EditP23: 3D Editing via Propagation of Image Prompts to Multi-View[2025 arXiv]

Mask 없이 3D 물체의 Editing을 하겠다는 논문입니다. 입력으로 3D Mesh와 정면 시점에서 어떻게 바꾸겠다는 정보를 제공해주면, 해당 정보를 기반으로 3D 상에서의 편집이 가능해집니다. 어떻게 3D에 FlowEdit을 적용했는지 살펴보도록 하겠습니다.
Method
Overview
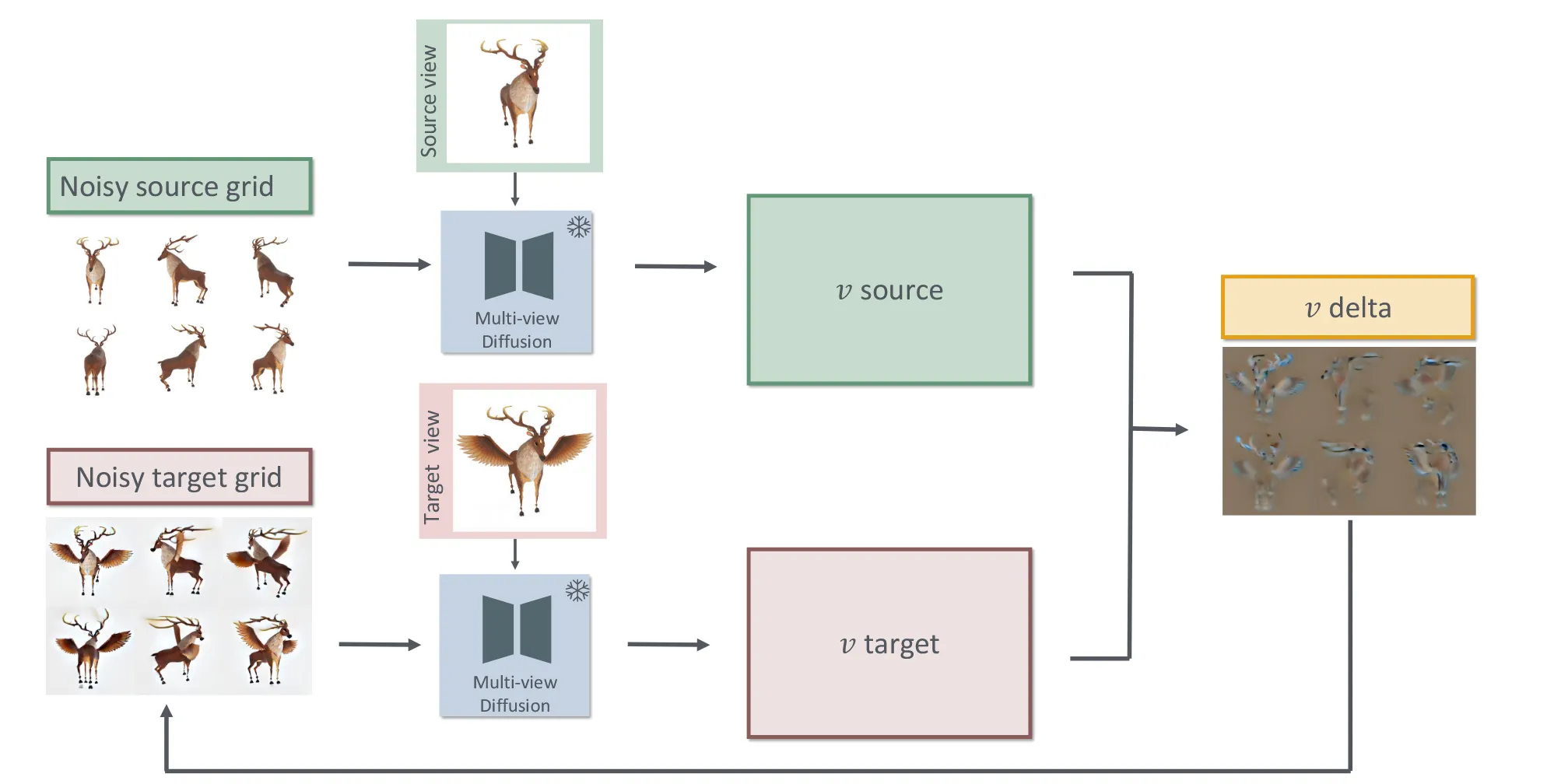
첫번째로 multi-view grid(mv-grid)를 생성하고, 이를 기반으로 3D object를 생성하는 2-stage pipeline를 채택했습니다.
대충 아키텍처를 봤을 때 zero123++를 통해서 생성된 이미지에 Target view에 대해서 수정하고 싶은 target image를 넣으면 이에 맞게 6개의 이미지(grid 이미지)가 Flow Edit을 기반으로 변경되는 느낌이고, 두번째 stage에서는 Multiviewimage to 3D로 생성하는거같습니다. 제 생각이 맞는지 하나하나 자세히 살펴보도록 하겠습니다.
Preliminaries: Multi-View Diffusion Models
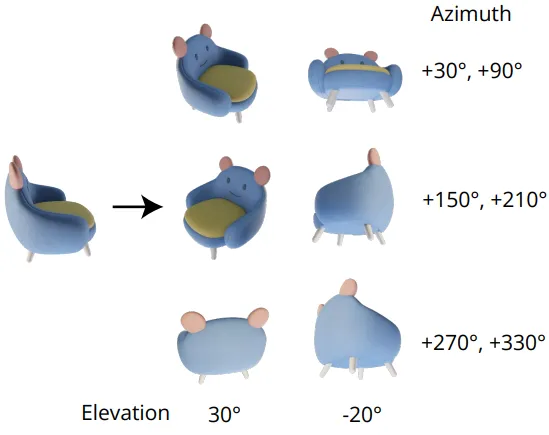
Mv-grid를 생성하기 위한 Multi-view diffusion model로는 Zero123++를 사용했습니다. 해당 모델은 입력 이미지를 넣으면 정해진 6개의 시점의 이미지를 1개의 grid로 생성하는 모델입니다.
Edit-Aware Denoising for Multi-View Diffusion
이 논문은 Delta Denoising Score(DDS)나 FlowEdit에서 제안된 방식처럼, edit-aware denoising 기법을 사용합니다. 핵심 아이디어는 원본 이미지(original prompt)와 사용자가 수정한 이미지(target prompt)의 차이를 계산하여 edit direction이라는 벡터를 구하고, 이 방향을 따라 전체 3D 이미지들을 수정해 나가는 것입니다. 이 과정을 통해 2D 편집 내용을 3D 구조에 일관되게 반영할 수 있습니다.
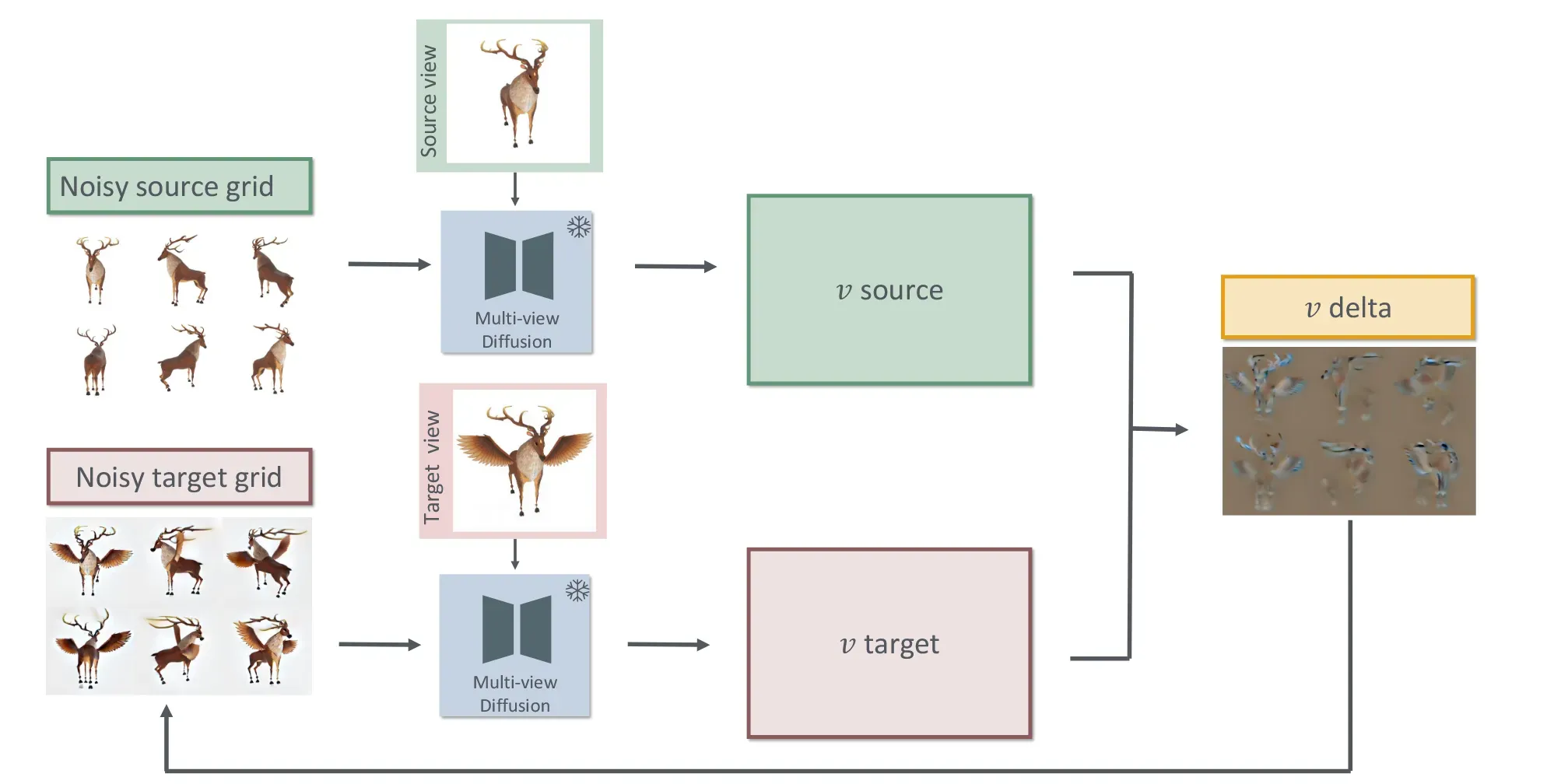
그림을 보면 구조를 더 쉽게 이해할 수 있습니다. diffusion 모델 Zero123++에 원본 이미지를 조건으로 넣으면, 각 뷰에 대한 예측된 변화 방향(velocity)이 나옵니다(v source). 반면, 사용자가 수정한 이미지를 넣으면 또 다른 예측 결과 (v target)가 나오고, 이 둘의 차이인 edit direction이 바로 우리가 원하는 편집 방향입니다. 이 edit direction을 활용해, 현재 denoising 중인 multi-view grid를 점진적으로 수정하며 최종 결과를 생성합니다.
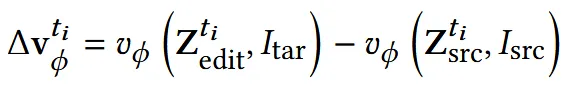
이 과정을 수식으로 표현하면 위와 같습니다. target 조건에서 예측된 velocity와 source 조건에서 예측된 velocity의 차이가 Δv이며, 이 벡터가 바로 편집 방향입니다. 이러한 Δv는 하나의 시점에서 편집된 이미지 한 장만을 조건으로 주었음에도, 전체 6개의 multi-view 이미지(grid 전체)에 일관되게 변화를 반영하는 역할을 합니다.
Algorithm

원본 이미지와 편집된 이미지를 각각 노이즈 상태로 만들면 비교시 공통된 부분과 노이즈로 인한 차이가 섞이게 됩니다. 따라서 DDS에서 사용한 동일한 노이즈를 각각에 똑같이 주입합니다.
FlowEdit과 다른 방식으로 노이즈를 둘다 적용했다고 하는데, 사실 FlowEdit은 source image는 존재하고 target image만 생성하지만, 해당 논문은 2개의 이미지(grid)를 동시에 생성하기 때문에 동일한 노이즈를 각각 똑같이 주입한 것이 차이점입니다.
Stage2 즉 멀티뷰 이미지를 이용해서 3D를 생성할 때는 InstantMesh를 사용했습니다.
Experiments


