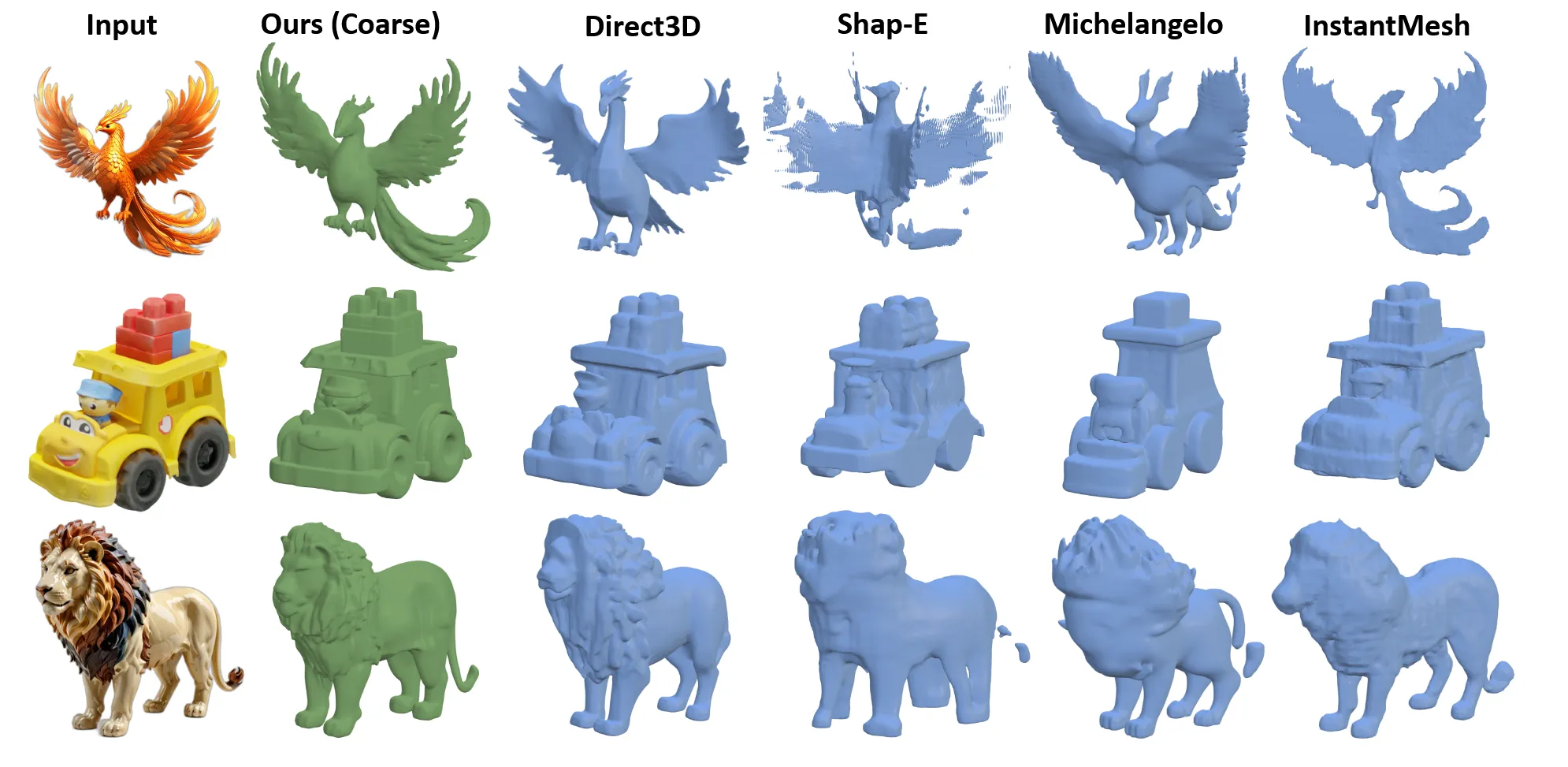
CraftsMan3D: High-fidelity Mesh Generation with 3D Native Diffusion and Interactive Geometry Refiner[2025 CVPR]
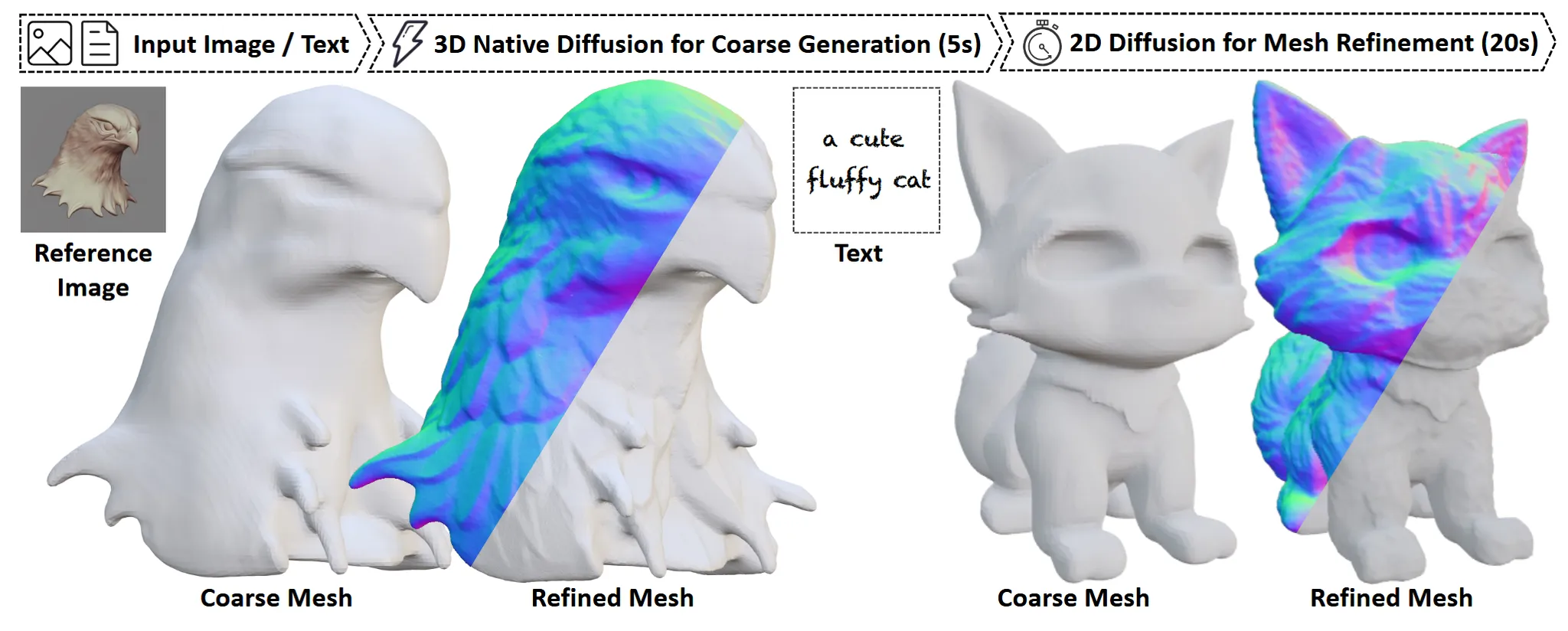
일반적은 text-to-3d, image-to-3d 모델들보다 빠르고 훌륭한 장인스러운 결과를 낼 수 있다는 모델입니다. 어떻게 이를 가능하게 했는지 살펴보도록 하겠습니다.
Method
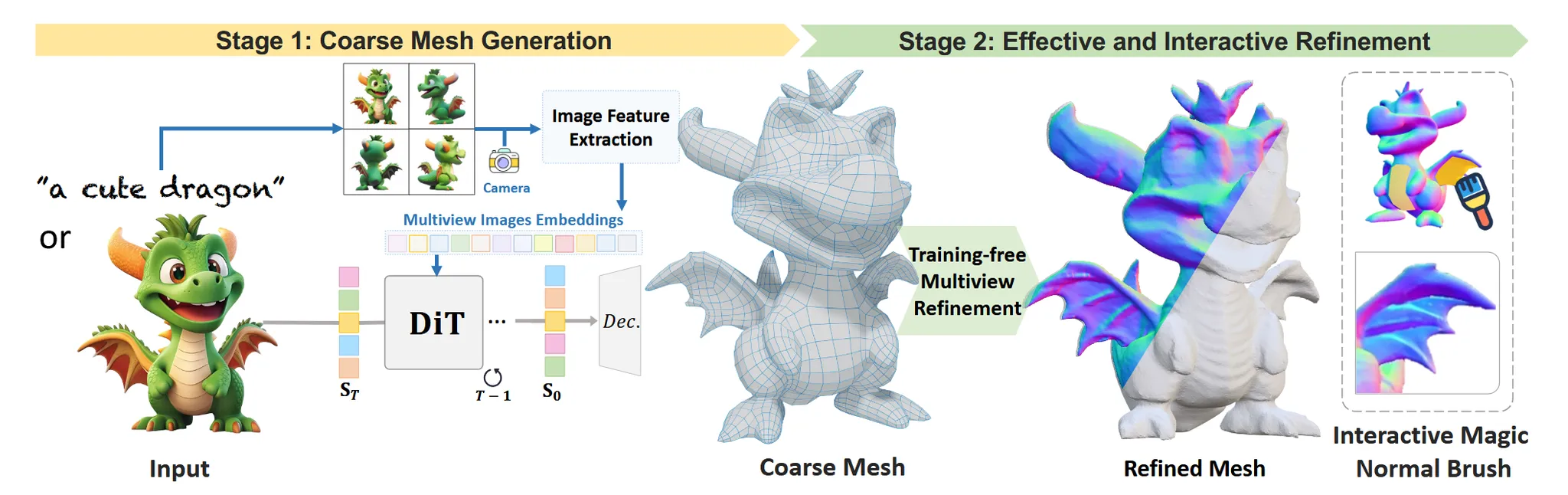
기존 3D 데이터를 최대한 활용하기 위해 watertight mesh로 정제하고, 해당 mesh를 TSDF field로 변환해서 VAE를 통해 latent로 보냅니다. Latent는 멀티뷰 이미지를 condition으로 받는 DiT를 통해서 coarse한 mesh를 생성합니다. 이후 coarse mesh를 normal기반의 refinment 과정을 거쳐서 최종적인 결과를 도출합니다.
Data Preprocessing
기존의 3D 데이터셋들은 mesh가 완벽하게 구멍이 매여져 있지 않았습니다. 이러한 mesh들로 학습하면 VAE의 퀄리티가 떨어질 수 있기 때문에 mesh들을 구멍을 매우면서 watertight하게 변환했습니다.
Winding Number-Enhanced Watertight Conversion
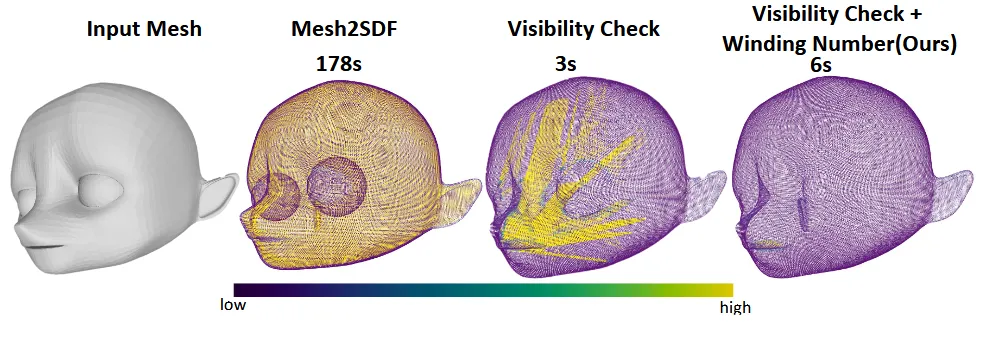
Mesh를 watertight로 변환하는 기존 방법들중에는 Dual Octree Graph Networks (DOGN)가 있는데 시간이 너무 오래 걸리고(위 그림에서 178s), CLAY논문에서 사용한 visibility-check는 구멍이 있는 mesh에서 구멍안에 floaters(둥둥 떠다니는 입자, 위그림 3번째 사진에서 노란색 부분들)가 생기는 경우가 있습니다.
해당 논문에서는 winding number를 통해서 각 점들이 외부인지 내부인지 정확하게 계산할 수 있고, 이를 사용해서 mesh를 watertight하게 변환한다고 했습니다. Supplementary에 자세한 변환 과정이 나와있고 결론적으로 objarverse 데이터 기준 60 → 80% watertight한 mesh로 변환을 했습니다.
Multi-view guided 3D generation model
3D Shape-VAE
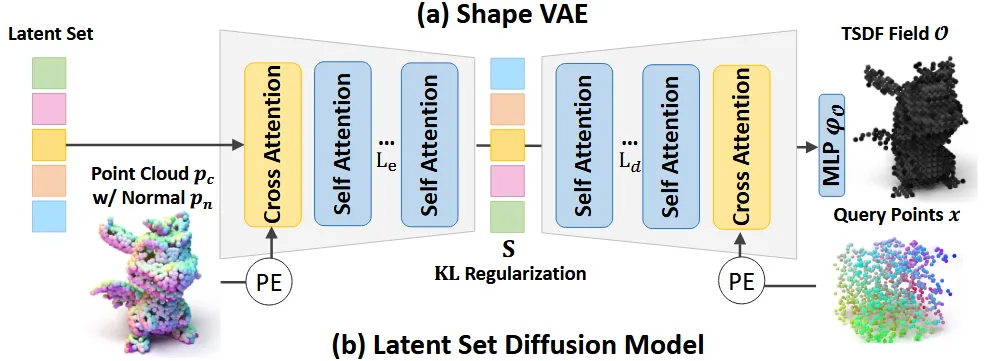
Perceiver 기반 shape VAE를 사용해서 3D mesh를 latent로 변환했습니다. 위의 그림처럼 mesh로부터 point()와 nomral()값들의 집합을 얻습니다. 기존 VAE 구조는 occupancy field를 예측했지만 이를 TSDF field로 변환해서 성능을 증가시켰습니다.
Multi-view Guided 3D Diffusion Model
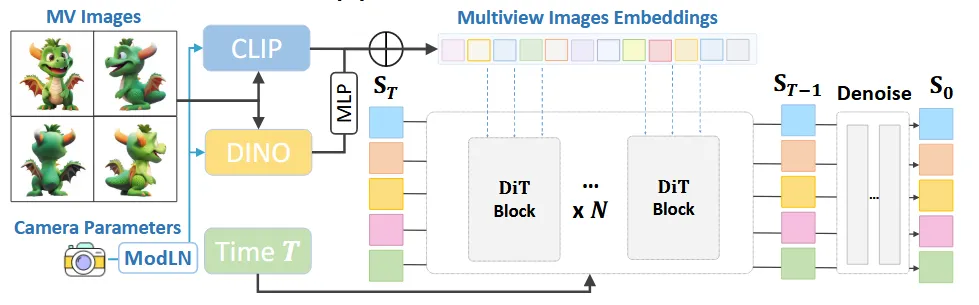
Text나 image 정보 1개만을 사용해서 latent를 변환하는 대신 multi-view 이미지를 함께 입력해서 결과의 예측도를 높이도록 설계했습니다.
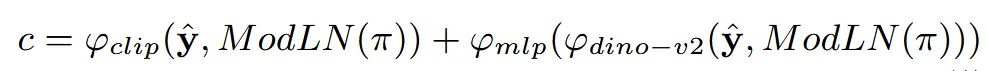
멀티뷰 이미지 와 카메라 임베딩 조건을 함께 반영하기 위해서 Adapative layer normalization(ModLN)을 적용했습니다. 2가지 임베딩 값을 clip과 dino-v2를 통해서 추출한 값이 최종적인 condition이 됩니다. 오른쪾에서 사용한 MLP는 dino space를 clip space로 변환해주는 간단한 mlp입니다.
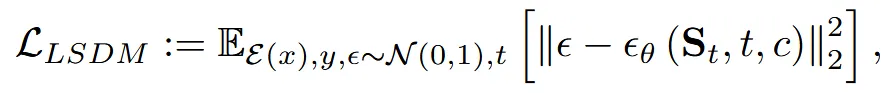
위의 condition을 이용해서 DiT 모델을 학습합니다.
Normal-based Geometry Refinement
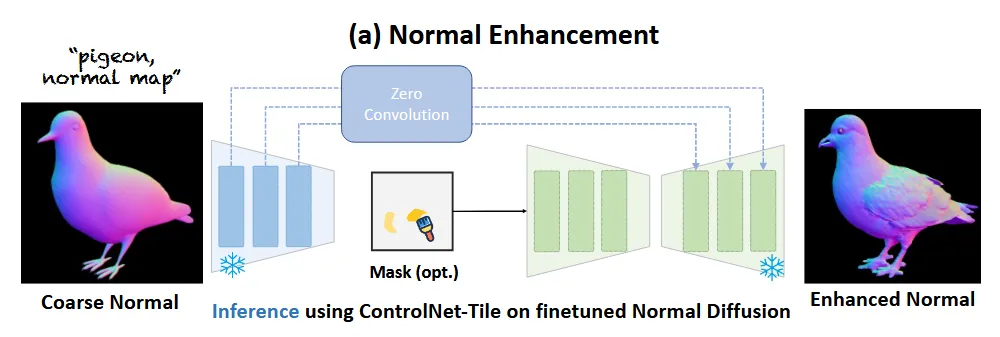
Normal기반 mesh를 refinement 하기 위해서 우선 coarse mesh에서 normal을 렌더링합니다. 이후 normal 기반 diffusion 모델을 통해서 normal을 refine하고, 이정보를 이용해서 vertex를 새로운 곳으로 이동시킵니다. 마지막으로 유저가 선택적으로 영역을 지정해서 해당 부분을 refine할 수 있는 방법도 지원합니다.
Intermediate Normal Guidance Generation
Normal 데이터로 사전 학습된 ControlNet-Tile을 이용해서 normal을 refine합니다. 이때 서로다른 뷰끼리 refine된 normal들은 consistency가 유지되지 않을 수도 있습니다. 이를 위해서 training-free 방식으로 cross-view transformer를 적용했습니다.
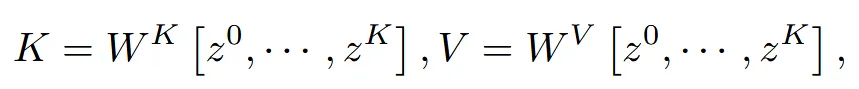
Attention layer의 모든시점의 key와 value를 cross-attention에서 사용함으로서 시점 간 일관성 있는 디테일 refine이 가능했습니다.
Shape Editing via Normal-based Optimization
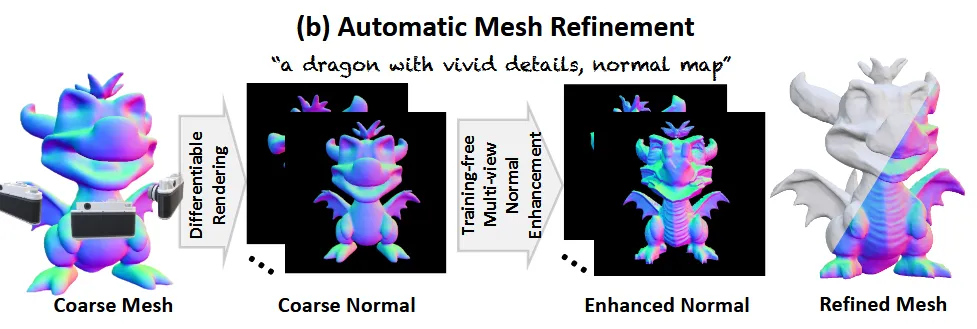
향상된 normal을 continous remeshing 방식에 이용해서 coarse mesh의 vertex와 face를 새로운 방향으로 이동시킵니다.
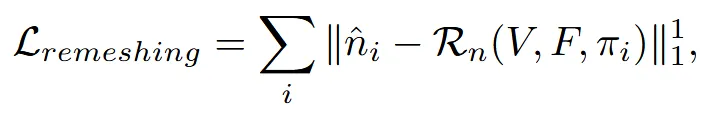
위의 수식은 coarse mesh의 렌더링된 normal와 향상된 normal 의 차이를 L1 loss를 이용해서 coarse mesh의 normal을 업데이트하겠다는 의미입니다.
Poisson Normal Blending
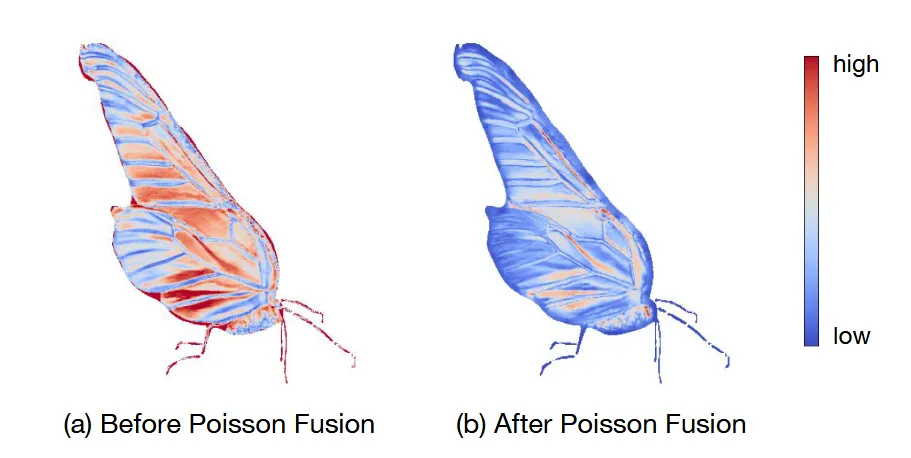
Diffusion으로 생성한 normal은 왼쪽 그림처럼 로컬한 디테일은 잘 잡지만, 전체적으로 왜곡이 일어날 수 있습니다. 위의 그림을 자세히 설명하면 coarse-mesh와 정제된 mesh와의 L2 distance를 시각화 한 것입니다. 왼쪽을 보면 차이가 심하기 때문에 전체적인 왜곡이 발생할 수 있습니다. 이를 해결하기 위해서 poisson blending을 진행합니다.
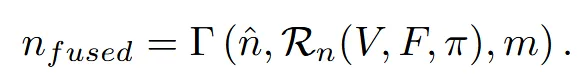
전체적인 형태는 유지하고 local한 부분만 업데이트하기 위해서 위의 poisson blending 알고리즘을 사용합니다.
Relative Laplacian Smoothing
이전 모델들은 Laplace regularization를 사용해서 stable optimization을 진행했습니다. 해당 방법은 모든 점들을 원점 근처로 끌어당겨서 가끔 원치 않은 결과를 야기하곤 합니다. 지금 모델에서 coarse mesh의 성능이 어느정도 잘나오기 때문에 해당 논문에서는 initial shape을 기반으로 laplacian smoothing을 진행했습니다.
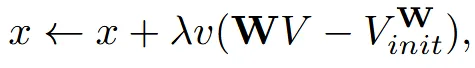
WV는 현재 Laplacian, init붙어있는건 coarse mesh의 Laplacian으로 vertex가 초기 위치를 벗어나려고 할수로고 패널티를 주는 식으로 디테일은 추가하되 전체 구조는 초기 형태를 유지하도록 합니다.
Experiments