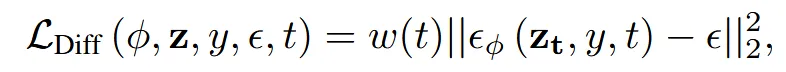
Target Text prompt를 기반으로 이미지를 살짝 편집하는 모델 Delta Denoising Score(DDS)를 설명하도록 하겠습니다. SDS랑 차이점은 위에 보이는 것처럼 target prompt의 SDS와 원본과 맞는 prompt의 SDS를 빼서 진짜 필요한 변화만 남깁니다. 자세한 내용을 아래에서 진행하겠습니다.
Delta Denoising Score(DDS)
SDS overview
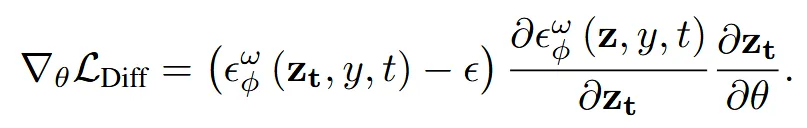
입력 이미지 z, conditioning text y, denoising model 를 이용해서 파라미터 φ를 업데이트하는 과정은 위와 같습니다. Classifier-free guidance(CFG)를 이용해서 text prompt를 반영한 노이즈를 예측하는 과정인 것입니다.

파라미터를 업데이트하면서 점점 text prompt에 맞는 이미지를 생성하게 됩니다. 하지만 SDS는 다양성이 떨어지고 blur한 결과가 나옵니다.

왼쪽은 SDS로 나온 결과이고, 오른쪽은 diffusion으로 나온 결과입니다. 확실히 다양성도 떨어지고 blur한 결과가 SDS에서 나온 것을 확인할 수 있습니다.
Eiditing with SDS
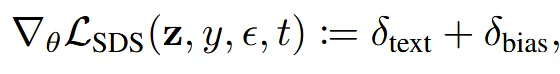
Image의 변형을 가하는 기존 SDS 방법은 위에서 봤던것처럼, 원본 이미지에 노이즈를 더한 다음에 CFG를 활용해서 text prompt를 반영합니다. 맨 위의 결과를 보면 panda를 squirrel로 변경했을 때 다람쥐로 바뀌기는 하지만 결과가 blur해지는 것을 확인할 수 있습니다.
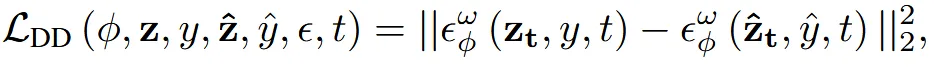
DDS에서는 SDS에는 text prompt에서 text에 맞게 유도하는 부분과, bias를 주는 부분 2가지로 나눌 수 있다고 제시했습니다. 위의 수식처럼 text-aligned 부분인 와 의도하지 않은 방향으로 유도하는 2가지 부분으로 나눌 수 있다고 제시했습니다.
Denoising the Editing Direction
DDS는 원본 이미지와 원본 이미지의 텍스트 설명이 존재한다는 가정으로부터 시작합니다. Source image에 이미지에 대한 설명을 각각 , 라고 하고, 우리가 원하는 이미지와 텍스트를 각각 z와 y라고 하겠습니다. z를 제외한 모든 건 주어져야합니다.
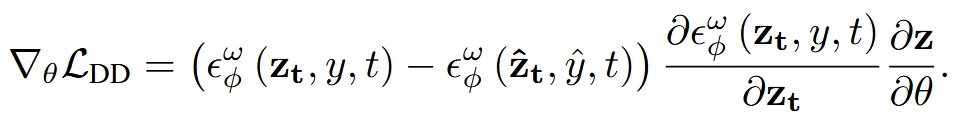
이때 DDS의 수식은 위와 같습니다. 와 는 동일한 sampled noise와 timestep t를 사용합니다.
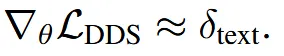
한마디로 2개의 text prompt 차이를 기반으로 진행합니다.

이렇게 2개의 text prompt 차이를 기반으로 학습되는 부분을 text-aligned 부분이라고 정했습니다. DDS의 핵심은 text prompt에 text-aligned 부분과 bias부분이 존재하는데, 2개의 text prompt차이를 기반으로 진행할 경우 bias 두부분이 빼져서 text-aligned 부분만 남게됩니다.

이전에 봤던 그림인데, 기존 이미지에서 동일한 text prompt를 사용해서 SDS를 사용해도 bias가 적용돼서 blur해지는 것을 맨 아래 그림에서 확인할 수 있습니다.
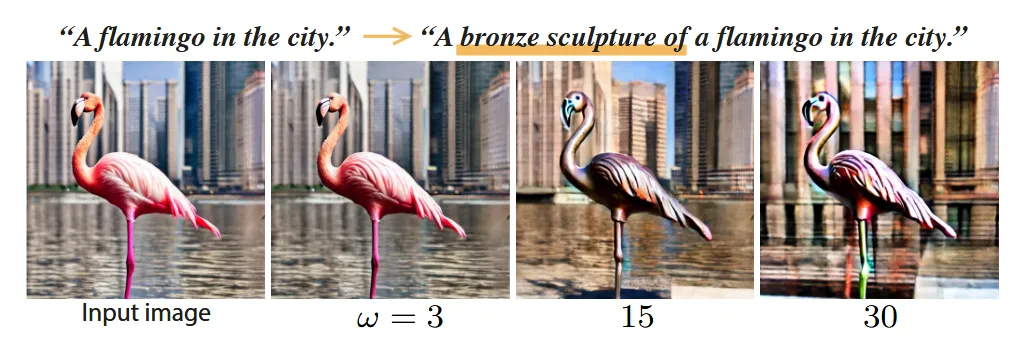
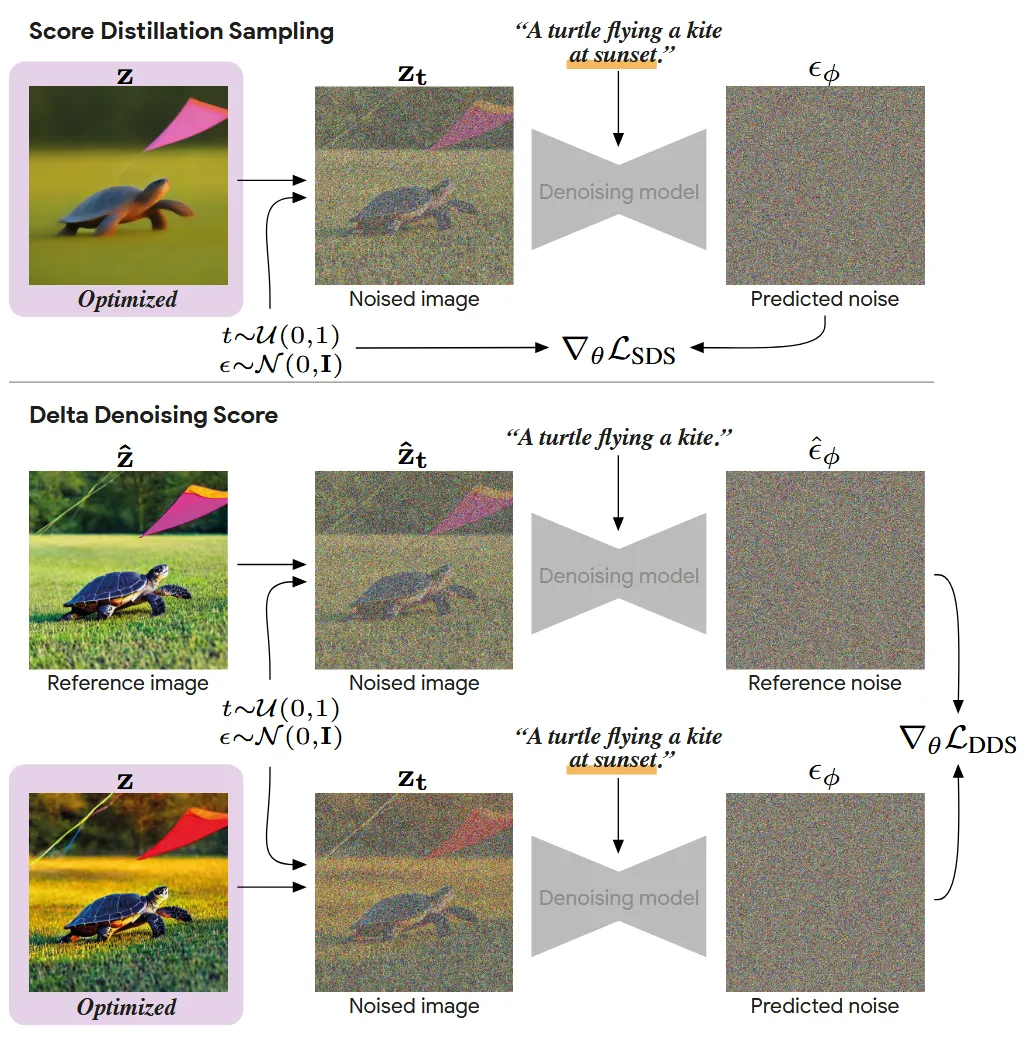
위의 그림이 지금까지의 과정을 요약해주는 그림입니다. hat이 쓰여져있는 부분이 source, hat이 없는 부분이 target입니다. 아래 부분을 보면 SDS를 사용할 경우 bias 부분이 존재하는데 2개의 차이를 기반으로 진행하는 DDS(맨 오른쪽 사진)은 bias가 상쇄돼서 text-aligned 된 부분만 남게 됩니다.
2개의 text prompt차이를 기반으로 하는 DDS도 여전히 classifier guidance의 scale에 영향을 받는 것을 시각적으로 확인할 수 있습니다.
Image-to-Image Translation
위에서 설명한 과정을 진행하기 위해서는 source와 target image에 대한 prompt가 필요하고, real 이미지에서는 성능이 저하되고, 20초 정도의 긴 수정 시간이 필요합니다. 이를 위해서 새로운 unsupervised training pipeline을 제시했습니다.
Unsupervised training with DDS
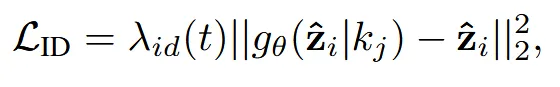
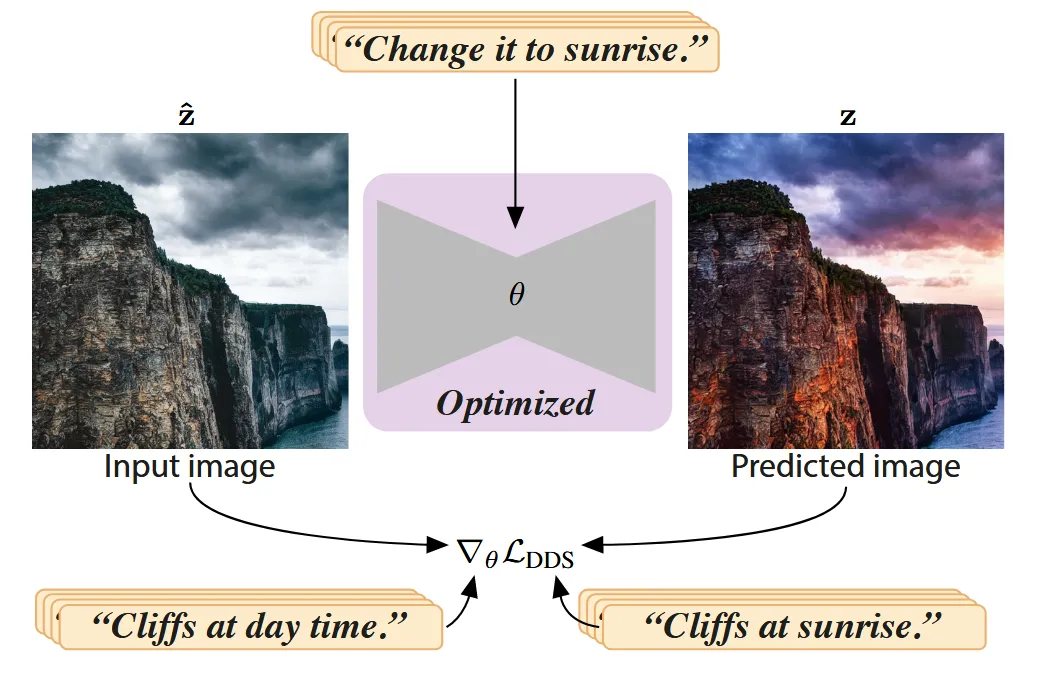
Text condition이 기존에는 source와 target 2개가 필요했는데, 1개만을 이용하기 위해서 위의 학습 방식을 사용합니다. 새로운 학습 방식으로 2 문장의 차이(예: Change it to sunrise) 부분만을 기반으로 2개의 text prompt와 2개의 image의 차이를 학습하는 기존모델에 새로운 condition으로 넣어서, 추론시에는 문장의 차이만으로도 동일한 결과를 낼 수 있도록 합니다.

원본 이미지와 비슷해지도록 weighted identity regularization term을 추가했습니다. 값은 t가 커질수록 점점 작아지도록 설계 했습니다.
DDS with CFG warmup
GAN(Generative Adverserial Network)에서 판별자만 속이면 되기 때문에 특정한 형태로 빠지는 mode collapse 문제가 DDS에서도 text prompt에 맞는 형태로만 바꾸면 점수가 높아지기 때문에 동일하게 발생합니다. 따라서 어떤 이미지가 들어가든, 어떤 텍스트 프롬프트가 들어가든 위의 결과처럼 특정한 사자의 형태로 고정되는 것을 확인할 수 있습니다.
CFG에서 guidance scale을 크게 키울수록 text condition을 더 반영해야 되기 때문에 위와 같은 mode collapse에 빠지기 쉽습니다. 따라서 저자는 warmup scheduler를 이용해서 초기에는 낮은 scale을 사용해서 global한 정보를 학습하고, 이후에 scale을 키워서 디테일한 부분을 학습하도록 했습니다.
