Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention[2025 Neurips]

Signed Distance Functions(SDFs)과 같은 3D shape를 고품질로 나타내는 과정은 많은 연산량이 필요하다. 이에 sparse volume을 사용해서 연산량을 줄여서 고품질 3D shape를 생성하는 Direct3D-S2를 제안했다. Spatial Sparse Attention (SSA)를 통해서 연산량을 줄이고 속도를 높였다. 또한 variational autoencoder (VAE) 모델을 통해서 sparse volumetric을 유지하면서 입력을 latent 공간으로 보내고 다시 decoder를 통해서 output을 생성할 수 있다. Direct3D-S2는 결론적으로 높은 생성 품질과, 1024해상도에서도 8개의 GPU만으로 학습을 가능한 모델이 되었다.
핵심적인 내용은 해상도를 높였지만 오히려 더 적은 GPU를 사용할 수 있는 적은 연산량인거같다. 어떻게 이를 가능하게 했는지를 중점적으로 아래 논문을 리뷰하겠다.
Introduction
이미지나 텍스트로부터 3D를 생성하는 분야는 게임이라 VR, 로보틱스와 같은 많은 분야에서 사용되면서 빠르게 발전되어 왔다. 특히 최근에는 implicit latent representations를 이용하는 방식이 많이 나오고 있다. 이 방식은 압축된 latent 공간에서 고퀄리티의 3D를 생성할 수 있다. 이러한 방식들은 VAE를 통해서 압축된 latent 공간으로 보내지만 여전히 학습 효율성이 떨어져서 많은 수의 GPU를 필요로 한다.
Implicit latent representation은 단순히 Neural Fields를 이용해서 압축된 latent를 만드는 방법이라면, Explicit latent representation 방식은 3D representation을 Grid나 Voxel등 공간적 구조가 명확히 드러나는 형태로 표현하는 방식이다. 이러한 방식은 압축된 latent 자체를 우리가 아는 공간적 구조 형태로 나타냈기 때문에 학습과 수정이 용이하다. 하지만 해상도가 늘어날수록 연산량이 기하급수적으로 늘어나기 때문에 제한적인 해상도가 한계점이다.
Direct3D-S2는 Native Sparse Attention (NSA)에서 영감을 얻은 Spatial Sparse Attention (SSA) 방식을 통해서 explicit latent representation 방식을 활용하지만 1024해상도에서 8개의 GPU만으로도 학습할 수 있도록 모델을 설계했다. 또한 논문에서 VAE가 입력, latent, 출력 모든 단계에서 동일한 형태를 유지하는 방식이 돼서 효율적인 계산을 할 수 있도록 설계했다고 밝혔다.
Related Work
Multi-view Generation and 3D Reconstruction
3D 생성 방식은 2D Stable Diffusion 모델을 이용해서 멀티뷰를 생성하는 방식을 통해서 발전해왔다. 이렇게 생성된 멀티뷰 이미지들은 3D shape을 만드는데 사용된다. 하지만 멀티뷰 방식들은 뷰끼리의 일관성 문제와 최종 생성되는 3D의 퀄리티가 별로라는 문제가 있었다. 또한 멀티뷰 이미지를 3D로 변환하는 과정에서 NeRF나 DMTet 방식이 사용되는데 이과정에서의 계산량도 많이 필요하다.
Large Scale 3D Latent Diffusion Model
2D Latent Diffusion Models(LDMs)을 3D 생성에 사용하는 방식들이 나왔다. Introduction에서도 말했지만 vecset-based 방식인 implicit representation방식들에서 vecset의 크기가 커지면 계산 비용도 커진다. 반대로 voxel-based 방식인 explicit representation 방식은 더 이해하고 학습하기 쉬운 형태로 latent를 나타낸다. 그럼에도 불구하고, latent의 해상도를 늘리면 계산량이 매우커진다는 한계점이 존재한다. 이에따라 논문에서는 계산비용을 줄이는 것을 목표로한다.
Efficient Large Tokens Generation
높은 해상도를 생성하기 위해서 큰 토큰을 효율적으로 다루는 방식은 도전적인 과제다. Native Sparse Attention (NSA)는 효율을 유지하면서 attention 계산 과정에서 토큰을 줄이는 방식을 제안하면서 이 과제를 해결했다. NSA의 방식은 비디오와 large language 모델에 적용되며 계산 효율성을 높였다. 이 논문에서는 NSA를 3D에 맞게 변형한 Spatial Sparse Attention (SSA)를 제안했다. 큰틀은 동일하지만 block partitioning 전략을 3D에 맞게 변형했다.
Sparse SDF VAE
2D와 달리 3D는 mesh, point cloud, implicit fiedls처럼 다양한 방식으로 생성할 수 있다. 이러한 다양성은 기존 3D VAE들은 입력과 latent 그리고 출력값이 서로다른 형태를 갖도록 설계되어 있었다. 이렇게 다른 형태를 갖으면 형태 변환을 하는 과정에서 추가적인 계산량이 존재한다. 본 논문에서는 이를 극복하기 위해서 end-to-end sparse SDF VAE를 사용해서 입력, latent, 출력이 동일한 형태를 갖도록 했다.
의 해상도를 갖는 SDF volume V는 과정을 거쳐 latent representation으로 변환되고, 이는 다시 를 거쳐 SDF를 생성한다.
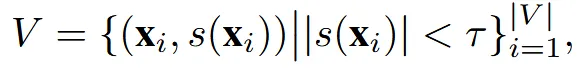
해상도를 높이면 많은 수의 Voxel이 생성되기 때문에 연산량을 줄이기 위해서 물체에 가까운 Voxel만 선택하는 필터링 과정을 위의 수식을 통해서 진행한다. SDF는 물체가 존재하는 부분에서 0을 갖기 때문에 임계치를 기반으로 물체 외부의 Voxel을 제거한다.
Symmetric Network Architecture
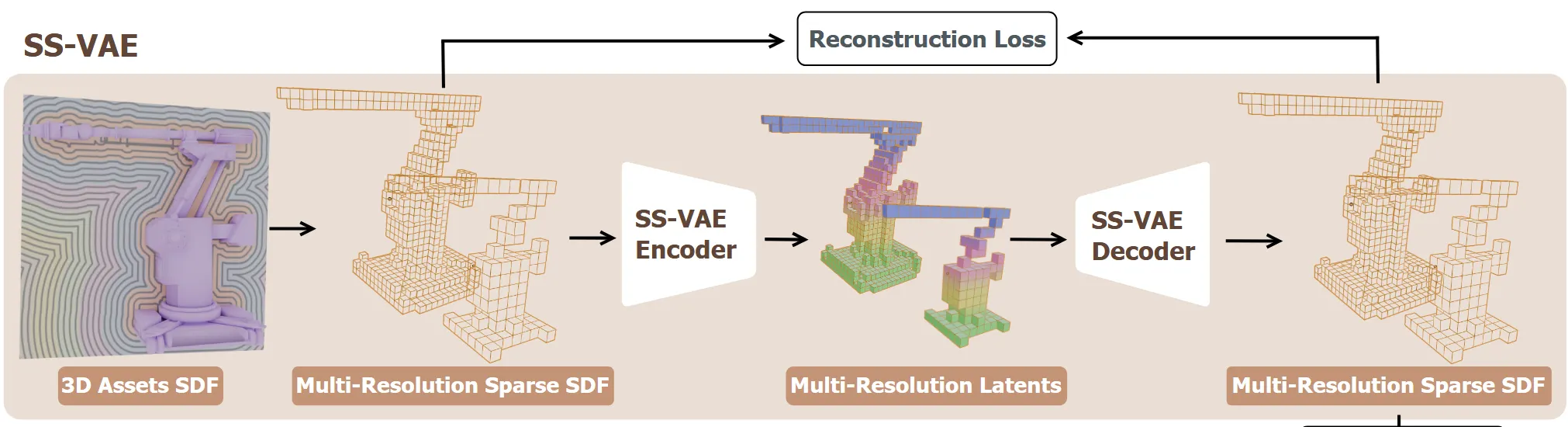
Encoder와 Decoder는 3D Convolution과 transformer를 혼합해서 사용했다. 먼저 3D CNN으로 해상도를 줄이면서 디테일한 특징을 뽑아내고, 그 결과를 토큰으로 만들어 Window attention을 통해 Voxel들끼리의 세밀한 관계를 파악한다. 이러한 3D CNN과 Transformer의 혼합 과정 덕분에 고해상도 데이터를 효율적으로 압축된 latent representation으로 변환할 수 있다. Trellis와 유사하게 각각의 Voxel들은 3D 좌표를 기반으로 positional encoding을 수행하고 3D shifted window attention을 진행하도록 한다.
Training Losses
Decoder를 통해서 생성된 Volume의 경우 입력 voxel에 있는 voxel을 잘 생성한 부분과 새롭게 추가된 부분이 존재한다. 새롭게 추가된 부분이 무작정 틀린게 아닌게 해상도를 높이면 당연히 voxel이 추가되기 때문에 원래 있는 부분의 근처에 적절하게 생기는지 여부가 중요하다.
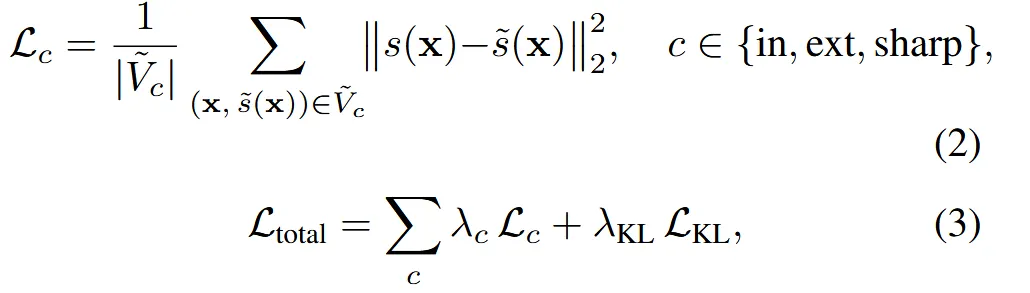
결론적으로 원래 존재하는 부분(in), 추가적으로 모델이 생성한 부분(ext), 뭉개지기 쉬운 모서리 부분을 학습하기 위한 디테일한 부분(sharp) 3가지 부분에 대해서 loss를 계산하고, 마지막으로 KL-divergence 항을 통해서 latent가 너무 복잡해지지 않고 정규 분포를 따르도록 제약한다.
Multi-resolution Training
4가지 해상도에 대해서 랜덤하게 학습을 진행하면서 다양한 해상도의 결과를 얻을 수 있도록 한다.
Spatial Sparse Attention and DiT
ShapeVAE를 통해서 3D를 latent로 압축하고 다시 복원하는 과정을 진행할 수 있고, Rectified Flow를 통해서 이미지에 맞게 latent를 학습하는 과정을 설명하는 단락이다. 이 과정에서 이전부터 계속 말했지만 계산 효율성을 높이기 위해서 spatial sparse attention를 추가한다.
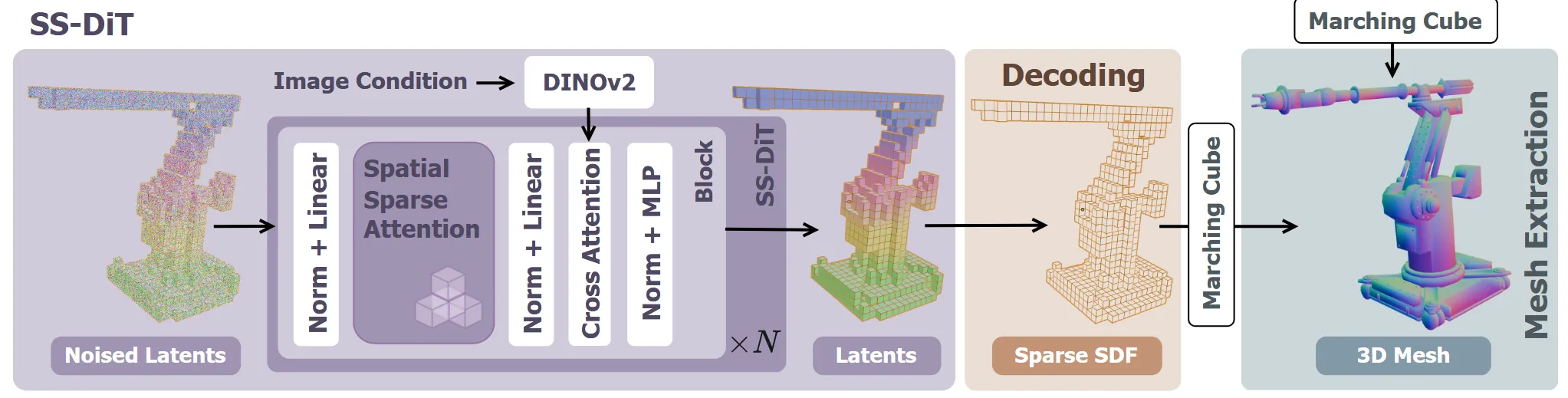
Spatial Sparse Attention
논문에서 계속 핵심적으로 말하는 기술이니 자세히 확인해보도록 하겠다. 입력으로 token length(N) x head dimension(d) 차원을 갖는 q,k,v가 들어오면
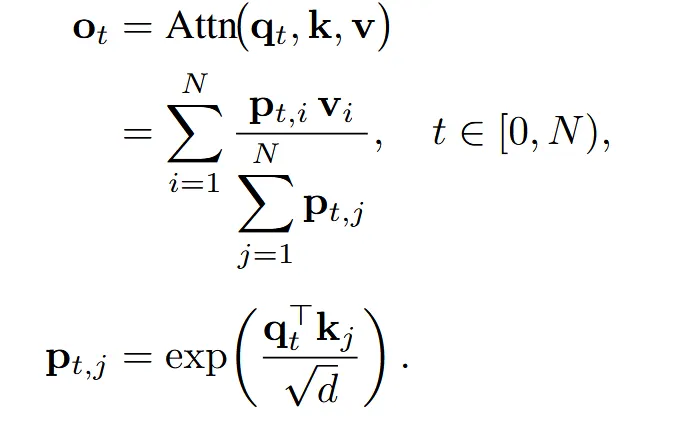
위의 attention 연산을 통해서 진행된다. 기존 방식을 그대로 사용하면 해상도가 높을 때 엄청난 연산량이 필요하다. 따라서 필요한 부분을 묶어서 계산하는 NSA 방식을 이용해서 제안한 SSA를 사용한다. NSA는 단순히 token을 1D로 나타내서 블록을 나누는데 이러면 공간적으로 유사하지 않은 부분들이 묶일 수 있다. 따라서 공간적으로 유사한 부분을 하나의 블록으로 묶도록 SSA는 수정했다.
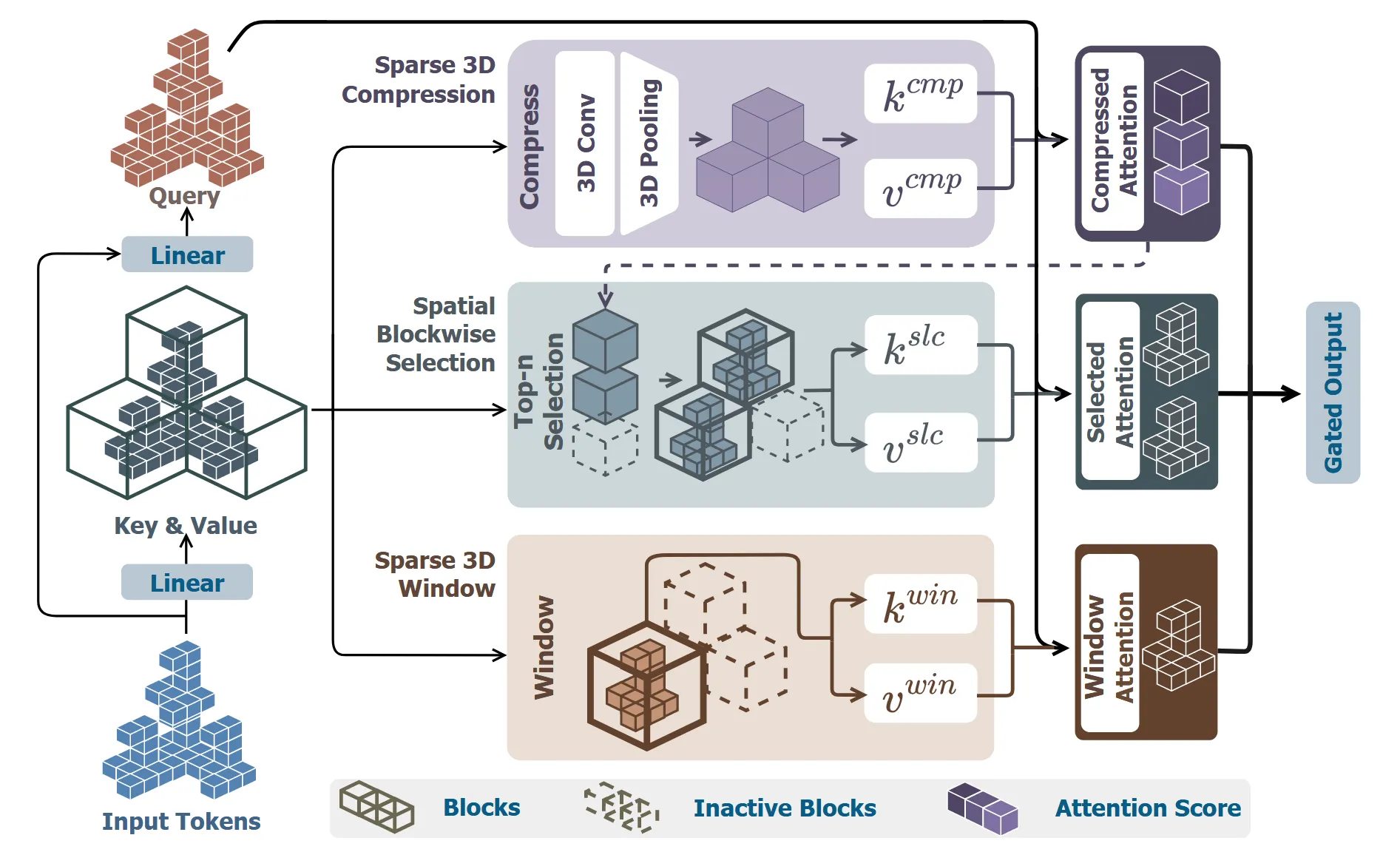
우선 3D 공간을 새로운 의 subgrid로 나눈다.
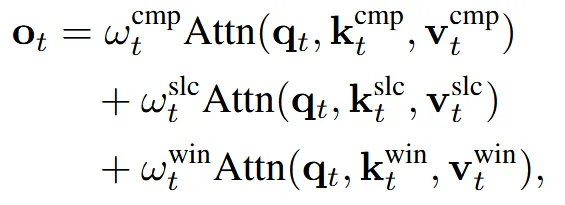
이렇게 나눠진 부분들은 3개의 방법으로 block을 생성하고, 3개의 값을 합친 값을 최종적인 output으로 사용한다. 는 gating score로 상황에 따라서 자동으로 가중치가 계산된다. 이제 아래 부분에서 3가지를 어떻게 나눴는지 자세히 살펴보겠다.
Sparse 3D Compression
Subgrid로 나눠진 하나의 grid 안에는 여러개의 voxel들이 존재하기 때문에 grid를 대표하는 임베딩을 만들기 위해서는 모든 voxel들의 정보가 포함된 임베딩이 필요하다.
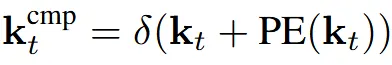
따라서 grid안에 voxel들의 위치 정보를 반영하기 위해서 positional encoding을 각 토큰에 대해서 진행하고, 3D convolution과 3D mean pooling을 진행해서 각 grid의 임베딩을 얻는다.
Spatial Blockwise Selection
위에서 구한 Sparse 3D Compression은 대략적인 정보만을 포함하기 때문에 디테일한 부분의 정보를 얻는 과정이 필요하다. 원본 토큰은 너무 많기 때문에 디테일한 정보를 담으면서도 적은 수의 토큰 정보를 새롭게 선택해야 한다. 이 과정에서 이전에 우리가 계산한 Sparse 3D Compression을 사용한다.
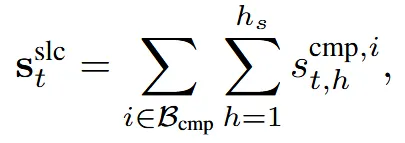
계산 과정은 위와 같다. 우선 각각의 토큰들에 대해서 Sparse 3D Compression의 block과 attention score 를 구한다. 이후에 우리가 subgrid로 나눈 영역의 배수배만큼 더 큰 영역인 영역을 선택하고, 이 영역 안에 있는 모든 값을 모두 더하고 가장 값이 높은 block Top 개를 선택하는 GQA (Grouped-Query Attention) 방식을 이용해서 연산량을 줄였다. 는 선택된 영역 안에 포함된 Compression block들이고 는 하나의 그룹 안에 들어있는 쿼리 헤드의 개수이다. 이렇게 선택된 Top K개안의 토큰들은 concat돼서 와 로 만들어진다.
Spatial blockwise selection attention을 Triton을 이용해서 진행할 때 2가지 문제점이 발생한다. 첫번째로 각 블록에 들어있는 voxel의 수가 다르다는 점, 두번째로 token끼리 HBM(GPU의 메모리)에 인접하게 존재하지 않을 수 있다는 점이다. 논문에서는 이를 해결하기 위해서 block 인덱스를 기반으로 정렬하고 시작 인덱스를 기록하는 Map인 C를 만들었다.

지금까지 설명한 Spatial Blockwise Selection Attention의 Forward pass를 알고리즘으로 나타낸 것이다. 솔직히 어려워서 대략적으로 논문을 보고 싶으면 넘어가도 되고 아니면 아래 설명을 읽으면 도움이 될것이다.
일단 알고리즘을 설명하기 전에 GQA (Grouped-Query Attention) 알고리즘을 대략적으로 설명해보겠다. GQA는 기존 Multi-head attention이 하나의 query당 하나의 Key&Value를 사용한 점을 여러개의 query당 하나의 Key&Value 즉 N:1 관계를 이용함으로써 메모리를 줄이고, 메모리 병목현상을 줄여서 속도를 높이는 방식이다. 여기서 Key Value의 개수가 알고리즘의 Require 부분의 가 되는 것이고, 의 개수가 Key&Value당 계산되는 Query이다. 는 선택한 block의 개수, 는 선택된 어떤 토큰이 어떤 그룹(GQA에서의 그룹)에서 어떤 블록을 선택할지에 대한 인덱스, 는 T를 선택하기 전 크기의 grid 개수, C는 각 블록이 메모리 상의 몇번째 위치에서 시작하는지 알려주는 주소록 역할을 하는 인덱스, 는 한번에 계산하는 토큰의 개수이다.
사실 나는 GQA랑 FlashAttention을 정확히 몰라서 알고리즘이 어렵지만 이후의 과정은 2개중에 하나라도 알고 있으면 편하게 이해될거다. 하지만 나처럼 이에대해서 모르는 독자들을 위해서 일단 내가 이해한 과정을 아래에서 한줄한줄 적도록 하겠다. 일단 설명에 앞서 Flash Attention도 간단히 설명하면 기존에 Attention은 메모리를 썼다 지웠다 하는 과정에서 속도 저하가 나타나는데, Flash Attention은 메모리 이동을 최소화하기 위해서 작게 쪼개서 계산하고 어떤 노트에 계산값만 저장해두는 방법이다. 이제 설명을 진행해보겠다.
1: o(output)과 l(LogSumExp)는 FlashAttention에서 사용하는 변수로 Online Softmax를 하기 위해서 사용된다. o는 계산된 벡터값을 저장하는 공간, l은 Softmax를 계산하기 편하기 위해서 분모를 미리 계산해둔 값들의 모음이다.
2: 이전에 말한 것처럼 모든 토큰들을 블록별로 정렬하는 과정이다. 여기서 q,k,v가 따로 저장되어 있으니까 각 행렬에서 동일하게 블록별로 정렬한다.
3: N개의 토큰에 대해서 모두 진행한다.
4: GAQ에서 정한 key와 value의 개수 만큼 진행한다. 실제로 논문에서는 2로 파라미터 지정했다.
5: 이전에 말한 o(output)과 l(LogSumExp)를 초기화하고, 현재까지 확인한 점수 중 최댓값을 저장하는 m도 동일하게 초기화한다. m은 모든 값을 최댓값만큼 빼고 지수승 했을 때 숫자가 커져서 overflow가 발생하는 현상을 막는다.
6: 현재 query에 해당하는 값과, 참조할 정보가 담긴 인덱스 정보값을 HBM에서 SRAM으로 가져온다.
7: 선택된 블록의 개수만큼 진행한다.
8: C를 기반으로 참조할 토큰들의 정보를 이용해서, 해당 토큰을 가져온다.
9: 전체 토큰들중에서 한 번에 연산하는 양인 개 만큼씩만 잘라서 가져오는 작업을 반복한다.
10: 개만큼의 Key와 Value를 가져온다.
11: 가져온 것들에 대해서 attention score를 계산한다.
12~15: Flash Attention 방법으로 12에서는 가장 높은 값을 m에 적고, 13에서는 점수를 확률로 변환해주고, 14에서는 결과값을 저장, 15에서는 합계를 기록하기 위해 l값에 저장하는 과정을 진행한다.
18: 저장된 결과물을 합계로 나누어 Normalization을 수행하여 최종 값을 완성한다.
19: 완성된 결과물을 HBM의 지정된 위치에 저장한다.
Sparse 3D Window
전체적인 정보랑, 지역적인 정보와 함께 공간적으로 인접한 정보를 활용하는 Sparse 3D Window 방식도 마지막으로 추가했다. 우선 겹치지 않은 영역을 크기의 window로 나눈다. 각 영역 안에 있는 토큰들끼리 Self-attention을 진행해서 공간을 기반으로 한 디테일한 정보를 학습한다.
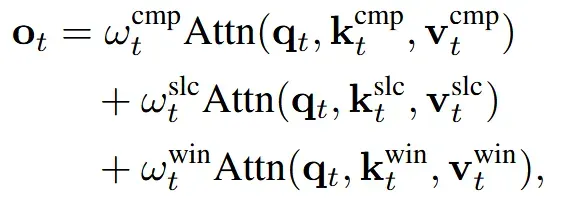
최종적으로 각각의 모듈에 대해서 gate score를 활용해서 출력값을 얻는다.
Sparse Conditioning Mechanism
기존 Image-to-3D 모델들은 DINOv2를 이용해서 이미지 condition을 넣는다. 하지만 대부분의 이미지는 배경이 존재하고, 배경을 제거하는 추가적인 과정을 진행해야 좋은 성능이 나온다. 이러한 추가 과정을 없애기 위해서 sparse conditioning mechanism을 제안했다. 이 방법은 배경을 제외한 부분의 토큰들만 cross-attention에 사용하는 것이다.
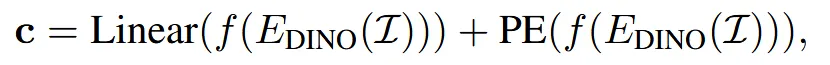
여기서 DINO를 쓰는건 동일하지만 f(.) 즉 foreground만 선택하는 과정을 추가로 진행해서 배경 제거 없이 바로 사용할 수 있도록 설계했다.
Rectified Flow
생성모델은 Rectified Flow를 사용했다.
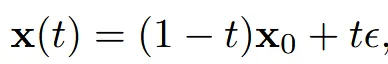
데이터와 노이즈의 분포를 직선 형태로 나타낸 것이고
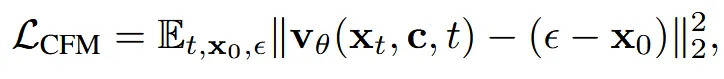
네트워크는 를 학습하면서 진행한다. 자세한 설명은 위에 작성해뒀다.
Experiments
Datasets
Direct3D-S2의 학습 데이터는 Objarverse, Objarverse-XL과 ShapNet을 사용했다. 좋은 mesh만을 학습하기 위해 필터링해서 총 452K 3D 데이터를 활용했다. Non-watertight mesh는 watertight로 변환 후 SDF의 ground-truth를 계산해서 SS-VAE의 학습에 사용됐다. DiT를 학습할 때 한 mesh에 45개의 RGB이미지를 1024x1024이미지 해상도의 랜덤한 뷰로 렌더링해서 사용했다.
Implementation Details
VAE에서 임계치(τ)는 1/128을 이용했다. Latent는 원본에 대해서 1/8배 축소한 해상도와 16차원을 갖는다. Loss에서 사용하는 weight 을 갖는다. 초기에 256, 384, 512의 해상도를 키워가면서 learning rate 1e-4로 학습하다가 1024로 해상도를 올릴 때는 learning rate를 1e -5로 더 낮춰서 배치사이즈 1로 학습을 진행했다. 배치사이즈를 줄인 이유는 언급안했지만 아마 메모리 때문일거라 추측된다.
DiT의 경우 24 layer로 구성된 DiT 블록들을 이용했다. 이전에도 언급했지만 GQA에서 그룹의 개수는 2고 각 그룹에는 16개의 attetnion head들로 구성된다. Compression block은 4로 나머지는 8배 원본에서 압축된 해상도로 블록들을 구성했다. 여기서는 256에서 1024로 해상도를 높여가면서 학습을 진행했다.
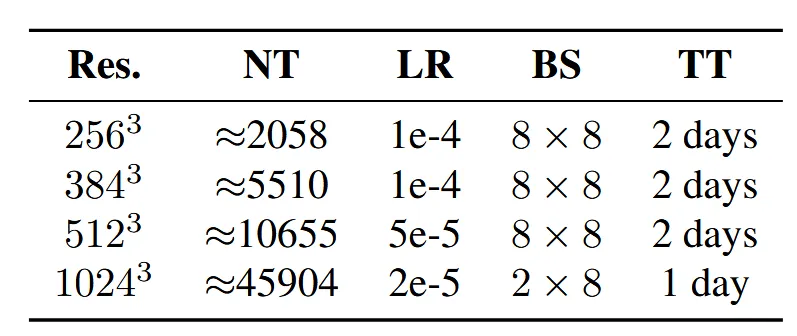
해상도에 따른 NT(토큰의 개수), LR(learning rate), BS(배치 사이즈), TT(총 학습 시간)을 요약해 놓은 표가 위와 같다.
Quantitative and Qualitative Comparisons
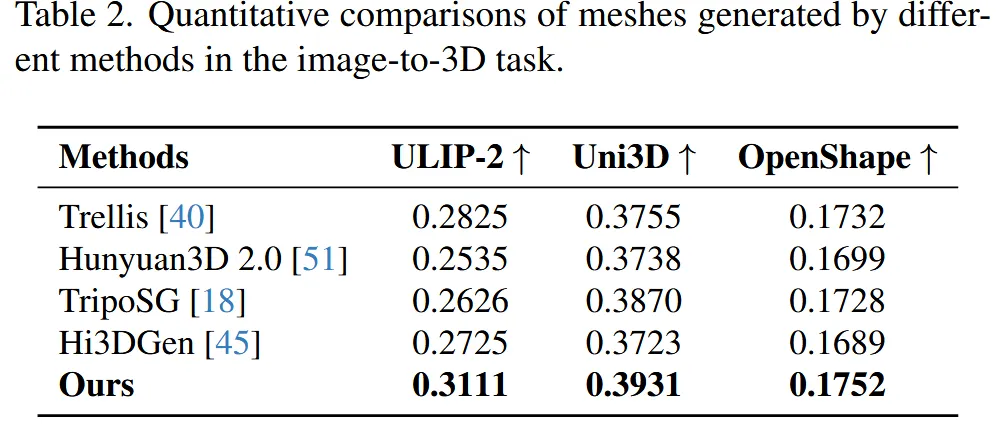
이미지와 3D가 얼마나 일치하는지 ULIP, Uni3D, OpenShape의 비교를 통해서 나타냈다.

전체적인 형상들은 모든 모델들이 잘 생성하지만, 디테일한 부분은 해상도 이유로 인해서 Direct3D-S2가 가장 잘 생성했다.
Comparison of VAE
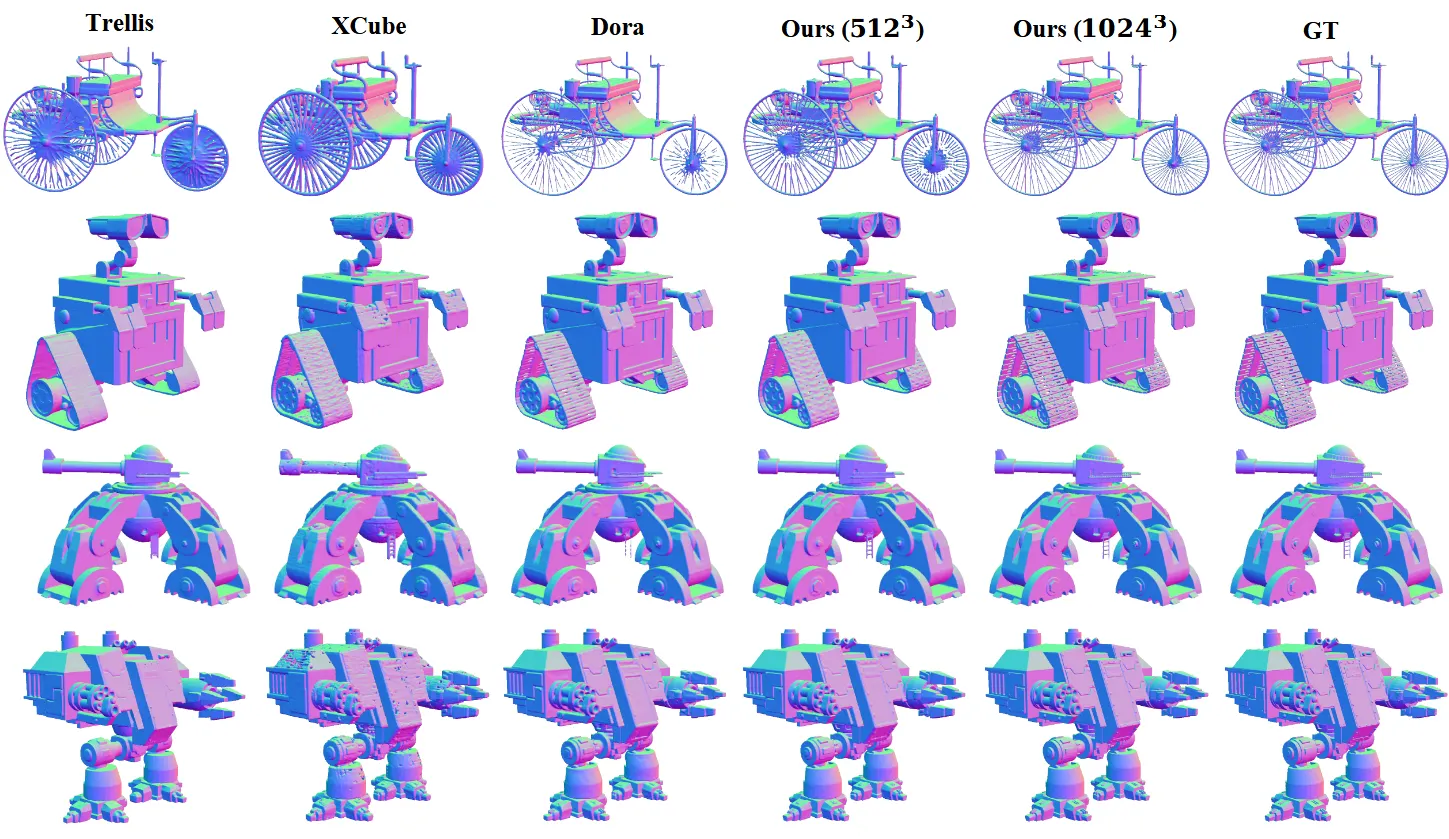
Objarverse의 데이터에 대해서 VAE의 성능을 비교햇다. 높은 해상도로 학습한 덕분에 디테일한 부분들이 더 잘 보존된다.
Ablation Studies
Image-to-3D Generation in Different Resolution

Image-to-3D 모델을 해상도를 256, 384, 512, 1024에 대해서 mesh를 생성하도록 비교했는데 당연히 해상도를 높일 때 성능이 좋아졌다.
Effect of Each Module in SSA

SSA과정에서 3가지 loss를 사용했는데 여러가지 조합을 통해서 1개 혹은 2개만 사용했을 때의 결과도 보여준다. 근데 솔직히 말하면 모르겠다… 차이가 없어보인다..
Runtime of Different Attention Mechanisms
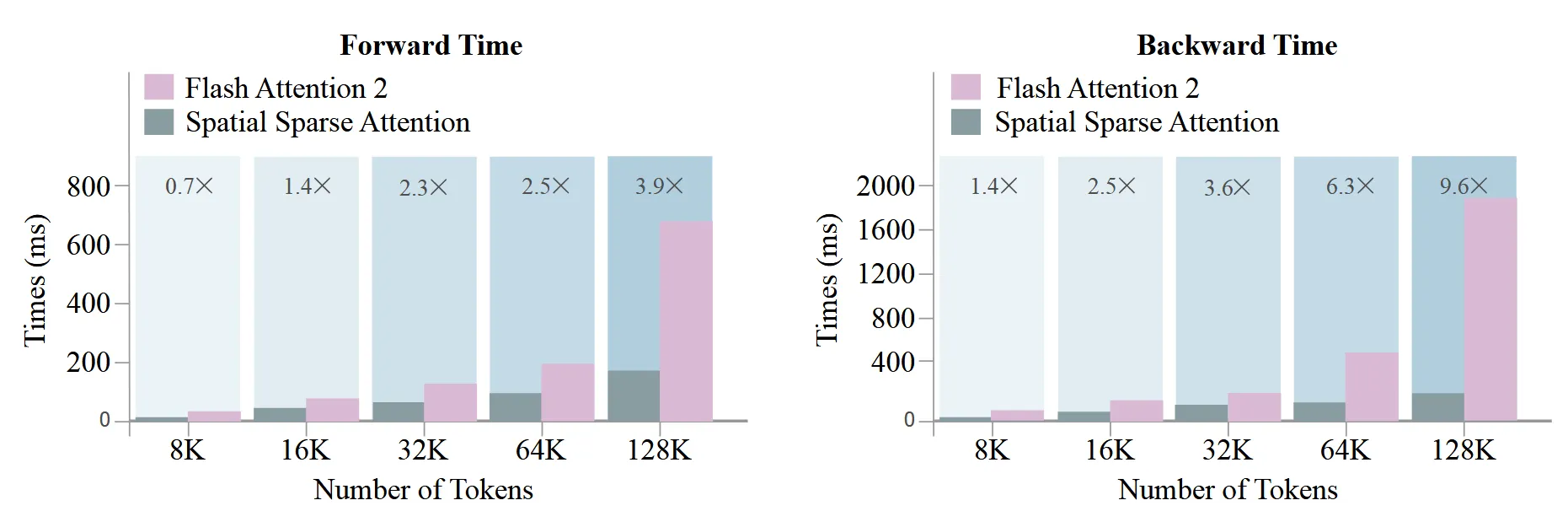
가장 중요한건 연산량이다. Flash Attention2를 사용했을 때보다도 연산량이 훨씬 줄어든 것을 위의 그림을 통해서 확인할 수 있다. 연산량이 줄어든만큼 속도도 빨라졌다.
Effectiveness of SSA

Attention 연산을 줄이는 방법은 기존에 2개가 나왔었다. Full Attention은 Trellis에서 패치단위로 묶어서 연산을 하는 방법이고, NSA는 단순히 1D sequence로 취급해서 하는 방식이다. 결론적으로 나는
Effect of Sparse Conditioning Mechanism

배경이 있는 이미지에 대해서 Sparse Conditioning Mechanism이 잘 작동하는 결과를 나타냅니다. 해당 부분은 확실히 잘 작동하지만.. 배경은 사용자가 제거해도 된다고 개인적으로 생각하긴 합니다.
Conclusion
결론적으로 높은 해상도의 3D mesh를 빠른 속도로 생성할 수 있지만 압도적인 성능까지는 아니고 디테일한 부분에서 성능이 더 좋아진다. 그리고 한계점으로 forward pass는 flash attention2에서 속도만큼 빨라지지는 않았다고 언급했다.
