DrawingSpinUp: 3D Animation from Single Character Drawings[2024 SIGGRAPH]
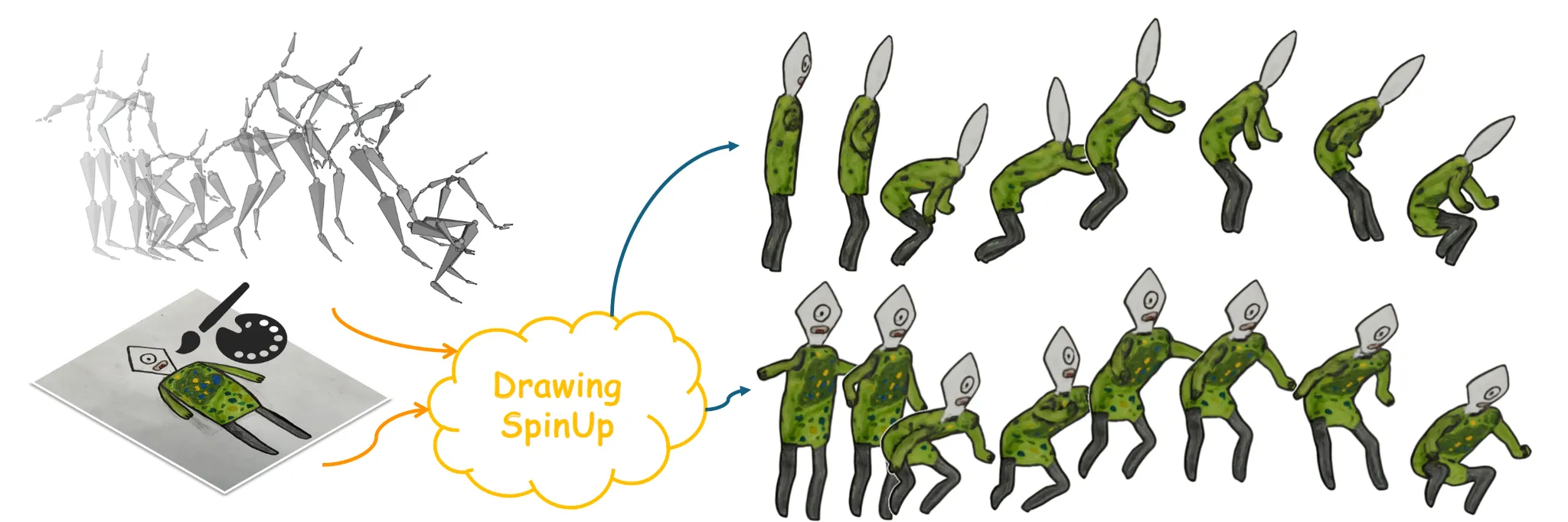
사람들이 그린 이미지를 입체감 있는 애니메이션으로 표현하는 방법은 어렵습니다. 왜냐하면 캐릭터 그림에 흔히 있는 윤곽선이 문제인데, 이는 시점에 따라 보이는 모양이 달라지고 실제로 존재하는 텍스처가 아니라 스타일적인 표현이기 때문입니다. 이를 극복한 DrawingSpinUP은 어떤 방식을 사용해서 이를 가능하게 했는지 살펴보도록 하겠습니다.
Introduction
기존에 존재하는 일반적인 방식은 2D motion을 캐릭터에 적용하기 위해서 2D image space상에서 as-rigid-as-possible(ARAP)를 적용했습니다.
3D motion을 2D image plane에 적용한 결과는 안타깝게도 좋지 않았습니다. 이를 극복하기 위해서 2D image를 3D로 변환한 후 3D motion을 적용할 수 있습니다. 하지만 기존 모델들은 photo-realisitc 이미지를 기반으로 학습되었고, cartoon 이미지는 domain-gap 문제로 인해서 성능이 위와 같이 좋지 않았습니다.
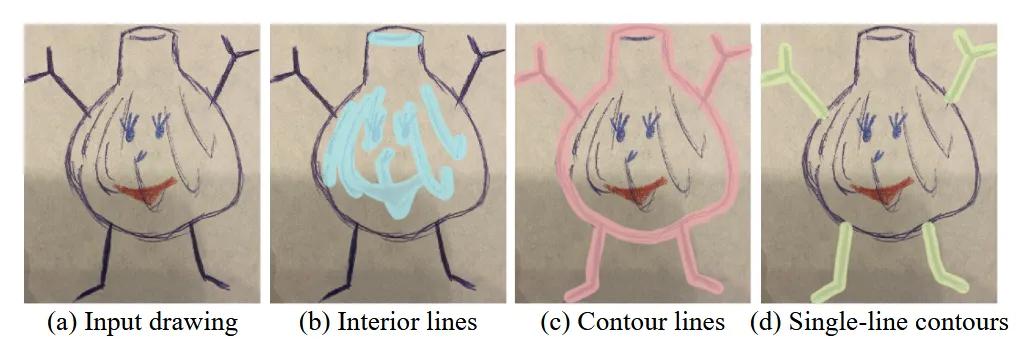
Photo-realistic한 이미지와 다르게 cartoon 이미지는 위와 같이 interior line들이 존재했습니다. Interior lines는 texture를 표현하기 위한 선들이라고 생각하시면 됩니다.
Contour lines는 photo-realistic에는 없는거로서 view와 motion에 dependent하게 생깁니다.
이러한 차이점 때문에 기존 Image-to-3D 모델은 cartoon image를 잘 생성하지 못합니다.
또한 Image-to-3D 모델들은 주로 여러시점의 이미지를 생성하고, 이로부터 3D를 생성하는데 윤곽선은 시점에 의존적인 정보를 담고 있기 때문에 결과에 안 좋은 영향을 미칩니다.
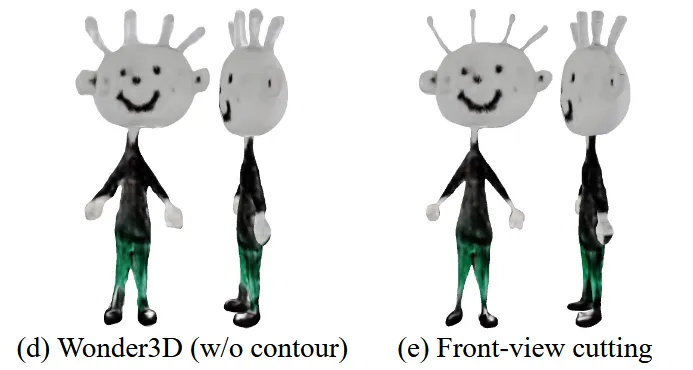
마지막으로 (d)의 single-line contours과 같은 가는 부위에 대한 묘사도 기존 photo-realistic으로 학습한 모델들에서는 잘 복원하지 못합니다.
이를 위해서 논문에서는 윤곽선을 제거한다음 3D를 생성하고, 생성된 3D에 다시 윤곽선을 넣는 작업을 진행했습니다. 이에 대해서는 아래에서 더 자세히 설명하도록 하겠습니다.
Related Work
2D Character Animation
이전 논문들은 주로 as-rigid-as-possible(ARAP) 방식을 적용해서 어느 부분을 수정할지 사용자가 드래그 하면 해당 정보를 기반으로 2D image space에서 캐릭터를 수정하도록 했습니다. AniClipart에서 텍스트를 기반으로 clipart를 새 포즈로 자동으로 바꾸는 딥러닝 기반 ARAP를 제안했지만 여전히 2D space상에서의 animation을 다루기 때문에 입체적인 animation은 불가능했습니다.
이에 비해 해당 논문은 3D로 변환한 후 animation을 다루기 때문에 2D space에서 다루지 못 했던 입체적인 동작들까지 다룰 수 있게 됩니다.
3D Character Animation
초기 3D character 생성 논문들은 silhouette이나 skeleton을 팽창 시키는 방식을 선택했습니다. 이후에 SMPL같은 사람 모형에서 shape 파라미터를 예측하는 형태로의 발전이 진행됐습니다. 이러한 방식들은 뒷모습의 texture가 잘 생성되지 않고 단순히 앞모습과 똑같이 나온다는 한계점이 존재합니다.
이러한 한계를 극복하기 위해 3D character에 특화된 모델들이 나왔습니다. 해당 모델들의 퀄리티는 좋지만 일반 손그림이나 다양한 스타일에는 한계가 존재합니다. 또한 3D character에 특화된 데이터를 대량으로 얻어야 한다는 단점이 존재합니다.
해당 논문에서는 Novel view synthesis 모델중 Wonder3D를 기반으로 3D animaiton을 생성할 수 있습니다. 자세한 내용은 아래에서 다루도록 하겠습니다.
Contour Rendering
PAniC-3D에서는 애니메이션 캐릭터 이미지를 더 현실적으로 바꾸는 방식을 사용했습니다. DOG 필터로 선을 뽑는데, 모든 선을 동일하게 처리하기 때문에 디테일한 부분의 선이 사라질 수 있습니다.
ReenactArtFace에서는 parsing map과 contour loss를 활용해서 인위적인 윤곽선을 artistic face에 생성했습니다. 하지만 선 굵기를 균일하게 처리하는 방식이라 다양한 선 스타일이 있는 실제 손그림에 어울리지 않습니다.
Neural Strokes는 3D Shape과 line을 함께 다루며 선을 스타일 했는데, 선과 내부 texture를 어우러지게 만드는 조화는 진행하지 않았습니다.
Method
단 하나의 손그림 캐릭터 이미지를 입력 받아서 원하는 3D animation을 진행하는 과정을 자세히 설명해드리도록 하겠습니다. ‘A method for animating children’s drawings of the human figure’ 논문에서 사용한 방식처럼 입력 이미지에 detection, segmentation, pose estimation 전처리를 진행합니다. 이로부터 나온 결과인 foreground mask, joint keypoints, target 3d motion이 추가 입력으로 DrawingSpinUp에 들어간 결과로부터 3D animation을 생성할 수 있습니다.
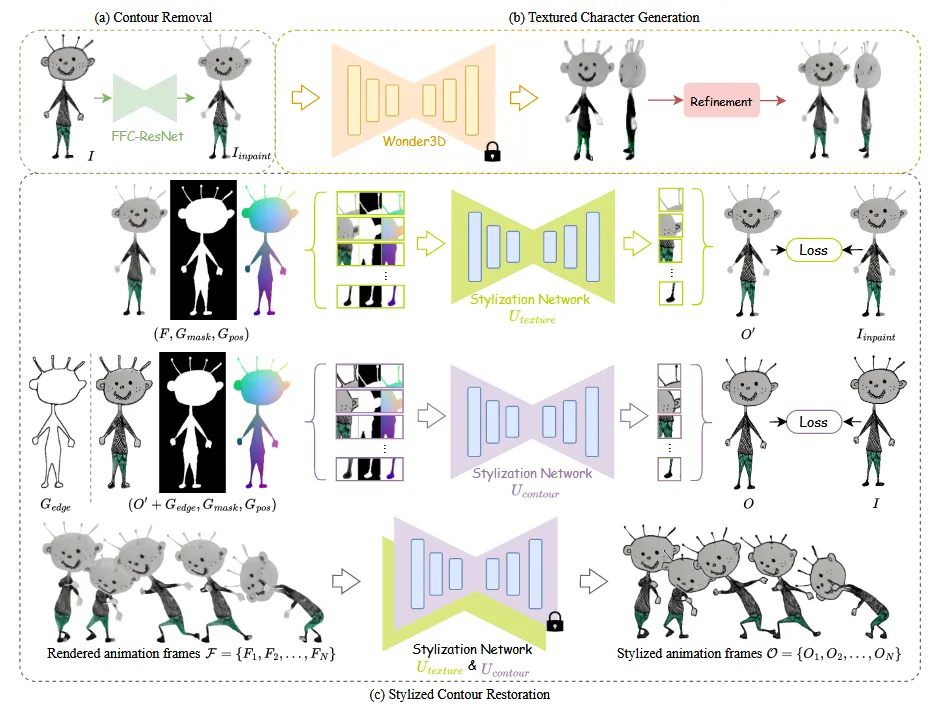
전체적인 파이프라인은 위와 같습니다. Image-to-Image 모델로 윤곽선을 제거하고 윤곽선 영역에 inpainting을 진행하고, Wonder3D를 이용해서 대략적인 3D 형태를 얻습니다.
이후에 thin strokes에서 사용한 방식으로 shape refinement를 진행하고, Joint keypoints를 변형해가면서 최종적인 3D animatinon을 얻습니다. 마지막으로 geometry-aware stylization network를 통해서 원래의 이미지 스타일을 반영합니다.
Contour Removal
이미지들마다 다양한 윤곽선이 존재하기 때문에 이를 고정된 파라미터로 윤곽선을 예측하게 하면 명확하지 않은 결과가 나오거나 추가적인 제거가 생길 수 있습니다. 따라서 해당 논문에서는 윤곽선의 부분에 mask를 씌워서 마스크를 예측하도록 하는 방식을 선택했습니다.
입력 이미지(I)과 foreground mask(M) 들어갔을 때 우리는 contour mask()를 예측합니다. Contour mask를 예측하기 위해서 FFC(Fast Fourier Convolution)-ResNet을 사용했습니다. FFC-ResNet은 큰 receptive field를 갖고 잇기 때문에 모든 이미지를 볼 수 있어서 일반적인 convolution보다 정확한 윤곽선을 예측할 수 있습니다.
학습을 위해서 3DBiCar 데이터셋을 사용했습니다. 정면 이미지를 렌더링 하고 Blender를 이용해서 다양한 윤곽선을 만들었습니다. 추가한 윤곽선에 랜덤한 색깔을 추가해서 amateur drawings 스타일로 변형합니다.
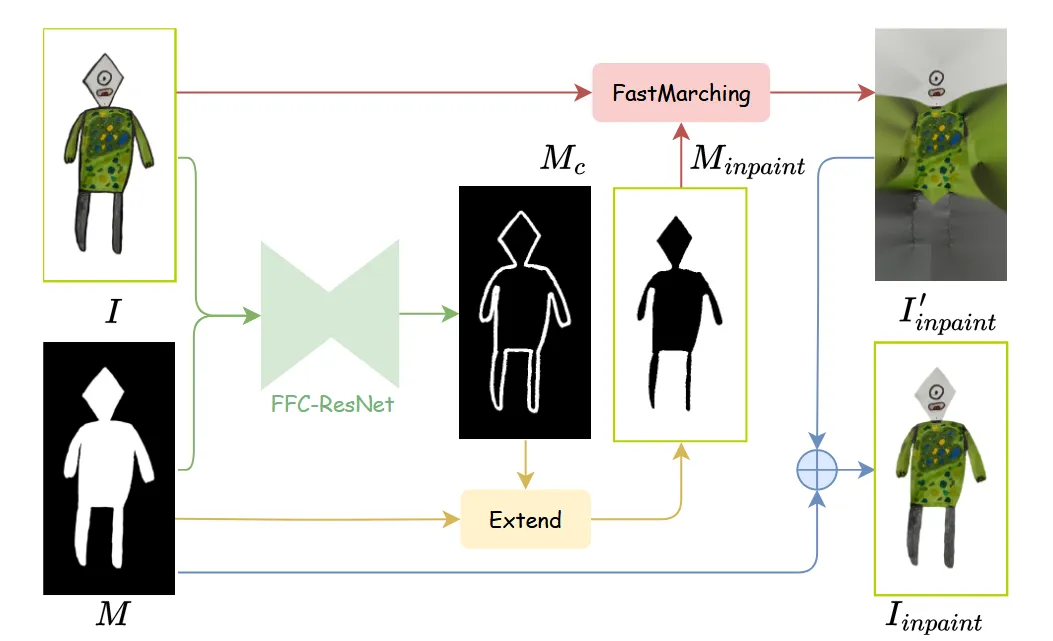
Contour mask를 예측하면 inpainting 모델을 사용해서 안에 있는 texture를 채워 둡니다. 배경의 색깔에 영향을 받는것을 방지하기 위해서 위의 그림처럼 contour mask를 (1-M)영역으로 확장해서 배경을 포함하도록 합니다.
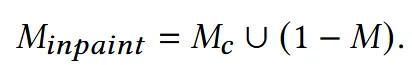
위의 수식처럼 contour mask 는 배경 영역까지 합쳐져서 로 변환됩니다.
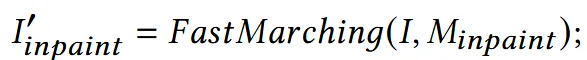
이후 해당 영역을 fast marching 방식을 사용해서 안쪽의 texture를 확장합니다.
이렇게 확장된 texture를 다시 foreground mask를 이용해서 윤곽선은 제거되고 안의 texture로 덮어씌워진 이미지 를 얻게 됩니다.
3D Character Generation
Coarse Reconstruction

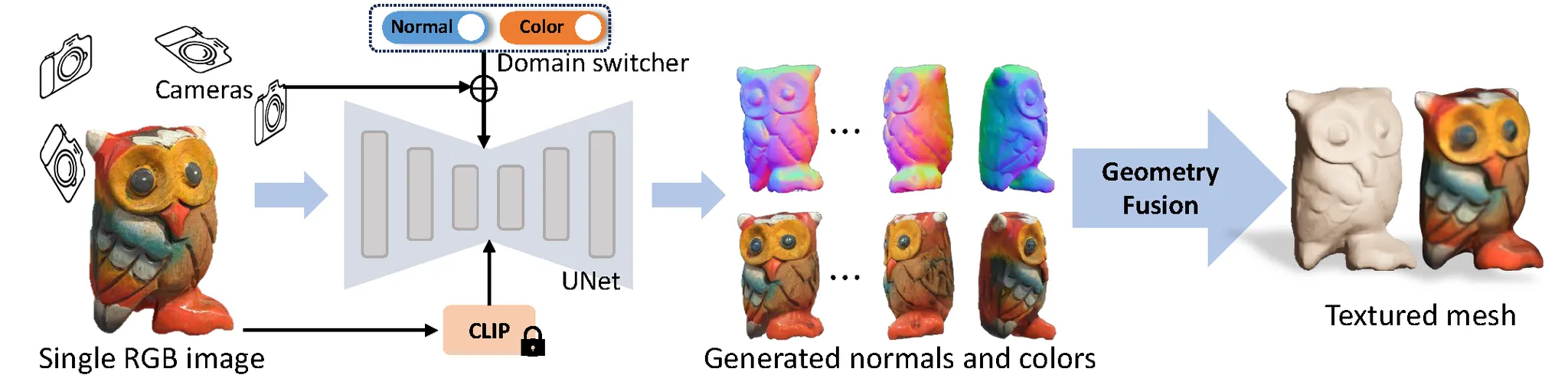
윤곽선이 제거된 이지로부터 3D를 생성하기 위해서 Wonder3D 모델을 사용합니다. Wonder3D는 위의 사진처럼 한장의 이미지를 입력하면 여러 시점의 normal과 color 이미지를 예측합니다.
IS-Net을 통해서 normal map을 segmenation하기 위해서 사용합니다. 이후 입력 이미지 + normal + mask를 Instant NSR에 넣어서 3D를 생성합니다.
자세히는 모르겠지만 이미지 대신에 normal을 이용해서 mask를 생성하는 이미지에는 texture 정보가 있어서 객체와 배경의 경계가 모호하기 때문이라고 생각합니다.

하지만 이렇게 얻은 결과는 얇은 구조가 뚱뚱하게 복원되거나, 표면이 붙어버리는 디테일이 부족한 결과가 나옵니다.
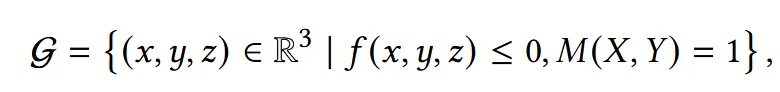
g)
이러한 결과로 animation을 적용하게 된다면 위의 결과처럼 우리가 원하는 퀄리티의 결과가 나오지 않을 것입니다.
Shape Cutting
Shape Cutting은 3D 모델에서 불필요한 외곽 부분을 잘라내어 원본 그림의 실루엣과 더 닮도록 다듬는 작업을 진행하는 과정입니다.
생성된 Mesh는 현재 SDF(Signed Distance Function)형태로 존재합니다. 내부는 음수이고 외부는 양수이기 때문에 일단 SDF값이 음수인 값인 부분만을 사용하면 그냥 위의 결과가 나오고, 여기에 정면 이미지로부터 얻은 mask M(X,Y)를 사용해서 정면 이미지의 실루엣과 비슷하게 mesh를 변형합니다. 이후 나온 결과로부터 marching cubes 알고리즘을 이용해 실제 mesh를 추출합니다.
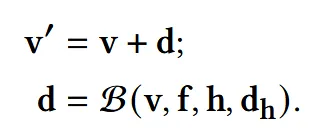
왼쪽이 이전결과 오른쪽이 실루엣 마스크 기반으로 커팅한 결과입니다. 하지만 여전히 디테일한 부분의 개선은 필요한 것으로 보입니다.
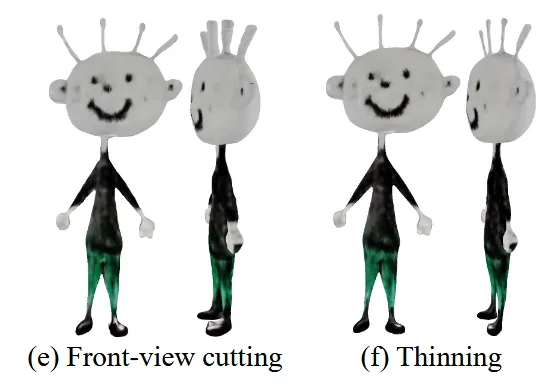
Skeleton-based Thinning Deformation
얇은 부위를 실제로 날씬하게 만드는 작업인 thinning deformation을 진행합니다. 이를 위해서 skeleton 기반의 shape deformation알고리즘을 사용하고, 이걸 bi-harmonic problem으로 해결합니다. Shape cutting을 통해서 다듬어진 geometry g에서의 verteices v와 faces f를 이용해서 아래의 과정을 진행합니다.
새로운 정점 v’은 원래의 정점 v에서부터 d만큼 움직여서 얻게 됩니다. d는 deformation field로서 bi-harmonic map(B)를 통해서 얻을 수 있습니다. 변형을 가할 handle vertex의 index를 h, 해당 handle vertex에 가하고자 하는 이동량을 입니다. 즉 어떤 부분은 움직이고, 어떤 부분은 움직이지 않는게 핵심 아이디어 입니다.
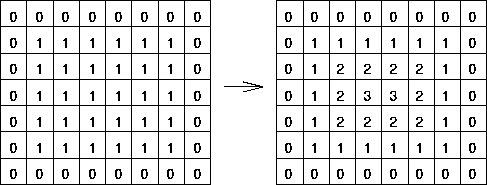
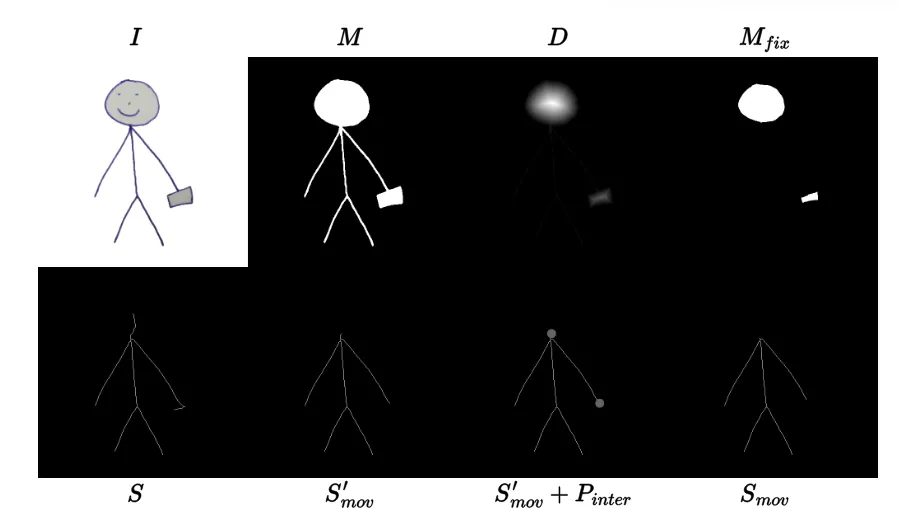
어떻게 handle vertices(h)를 정할 수 있는지 설명하도록 하겠습니다. 우선 Mask(M)으로부터 distance map(D)를 얻습니다.
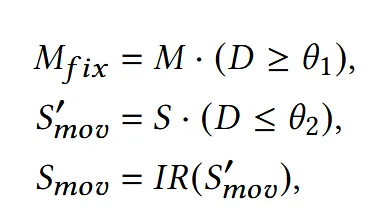
Distance map은 마스크내부의 픽셀들에 대해서 경계로부터 얼마나 떨어져있는지를 나타내는 값입니다. 위의 사진처럼 마스크 부분이 왼쪽과같이 1일 때 그 경계를 1로잡고 내부의 값들은 한칸씩 멀어질 때마다 값이 1씩 증가하는 것입니다.
돌아와서 medial-axis extraction algorithm을 사용해서 mask M으로부터 skeleton S를 얻습니다.
값을 사용해서 와 를 만듭니다. 값이 너무 작거나 인접 영역과 부딪힐 수 있으니 조금 더 확장(IR: dillation)해서 를 만듭니다. 이렇게 확장된 와 를 3D로 변환한 와 겹치는 영역(위의 그림에서 회색 동그라미 부분)은 에서 제거합니다.
최종적으로 가 가 되는거고, 가 가 되는 것입니다. 에 대해 각 정점마다 distance map을 를 계산하고 이를 기반으로 전체 distance d를 구합니다. 최종적으로 첫번째 수식처럼 새로운 정점은 기존 정점에서 d를 더해서 구하게 됩니다. 이후 최종적으로 Laplacian smoothing을 거쳐서 surface를 부드럽게 합니다.

왼쪽에 비해서 오른쪽 결과를 보면 머리카락, 팔, 다리가 얇아진 것을 확인할 수 있습니다.
Color Back-projection
여러 시점에서 생성된 color 이미지들을 기준으로 3D mesh의 각 정점이 어디에 위치하는지 계산해서 해당 위치에서 색깔을 거꾸로 가져와서 texture를 입히는 방식입니다.

대부분의 그림들이 A나 T-pose를 하고 있기 때문에 위와 같이 Charactegen 모델을 통해서 4개의 뷰 이미지를 얻고, 이를 기반으로 texture를 업데이트 합니다. 보이지 않는 영역은 interpolation을 통해서 채워넣습니다.

결과적으로 왼쪽에서 오른쪽으로 더 나은 texture가 보이는 것을 확인할 수 있습니다.
Rigging and Retargeting
지금까지 생성한 3D 캐릭터에 애니메이션을 적용하기 위해, 먼저 Mixamo 툴을 사용하여 자동으로 rigging을 수행합니다. 이후 Rokoko의 모션 데이터를 캐릭터에 적용(retargeting)하며, 각 정점의 skinning weight는 Blender를 통해 자동 계산됩니다.
Stylized Contour Restoration
지금까지의 과정을 진행하면 왼쪽의 그림처럼 윤곽선이 제거된 이미지들에 대한 animation이 가능합니다. 여기에 윤곽선을 다시 넣기 위해서 stylization network를 사용합니다.
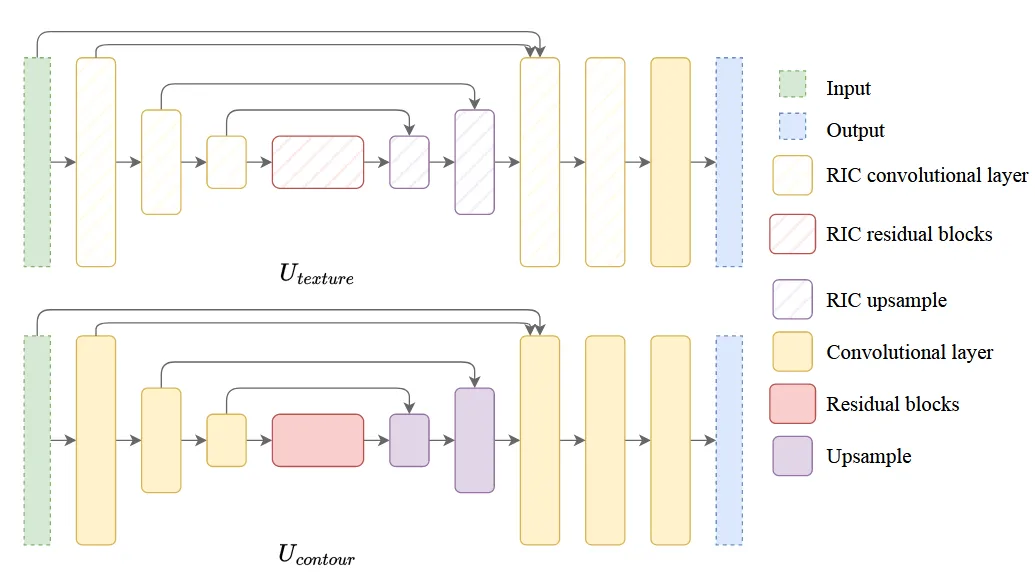
Network Architecture
Stylization network는 2개의 U-Net을 순차적으로 연결한 구조로 이루어져 있습니다. 첫번째 는 내부 텍스철르 복원하는 역할이고, 2단계 는 외곽 윤곽선을 다시 그려주는 역할입니다. 일반적인 U-Net의 convolution layer는 회전을 인식하지 못하는 경우가 있기 때문에 의 convolution layer를 RIC(Roation-Invarian Coordinate) convolution으로 교체 했습니다.
Geometry-aware Inputs
프레임마다 스타일이 일관되게 유지되되록 하는 과정입니다. 현재 프레임의 color image(F), foreground mask(), positional hint(), edge map() 4가지 정보를 이용해서 스타일을 유지합니다.
Positional hint 는 각 프레임마다 (x,y)위치를 정규화된 좌표로 제공해줍니다. 따라서 프레임마다 캐릭터가 회전하더라도 스타일이 유지될 수 있는 정보를 제공해줍니다. Edge map 는 프레임마다 생성된 z-depth map에서 canny edge를 검출하는 값입니다.
에는 값이 들어가서 O’을 출력하고, 에 정보를 넣어서 최종적인 결과 O를 생성합니다.
Patch-based Training
큰 이미지를 한 번에 학습시키는 대신, 32×32 크기의 패치들을 샘플링하여 U-Net을 학습시킵니다. 각 패치에 대해 내부 texture와 contour을 예측하도록 학습하며, 손실 함수로는 L1, adversarial, VGG loss를 사용합니다.
중간 출력 O′와 윤곽선 제거된 이미지 간의 차이를 기준으로 를 업데이트하고, 최종 출력 O와 원본 이미지 I 간의 차이를 기준으로 를 업데이트합니다.
Experiments
Runtime
RTX 4090 GPU 1대 기준
contour removal: 0.1s
3D character generation: 2~3m
online rigging: 1~2m
stylization network training: 5~10m
frame rendering in Blender with Eevee: 0.1s/frame
stylization network inference: 0.2s/frame
Total: 10~15m
Comparison to State-of-the-Art Methods
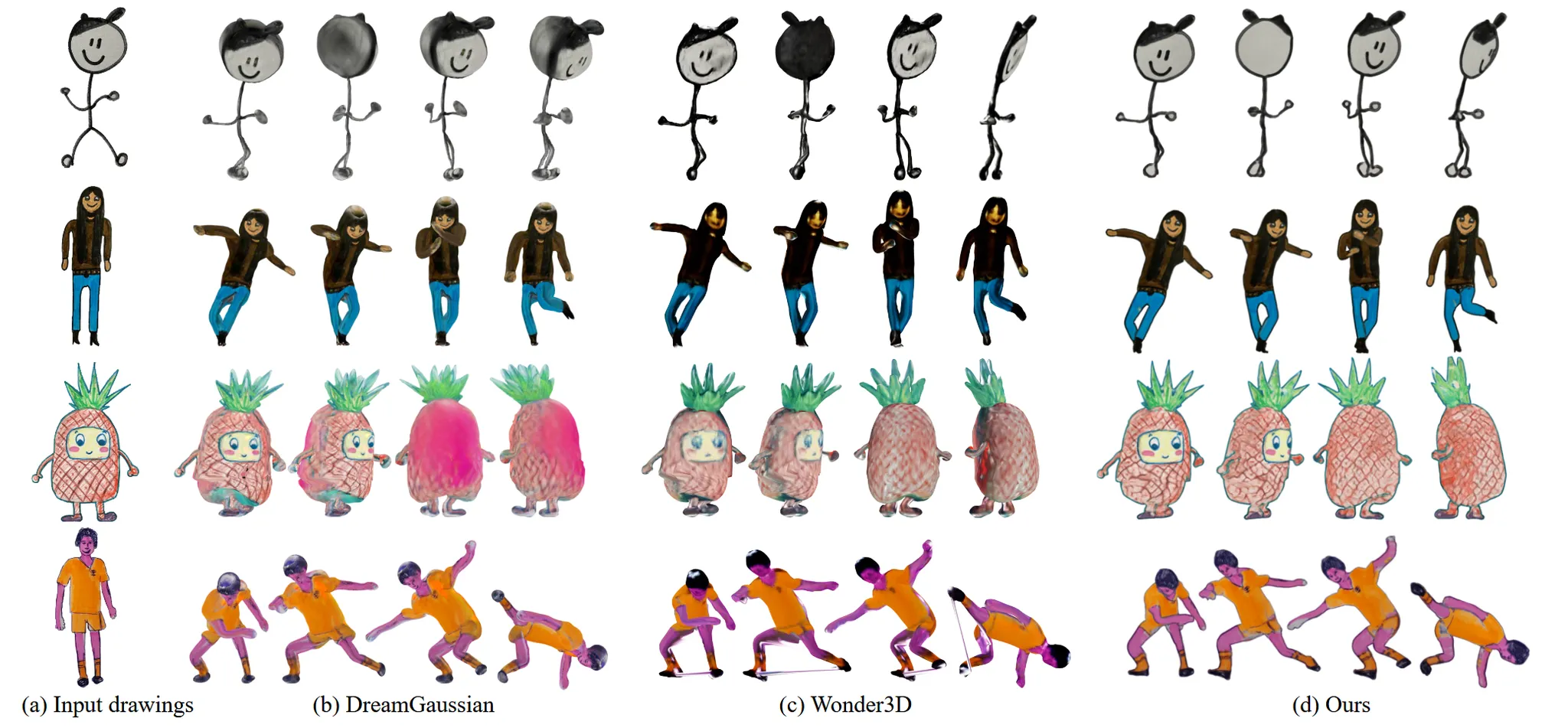
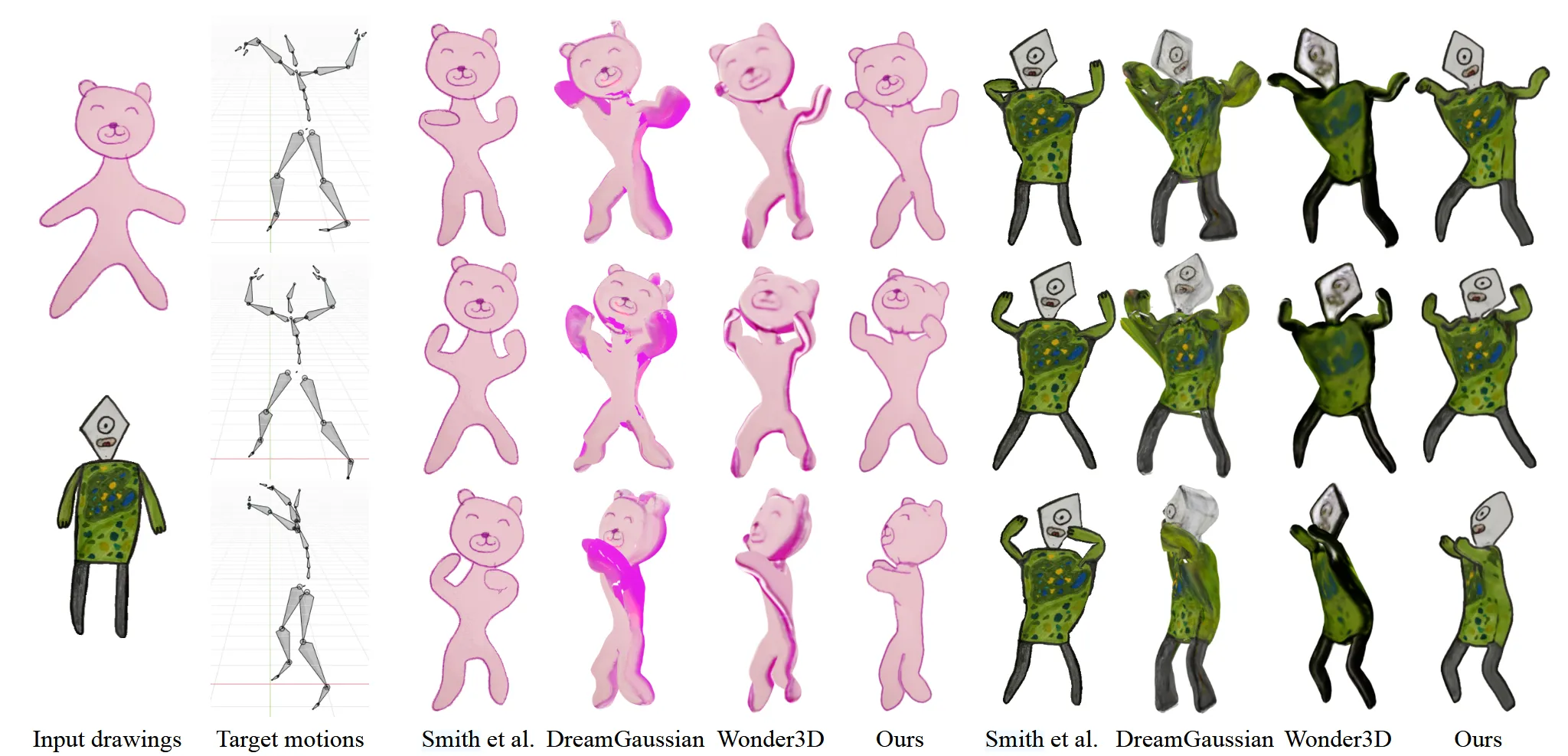
맨위의 target motion에 대해서 2번째 줄은 현재 SoTa모델의 결과 3번째 줄은 DrawingSpinUp 논문의 결과입니다. 확실히 3D 애니메이션 표현은 DrawingSpinUp 모델에서만 표현된 것을 확인할 수 있습니다.

다른 Imgae-to-3D모델로 3D를 생성한 후 애니메이션 과정은 동일하게 진행했을 때의 결과를 비교했습니다. Dreamgaussian은 texture특히 뒷부분에서의 결과가 망가진 것을 확인할 수 있습니다. Wonder3D 결과는 어느정도 consistency하지만, 디테일한 부분에서 윤곽선을 제거한 Ours가 조금 더 좋은것을 알 수 있습니다.
Perceptual User Study
사람들에게 얼마나 target motion과 일치하는지에 대한 MC(Motion Consistency)와 원본 스타일을 얼마나 잘 유지하는지에 대한 SP(Style Preservation)에 대해서 조사를 했습니다. 15개 그룹에 53명에게 5점 만점에 대해서 조사를 진행했습니다.
MC: 3.85 (Smith), 4.30 (DreamGaussian), 4.30 (Wonder3D), and 4.55 (Ours)
SP: 4.18 (Smith), 3.65 (DreamGaussian), 3.50 (Wonder3D), and 4.53 (Ours)
Ablation Study
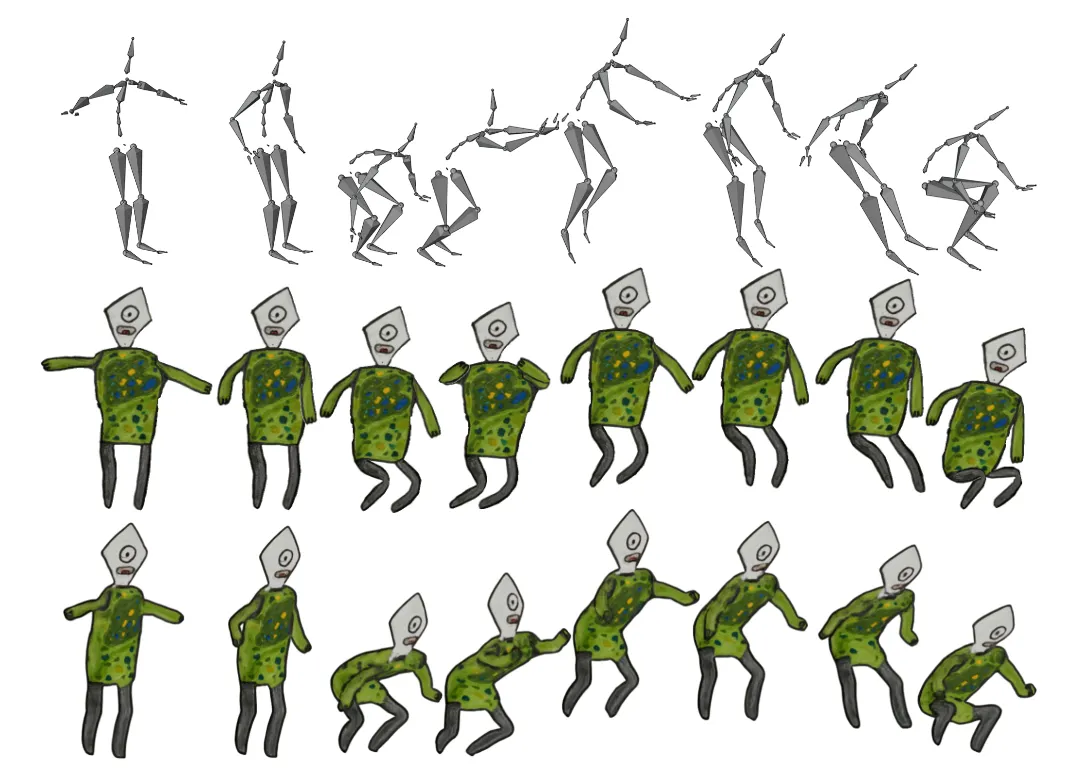
윤곽선 제거를 하지 않았을 때 이후의 과정을 비교한 결과입니다. 위에 안한 결과, 아래가 한 결과입니다. 자연스러운 면에서 확실히 윤곽선을 제거한게 더 좋은 것을 확인할 수 있습니다.
맨 윗줄은 아무것도 refine하지 않은 것, 두번째는 cutting을 진행한 결과, 세번째는 cutting과 thin을 진행한 결과입니다.
위의 결과는 Unet에서 일반적인 convolution을 아래는 RIC convolution을 사용한 결과입니다. 확실히 회전할 때 디테일한 부분의 결과가 좋아집니다.
Conclusion
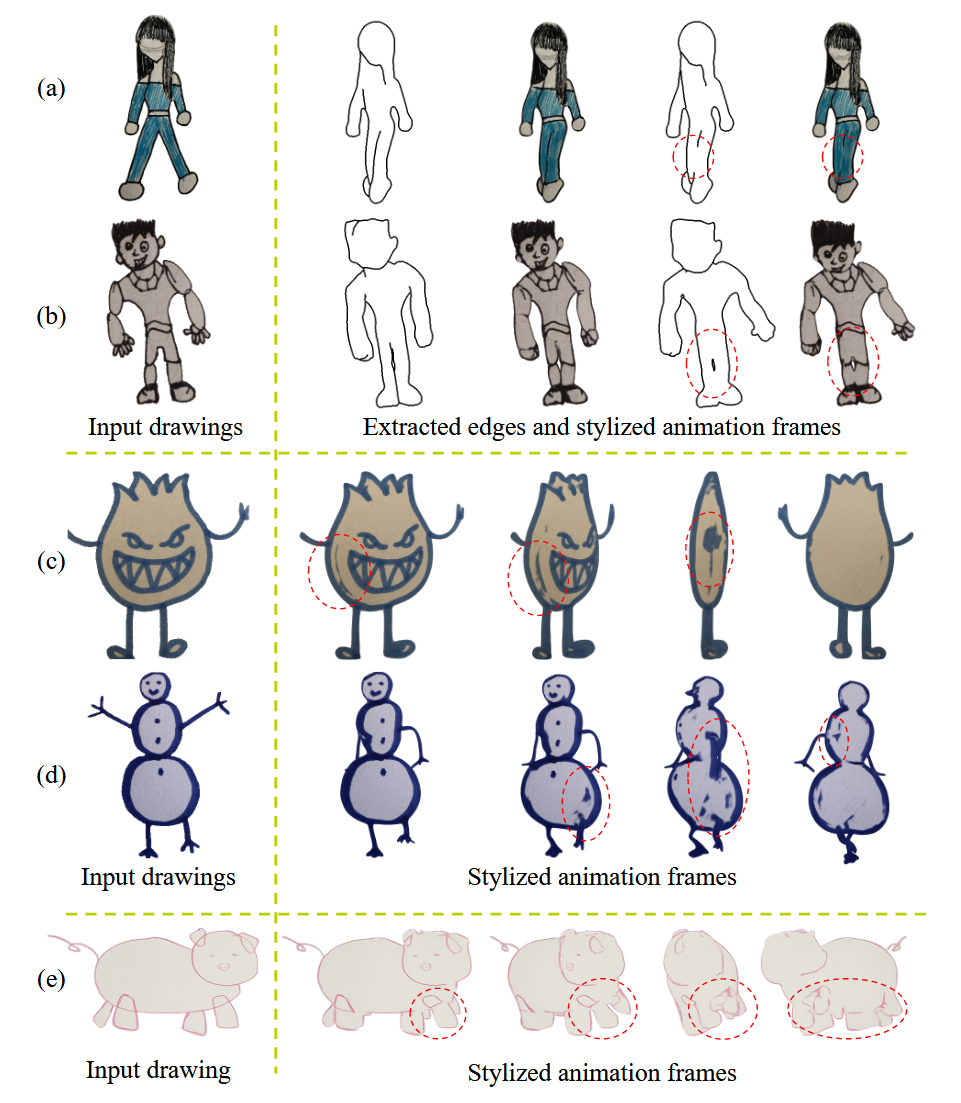
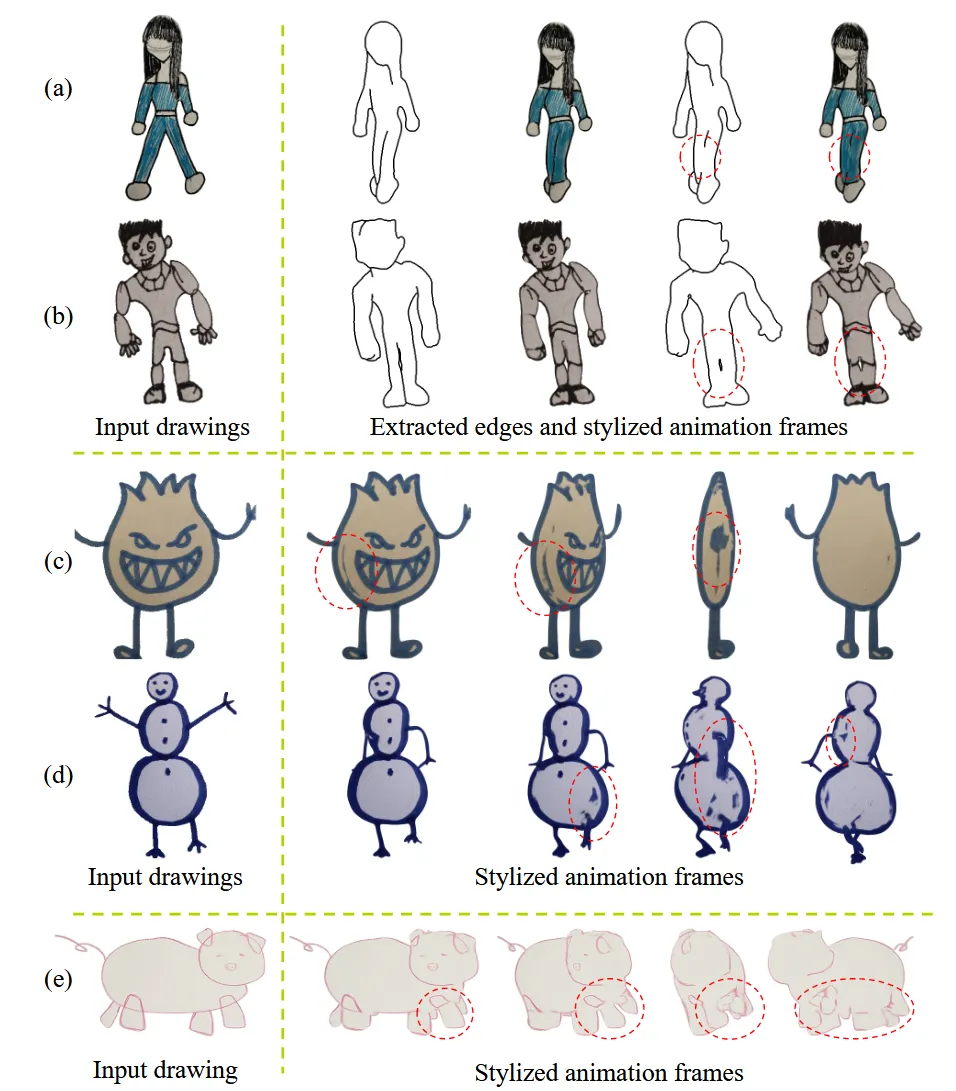
손으로 그린 그림에 대해서 윤곽선을 제거하고 애니메이션을 적용하는 훌륭한 모델을 만들었지만 몇가지의 한계점은 존재했습니다. 첫번째로 입력으로 들어가는 캐릭터의 포즈가 A나 T자의 포즈를 하고 있다는 가정입니다. 두번째로 윤곽선의 threshold를 잘못 정하면 위의 그림 a와 b처럼 잘못된 결과를 야기합니다. 세번째로 c와 d처럼 윤곽선이 두꺼운 결과는 잘 뽑지 못합니다. 추가적으로 그림이 너무 추상적이거나 e그림처럼 두발로 걸어다니는 형태가 아니면 잘 예측하지 못합니다.
