CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Calibration [SIGGRAPH 2024]
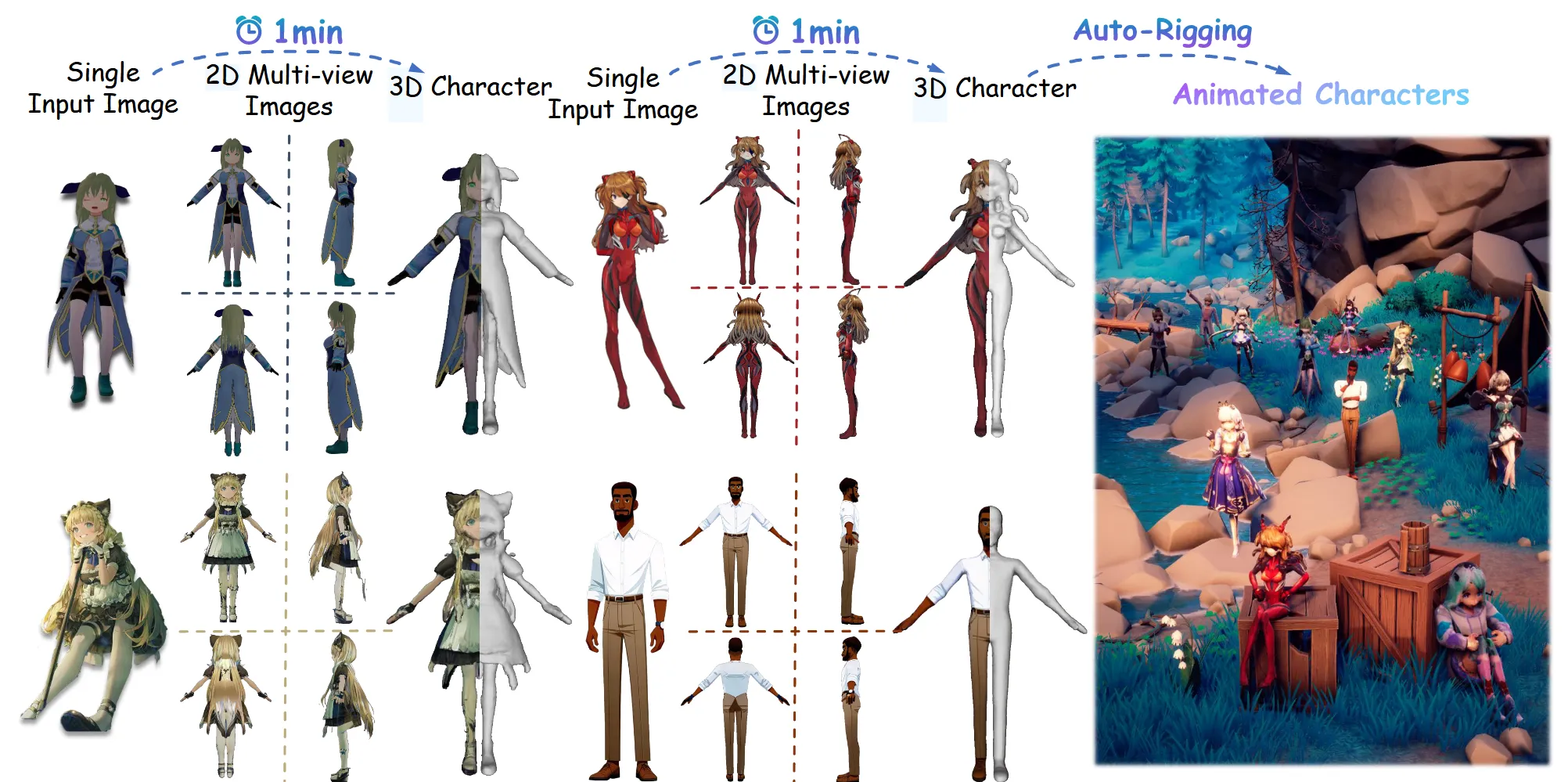
선별된 애니메이션 데이터 13,746으로 학습을 해서 캐릭터에 특화된 결과를 뽑을 수 있는 모델입니다. 1분내에 전체 파이프라인이 끝날정도로 굉장히 빠르고 단순합니다. 위의 결과에서 보이는 것처럼 모든 output은 canonical pose(정식 포즈)로 A자 모양을 띄고 있습니다. 어떻게 모델이 이렇게 좋은 결과를 낼 수 있었는지 한번 알아보도록 하겠습니다.
Method
Anime3D Dataset
3D 캐릭터를 더 잘 이해하고 Janus 이슈를 해결하고자 논문에서는 13,746개의 데이터셋 Anime3D를 구축했습니다. 데이터는 VRoidHub에서 14,500개의 anime 캐릭터를 얻고, non-humanoid data를 제거했습니다.
3D 데이터를 2D로 변환하기 위해서 three-vrm(https://github.com/pixiv/three-vrm) 방식을 사용했습니다. A-pose를 얻기 위해서 왼쪽과 오른쪽 팔의 joint rotation을 Z축에 대해서 45도로 정하고, 다리는 Z축을 기준으로 6도로 정했습니다.
입력으로는 Random pose가 들어가야 학습이 가능합니다(입력도 출력도 A-pose이면 학습할게 없으니까). 따라서 입력으로 들어갈 Random pose는 Mixamo에서 10개의 사람 애니메이션(sitting, walking, singing..)중 하나를 선택합니다.
캐릭터의 bounding box에 대해서 로 정규화를 진행합니다. FoV는 40, 카메라 거리는 1.5, 렌더링할 때 ambient light and directional lighting를 사용합니다.
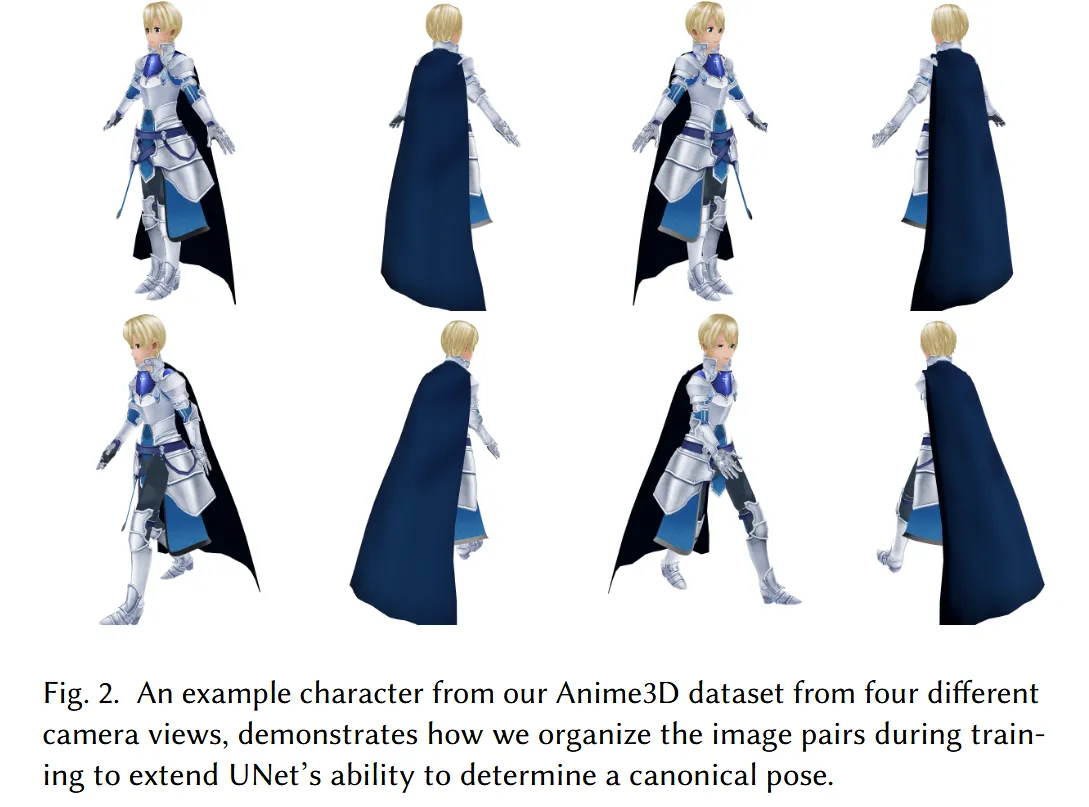
모델은 기본적으로 (0,90,180,270)의 pose를 이용해서 학습하지만, roubust를 위해서 랜덤한 시점에서 시작한 3개 그룹을 추가합니다(예:30,120,210,300). 위의 사진이 랜덤한 방위각에서 시작해서 90도만큼 차이를 시각화한 그림입니다.
방금 3개의 그룹은 고도는 0도가 기존과 동일한데 마지막으로 추가한 4개의 이미지는 방위각 뿐만아니라 고도도 랜덤으로 해서 모델의 일반화를 도울 수 있도록 데이터셋을 준비합니다.
Multi-view Image Generation and Pose Canonicalization
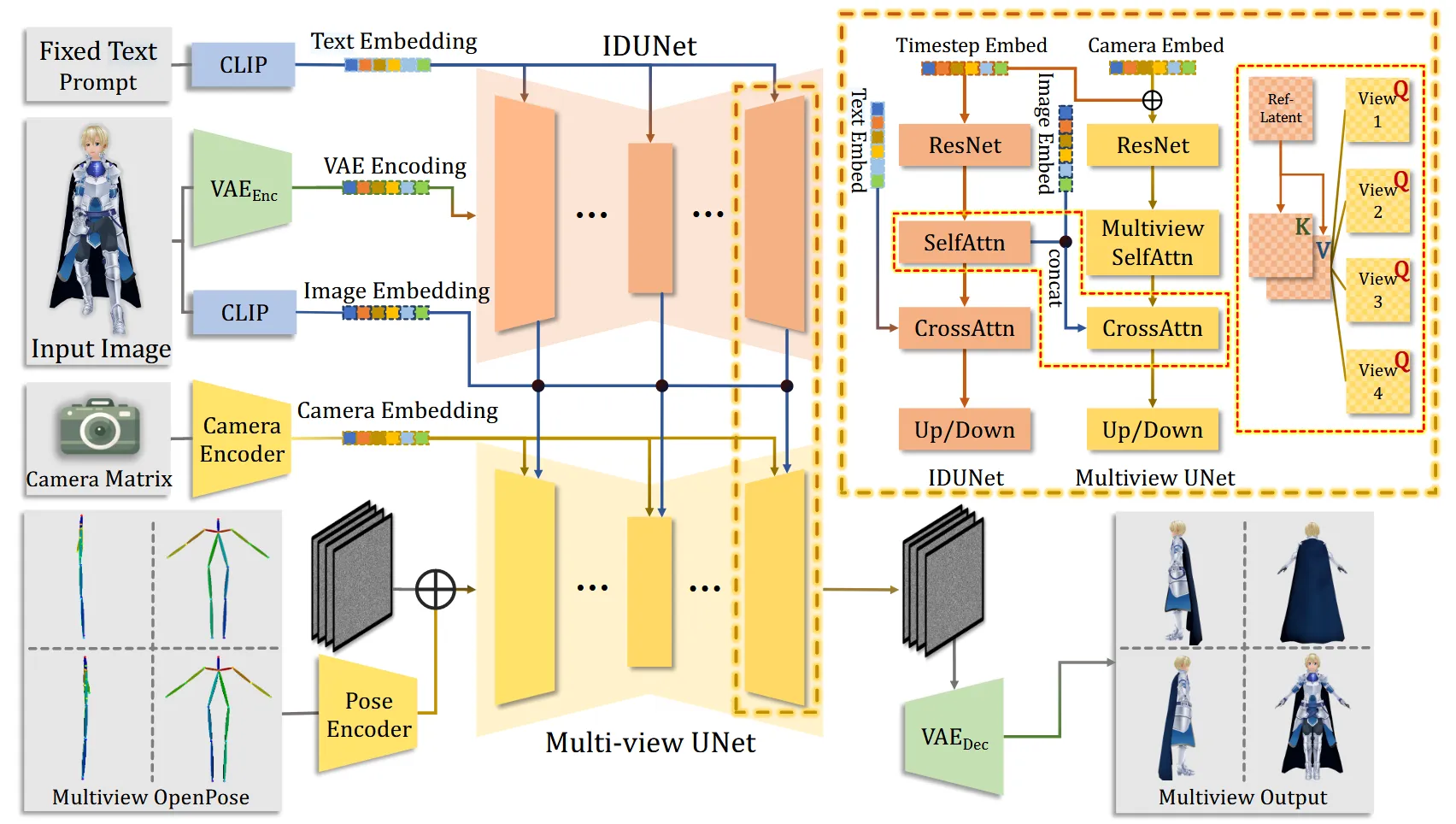
모델의 전체적인 아키텍처입니다. 하나씩 자세히 설명해드리겠습니다.
IDUNet
IDUNet은 입력 이미지로 부터 A-pose 4개의 consistency한 이미지를 얻는 것을 목표로 합니다.
기존의 IP-Adapter는 다음과 같은 문제를 갖고 있습니다.
| 문제 | 설명 |
|---|---|
| 전역 정보만 사용 | CLIP으로 추출한 "이미지 전체 특징 벡터(embedding)"만 사용함 |
| 픽셀 단위 정보 손실 | 머리카락, 옷무늬, 눈동자 등 세부 디테일이 무시됨 |
| 결과 이미지 일관성 낮음 | 멀티뷰 이미지 간에 텍스처, 색, 위치가 미묘하게 불일치함 |
IP-Adapter의 문제를 극복한 IDUNet과 기존 방식을 비교해보도록 하겠습니다.
| 항목 | IP-Adapter | IDUNet |
|---|---|---|
| 입력 방식 | CLIP의 전역 벡터 | 이미지의 patch-level 특징들 |
| 통합 방식 | CLIP embedding을 UNet 내부에 덧셈(add) | cross-attention으로 상호작용 |
| 데이터 흐름 | 전역 조건 → 전체 latent에 전달 | 조건 이미지의 지역적 정보가 직접 latent와 상호작용 |
| 학습 방식 | 기본 diffusion만 학습 | IDUNet도 함께 joint 학습함 |
나머지 부가적인 부분들은 아래에 자세히 설명해드리겠습니다.
Fixed text-prompt: best quality라는 text prompt 고정
VAE Encoder: 입력 이미지를 노이즈 없는 latent로 인코딩
CLIP Encoder: 입력 이미지의 global embedding 추출
Multi-view UNet Condition: IDUNet의 출력 + CLIP feature
전체적인 기능을 요약하면 다음과 같습니다.
- VAE의 latent를 입력으로 받아서 패치 단위로 나눕니다.
- Best quality라는 prompt를 condition으로 사용해서 UNet 구조로 feature를 추출합니다.
- 추출된 feature와 입력이미지의 clip 임베딩값을 concat해서 Multi-view UNet의 condition으로 활용합니다.
Multi-view Unet
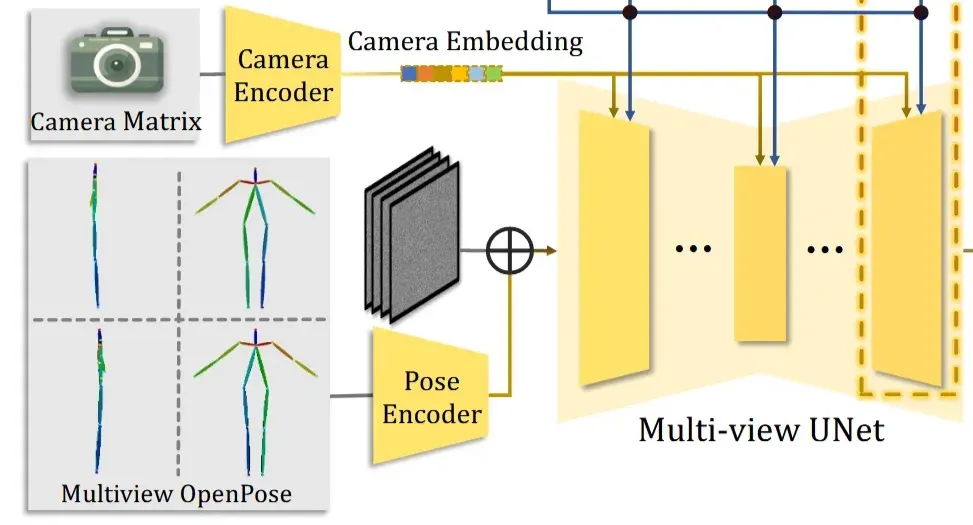
입력으로 들어가는 Multiview OpenPose는 OpenPose의 Pose Encoder를 통해서 latent로 변환되고, 여기에 노이즈를 추가하면 ()를 얻습니다. Multi-view Unet은 MVDream의 stable diffusion 2.1버전의 모델을 가져왔습니다.
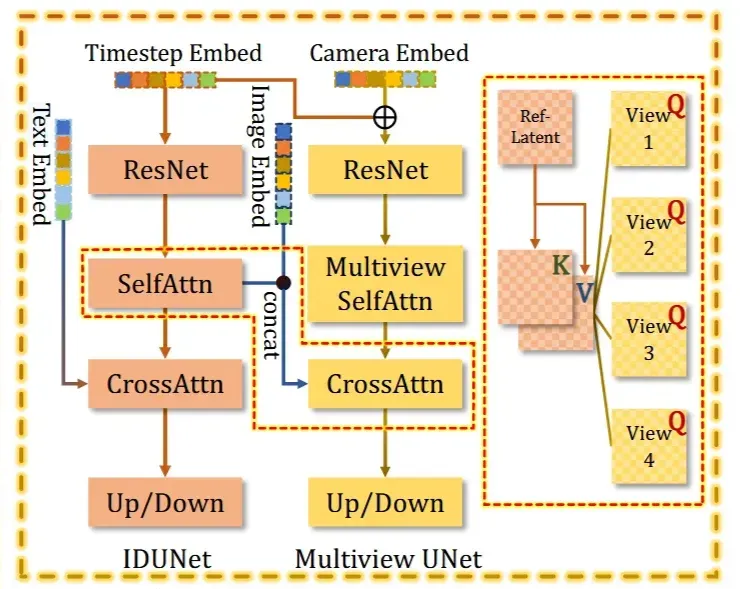
Condition은 2가지 값이 들어갑니다. 첫번째로 Camera Matrix 정보가 담긴 Camer Embedding, 두번째로 이전에서 구한 IDUNet의 결과와 CLIP임베딩을 concat한 가 들어갑니다. Camera Embedding 값은 Self-attention으로 positional 가이드를 제공하고, 정보는 Cross-attention으로 어떤 외형을 따라가야 하는지에 대한 가이드를 제공합니다.
기존 UNet은 노이즈를 예측하는 모델들이 일반적이지만, CharacterGen에서는 UNet이 velocity를 직접 예측하도록 설계 됐습니다. loss를 계산할 때는 velocity가 노이즈로 변환됩니다.
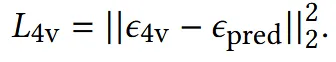
변환된 노이즈는 forward pass를 통해서 나온 노이즈와 비교하면서 loss를 구성하게 됩니다.
Pose Canonicalization
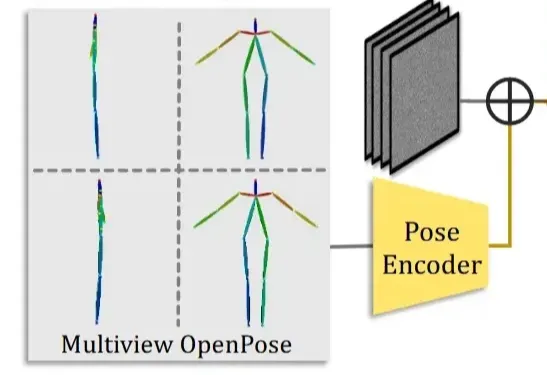
Pose를 A자로 정규화하기 위해서 OpenPose의 데이터를 적용합니다. Pose Encoder를 통해서 얻은 pose embedding 값은 noise latent에 바로 더해지게 됩니다. 캐릭터들이 다양한 형태(몸매)를 가질 수 있기 때문에 3가지 데이터셋의 OpenPose를 준비하고 CLIP Score가 가장 높은 데이터셋을 선택하도록 합니다.
3D Character Generation
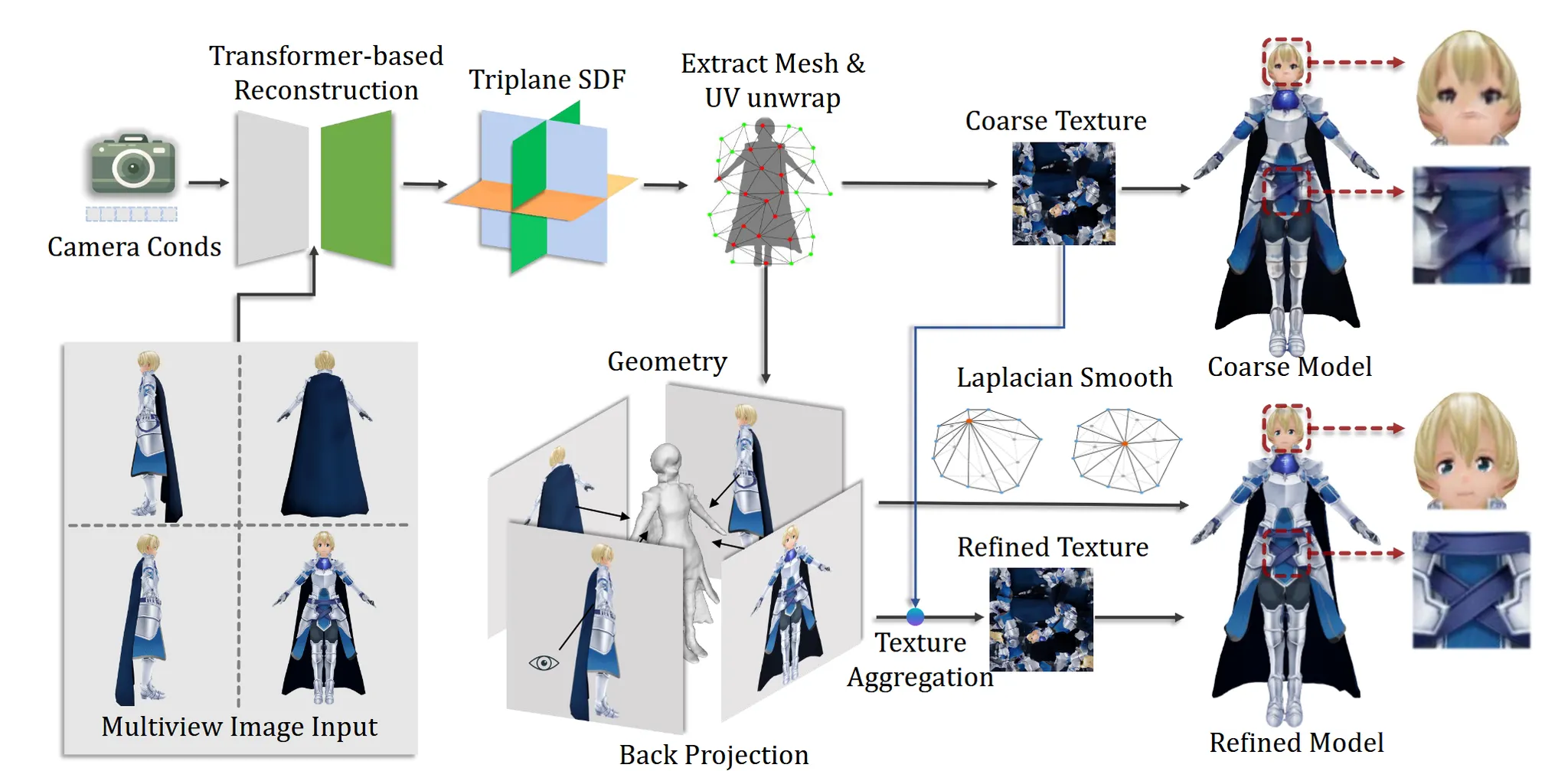
이제 4가지 뷰의 이미지를 기반으로 어떻게 3D를 생성하는지 설명하도록 하겠습니다.
Character Reconstruction with Coarse Texture
Baseline 모델은 LRM(Large Reconsturcion Model for Single Image to 3D) 모델을 사용했습니다.
Objaverse 데이터셋으로 pre-train을 진행하고, Anime3D 데이터셋으로 fine-tuning을 진행했습니다.
LRM에서 사용한 Triplane NeRF 방식만을 사용했지만, 이는 noisy surface geometry를 야기할 수 있습니다. 이후에 density를 예측하는 decoder를 SDF를 예측하는 decoder로 수정해서 더 smoother하고 precise한 surface geometry를 얻을 수 있도록 했습니다.
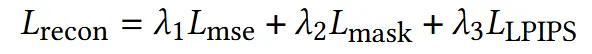
기존 MSE Loss와 더불어서 ground truth alpha mask와 렌더링된 alpha mask를 비교하는 mask Loss, 입력 이미지의 perceptual information을 추출하는 LPIPS Loss들을 추가했습니다. 은 각각 1, 0.1, 0.5를 default 값으로 정했습니다.
3D Character Refinement
DMTet을 이용해서 마지막 mesh에서 coarse UV map과 explicit mesh를 얻을 수 있습니다. UV unwrapping 과정에서 appearance가 손실되기 때문에 텍스처 디테일이 부족합니다.
생성된 4개의 이미지들을 NvDiffRast 모델을 이용해서 다시 3D mesh로 back project시켜서 texel에 실제 RGB를 입혀줍니다. 이때 texture의 해상도가 4개의 이미지들보다 높기 때문에 여러 texel이 하나의 이미지 픽셀에 매핑되면서 noise가 발생합니다.
이를 해결하기 위해서 4가지 해결책을 제시했습니다.
- Depth Test로 occlusion 제거
각 뷰에서 찍은 픽셀을 texel에 매핑할 때, z-buffer 기반 depth check를 수행
- 실루엣 제거 필터링
카메라 시야 벡터와 texel normal map의 내적을 계산해서 -0.2보다 큰 경우 제거. 즉, 카메라를 비스듬히 스친 실루엣 부근 texel은 제외
- 여러 뷰가 덮이는 texel
동일한 texel이 여러 RGB 후보가 있을 경우, coarse texture와 가장 가까운 RGB 선택
- Poisson blending
Seam을 제거하기 위해서 Poisson image editing으로 자연스럽게 블렌딩
Experiments
Results and Comparison
2D Multi-view Generation
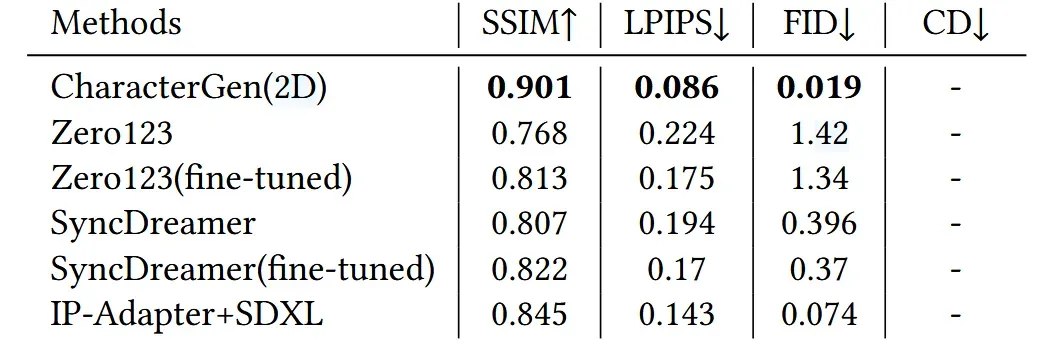
2D상에서는 Zero123와 SyncDreamer 모델과 비교를 진행했습니다. 기본 모델과 Anime3D 데이터셋으로 fine-tuned한 결과에 대해서 모두 비교를 진행했습니다. 결과적으로 CharacterGen의 성능이 가장 좋은 것을 확인할 수 있습니다.
추가적으로 IP-Adapater-SDXL(SD2.1버전이 없다)과의 비교도 진행했습니다. SDXL-base 모델에 대해서 2x2 grid 캐릭터 이미지(4개의 뷰)에 대해서 100 epoch 학습을 진행하고, IP-Adapter-SDXL을 추가한 결과보다 ChracterGen의 성능이 더 좋은 것을 확ㅇ니할 수 있습니다.


3D Character Generation.

3D상에서는 ImageDream과 Magic123와의 비교를 진행했습니다. 맨오른쪽 지표 cD(Chamfer Distance)가 낮을수록 더 정확한 reconstruction이 가능합니다. 따라서 CD값이 낮을수록 Janus 문제를 해결했다고 할 수 있습니다.
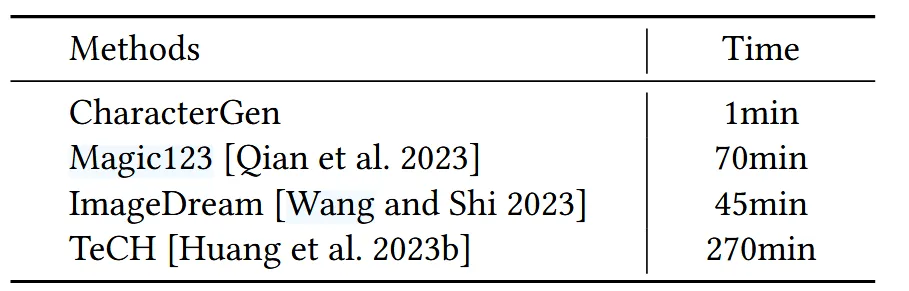
결과를 뽑는 속도도 비교했을 때 압도적으로 CharacterGen이 빠른것을 알 수 있습니다.

Ablation Study
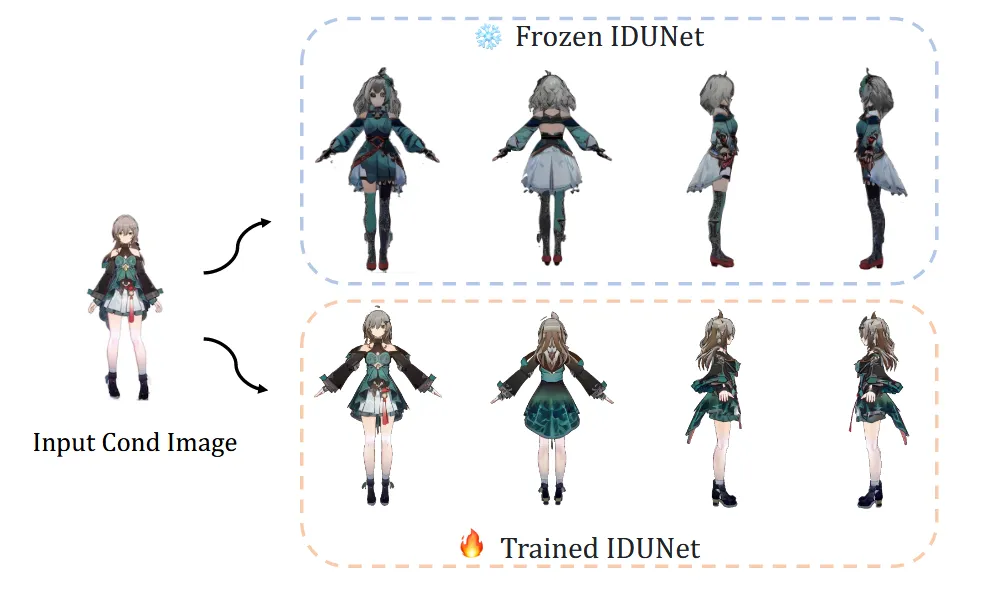
IDUNet의 Frozen하고 결과를 뽑아봤을 때 입력 이미지의 feature를 충분히 보존하지 못하는 것을 확인할 수 있습니다.
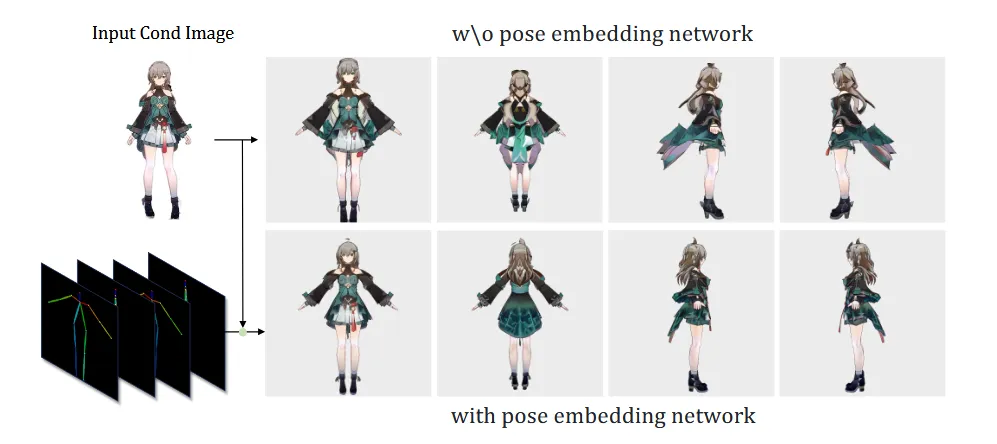
Pose Embedding network를 제거한 결과 생성된 이미지가 중앙에 위치하지않고, 옷 부분이 입력 이미지와 일치하지 않는 것을 알 수 있습니다.
Limitations
입력 이미지가 극단적인 포즈를 하고 있거나, 비정상적인 시점이라면 멀티뷰의 결과가 좋지 않습니다. 이후에 non-photorealistic rendering(NPR) 기술을 texture refinement 단계에서 추가함으로서 texture 퀄리티를 향상시킬 것임.
Multi-view Unet에 SDS를 추가하면 더 좋은 geometry를 얻을 수 있다.(시간은 더 걸린다!)
