Joint Learning of 3D Shape Retrieval and Deformation[CVPR 2021]
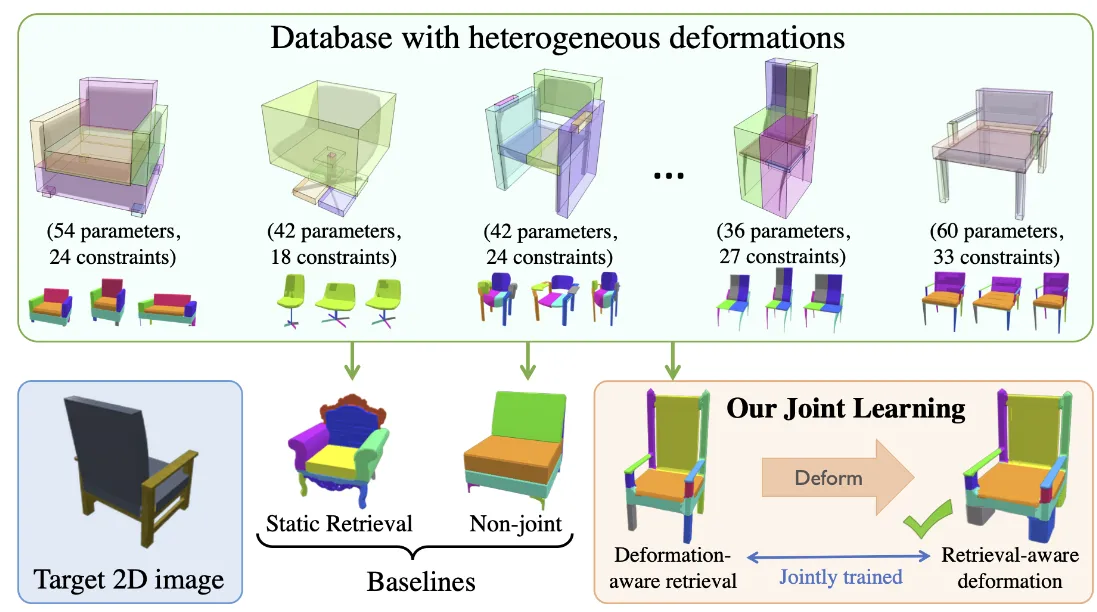
입력 이미지를 넣으면 이와 비슷한 3D data를 찾는 Retreival과, 이를 2D image에 유사하게 Deformation 하는 과정이 상호 작용하면서 좋은 3D generation을 할 수 있는 논문입니다.
Method
모델은 2D image와 유사하면서 Deformation하기 적합한 source 모델을 꺼내오는 Retreival 과정과 꺼내온 source 모델을 실제 타겟 형태에 맞게 변형하는 Deformation 과정을 joint learning 시키는 방식입니다.
Joint Deformation and Retrieval Training
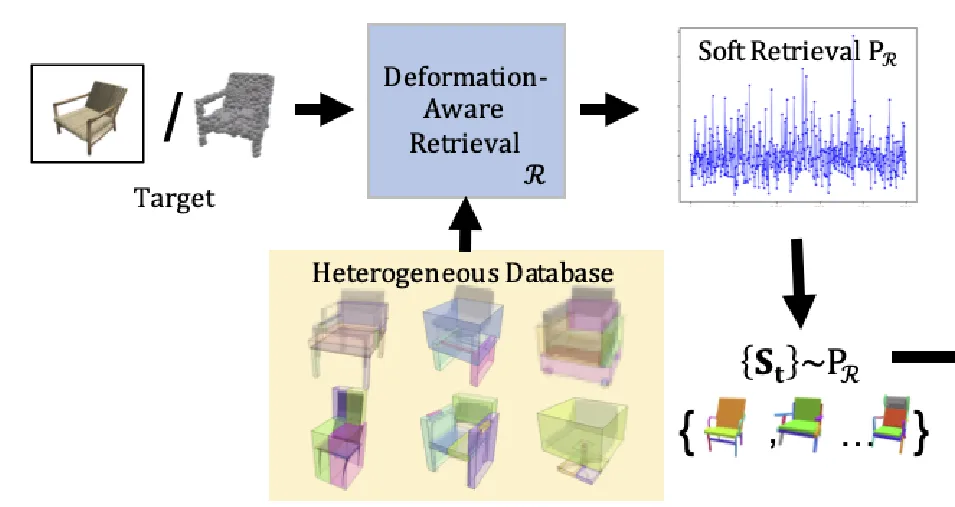
Soft Retrieval for Training
Target 2D image의 임베딩과 Database에서의 임베딩 값을 비교해서 가장 유사한 3D source model을 하나만 선택하는게 아니라 여러 후보를 선택하는 Soft Retrieval 방식을 선택합니다.
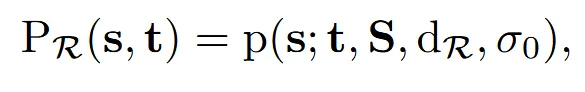
위의 식은 target(t)에 대해 소스(s)가 변형에 적합할 확률을 나타낸 것입니다.
- S: Source databse
- : Retrival 임베딩 공간에서 계산한 s와 t사이의 거리
- : 분포의 퍼짐 정도(상수 100)
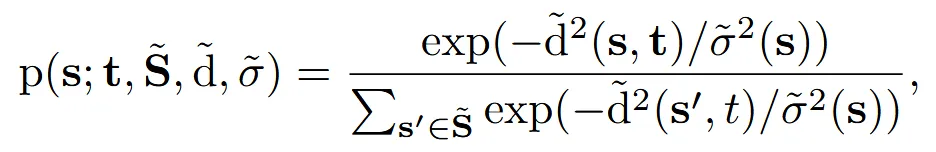
- 이전 식을 자세히 보면 source와 target 거리를 softmax 정규화를 진행한 것을 알 수 있습니다.
- 값은 s에 따라서 바뀔 수 있지만, 실험적으로 100으로 고정해서 사용
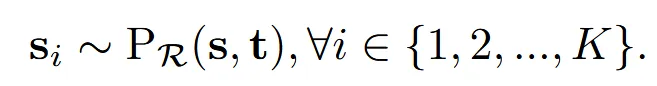
- 위의 수식을 통해서 얻은 K(10)의 source model들을 선택
- 여러개의 source를 얻었기 때문에 초기에 편향 없이 폭넓게 학습 가능
- 따라서 retrieval 상에서는 안 맞아 보이는 모델이, Deformation 과정에서는 좋은 모델이 될 수 있는 경우에 대해서도 학습을 통해서 알 수 있습니다.
Training
Retrieval 학습
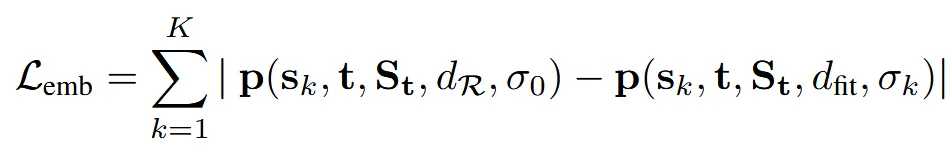
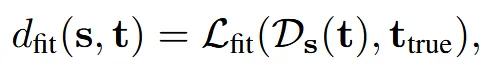
첫번째로 target(t)과 source model(s)의 임베딩을 계산합니다. 이후 soft retrieval 확률 계산 했던 방식으로 두 임베딩의 거리에 대해서 softmax를 취한 값을 얻습니다.
실제로 source를 target에 맞게 변형한 뒤 이에 대해서 다시 soft retrieval에서 사용했던 수식으로 값을 얻고, 이에 대해서 비교하는 수식이 위의 첫번째 값이 됩니다. 따라서 Loss의 왼쪽 부분은 source와 target간의 거리, 오른쪽 부분은 source가 target에 맞게 변형된 이후 target과의 거리 입니다. 2개의 차이가 클수록 변형이 어려운 source model이라는 정보를 얻을 수 있습니다.
Deformation 학습
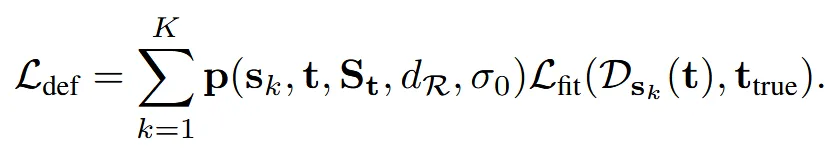
위에서 구한 Retrieval 확률을 가중치로 사용합니다. 확률이 높은 source일수록 실제 chamfer 오차를 더 크게 줄이도록 학습시키는 효과가 있습니다. 즉 주로 선택될 소스에 더 많은 학습 비중을 두는 것 입니다.
Inner Deformation Optimization
더 정교한 deformation 과정을 진행합니다. 이전에 학습한 네트워크 가중치에 대해서, 파라미터 자체를 움직여서 최적의 를 얻습니다. 이후 방금 구한 과 이전에 구한 과의 least-square error로 최적의 파라미터를 구합니다.
Structure-Aware Neural Deformation
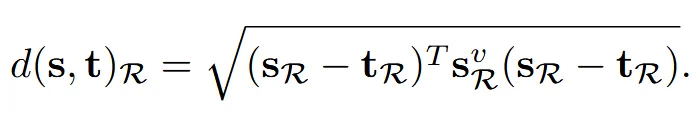
Source model에 대해서 Part을 얻는 과정을 먼저 진행합니다. 여기서 말하는 Part는 segmentation 결과라고 생각하시면 되는데, 그림에서 색깔로 구분되어 있는 각 부분들입니다. 예를들어서 의자면 등받침대, 팔걸이, 다리 이렇게 구분이 될 것입니다. Part를 수동적으로 얻을 때는 PartNet 방식을, 자동적으로 얻을 때는 ComplementMe 방식을 사용합니다.
이후 source model 전체를 표현하는 global code(), 파트 별로 표현된 local code(), target code() 3개의 임베딩을 concat해서 MLP를 통과시킵니다. Point cloud는 PointNet을, image는 ResNet을 사용해서 target code를 얻습니다. global과 target code의 차원은 256, local code의 차원은 32로 실험적으로 설정했습니다. MLP의 경우 (512,256,6)의 차원을 갖도록 설계 했습니다. Global과 local code는 auto-decoder를 학습해서 얻도록 설계 했습니다.
가구들이 대부분 대칭적인 형태이기 때문에 symmetry loss를 추가했습니다.
Connectivity Constraints
Part간에 원래 접촉 관계를 유지하기 위한 선형 제약을 두는 부분입니다. 예를들어서 의자의 앉는 부분과 의자 다리는 항상 붙어있는데 변형 이후에 떨어질 수 있다는 문제점이 존재합니다.
따라서 각 접촉 쌍 (i,j)에 대해, 부품 i와 j가 원래 접촉하던 점들 사이의 거리 변화가 0이 되도록 수식화합니다. 같은 형태로 선형 제약을 줄 수 있습니다.
Retrieval in Latent Space
여기서는 Retrieval에 대해서 더 자세히 설명하는 과정입니다. Auto-decoder의 학습을 통해서 source model에 대해서 임베딩 값 과 variance matrix 를 얻습니다. 여기서 말하는 분산은 어느 방향으로 얼마나 변형이 가능한지를 나타내는 값입니다.

결과적으로 target 값과 source 값의 distance를 줄이는 방식으로 retrieval을 진행하게 됩니다. 이 방식은 ‘ Deformation-Aware 3D model embedding and retriva’ 논문에서 사용한 방식을 그대로 가져왔으며, 분산 값도 학습한다는 차이점만 존재합니다.
Result
Test dataset: 3개의 가구 데이터 ShapNet dataset chairs(6531), tables (7939) and cabinets (1278)를 사용했습니다.
Source dataset: PartNet(가장 세분화된 레벨에서 10% 랜덤 샘플링), ComplementMe(의자, 탁자 클래스 각각 200개 랜덤 샘플링)
모든 3D 형태는 2048개의 uniform sampling 해 point cloud로 변환합니다.
Image to Mesh
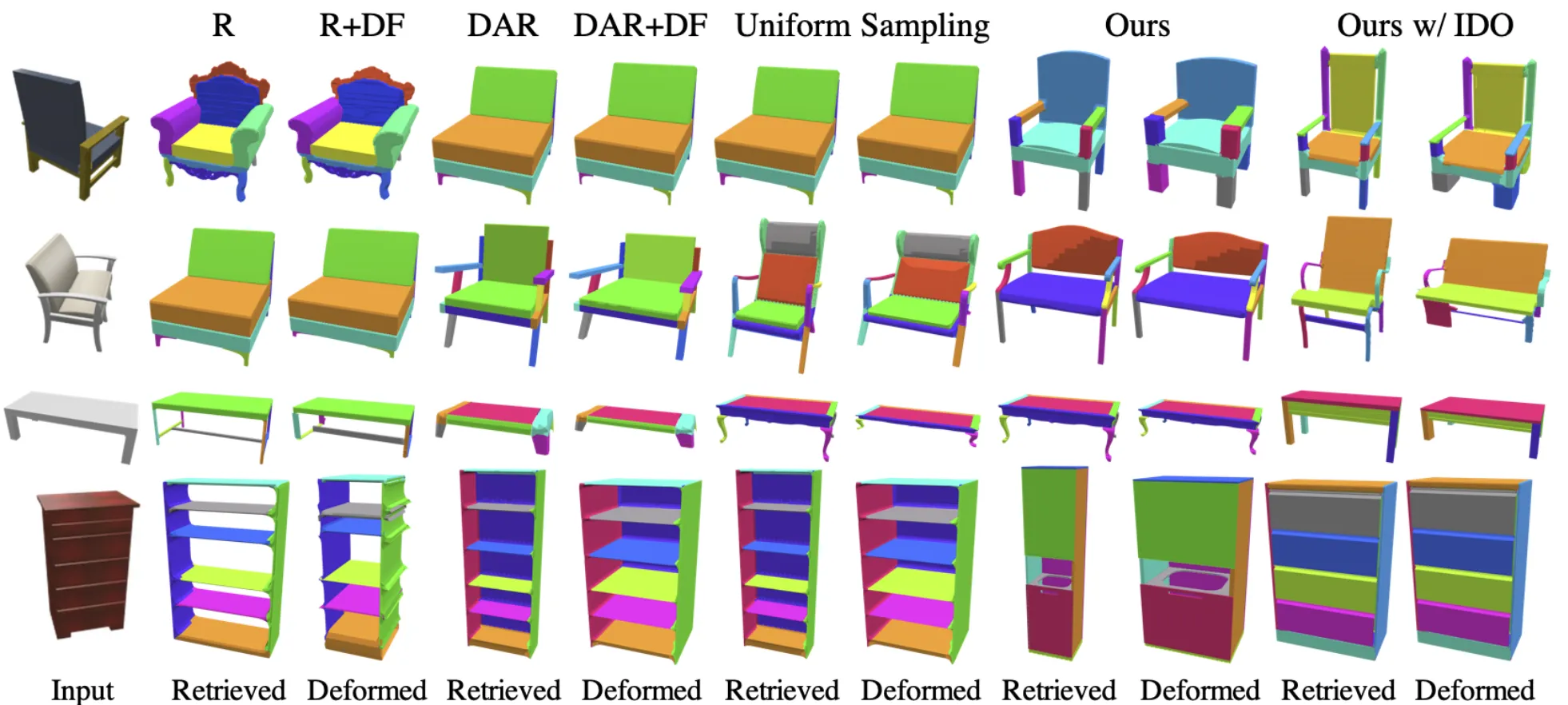
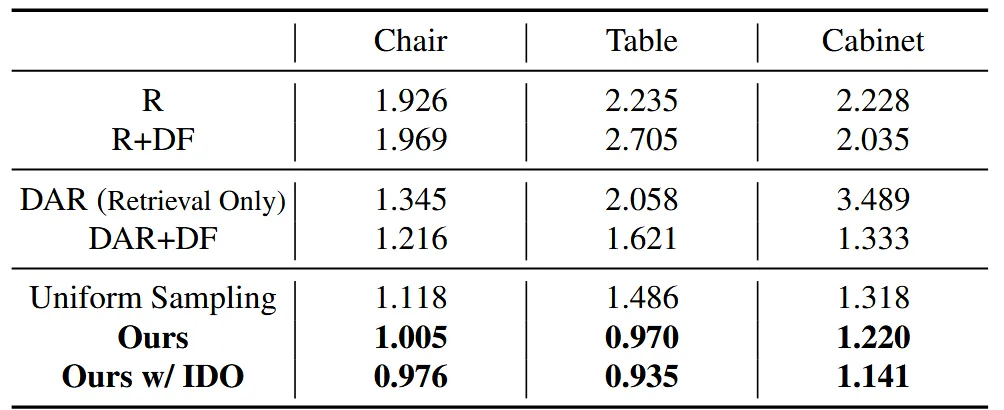
Limitations
- Chamer distance로만 학습을 진행했기 때문에 충분히 학습되지 않을 수 있다.
- Part를 연결하는 부분에 대해서 충분히 제약 조건을 주지 못 했다.
