Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation[2025 CVPR]
개인적으로 너무 깔끔하게 잘 쓴 논문이라고 생각합니다. 어려운 개념은 없어서 한번쯤 꼭 읽어보면 좋을거같습니다!

Single image to 3D 모델들은 대부분 하나의 이미지로부터 멀티뷰 이미지를 생성하고, 이를 3D 모델에 넣어서 생성합니다. 하지만 멀티뷰 이미지들은 서로 일관성이 부족한 경우가 있습니다.
이를 위해서 Fancy123는 2D상에서 이미지들끼리의 일관성을 높이는 작업, 3D mesh를 입력 이미지와 더 잘 닮도록 변형하는 과정을 진행합니다. Fancy123의 이러한 모듈들은 기존의 3D 모델에 보정 모듈만 추가해서 이용할 수 있기 때문에 널리 사용될 수 있습니다. 아래에서 Fancy123에 대해서 자세히 알아보도록 하겠습니다.
Method
Overview
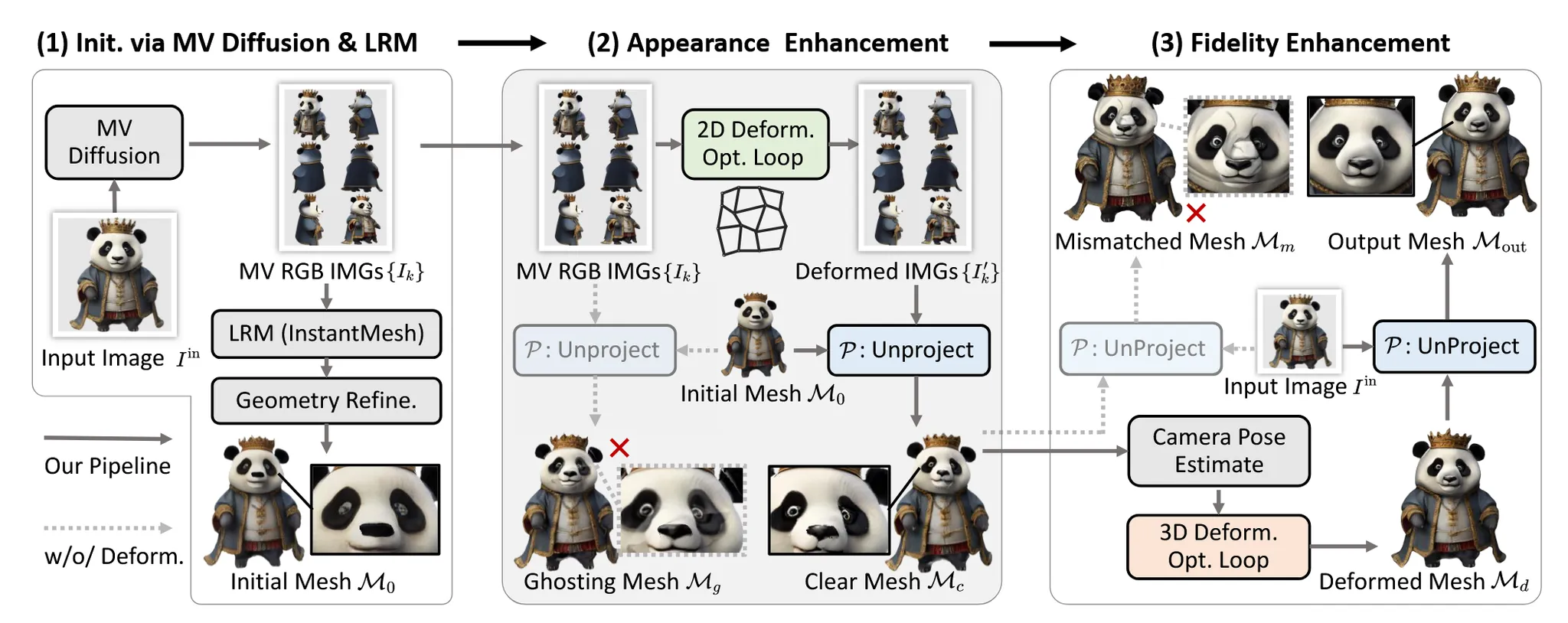
Fancy123은 총 3단계로 구성된 파이프라인입니다.
첫번째로 입력이미지들을 멀티뷰 이미지로 생성하고 LRM(Large Reconstruction Model)을 이용해서 initial 3d mesh 를 생성합니다. 이 mesh는 추가적으로 normal map을 기반으로 geometry refinement를 진행합니다.
두번째로 멀티뷰 이미지들에 대해서 서로의 일관성을 유지하기 위한 appearance enhancement 과정을 진행합니다. 그리고 이렇게 변형된 이미지를 에 unproject해서 이미지들과 비슷하게 변형 파라미터를 최적화해서 mesh 를 생성합니다.
마지막으로 가 겉보기에는 좋아졌지만 입력 이미지와 모양이 다를 수 있습니다. 따라서 fidelity enhancement 과정을 진행해서 입력 이미지와 최대한 비슷한 모습이 되도록 조정합니다.
이 모든 과정은 A100 GPU 기준으로 약 62초가 걸립니다.
Preliminaries
여기에서는 기본적인 개념들에 대해서 다룰건데 여기서 사용한 symbol들을 그대로 사용하기 때문에 정확하게 확인하고 넘어가도록 하겠습니다.
2D deformation
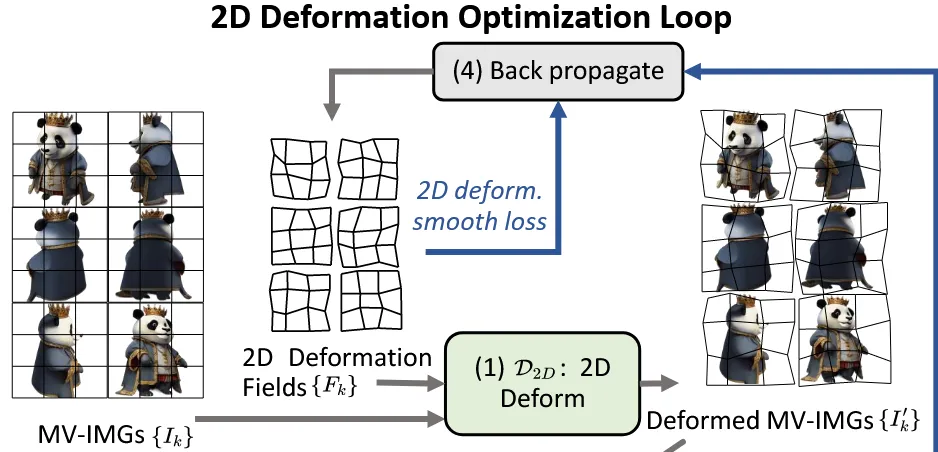
2D 이미지를 simple grid-deformation-field strategy 방식을 적용해서 로 변형합니다. 처음에 입력 이미지를 GxG grid로 나누고, 각 Grid에 대해서 (x,y)방향 어디로 이동할지에 대한 offset deformation field 를 예측합니다. 위의 그림을 보시면 3x3 grid로 나누고 각각 의 grid가 찌그러지면서 약간의 변형이 된 것을 확인할 수 있습니다.
3D Deformation
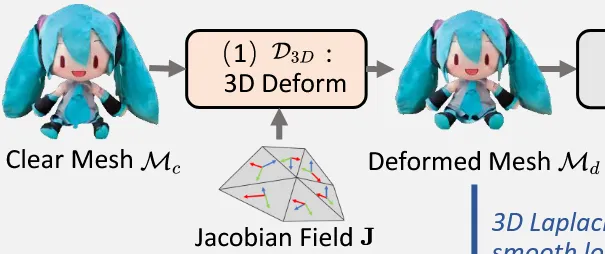
3D deformation은 Jacobian-field 기반으로 수행됩니다. (참고논문: https://velog.io/@guts4/Neural-Jacobian-Fields-Learning-Intrinsic-Mappings-of-Arbitrary-MeshesSIGGRAPH-2022)
Jacobian Field는 각 삼각형(face)에 대해 정의되는 3×3 행렬로, 해당 face가 어떻게 변형될지를 나타냅니다.
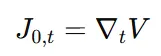
초기에는 각 face의 gradient를 사용해 Jacobian을 초기화하고, 이를 바탕으로 전체 정점(vertex)들이 새로운 위치로 이동하게 됩니다.
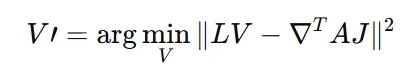
이 과정은 다음과 같은 Poisson 방정식을 풀어 수행되며, 전체적으로 부드럽고 자연스러운 형태의 변형을 이끌어냅니다.
Unprojection
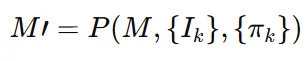
Unique 3D에서 사용한 방식으로 멀티뷰 이미지 를 3D로 unprojection 시켜서 mesh에 texture를 입힌 M’를 생성하는 방식입니다. 3D의 하나의 점은 멀티뷰 이미지 여러개에 속할 수 있는데 단순히 이 점들을 평균 내서 색상을 구하는게 아니라 정점의 normal vector와 카메라 시선 방향 사이의 cosine similarity 값을 기반으로 가중치를 내서 색깔을 구합니다.
Differentiable rendering
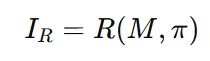
3D mesh를 2D 이미지로 렌더링하는 과정을 수학적으로 미분 가능하게 만들어서 딥러닝 모델이 학습할 수 있도록 하는 방식입니다.
Initialization via multiview diffusion and LRM
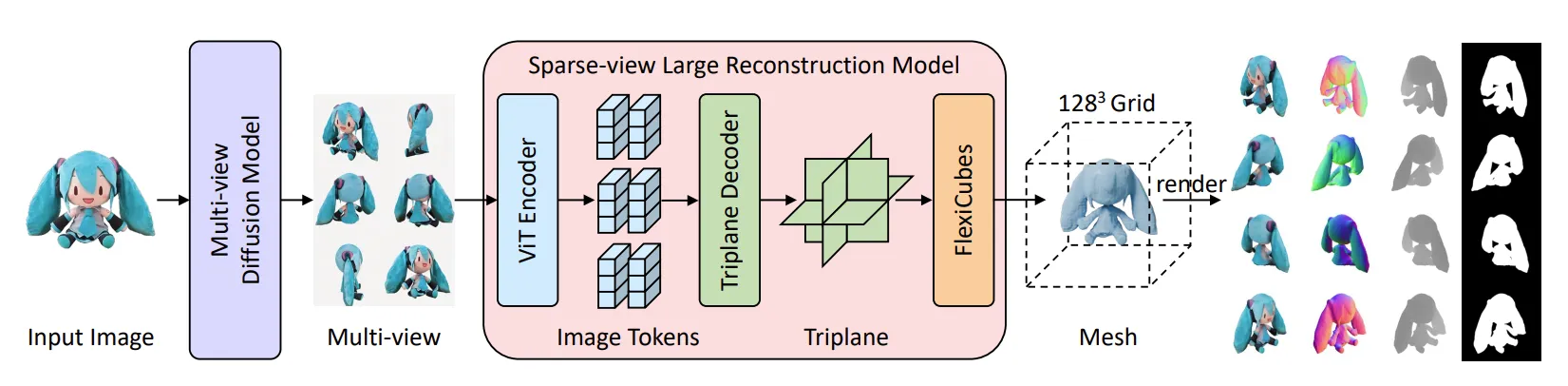
Input 이미지 을 Zero123++에 넣어서 멀티뷰 이미지 를 생성하고, LRM을 기반으로 coarse한 mesh를 생성합니다. 해당 과정은 InstantMesh 모델(위 그림 참조)을 바탕으로 생성했지만, 다른 LRM 모델을 써도 Fancy123 구조에는 문제 없다고 언급했습니다.
이렇게 생성된 mesh를 Wonder3D,Unique3D에서 사용한 멀티뷰 normal map을 기반으로 refinement하는 과정을 그대로 사용했습니다.
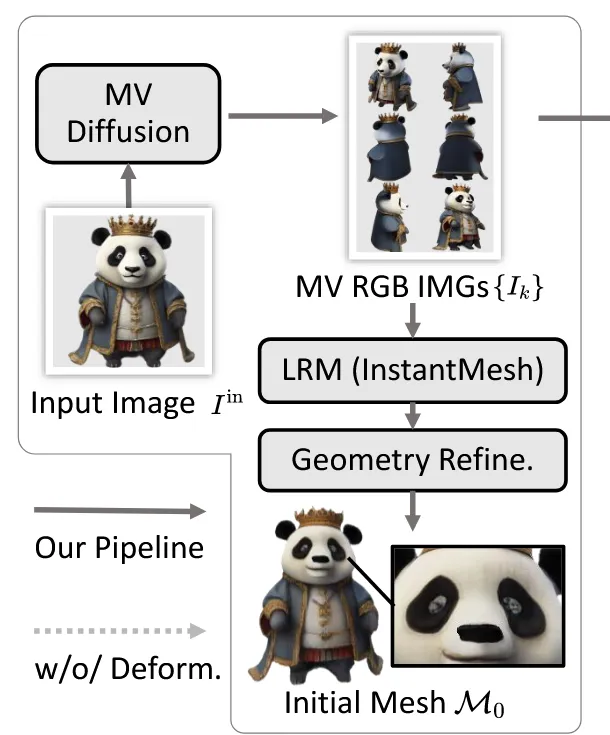
첫번째 단계의 전체적인 파이프라인은 위와 같습니다.
Appearance enhancement
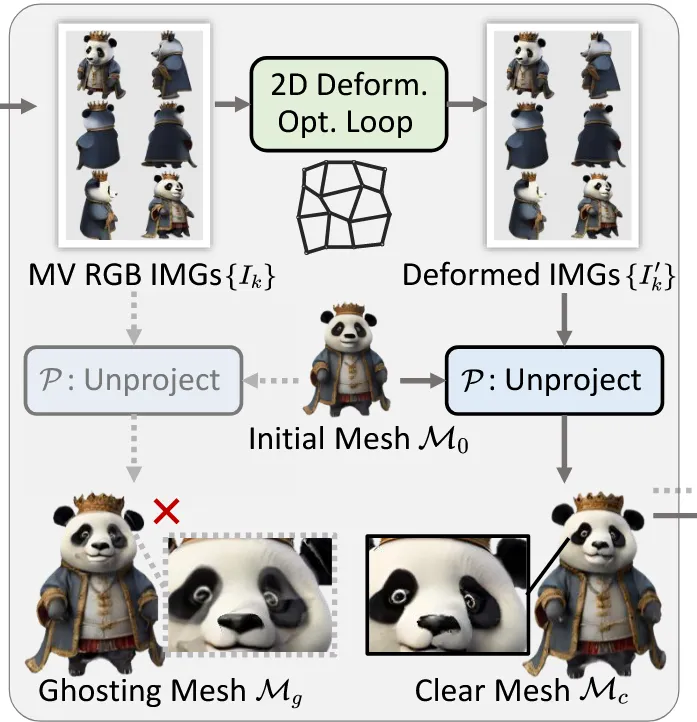
한장의 이미지로 생성한 멀티뷰 이미지는 시각적으로 품질이 높지만, 이 이미지들을 3d mesh에 바로 입히면 픽셀 위치가 정확히 맞지 않아 위의 그림 왼쪽처럼 ghost 현상(겹침, 흐림)이 발생합니다.
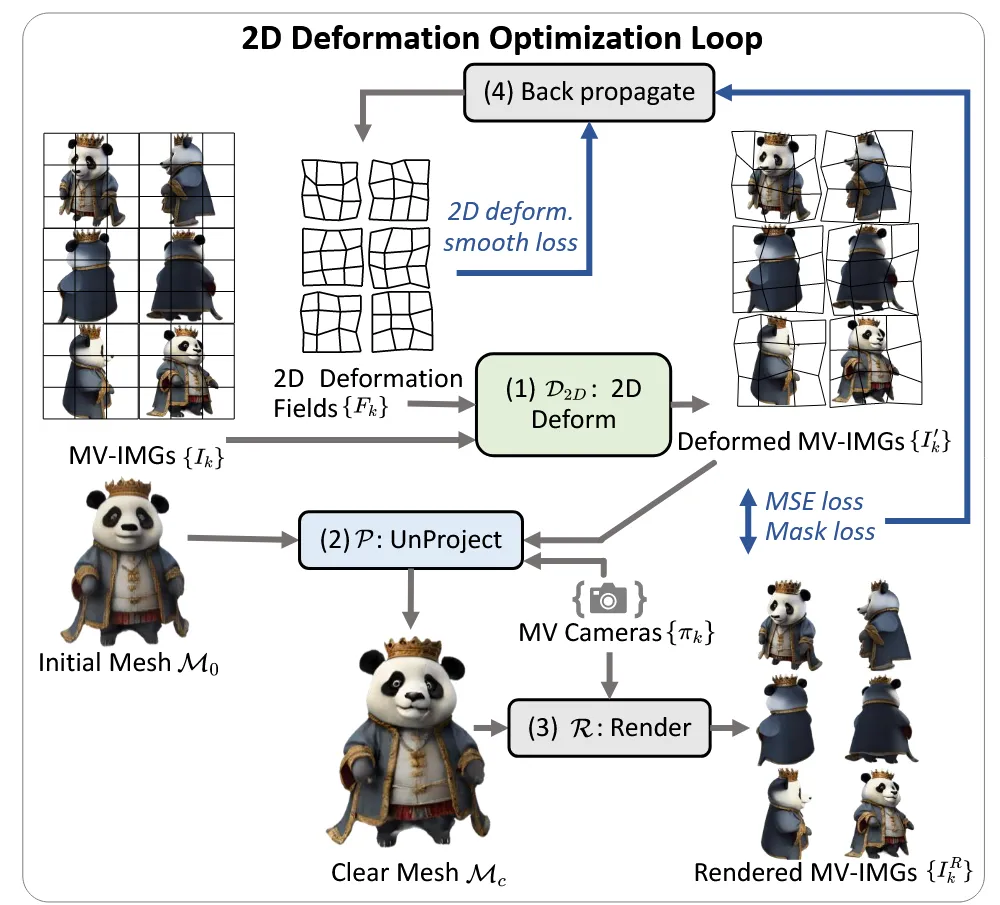
이를 극복하기 위해서 2D deformation optimization loop를 진행합니다. 핵심 내용은 2d deformation fields 를 최적화해서 이를 통해 얻은 를 에 unprojecting했을 때 얻은 가 와 비슷하게 해지는 것입니다. 요약하면 그냥 멀티뷰 이미지가 잘 반영되도록 2D 상에서 deformation을 진행하겠다! 입니다.
2D deformation fields를 학습하는 방법은 아래와 같습니다.
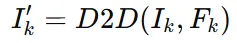
초기값 0으로 설정된 2d deformation field를 반영해서 새로운 이미지 를얻습니다.
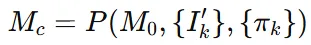
를 초기 mesh 에 투영해서 새로운 mesh 를 얻습니다.
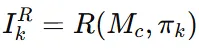
를 다시 렌더링해서 이미지 를 얻습니다.
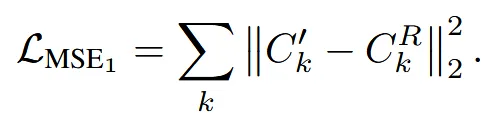
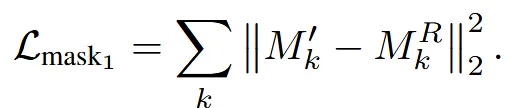
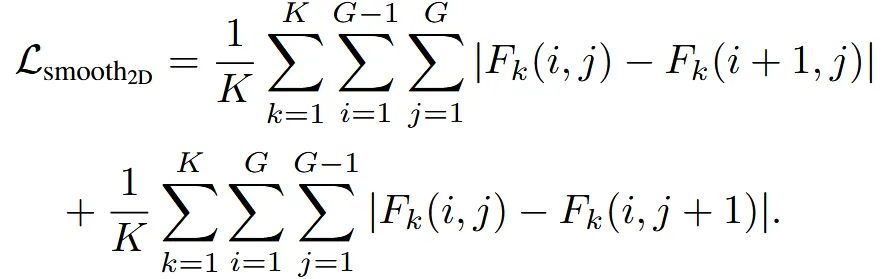
3가지 loss를 결합해서 렌더링된 이미지와 변형된 이미지가 최대한 비슷해지게 학습합니다. MSE loss에서는 색상 차이를, Mask loss에서는 형태의 차이를, Smoothness loss는 deformation field의 부드러움을 유지합니다. Smoothness loss만 자세히 설명하면 K는 view의 개수이고 G는 의 해상도로서, Grid의 (i,j)값이 이웃한 (i+1, j)와 (i, j+1)과 유사하도록 만듭니다.
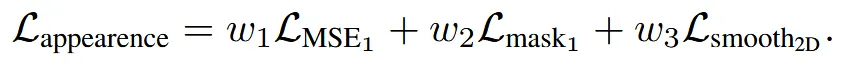
Supplementary에 로 설정했다고 언급했습니다.
Fidelity enhancement
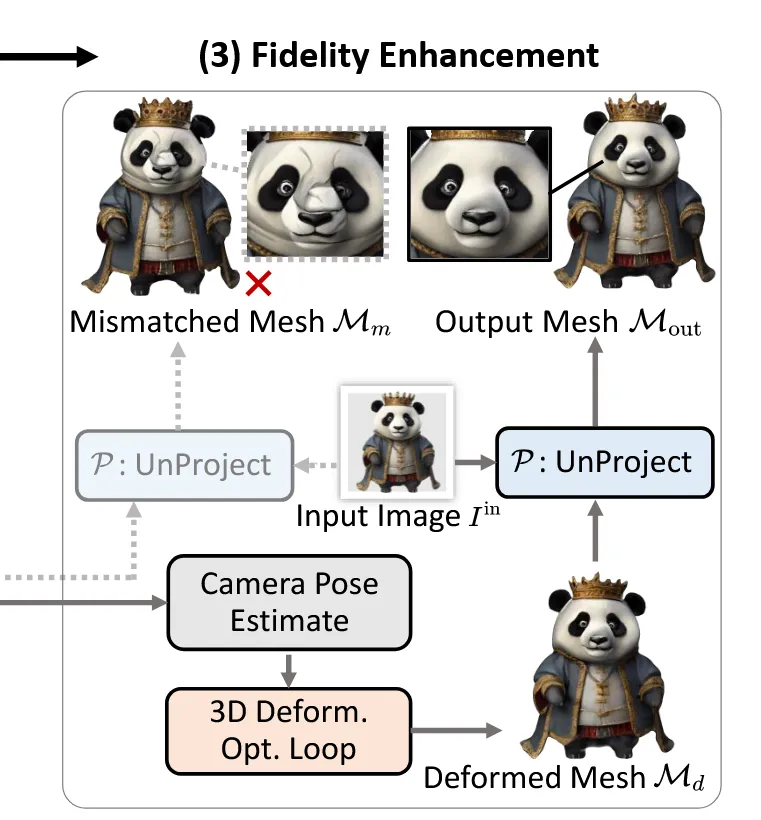
지금까지 만든 mesh가 시각적으로는 깔끔하더라도 원래 입력 이미지와는 디테일이 다를 수 있기 때문에 입력 이미지와 일치하도록 하는 변형을 진행합니다. 전체적인 파이프라인은 위와 같습니다. 입력 이미지의 camera pose를 예측하고, 현재 생성된 mesh 를 jacobian field를 변형시켜서 를 생성합니다. 변형된 를 렌더링 했을 때 입력 이미지 와 일치하도록 학습합니다.
Camera pose estimation
Baseline으로 사용하는 InstantMesh는 azimuth(방위각)을 상대값 elevation(고도)을 절대값으로 해석하기 때문에 2개의 값을 정면이라고 해서 단순히 0으로 설정하면 시점이 틀어질 수 있습니다.
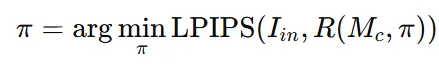
Coarse-to-fine grid search를 사용해서 LPIPS score가 가장낮은 카메라 시점을 예측하도록 합니다. LPIPS(Learned Perceptual Image Patch Similarity)는 이미지 간 시각적 유사도를 수치화하는 지표로서 값이 작을수록 두 이미지가 비슷합니다. 대략적인 최적 시점을 찾은 뒤, 작은 최적화 루프로 미세 조정을 해서 최적의 카메라 시점을 찾습니다.
Appendix 내용
1단계: azimuth0으로 고정하고 정확한 elevation 찾기
Instant Mesh는 절대값으로 사용하는 elevation이 성능에 큰 영향을 주기 때문에 -90부터 90까지 3단위로 탐색을 진행해서 LPIPS score가 가장 적은 값을 선택합니다. 이후 3단위에 대해서 1단위로 변경해서 LPIPS score를 비교해 최종적인 elevation을 선택합니다.
2단계: 미세 조정으로 정확한 카메라 찾기
100번의 iteration을 통해서 카메라 위치를 미세 조정해서 입력 이미지와 가장 유사한 시점을 찾습니다.
3D efromation optimization
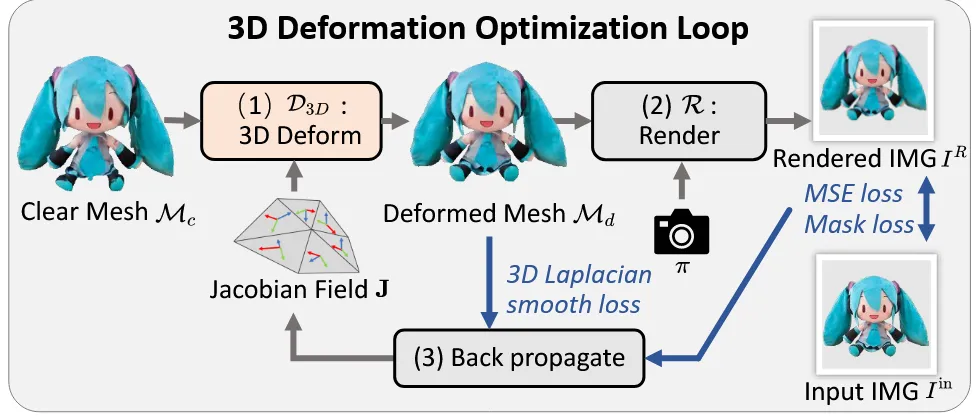
현재 생성된 mesh 와 입력 이미지 와 이전에 추정한 카메라 파라미터 를 기반으로 optimization loop로 를 과 닮도록 학습합니다.
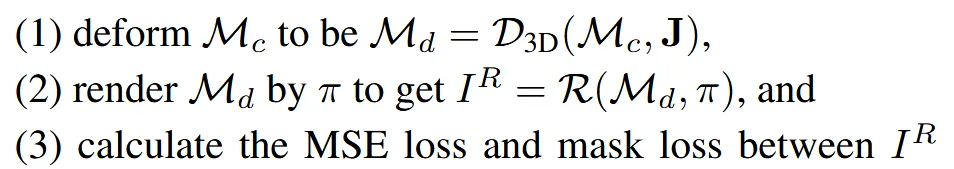
Supplementary에서도 설명했지만 우리는 입력 이미지에 맞게 Jacobian을 최적화해서 mesh의 점들을 수정합니다.
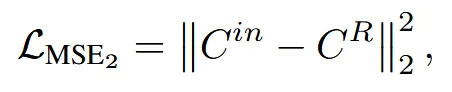
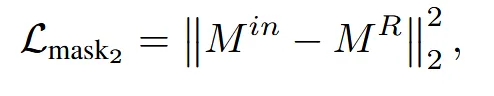
렌더링된 이미지와 입력이미지간의 색깔을 비교하기 위한 MSE loss, 형태를 비교하기 위한 mask loss를 사용합니다.
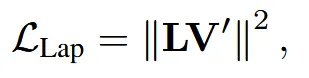
V’은 변형된 mesh의 정점 좌표이고, L은 laplacian 연산자로 정점 간 이동이 너무 급격하지 않도록 제어하는 방법입니다.
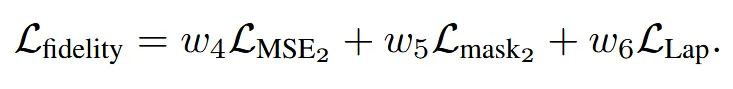
최종적으로 3가지 loss를 합친 loss를 기반으로 mesh를 deformation합니다. 를 사용했다고 논문에 나와 있습니다.
최종적으로 변형된 3D mesh에 우리는 안전하게 입력 이미지를 투영해서 우리가 원하는 mesh를 얻을 수 있습니다.
Experiments

Cross-view plausibility of 3D deformation

흥미로운 결과라서 가져오게 됐습니다. 마지막에 우리가 3D deformation을 할 때 정면 이미지만을 기준으로 변형하는데 이게 다른 뷰에 나쁜 영향을 미치지 않을까? 라는 실험입니다. 다행히 악영향은 없었습니다.
우선 a→c를 통해서 3D deformation을 통해서 더 정확한 정면을 얻을 수 있는 것을 확인했습니다. e에서는 vertex replacement를 통해서 정점을 바꿨지만 다른시점에서 부자연스러운 찌그러짐이 발생했고, f에서는 face가 아닌 vertex마다 deformation을 진행했는데 디테일이 깨지고 global consistency가 깨졌습니다. 결론적으로 Fancy123에서 사용한 Jacobian 방식은 Laplacian smooth loss가 없는 d에서도 global consistency를 잘 유지함을 증명합니다.
Limitations
- Multiview diffusion 모델의 성능에 영향을 받는다.
- 3D deformation에서 RGB 정보만을 학습했기 때문에 색이 같으면 같은 영역이라고 착각해서 artifact가 발생할 수 있습니다. 예를들어 갈색 눈썹과 갈색 머리를 같은 부분으로 착각할 수 있습니다.
