Scaling Rectified Flow Transformers for High-Resolution Image Synthesis[StableDiffusion3 2024 arXiv]

Stable Diffusion 3의 논문으로 알려진 논문으로 기존 Diffusion 모델에 Rectified Flow와 DiT 방식을 적용해서 성능을 향상시켰습니다. 결론적으로 성능이 향상됐다고 했는데 어떻게 성능 향상을 가능하게 했는지 확인하도록 하겠습니다.
Introduction
Diffusion model은 노이즈로부터 데이터를 생성하며, 학습된 분포 내에서 새로운 이미지를 만들어낼 수 있다. 하지만 생성 시간이 오래 걸려 효율성 문제가 제기되었고, 데이터 생성 경로(Path)에 대한 고민도 이어졌다. 곡선 경로보다 직선 경로가 시간과 에러 누적 면에서 유리하며, 그 대표적인 방법이 Rectified Flow이다. 본 논문은 이를 적용해 고품질 이미지를 빠르게 생성하고자 했다.
기존 Text-to-image의 Cross-attention 방식은 단방향성이라 한계가 있어, 논문에서는 이미지와 텍스트 토큰이 양방향으로 정보를 교환할 수 있는 MM-DiT를 제안했다.
본 논문의 주요 기여점은 다음과 같다:
- Rectified Flow를 적용하되, 인지적으로 중요한 중간 단계에 가중치를 두는 새로운 노이즈 sampler를 도입해 성능을 개선했다.
- 텍스트와 이미지의 양방향 정보 흐름을 가능케 하는 아키텍처를 설계했다.
- Validation Loss의 감소가 실제 성능 및 인간 선호도 향상과 직결됨을 보이며 예측 가능한 Scaling 법칙을 입증했고, 이를 통해 SOTA 모델을 능가하는 성능을 달성했다.
Simulation-Free Training of Flows
생성 모델은 노이즈 샘플 의 분포인 을 데이터 샘플 의 분포인 로 ordinary differential equation(ODE)를 통해서 보낸다.
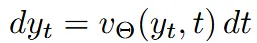
위의 수식에서 velocity 는 가중치 Θ로 부터 파라미터화 된다. 기존에 differential ODE solvers를 이용해서 velocity를 푸는 방법이 제시됐지만 이는 많은 연산량을 필요로 한다. 최근에는 연산량을 줄이기 위해서 노이즈 분포에서 데이터 분포로 이동시키는 vector field 를 학습시키는 방법이 나왔다.
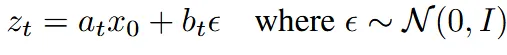
Forward 수식은 위에처럼 나타내는데 여기서 시간 t에서의 이미지 상태인 는 원본 이미지 과 가우시안 노이즈 를 혼합해서 나타낸다. 일 때는 원본 데이터, 일 때는 가우시안 노이즈다.
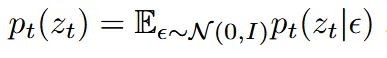
위의 수식을 통해서 이전에 설명한 원본 데이터와 노이즈를 섞는 과정이 타당하다는 것을 나타낸다. 조금더 자세히 설명하자면 는 특정 노이즈가 정해졌을 때 시간 t에서 데이터 가 이전 수식에 따라 정해진다는 것이고, 는 가능한 모든 노이즈에 대해서 다 더한다는 뜻이기 때문에, 결론적으로 는 모든 노이즈를 고려했을 때 시간 t에서의 데이터의 분포다. 결론적으로 특정 노이즈가 정해졌을 때 우리는 시간 t에서의 데이터의 분포를 알 수 있다는 것이다.
이제부터 Flow Matching의 본격적인 설명이 진행된다. 논문에서는 간략하게 나왔기 때문에 정확한 이해를 위해서 Flow Matching 논문을 읽어보는 것을 추천한다.
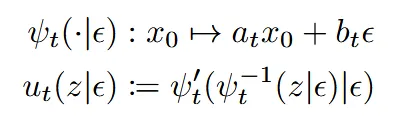
시간 t에서의 위치 와, 속도 를 수식으로 나타낸 것이다. 속도는 위치에 대해서 미분한 값이기 때문에 아래 식처럼 표현할 수 있다.
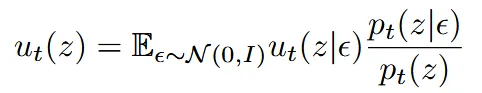
개별 데이터가 아닌 데이터 전체 집단의 움직임(Marginal Vector Field)를 나타내는 수식이 위와 같다. 특정 노이즈에 따라 결정되는 가 아닌 평균적인 는 결국 모든 노이즈에 대해서 가중 평균 낸 것과 같다는 것이다. 하지만 위처럼 계산하는 것은 현실적으로 계산량이 너무 많아서 불가능하다.
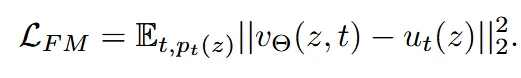
따라서 모델 이 전체 흐름 과 유사하게 학습하는 위의 수식이 최종적인 Flow Matching 함수이다. 하지만 이전에 말한것처럼 우리는 전체 흐름을 계산하는게 현실적으로 불가능하다.
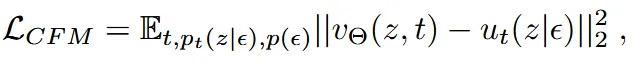
따라서 위의 수식처럼 개별 경로 에 모델을 학습시키는 Conditional Flow Matching 방식을 제안했고, 이는 계산도 쉽고 수식적으로도 Flow Matching과 동일함을 보였다.
이제 아래부분은 Flow Matching의 훈련 방법의 유도 과정을 나타낸다. 생각보다 어려우니 잘 따라와야 한다.
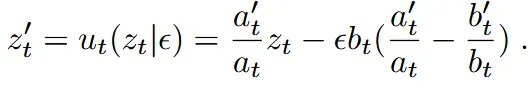
우리는 t시점에서 데이터의 위치를 로 정의했는데 실제로 우리는 원본 이미지 를 모르는 상태에서 속도를 정의해야 한다. 따라서 를 소거하는 방식으로 유도하면 위와 같은 수식이된다. 위의 수식은 단순히 대입하면 나오는 형태이기 때문에 이해가 안되면 대입했을 때 나온 결과구나 생각하면 된다.
식을 깔끔하게 정리하기 위해서 SNR(Singla-to-Noise Ratio) 개념인 를 도입하면
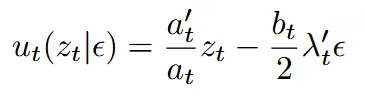
이렇게 깔끔하게 나타난다.
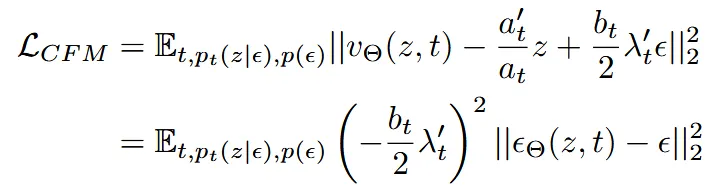
기존에 우리는 velocity를 예측하도록 설계를 했지만, 대부분 Diffusion 모델들이 노이즈를 예측하는 방식으로 나타냈기 때문에 기존에 사용하는 cfg를 쓰거나 다른 기술을 적용하기 용이하기 위해서 velocity대신에 노이즈를 예측하도록 위와같이 수식을 변경했다. 위의 수식에 가중치를 곱해준다고 해도 최적의 파라미터는 바뀌지 않을 것이다. 하지만 모델이 어디를 먼저 더 잘 배울지를 결정하는 학습 과정은 달라질 수 있습니다.
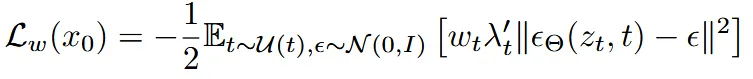
논문에서는 위와 같이 새로운 Time schdeuler를 소개하기 위해 diffusion 모델에 대해서 하나의 표준화된 loss 템플렛을 제시했다.
Flow Trajectories
Rectified Flow
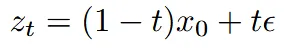
Rectified Flows는 forward 과정을 위의 수식처럼 데이터의 분포와 가우시안 노이즈를 연결하는 직선 경로로 정의했다.
EDM
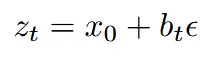
EDM은 데이터의 분포 앞에 붙는 계수 없이, 노이즈의 강도만 점점 더하는 방법이다. 노이즈의 강도는 로 나타내며 log-normal distribution를 따르도록 설계했다.
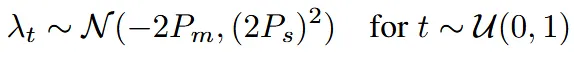
결과적으로 위와 같은 분포를 갖게 되며 이는 중간 정도의 노이즈 레벨에서 집중적으로 많이 학습하게 된다.
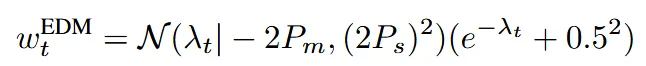
이전 문단의 마지막 부분에 표준화된 loss 템플렛에 EDM을 적용할 때는 위의 가중치를 사용하면 된다. 원래 EDM 모델이 F-prediction으로 모델 출력을 통해 학습을 하는데 이를 노이즈 예측으로 변환한 결과 위의 가중치가 나오게 되는 것이다.
Cosine
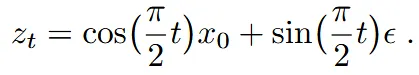
위의 스케줄러는 노이즈를 예측하냐 velocity를 예측하냐에 따라서 다른 가중치가 나온다. 당연히 이전에 우리가 변환하는 과정을 통해서 가중치를 다시 표현한 이유가 어떤걸 예측하느냐에 따라서 가중치가 바뀌기 때문이다. 결론적으로 노이즈를 예측할 때의 가중치는 , velocity를 예측할 때의 가중치는 로 나타낸다.
(LDM-)Linear
LDM은 DDPM 스케줄러를 변형해서 사용한다. 2가지 방식 모두 variance preserving(VP) 스케줄러를 선택해서 의 분포를 따라간다. 차이점은 2가지 방식이 를 증가시키는 방식이 다르다는 점이다. DDPM은 로 값이 시간에 따라 직선으로 증가하고, LDM은 로 시간에 따라 값이 2차 함수 형태로 증가하게 변형 한 것이다.
Tailored SNR Samplers for RF models
Rectified Flow에서 시간 간결을 균일하게 나눠서 학습을 하지만, 이 논문에서는 양 끝 시간에서는 노이즈가 완전히 많거나 적은 극단적인 상황이기 때문에 노이즈를 예측하기 쉬운데, 중간에서는 이미지와 노이즈가 섞여 있기 때문에 이미지 구조를 생성하기 때문에 균일하게 나누지 말자라고 의견을 제시했다.
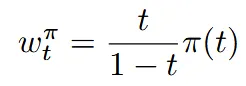
위의 수식에서 확률분포 를 바꿈으로써 중요한 시간대를 더 자주 학습시키는 방법을 제시한 것이다. 아래에서 어떤 방식들을 제시했는지 확인해보겠다.
Logit-Normal Sampling
중간 step에 더 많은 가중치를 가하는 첫번째 방식은 logit-normal distribution 방식이다.
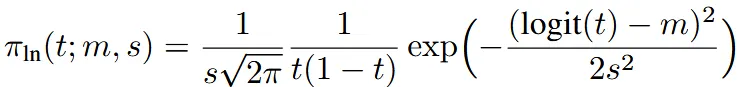
해당 방식의 아이디어는 간단하다, 우리가 다루기 쉬운 정규분포의 범위를 시간 범위인 0부터 1로 나타내기 위해 Sigmoid 함수를 통과시키고 m이랑 s 2가지 파라미터를 이용해서 분포를 바꾸자는 것이다.
첫번째 파라미터인 m은 정규 분포의 평균에 해당 하는 값으로, 값이 작을수록 원본 데이터에 더 많이 쏠려서 초반 단계를 더 많이 학습한다. 두번째 파라미터인 s는 랜덤한 숫자를 뽑을 때 사용하는 표준편차 값으로, 이 랜덤한 숫자는 시그모이드 함수에 사용된다. 위의 수식은 이를 통해 나타낸 timestep t에서의 확률분포이다.
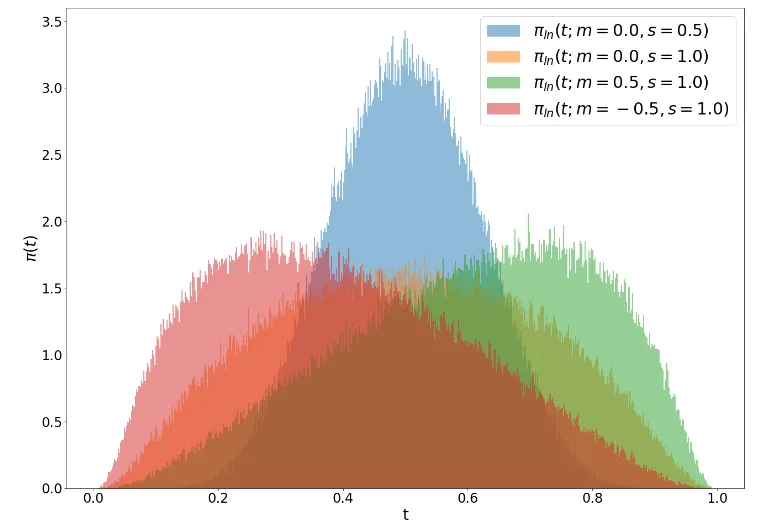
m과 s의 값에 따른 정규분포의 변화는 위의 그림을 통해서 확인할 수 있다.
Mode Sampling with Heavy Tails
위의 방식은 양쪽 끝에서 값이 무시되는 경향이 있고, 이를 보완하기 위해서 Mode Sampling with Heavy Tails 방식을 제안했다.
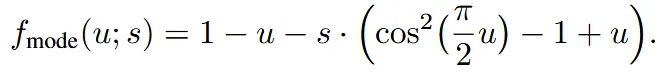
이전처럼 정규분포에서 뽑은 값 를 우리가 원하는 시간 t로 변환해주는 함수가 위와 같다. 여기서 파라미터 s가 0이면 뒤에 부분이 다 사라지고 Rectified Flow에서 사용하는 균등 분포와 동일해진다. 따라서 s의 범위를 로 제안했다. s의 값이 커지면 중간을 더 오래보고, 작아지면 양쪽 끝을 더 오래본다.
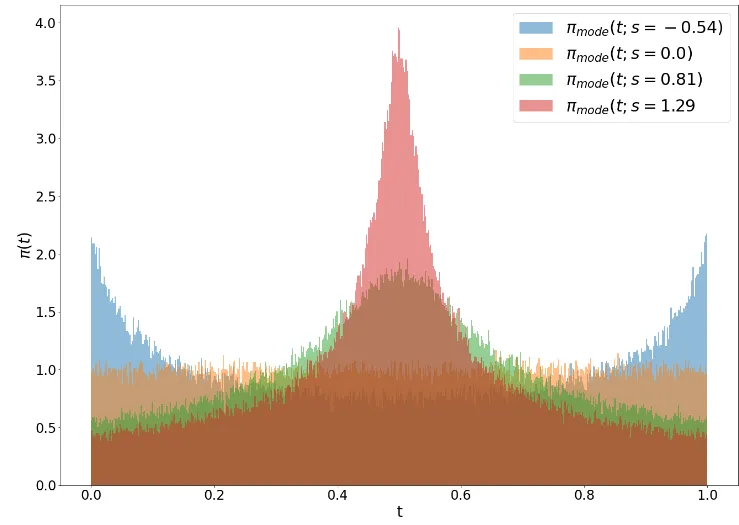
s의 값에 따라 정규분포가 어떻게 변하는지를 시각화하면 위와 같다.
CosMap
이전에 설명한 cosine 스케줄러를 Rectified Flow에서 적용하는 방식이다. Cosine 스케줄러는 곡선 형태이기때문에 이를 직선 형태로 변환하면서 cosine 스케줄러의 장점인 중간 부분을 잘 학습하자는 아이디어다. Cosine스케줄러는 로 표현되고, Rectified Flow는 로 표현되기 때문에 u와 t사이를 변환해주는 함수 를 사용한다.
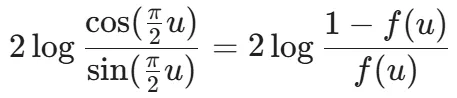
위의 수식처럼 SNR이 동일하다고 나타낼 경우 수식 하나가 나오고, 이를 에 대해서 풀면
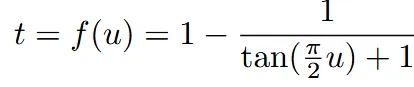
위와 같이 나온다. 결론적으로 우리가 원하는건 t시점에서의 분포이기 때문에 위의 수식에 대해서 역함수를 미분해서
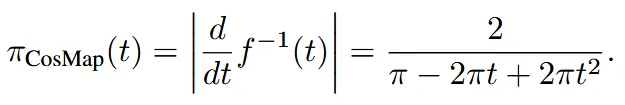
분포를 얻는다.
Text-to-Image Architecture
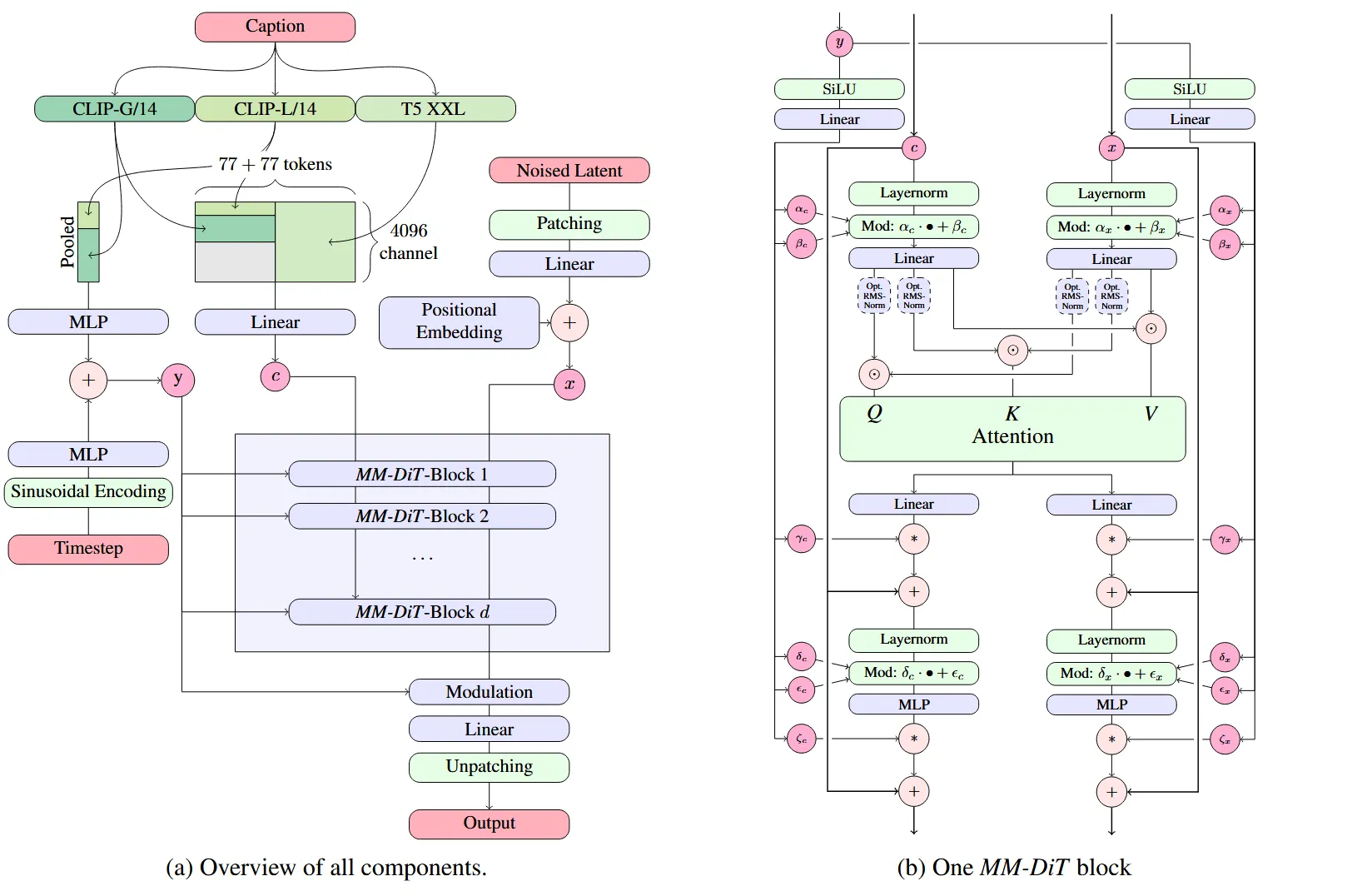
모델의 아키텍처는 위와 같다. 전체적인 흐름은 LDM과 유사하다. 이전에 개념들이나 스케줄러는 자세하게 설명했는데 논문에 아키텍처에 대한 설명은 간략하다. Appendix에 자세히 나와있지만 일단 간략하게 필요한 내용들을 아래에 설명해보겠다.
일단 전체적인 아키텍처인 왼쪽 그림을 보면 Text-to-Image 모델이니까 처음에 Caption(Text)가 들어간다. 이를 3개의 Text Encoder 모델(CLIP-L, OpenCLIP-bigG, T5-XXL)을 사용해서 임베딩을 얻는다. 여기서 왼쪽에 생성되는 임베딩은 timestep의 임베딩과 더해지는 값으로 CLIP과 OpenCLIP의 CLS token을 concat해서 얻은 값이고, 가운데에 있는 값은 두 모델에서 나온 모든 시퀀스 토큰들과 T5모델의 sequence 토큰까지 더해서 이후에 MM-DiT의 텍스트 임베딩으로 사용한다. 정리하면 3개의 Text Encoder 모델을 통해서 Text condition과 MM-DiT의 텍스트에 사용할 임베딩을 생성한다.
이미지는 LDM과 유사한 방식인데 기존 4차원에서 16차원으로 이미지를 더 압축한 latent space로 보낸다. 이를 통해서 얻은 임베딩은 텍스트 임베딩과 분리되며 처음에 말한것처럼 이미지와 텍스트는 따로따로 학습하다가 중간에 정보 교환을 하게 된다.
조금 복잡하니 한번 정리하고 들어가면 Text와 timestep을 이용해서 condition(y)를 생성하고, 많은 텍스트 임베딩을 하나로 합친 텍스트 임베딩(c) 그리고 16차원으로 더 압축된 공간의 이미지 임베딩(x)가 MM-DiT Block에 들어간다.
MM-DiT Block
MM-DiT Block은 오른쪽 그림처럼 텍스트와 이미지에 대해서 서로다른 가중치를 이용해서 학습하도록 DiT 모델을 사용하고, 여기서 가운데 부분에서 Attention을 통해서 정보 교환이 이루어지도록 했다.
Experiments
Improving Rectified Flows
지금까지 다양한 스케줄러, 방법들을 제시했는데 이에 대해서 어떤 값이 제일 적절한지 확인해보는 과정이다. 동일한 환경에서 ImageNet, CC12M 데이터셋을 이용해서 학습을 하고, COCO-2014 Validation 데이터를 이용해서 평가했다. 평가지표는 Valdiation Loss, CLIP Score, FID를 이용했다.
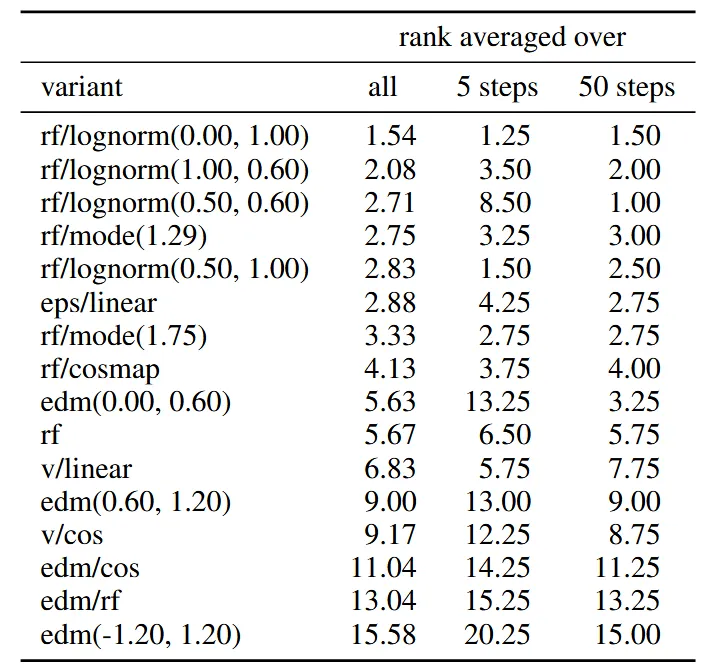
위의 표는 다양한 실험의 결과인데 rf는 Rectified Flow의 균일 샘플링 방식, lognorm은 Logit-Normal Sampling 방식, cosmap은 CosMap 방식이다. edm은 기존 모델중 하나, mode는 mode sampling 방식이다. eps는 노이즈 예측 v는 velocity 예측이다. 조금 나열식이다 그냥 여러 방식을 비교한 것이다.
기존 방식인 rf를 그대로 적용하는 방식보다 새로운 스케줄러 특히 Logit-Normal sampling 방식을 썼을 때 가장 좋은 성능을 나타낸다.
위의 Rank는 61개의 모델에 대해서 서로 다른 데이터와, EMA 적용 유무와 step과 같은 파라미터 변경을 24번 진행해서 얻은 평균 등수를 나타낸 값이다.
Improving Modality Specific Representations
IMPROVED AUTOENCODERS
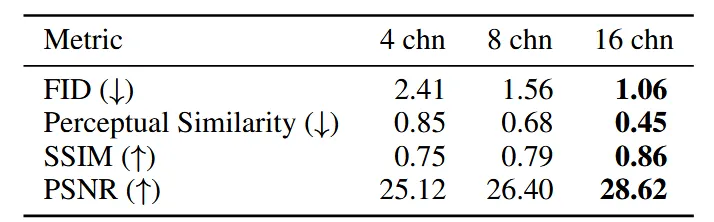
압축하는 latent차원을 기존 4에서 16으로 늘렸다고 했는데, 그 이유로 압축하는 차원 수를 늘릴 때 실험적으로 결과가 좋아졌기 때문이라고 밝혔다.
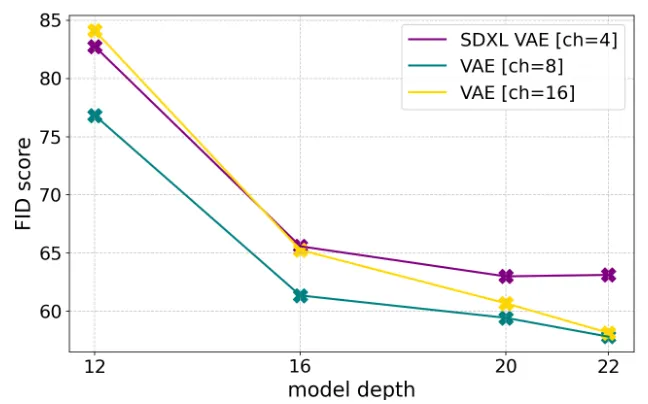
모델의 차원이 커질수록 더 많은 정보량을 요구하기 때문에 차원이 클수록 depth가 작을 때는 성능이 안 좋지만, depth가 커질수록 성능이 좋아지는 것을 확인할 수 있다.
IMPROVED CAPTIONS
학습하는 데이터셋의 Caption은 100% 사람이 작성했는데 이는 메인 피사체만 묘사하고 배경이나 구도 등은 생략되어 있다. 따라서 전체 데이터셋의 50%는 Caption 생성 모델인 CogVLM을 이용해서 생성하도록 변경했다.
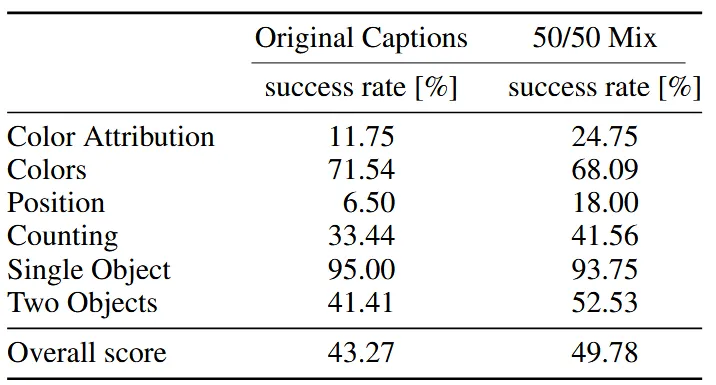
GenEval 벤치마크를 사용했을 때 결과를 보면 전체적인 성능이 5:5로 Caption을 생성한 경우 증가한 것을 확인할 수 있다. 재밌는 점은 Colors, Sinle Object 부분은 오히려 감소했고 나머지 부분들은 향상됐다는 점이다.
IMPROVED TEXT-TO-IMAGE BACKBONES
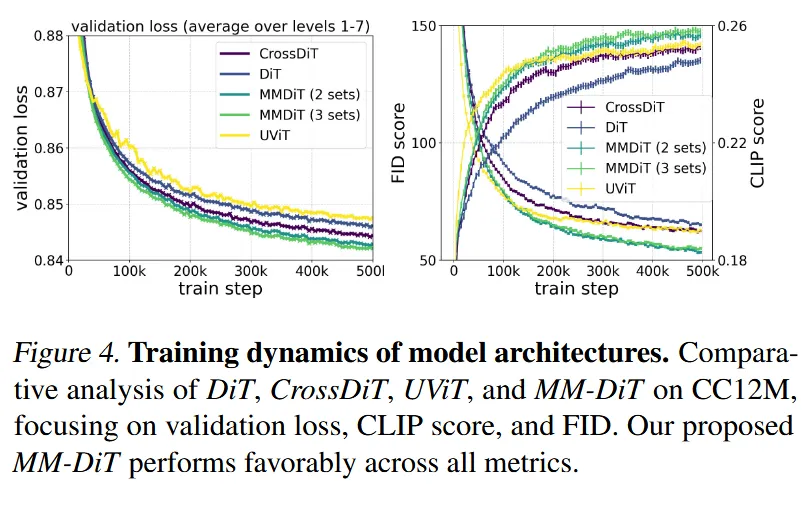
Backbone 모델을 어떤걸 쓰느냐에 따라서 결과가 달라진다는 것을 보여주는 단락이다. CrossDiT는 DiT모델에 Cross-Attention을 추가한 버전, DiT는 그냥 기본적인 Diffusion Transformer, UViT는 UNet과 Transformer를 섞은 기존 버전, 마지막으로 MMDiT는 이 논문에서 제시한 방법으로 이미지와 텍스트를 따로 학습하는 2sets와 여기서 이미지 CLIP토큰 T5토큰 3개를 학습시키는 3sests 아이디어도 제시했다. 결론적으로 MMDiT의 3sets가 성능이 가장 좋긴하지만 2sets와 성능 차이가 미미하고, 계산량을 고려해서 2sets를 최종 모델로 선택했다고 밝혔다.
Training at Scale
데이터처리나 Fine-tuning 과정등은 생략하도록 하겠다.
RESULTS
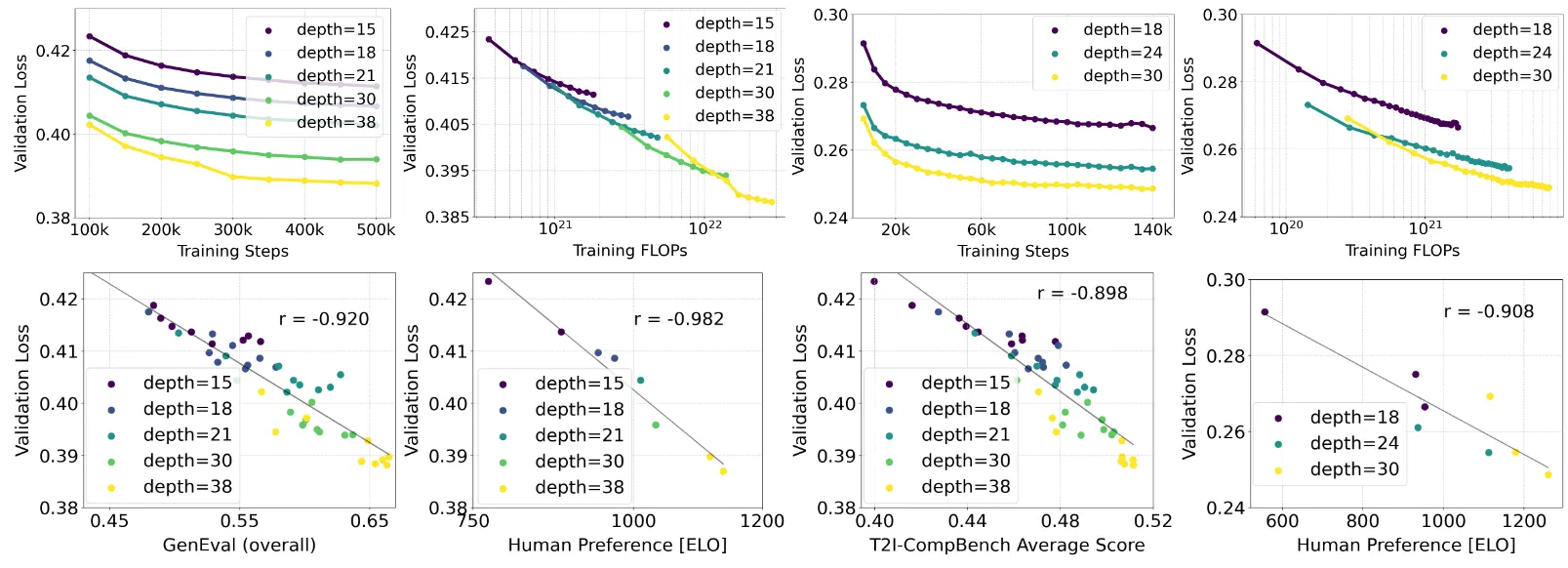
MM-DiT의 크기에 따라 미치는 요소들을 확인하는 그림이다. 윗줄을 통해서 스케일이 커질수록 즉 depth가 깊어질수록 더 많은 계산량(FLOPs)이 증가하고 Validation loss는 감소하는 것을 볼 수 있다. 또한 아래줄 그림을 통해서 GenEval과 CompBench 2개의 비디오 벤치마크와 Human Preference에서 모두 스케일이 커질수록 더 좋은 결과를 나타낸다. 참고로 비디오의 경우 이미지 모델의 가중치를 사용해서, 시간 축을 추가하고, 각 프레임내의 정보를 이해하기 위한 Spatial Attention과 모든 시간의 프레임끼리의 정보 교환을 위한 Spatiotemporal Attention을 추가했다.
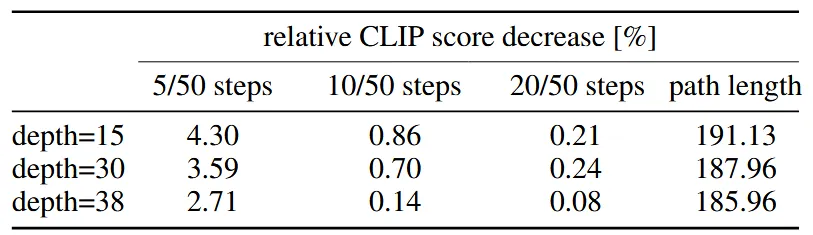
흥미로운점은 크기가 큰 모델일수록 적은수의 step만으로도 좋은 성능을 낼 수 있다는 것이다.

복잡한 prompt가 들어갈수록 T5의 유무에 따라서 성능이 크게 바뀌는 것을 실험을 통해서 증명했다.
Visual Results

Conclusion
StableDiffusion3 모델은 중간단계를 더 집중적으로 학습하는 새로운 timestep sampling 방식을 제안했고, 3가지 Text Encoder를 활용해서 Text와 Image 토큰을 서로다른 가중치를 이용해서 학습하는 방식을 제안함으로써 스케일의 확장을 통한 성능 증가를 입증했다.
