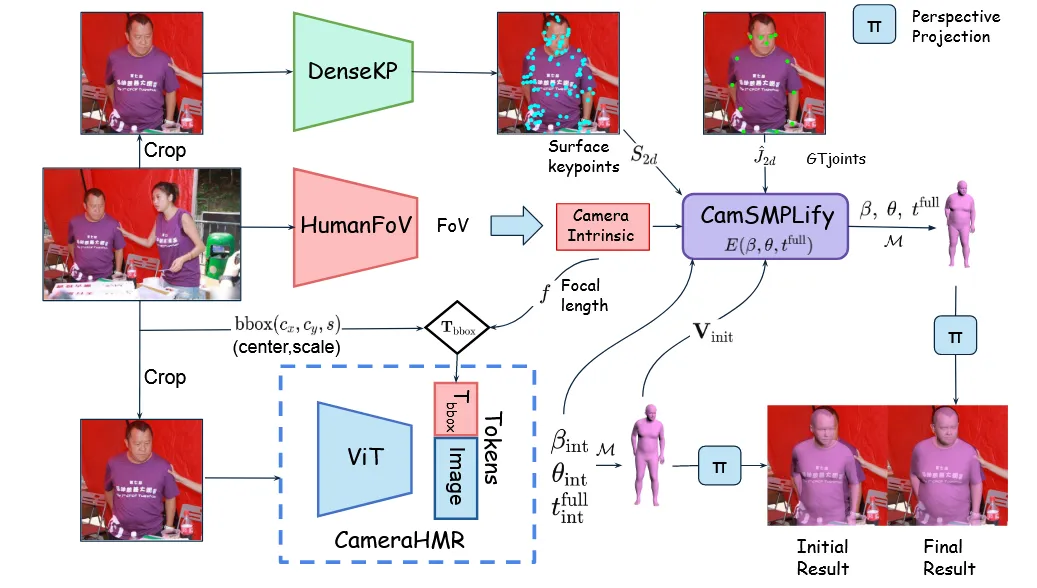
위의 사진을 보면 CamSMPLify의 입력값으로 들어가는 와 , , 의 값을 사용합니다. 참고로 CamSMPLify는 SMPLify fitting 프로세스를 개선한 최적화 기반 알고리즘입니다. 주어진 keypoints(관절)에 맞춰 3D SMPL파라미터(포즈, 체형,위치)를 예측합니다.
Losses
| 기호 | 의미 | 차원 / 타입 | 생성 출처 또는 계산 방식 |
|---|---|---|---|
| θ | SMPL 포즈 파라미터 (pose) | ℝ⁷² | 예측 or 최적화 대상 |
| β | SMPL 체형 파라미터 (shape) | ℝ¹⁰ | 예측 or 최적화 대상 |
| V | 현재 추정한 SMPL 메쉬 (vertices) | ℝ⁶⁸⁹⁰׳ | M(θ,β)를 통해 생성 |
| CameraHMR이 예측한 초기 메쉬 | ℝ⁶⁸⁹⁰׳ | ||
| 3D 관절 위치 | ℝᴷ׳ (K=17) | SMPL 메쉬에서 추출 | |
| 예측된 2D 관절 위치 (투영 후) | ℝᴷײ | ||
| Ground-truth 2D 관절 위치 (데이터셋 제공) | ℝᴷײ | 4DHumans 제공 값 | |
| 3D 표면 키포인트 (dense) | ℝ¹³⁸׳ | SMPL 메쉬에서 downsample | |
| 예측된 2D 표면 키포인트 | ℝ¹³⁸ײ | ||
| Ground-truth 2D surface keypoints | ℝ¹³⁸ײ | DenseKP에서 예측 | |
| SMPL 메쉬의 글로벌 위치 (translation) | ℝ³ | 최적화 대상 | |
| CameraHMR이 예측한 초기 translation | ℝ³ | 초기값 |
각 기호가 어떤 의미인지 위에 작성했으니 이를 기반으로 아래 설명을 참고하면 됩니다.
- 와 를 기반으로 θ와 β를 학습합니다.
- CamerHMR이 만든 초기 메쉬 는 regularization prior로 사용됩니다.

- : 예측된 2D surface keypoints(138)와 ground truth의 L2 Loss
- : 예측된 2D 관절 위치(17)와 ground truth의 L2 Loss
- : 정규화 항
사실 지금까지 잘 따라왔다면 CameraHMR에 ground truth 값이 들어가는데 어떻게 inference에 사용하지? 라는 의문이 생길 것 입니다. 논문에서는 이렇게 training시에 학습하다보면 자연스럽게 CameraHMR도 학습된다고 언급했습니다.
Iteration
| 단계 | 설명 |
|---|---|
| v1 모델 | BEDLAM 기반으로 학습된 초기 CameraHMR |
| 1차 CamSMPLify | v1의 출력으로 4DHumans 400만 이미지 fitting (280만 성공) |
| → CameraHMR v2 | 위 280만 + BEDLAM으로 학습 |
| 2차 CamSMPLify | v2 출력으로 다시 초기화 → 더 많은 이미지 성공적으로 fitting (320만) |
| 반복 목적 | 더 정밀한 pGT로 모델 성능 개선 + 데이터 커버리지 확대 |
CameraHMR와 CamSMPLify의 값을 비교해서 일정 임계치보다 큰 경우는 품질 불량으로 제거합니다. 이렇게 해서 400만개의 이미지 중 좋은 품질 280만개를 얻습니다. 280만개와 다시 ground truth BEDLAM 데이터를 함께 사용해서 v2를 학습합니다. V2의 경우는 좋은 품질이 320만개가 됩니다. 이렇게 iteration을 반복하면 더 정밀한 pGT를 얻을 수 있습니다.
Result
