MagicCartoon: 3D Pose and Shape Estimation for Bipedal Cartoon Characters[2024 ACM]
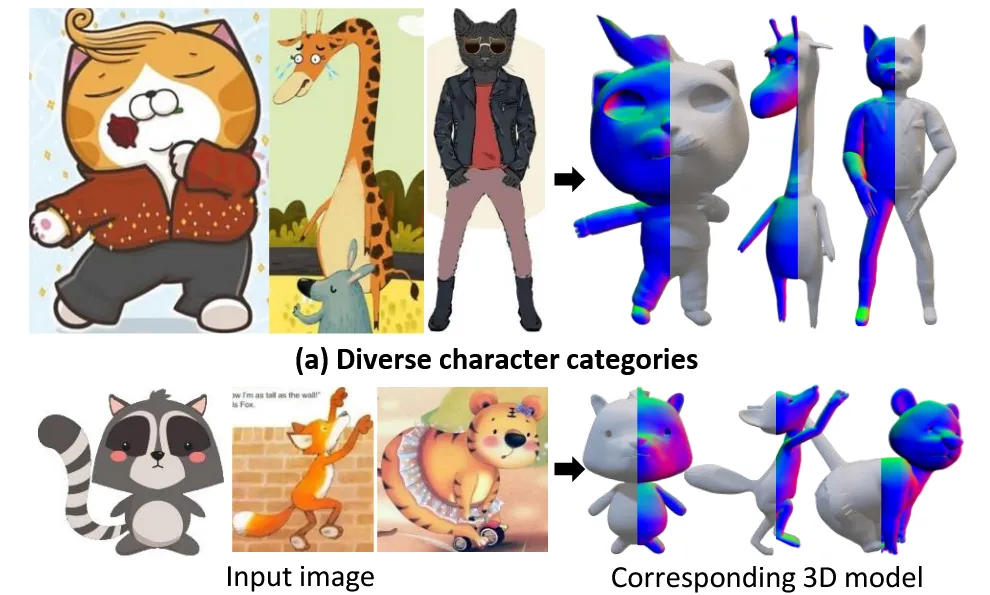
Cartoon single imgae로부터 3D 자세와 포즈를 예측하는 논문입니다. 이전에 소개한 Rabit에서 제공한 3DBiCar 데이터를 사용했지만 더 높은 성능을 나타냈다고 했는데 어떤 아키텍처를 기반으로 결과를 도출했는지 알아보도록 하겠습니다.
MagicCartoon
Framework
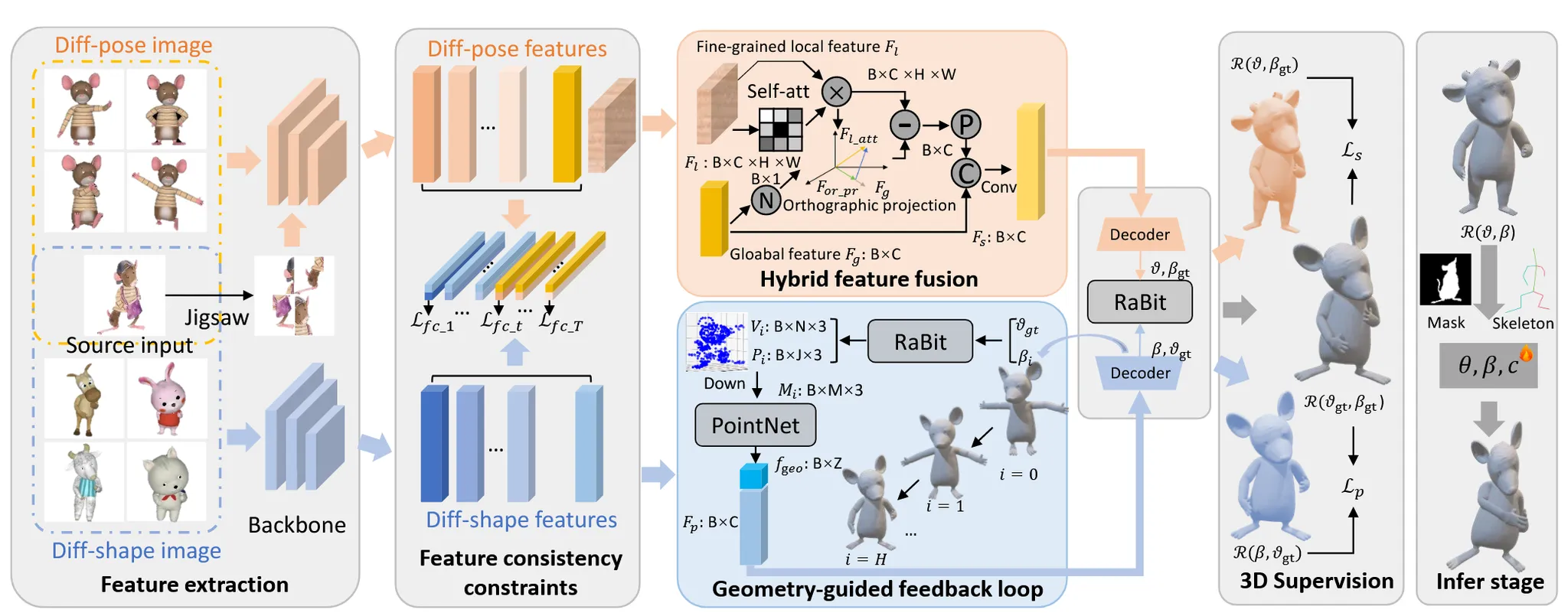
RaBit 논문과 유사하게, MagicCartoon 역시 한 장의 이미지로부터 dual-branch 구조를 활용해 3D pose 파라미터 β와 shape 파라미터 θ를 각각 예측합니다. 이 두 파라미터는 RaBit 모델에 입력되어 최종적으로 3D 메시 결과를 얻게 되며, 이는 본문의 그림을 통해 시각적으로 확인할 수 있습니다.
MagicCartoon에서는 단순히 인코더만을 사용하는 기존 방식과 달리, 보다 정교한 요소들이 추가되어 있는데, 이 부분은 아래에서 자세히 설명드리겠습니다.
Training에서는 렌더링된 이미지를 이용하여 파라미터를 약간씩 변형하며 모델을 학습시키고, Inference에서는 입력 이미지의 mask와 skeleton 정보를 활용하여 메시 파라미터를 정교하게 맞추는 방식을 사용합니다.
Feature Decoupling Module
하나의 네트워크에서 shape()와 pose()를 동시에 학습할 경우 서로 방해를 받을 수 있습니다.
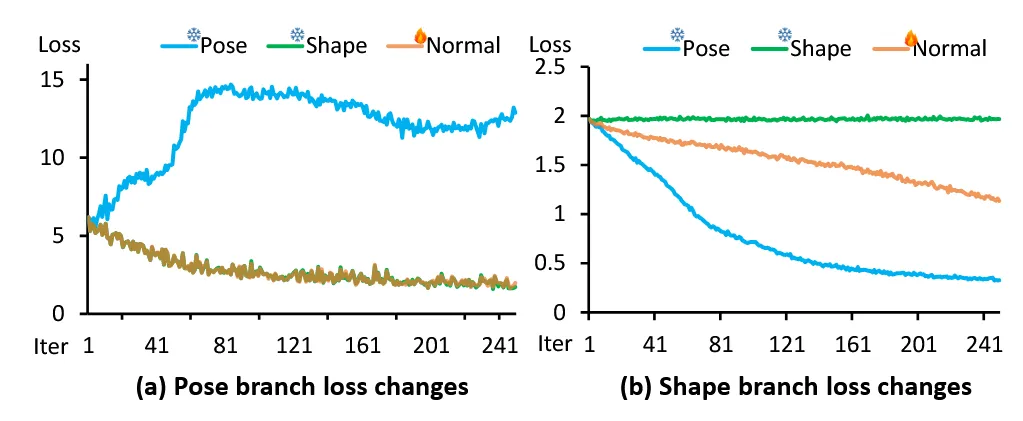
왼쪽은 pose branch를 freeze했을 때 loss 변화입니다. 나머지 2개의 loss는 약간 줄지만 큰 변화가 없는 상태이고, pose loss는 점점 커지다가 약간 내려가는 형태를 나타냅니다.
오른쪽은 shape branch를 freeze했을 때 loss 변화입니다. shape은 학습이 안돼서 그대로고, 나머지 2개의 loss는 조금씩 감소하는 것을 확인할 수 있습니다.
2개의 그래프를 통해서 freeze된 branch의 loss는 그대로거나 오히려 악화되어서 서로의 학습에 방해가 되는지를 실험적으로 확인할 수 있습니다.
따라서 2개의 branch를 분리시켜서 동작시키는 것이 각각의 파라미터를 정확하게 예측하는데 도움이 됩니다.
위와 같이 2개의 branch를 분리시키는 것이 예측에 도움이 된다는 것을 알고 이를 학습에 적용하기 위해서 feature consistency constraint를 적용했습니다.
Character image generator
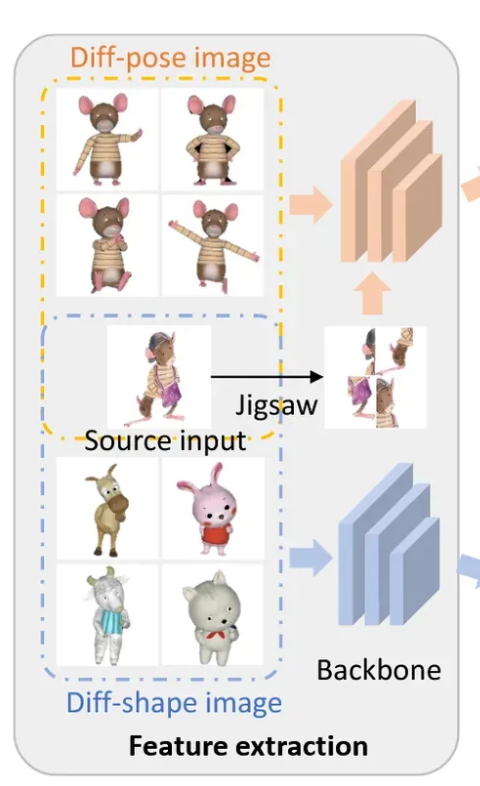
Shape을 학습 시키기 위해서 Shape은 다르지만 pose가 동일한 이미지들을 넣고, 반대로 Pose를 학습 시키기 위해서 Pose는 다르지만 Shape은 동일한 이미지들을 넣었습니다.
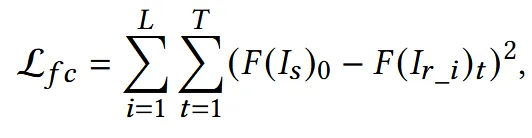
Feature consistency loss는 위와 같이 동작합니다. L이 reference image의 개수이고, F는 다양한 network stage에서의 feature를 나타냅니다.
Hybrid Feature Fusion

Cartoon image들은 사람 image보다 조금 더 다양한 카테고리와 형태를 갖고 있기 때문에 코와 귀 같은 디테일한 부분의 학습도 필요합니다. Local feature를 학습하기 위해서 Jigsaw puzzle을 사용합니다. ‘Fine-Grained Visual Classification via Progressive Multi-granularity Training of Jigsaw Patches.’ 논문에서 Jigsaw puzzle 이미지를 활용하면 local feature를 학습할 수 있음을 증명했습니다.
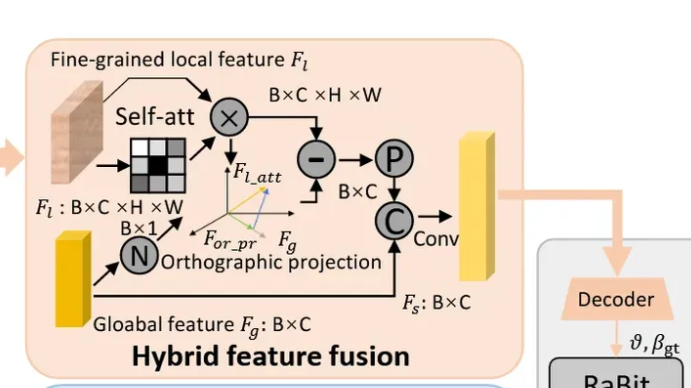
Jigsaw puzzle generator
이미지를 nxn bock들로 나눈 후, 이를 랜덤한 순서로 퍼즐처럼 재배치 합니다. 이후 재배치한 이미지를 backbone network에 통과시켜 local features 를 얻습니다.
Orthogonal decomposition
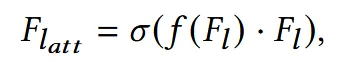
Global과 Local feature를 합치기 전에 Local feature에 위의 수식과 같은 self-attention mechanism을 적용합니다. 는 Softplus activation function, f는 채널이 1인 convolution입니다.
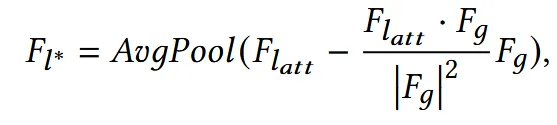
이후 Cross attention 수식과 비슷한 매커니즘으로 와 겹치지 않는 진짜 로컬한 정보만 남깁니다.
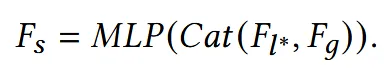
최종적으로 나온값을 global feature와 concat해서 MLP의 입력으로 들어가면 최종값 가 나옵니다.
Geometry-guided Feedback Loop
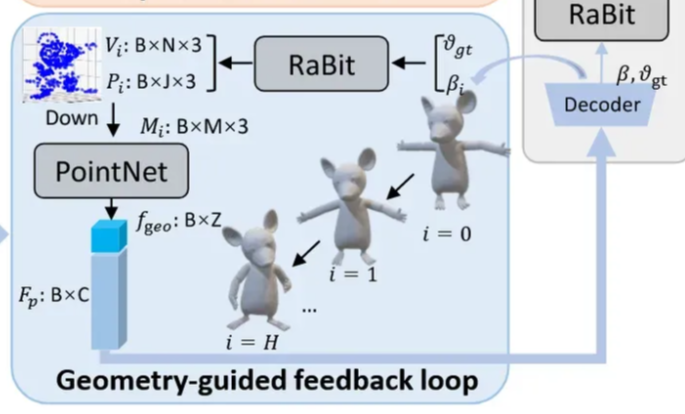
Cartoon 캐릭터의 복잡하고 과장된 pose를 정밀하게 하기 위한 과정입니다. 기존 HMR이나 pyMAF에서 반복적인 학습을 통해서 pose를 refine하는 과정은 이미 진행했었습니다. 차이점은 3D geometry 정보를 직접 사용한다는 점입니다.
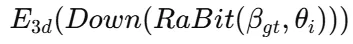
Ground truth Shape 정보인 와 i번째 pose 정보인 를 Rabit에 넣어서 vertex를 생성합니다. 이때 생성되는 vertex의 개수는 30,000개가 넘기 때문에 연산 부담이 큽니다. 따라서 Downsamplin(Down)을 진행해서 점 수를 M개로 줄입니다. Vertex가 줄어든 후 3D PointNet()를 사용해 기하적인 특징을 추출합니다.
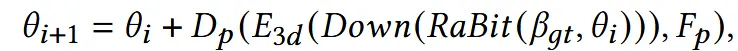
Decoder에 image feature 정보()와 함께 PointNet을 통해서 뽑은 기하학적인 특징을 추출한 것을 pose parameter로 업데이트 하면서 이를 반복합니다.
Training
기존 방식들이 사용하는 Pose나 Shape 파라미터를 비교하면서 학습하거나 2D로 projection해서 학습하는 대신 아래에 제시된 loss를 기반으로 학습됩니다.
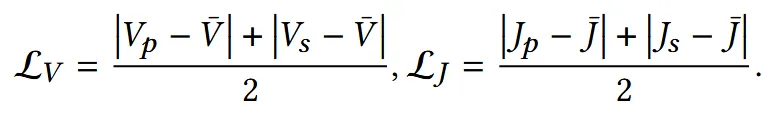
V를 vertex position, J를 joint location일 때 ground truth랑 비교해서 생성하는 loss는 위와 같습니다. 단순히 각각에 대해서 L1 loss를 적용한 것입니다.
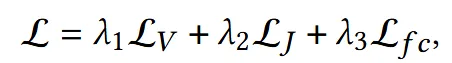
Feature consistency loss까지 더한 loss는 최종적으로 위와 같습니다. λ1=100, λ2=100, and λ3=1를 사용했는데 이러면 사실상.. feature consistency loss의 역할은 중요도가 떨어지는 파라미터인거 같습니다.
Experiments
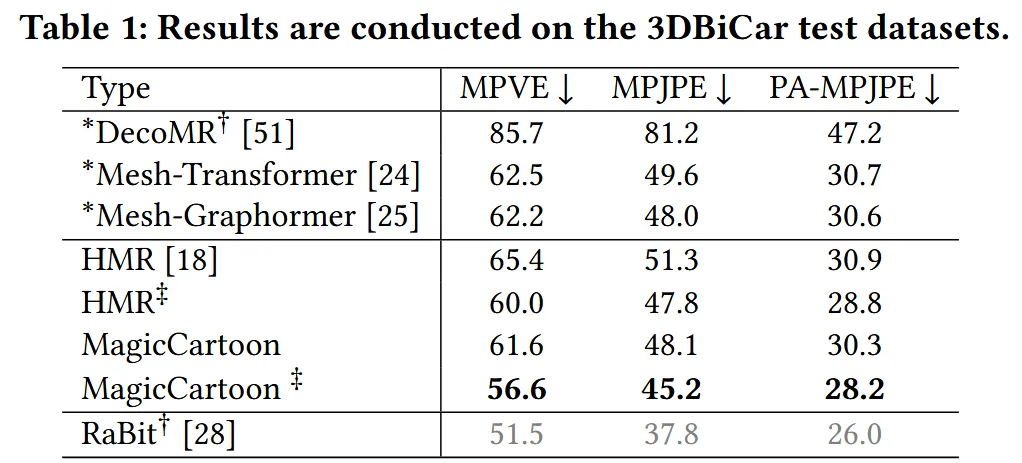
Rabit에서 사용한 3DBiCar 데이터에 대해 이전과 동일하게 1050개는 학습, 450개는 평가로 사용했습니다. 평가지표로는 human paramete model-based approach인 Per-Vertex Error(PVE), Mean Per-Joint Position Error)와 Mean Per-Join Position Error(PA-MPJPE)를 사용했습니다.


