DINO(Emerging Properties in Self-Supervised Vision Transformers) 논문리뷰
논문 링크
https://arxiv.org/abs/2104.14294Abstract
이 논문을 통해서 ViT의 self-supervised learning이 CNN에 비해서 눈에띄는 속성을 갖는지 확인해볼 것이다.
논문에서는 아래와 같은 특징을 발견했다.
- Supervised ViT나 Convnets에는 없는 semantic segmentation에 대한 명시적인 정보가 포함되어있다.

해당 그림이 Self-supersied ViT의 결과인데 물체에 대한 정보를 파악한 것을 알 수 있다. 아래에 자세히 설명하겠다.
- 이러한 특징들은 k-NN을 이용해서 분류했을 때 ImageNet에서 78.3%의 높은 정확도를 달성했다.
추가적으로 momentum encoder, multi-crop training과 작은 패치들을 이용한 ViT의 중요성도 설명할 것이다.
Introduction
Computer Vision 분야에서 ViT는 혁신적인 변화를 가져왔다. 하지만 여전히 문제가 존재한다.
더 많은 계산량, 더 많은 데이터 그리고 모델이 이미지 내의 고유한 특징을 잘 학습하지 못한다.
추가적으로 설명하자면 CNN은 필터를 이용해서 학습을 진행하기 때문에 local정보를, ViT는 패치들을 이용해서 attention을 학습하기때문에 global정보를 잘 학습한다과 알려졌다.
NLP에서 성공의 주요 요소 중 하나는 self-supervised learning 방식이다(BERT, GPT). 이를 ViT에도 적용해보자는 것이 이 논문의 핵심 내용이다.
Abstract부분에서 언급한 내용들을 기반으로 논문에서는 DINO라는 프레임워크를 제시했다.
다른 논문들과 다르게 predictor, normalization, contrastive loss를 사용하지 않고 ViT와 CNN모두에게 범용적으로 적용이 가능하다.
시간도 더 적게 걸렸다고 한다. 2개의 8-GPU서버를 이용해서 3일 걸렸다고 한다.
Reltated work
Self-supervised learning
각각의 이미지는 독립된 class이고, 각 이미지를 augmentation(변형)을 통해서 생성한 이미지는 동일한 class라는 개념인 instance classification를 이용해서 학습을 진행한다.
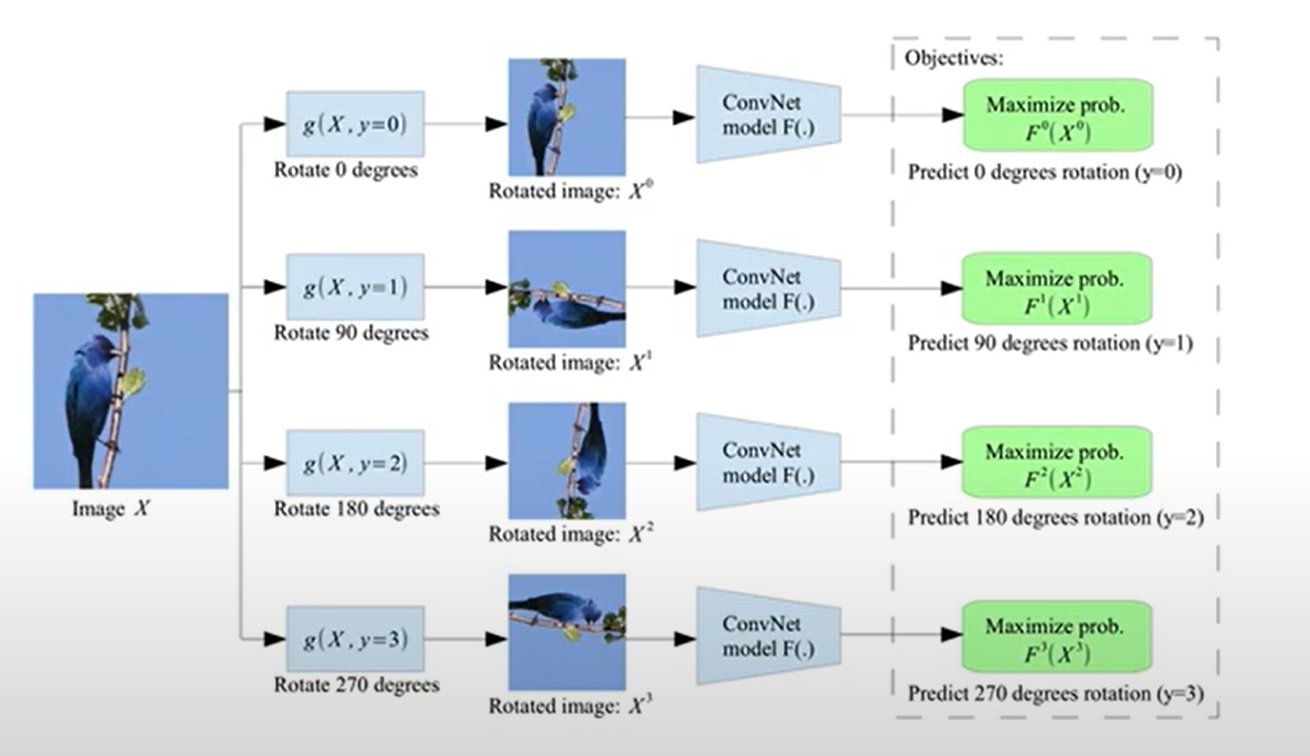
하지만 각각의 이미지가 독립된 class이므로 많은 수의 이미지를 학습할 수 없다.
이에 noise contrastive estimator(NCE)라는 방식이 나왔다. CLIP에서 사용하는 contrastive learning방식과 유사한데 여기서 positive pair는 원본이미지의 변형된 이미지, negative pair는 다른 이미지가 된다.
하지만 이 방식 역시 많은 수의 데이터들을 비교해야된다는 문제가 발생한다.
Recent works
BYOL: momentum encoder를 사용해 학습을 진행. online network와 target network에 대해서 가중치의 지수 이동 평균을 통해서 안정적인 학습이 되는 방식이다. 이 방식은 DINO에서도 사용되기때문에 아래에서 자세히 설명하겠다.
Self-training and knowledge distillation
Self-training
레이블이 없는 데이터를 활용하여 모델의 성능을 향상시키는 방법
- 초기 소량의 레이블이 있는 데이터를 이용해서 대용량 데이터의 레이블을 할당해준다(Hard: One-hot방식, Soft: 각 확률값을 할당)
- 해당 레이블을 이용해서 대용량 데이터를 학습
knowledge distillation
위의 방식 중 Soft label은 knowledge distillation에서 활용된다.
knowledge distillation은 작은 네트워크가 큰 네트워크를 모방하는 방식이다. 주로 모델 경량화에서 사용된다.
knowledge distillation을 이용해서 self-training 방식을 활용하자는 방법이 제시됐다. 레이블이 있는 데이터를 학습한 teacher모델에 대해서 레이블이 없는 데이터로 학습하는 student 모델을 닮게 학습하는 것이다.
해당방식이 이 논문에서 사용되기는 하지만 위에서 설명한 방식은 사전에 학습된 teacher model에대해서 student가 닮아간다면, 논문에서는 2모델 모두 학습 과정에서 파라미터 값이 업데이트가 된다. 또한 모델 경량화에서 student모델이 조금더 가벼운 모델로 설정된다고 했는데 해당 논문에서는 student와 teacher이 동일한 모델을 사용한다.
Approach
SSL with Knowlege Distillation
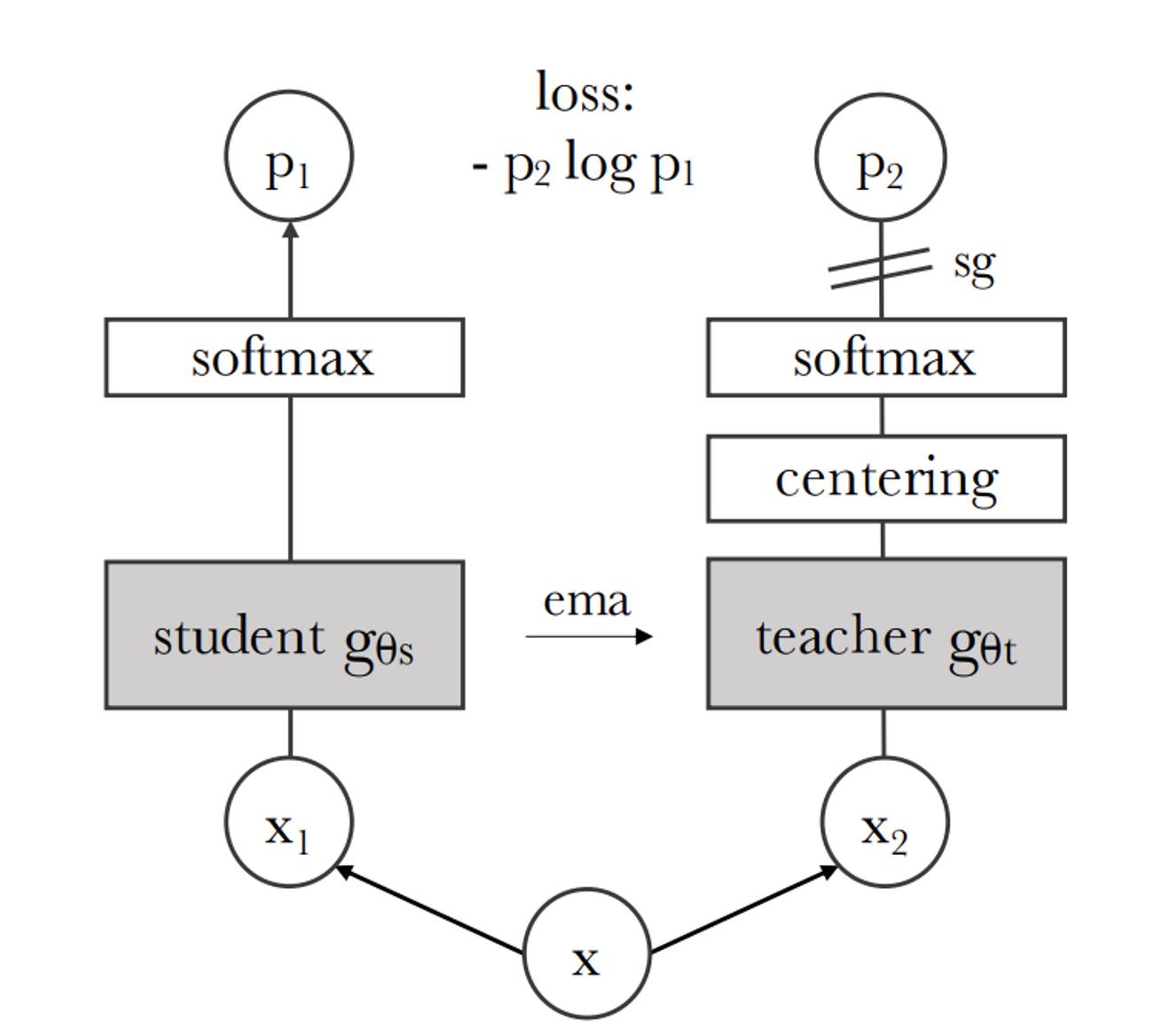

gt.parms = gs.parms
teacher와 student 모델의 파라미터를 동일시하며 시작
x1, x2 = augment(x), augment(x)
이미지에 대해서 augmentation 진행
s1, s2 = gs(x1), gs(x2)
t1, t2 = gt(x1), gt(x2)
student와 teacher에 대해서 x1,x2의 이미지에 대한 output을 각각 추출
def H(t, s):
t = t.detach() # stop gradient
s = softmax(s / tps, dim=1)
t = softmax((t - C) / tpt, dim=1) # center + sharpen
return - (t * log(s)).sum(dim=1).mean()H함수는 t에대해서는 gradient를 update하지 않고 s를 update 하기위해서 softmax를 활용해서 loss를 구한다
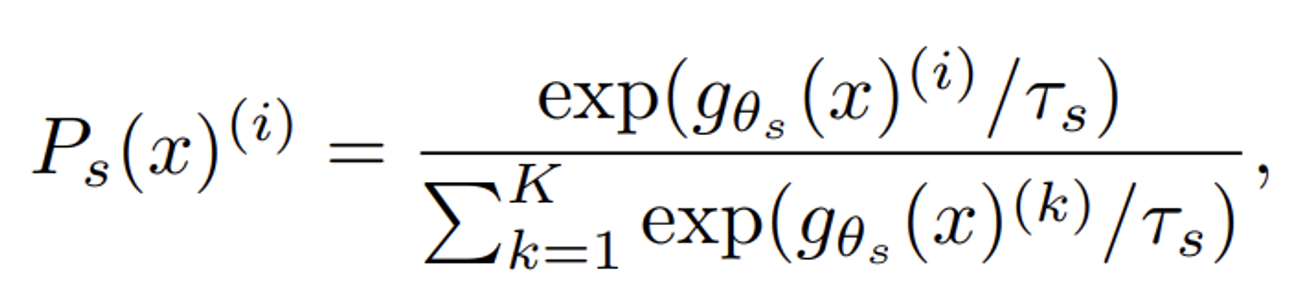
softmax를 구하는 식은 다음과 같고 분모의 temperature 값을 이용해서 sharpness하게 만든다.
Sharpening 은 softmax 함수에 적용되는 온도 매개변수를 조정하여 feature 벡터를 정규화하는 것을 의미
T가 커질수록 확률 분포가 평평해지고, T값이 낮을수록 확률 분포가 선명해진다.
또한 return 윗부분에 t-C를 통해서 Centring도 진행한다.
Centering 은 teacher 네트워크가 생성한 feature 벡터의 평균을 각 벡터에서 빼는 방법입니다. 이를 통해 어떤 차원도 지배하지 않도록 하고 feature 벡터가 더 균일하게 분포되도록 합니다.
예시
[4-6, 6-6, 8-6] = [-2, 0, 2]
최종적으로 return 값은 cross-entropy loss를 사용한다
global & local views
global view: 224x224 / local view: 96x96
이미지에 대해서 와 와 같은 global view와 이에 비해 더 작은 resoultion(해상도)를 갖는 local view가 존재한다
student 모델에 대해서 모든 view들의 값이 지나고, teacher모델은 오직 global view만 지난다.

수식을 자세히 보면 x라는 데이터는 global 값만을 갖고 이는 teacher에서 사용된다. 다음으로 x’데이터는 V라는 집합에 있는 데이터 즉 원본 이미지로부터 변형된 모든 값을 나타내므로 local&global 모든 값들이 될 수 있다. 단 teacher에서 선택한 global view의 이미지는 안된다.
Teacher Network
네트워크를 업데이트 하는 방법으로 student network의 가중치에 대한 EMA(Exponential Moving Average)을 사용했다.
EMA는 위와 같고 λ 코사인 스케줄을 따라 0.996에서 1로 변한다.
momentum encoder는 원래 queue(큐)나 contrastive learning에서 사용하지만 DINO에서는 사용되지 않기 때문에 학생 네트워크의 과거 상태를 유지하여 Teacher 네트워크를 구성하는 역할을 한다.
Network architecture
network(g)는 projection head(h)와 backbone(f)로 구성되어 있다.
backbone(f)는 ViT나 ResNet이다.
projection head(h)는 3개의 layer를 가진 MLP로 나타나 있고 이는 2048차원으로 매핑해준다.
추가적으로 BN(Batch Normalization)을 사용하지 않는다.
Avoiding collapse
Centering과 Sharpening을 통해서 collapse를 피한다.
Centring은 위에서도 설명했지만 teacher 네트워크가 생성한 feature 벡터의 평균을 각 벡터에서 빼는 방법
여기서 c는 centering 벡터로 EMA를 통해서 업데이트 된다
여기서 m은 업데이트 속도 매개변수, B는 배치 크기
Sharpening은 Centering의 반대의 효과로 softmax값을 uniform하게 하거나, 반대로 하나의 값만을 높일 수 있다.
- Centering: 특정 차원이 지배하지 않도록 하지만, 출력이 균일 분포로 붕괴하는 경향이 있습니다.
- Sharpening: 출력이 균일 분포로 붕괴하는 것을 방지하지만, 특정 차원이 지배할 수 있습니다.
따라서 2개의 방법을 적절하게 결합하여 collapse를 방지
Implementation and evaluation protocols
하이퍼파라미터 설정
τs: 0.1 / τt: 0.04 to 0.07
augmentation: BYOL과 동일(color jittering,Gaussian blur and solarization) and multi-crop
Evaluation protocols
- Linear Evaluation:
- 고정된 특징 사용: 사전 학습된 모델의 특징을 고정(frozen)시키고, 이 특징에 대해 선형 분류기를 학습
- 데이터 증강: 학습 중에는 random resize crops과 horizontal flips을 적용
- 평가 시에는 central crop만 사용하여 정확도를 측정
- Finetuning Evaluation:
- 사전 학습된 가중치 사용: 사전 학습된 가중치로 네트워크를 초기화하고, 다운스트림 작업에서 이 가중치를 finetuning
- k-NN Evaluation:
- 사전 학습된 모델을 고정(freeze)시킨 상태에서, 다운스트림 작업의 학습 데이터에 대한 특징을 계산하고 저장
- k개의 가장 가까운 특징(k-nearest neighbors)을 찾고, 이 특징들이 투표하여 레이블을 결정(k=20)
Main Results
Comparing with SSL frameworks on ImageNet
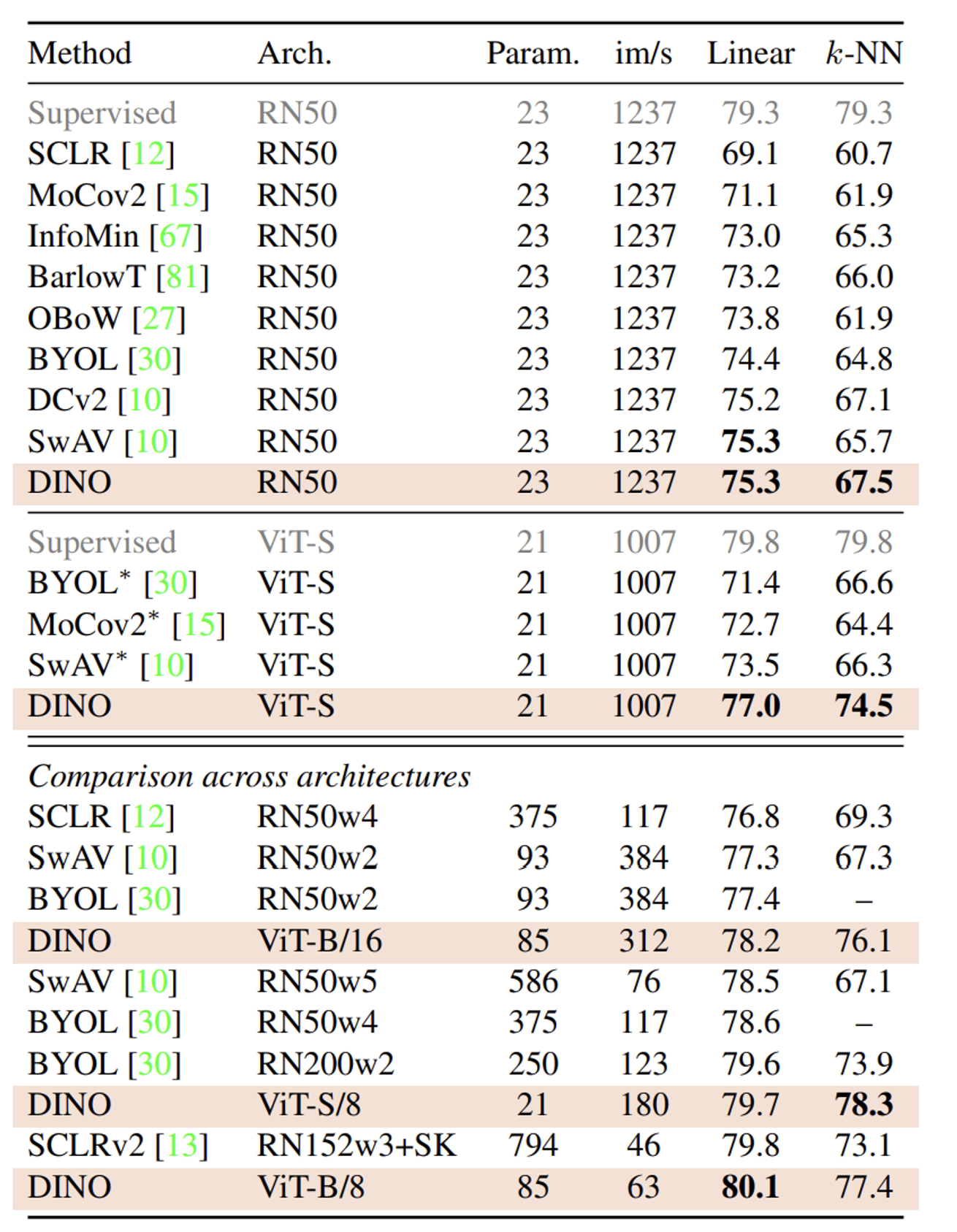
throughput (im/s): 초당 이미지 처리 속도
Parameters (M): 모델의 파라미터 수
RN50w2, w4: w는 width를 나타내며 모든층의 채널 수가 2배, 4배라는 것을 의미
SK: Sinkhorn-Knopp
결과 분석
Linear
RN50의 supervised learning시 79.3인 값에 비해 4%가 낮아진 DINO의 RN50이다. SwAV모델과 함께 self-supervised learning에서 SoTA인것을 알 수 있다.
또한 ViT-S에서는 supervise learning시 79.8인 값에 비해 2.8%밖에 차이가 안난 77%를 기록했다. 심지어 기존 SoTA모델인 SwAV와 3.5%가 차이난다.
마지막으로 모든 모델에서 아키텍처를 통일하지 않고 수행한 결과 역시 SoTA값인 80.1을 기록한 것을 알 수 있다.
k-NN
linear에 비해서 성능은 떨어지지만 다른 모델들과 비교한 결과에 비해서는 월등한 성능을 자랑한다.
Properties of ViT trained with SSL
시간관계상 다른 Task에 대해서 DINO의 결과 비교는 생략하고 표만 제시하겠다.
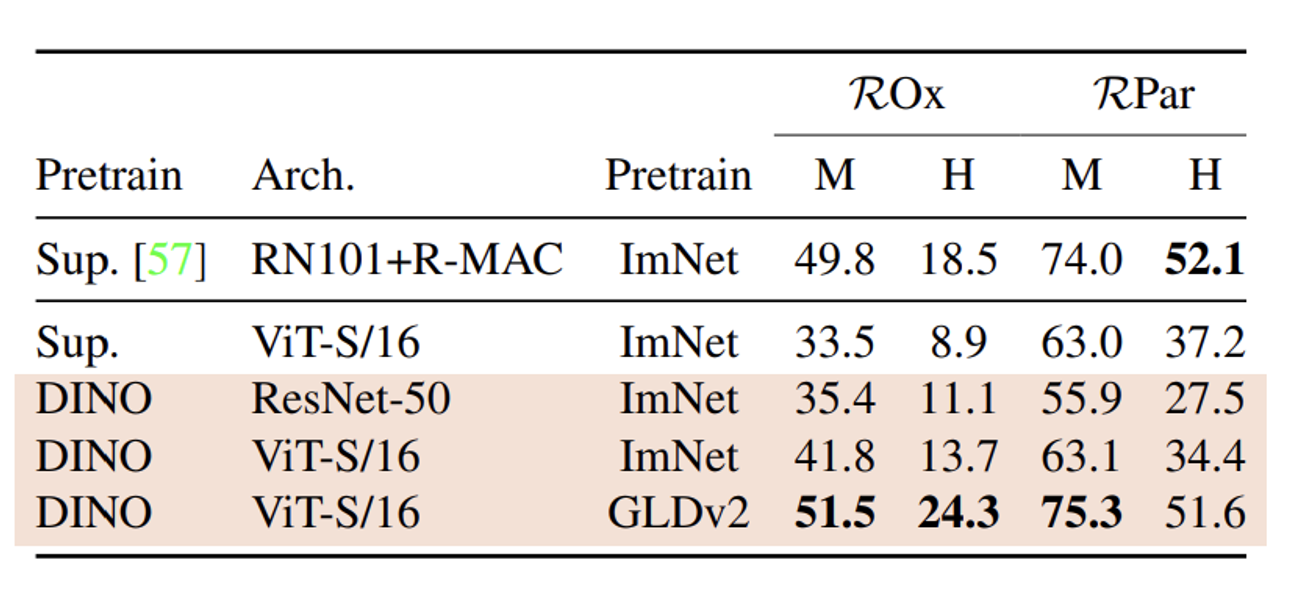
Image retrieval
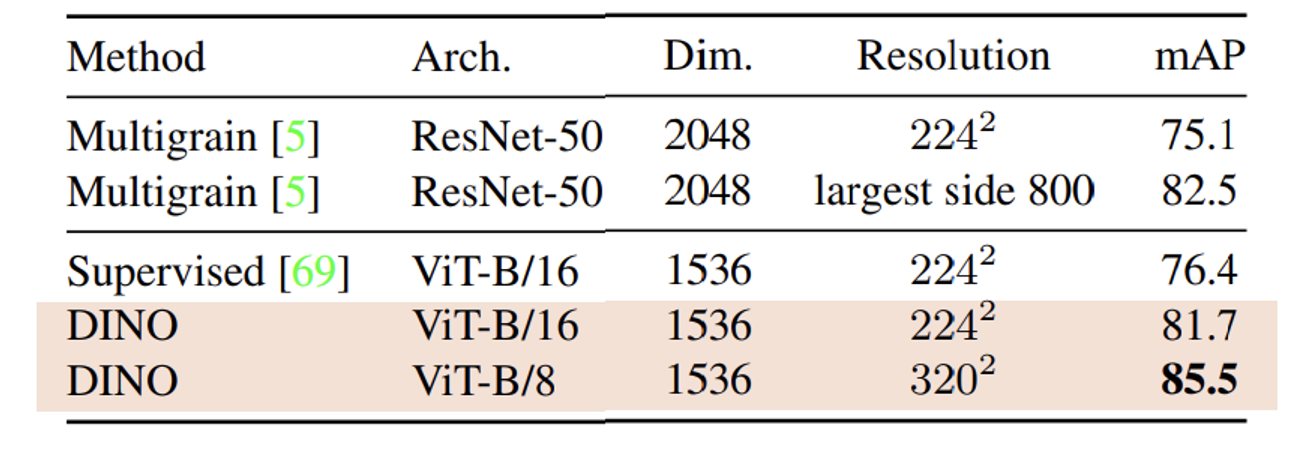
Copy detection
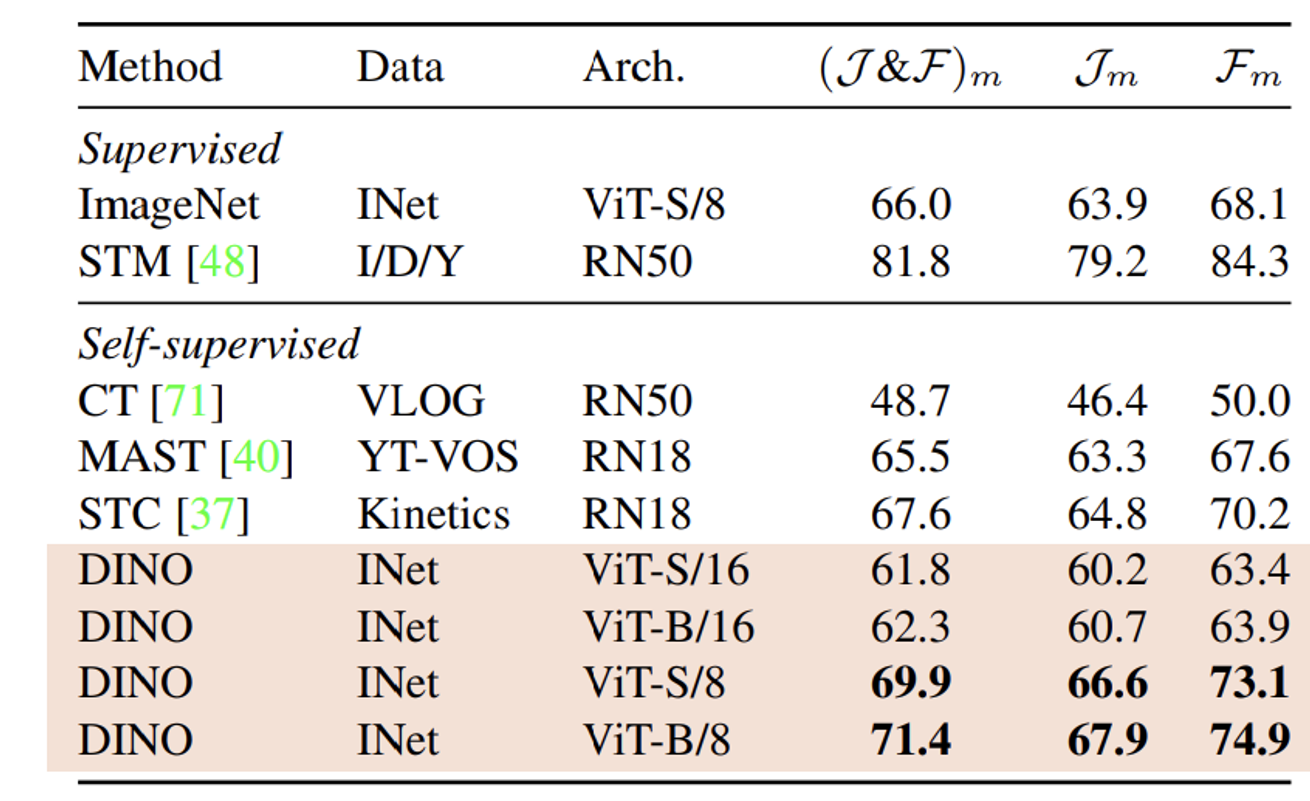
Video object segmentation
Ablation study of DINO
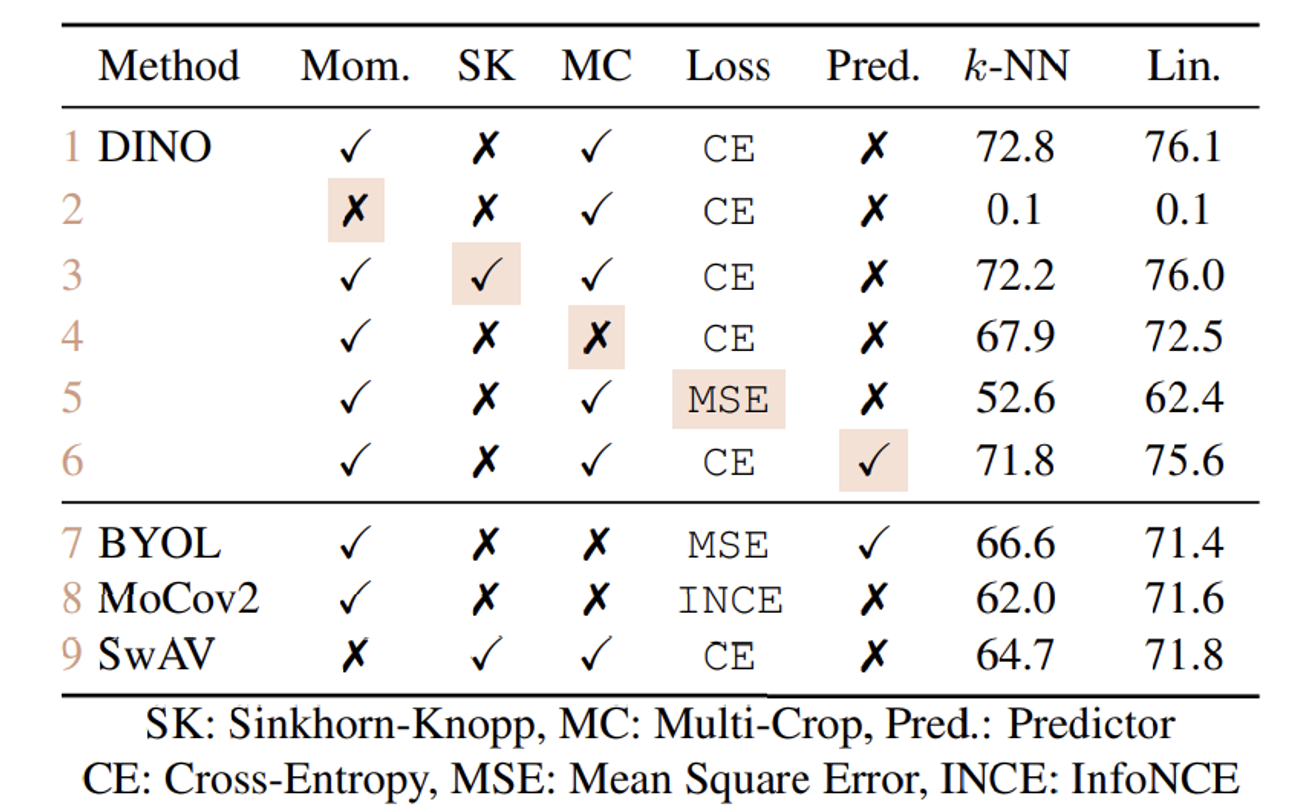
Mom의 값은 momentum인데 이를 제거한 결과가 정말 충격적이다. momentum과 teacher, student model에 대한 중요성을 다시한번 느끼게 됐다.
또한 SK, MC, Loss(CE, MSE), Pred의 유무를 통해서 결과에 대한 납득을 하게 됐다.
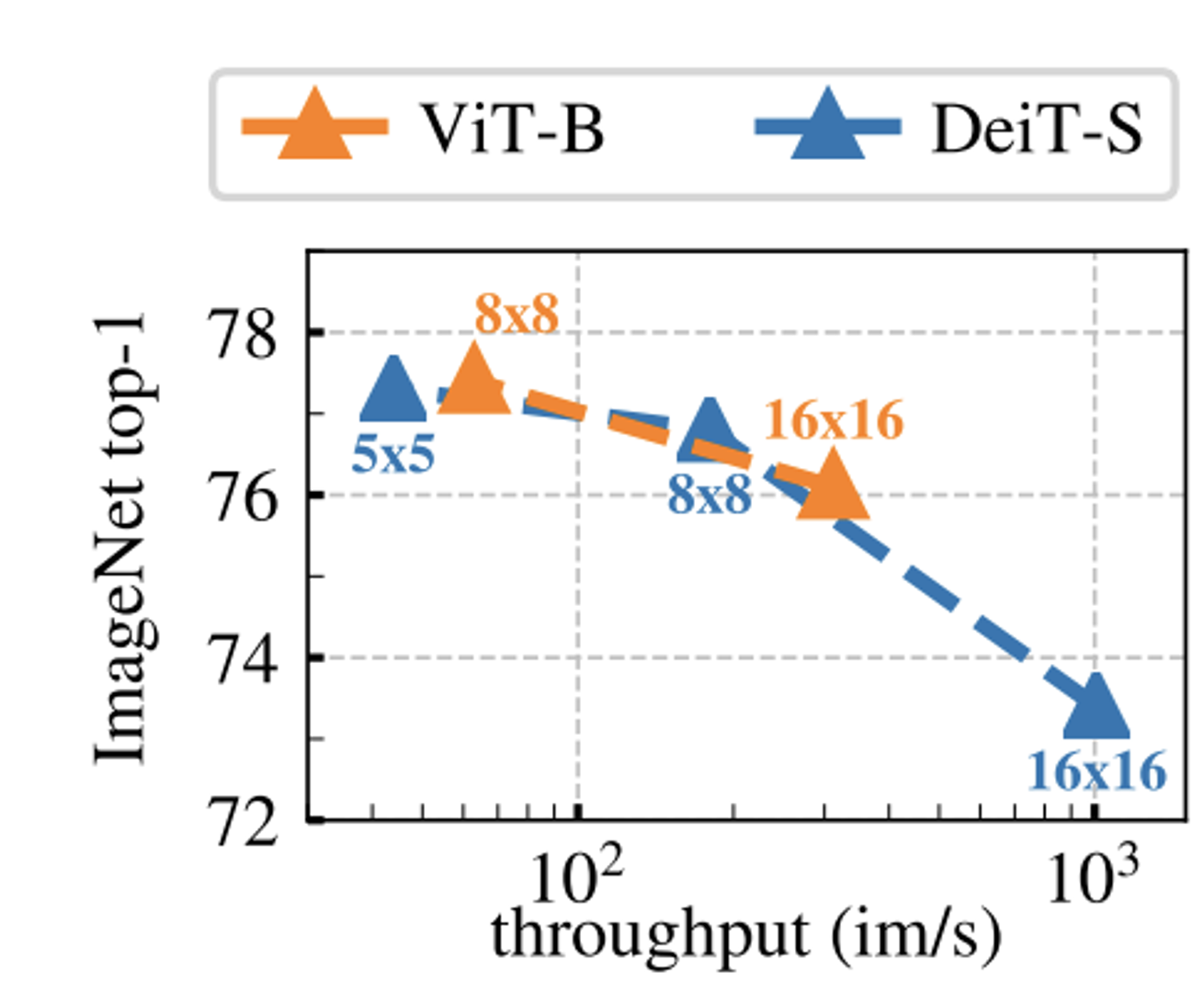
k-NN의 결과에 대해서 패치의 크기가 어떤 영향을 주는지를 나타내는 그림이다.
ViT에서도 알 수 있지만 패치의 크기가 작을수록 성능이 증가하고 computation cost도 증가한다.
속도차이: 5×5 patches, the throughput falls to 44 im/s, vs 180 im/s for 8×8 patches
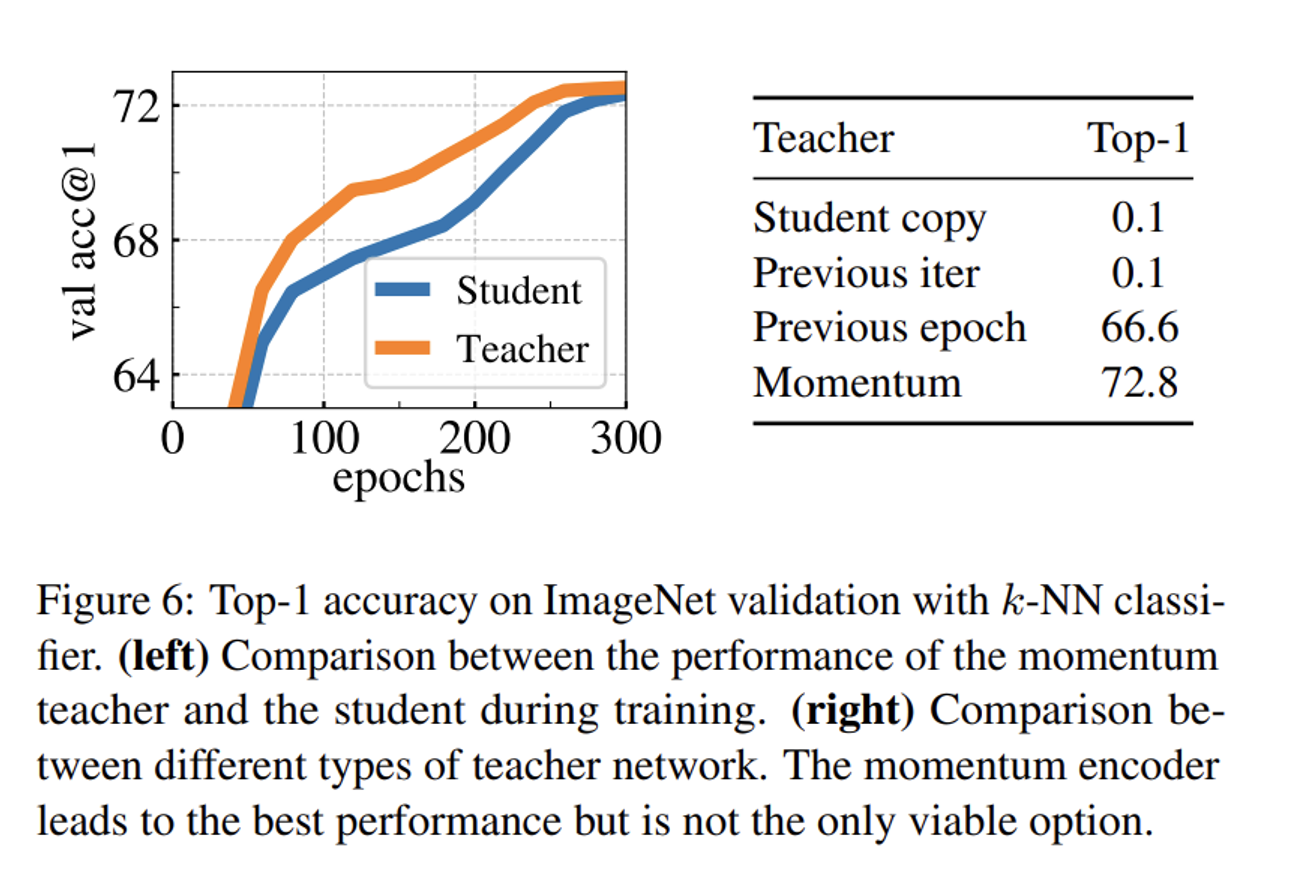
Student copy: Student 네트워크의 현재 상태를 복사하여 Teacher 네트워크로 사용
Previous iter: 이전 반복(iteration)에서 학습된 Student 네트워크를 Teacher 네트워크로 사용
Previous epoch: 이전 에포크(epoch)에서 학습된 Student 네트워크를 Teacher 네트워크로 사용
Momentum: Student 네트워크의 파라미터를 지수 이동 평균(EMA) 방식으로 업데이트하여 Teacher 네트워크를 구성
추가적으로 그림을 보면 항상 Teacher network의 성능이 Student network보다 뛰어난 것을 알 수 있다.
이에 대한 근거로 논문에서는 Polyak-Ruppert averaging를 제시했다. EMA방식이 Polyak-Ruppert averaging의 일종으로, 모델 파라미터를 안정화하고 성능을 향상시킨다.
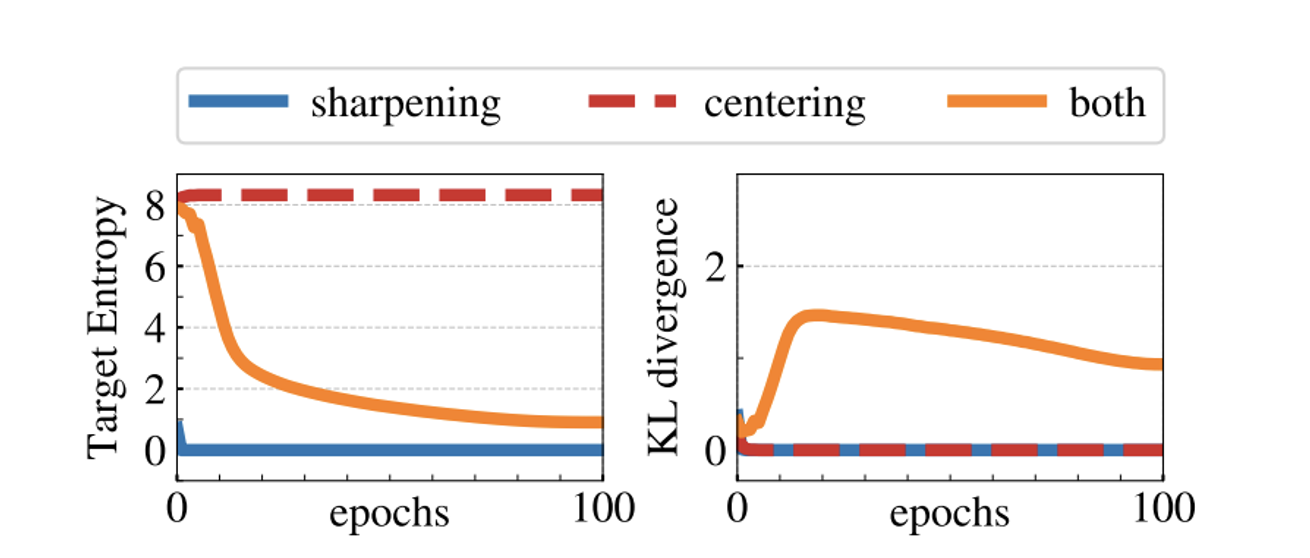
벌써 3번째 설명이라 결론만 말하면 sharpening과 centering은 collapse를 피할 수 있지만 2개의 역할을 반대로 작용한다. 따라서 이를 적절히 활용해야한다.
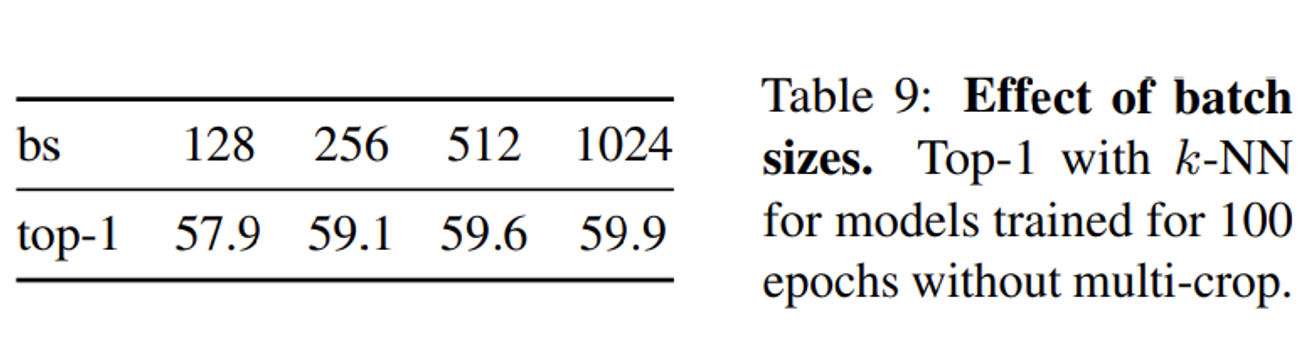
배치가 커질수록 성능이 증가하는건 웬만한 분들은 다들 아실거다. 이에 대한 ablation study의 결과는 위와같다.
Conclusion
결론적으로 이 논문을 쓴 이유는 Self-supervised를 Computer Vision분야에 적용한 결과는 성공적이었다.
추후에 더 많은 데이터를 활용해서 ViT 모델의 DINO를 학습시킨다고 한다.
