SHAP-EDITOR: Instruction-guided Latent 3D Editing in Seconds[2024 CVPR]

기존에 3D 모델을 Editing 할 때 2D 이미지로 렌더링 한 뒤 2D space에서 변환한 뒤 이를 다시 3D로 보내는 distillation 방식을 사용했습니다. Distillation 방식은 1개의 모델을 수정하는 데에도 수십 분이 걸리기 때문에 실시간 사용에 부적합합니다. SHAP-EDITOR는 feed-forward 방식으로 빠르게 한번의 네트워크 연산만으로 1초 이내에 편집을 가능하게 했습니다. 어떻게 1초만에 3D Mesh를 편집할 수 있었는지 자세히 알아보도록 하겠습니다.
Method
위에도 설명했지만 기존의 distillation 방식은 3D 데이터를 2D로 렌더링 한다음에 이 렌더링한 이미지를 업데이트할 때의 정보를 이용해서 3D model의 파라미터 를 업데이트 합니다.
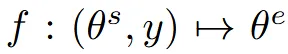
위의 수식은 source 3D object 가 들어왔을 때 text prompt y를 기반으로 편집된 target 3D object 를 생성하는 것입니다.
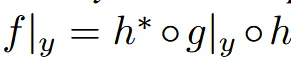
해당 논문에서는 위와 같이 latent 상에서 업데이트 하는 방식인 feed-forward editor function f를 제안했습니다. 이를 위해 첫번째로 encoder( )와 decoder()로 3D object를 latent r로 보냅니다.
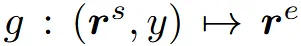
마지막으로 latent 상에서 text prompt y를 기반으로 편집하는 함수를 사용하면 됩니다. 이를 통해 빠르고 간결하게 text prompt를 3D object에 반영할 수 있습니다.
Background
Shap-E
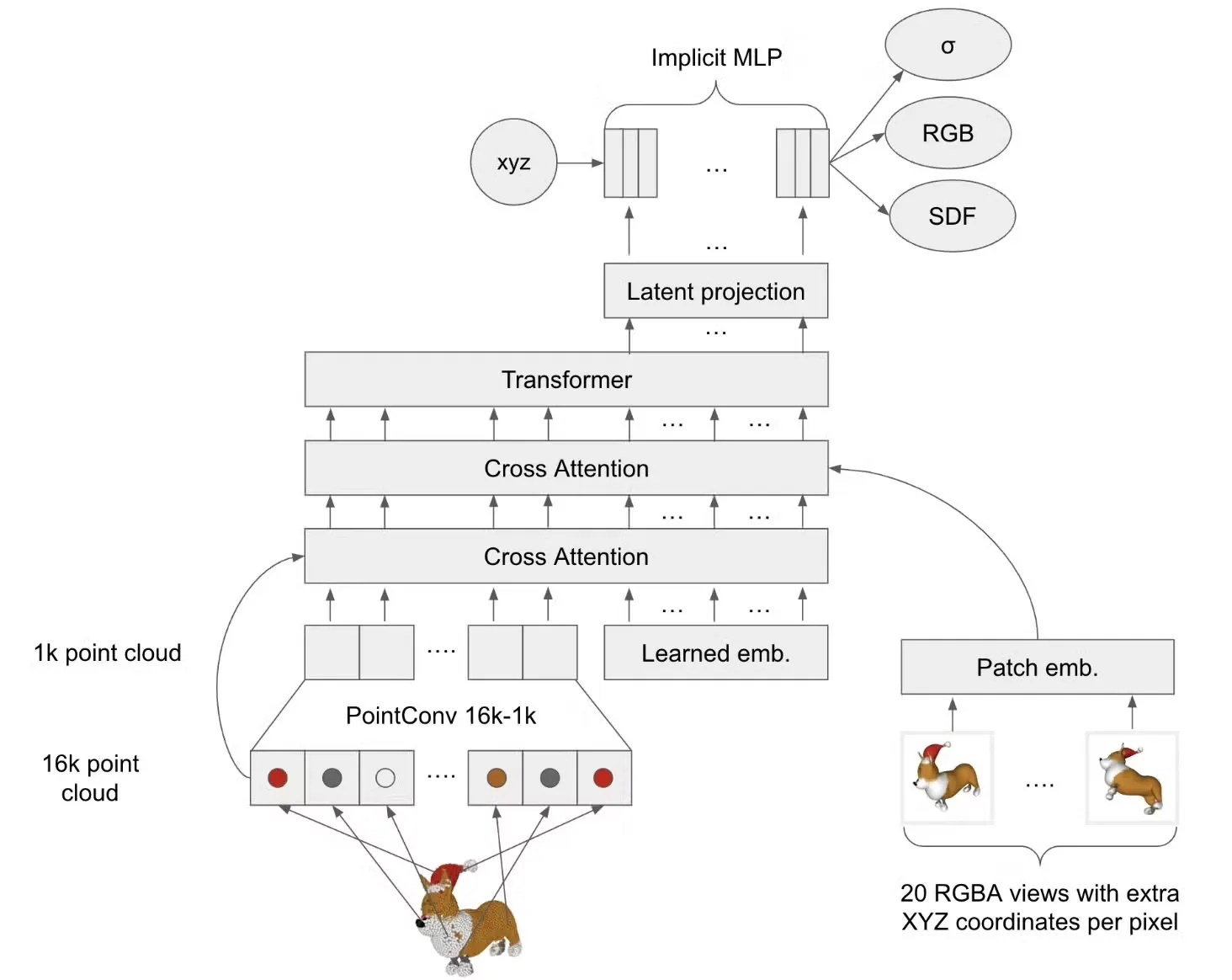
3D object를 latent로 변환하기 위해 새로 학습된 모델이 아니라, 사전학습된 off-the-shelf 모델인 Shap-E를 사용했습니다. Shap-E는 3D 오브젝트를 latent로 인코딩하는 auto-encoder 구조를 포함하고 있으며, 해당 latent는 다시 디코더를 통해 3D 오브젝트로 복원할 수 있습니다. 또한, Shap-E는 텍스트나 이미지 조건을 기반으로 latent를 샘플링할 수 있는 diffusion 기반 생성기도 포함하고 있으며, SHAP-EDITOR에서는 주로 이 모델의 Encoder와 Decoder를 사용하여 3D ↔ latent 변환에 활용합니다.
Score Distillation Sampling(SDS)
SDS는 2D diffusion을 distillation을 통해서 3D 파라미터를 업데이트 하는 대표적인 방법입니다.
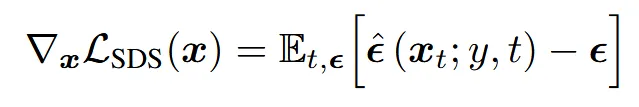
이전부터 계속 언급한 3D에서 렌더링 해서 2D로 변환하고 이를 diffusion을 이용해서 distillation 하는 방식의 대표적인 방법이 위의 수식인 SDS입니다.
3D editing in latent space
Shap-E를 통해서 latent를 생성했으니 어떻게 latent를 수정할지에 대한 latent editor g(SHAP-EDITOR) 방식을 설명하도록 하겠습니다.
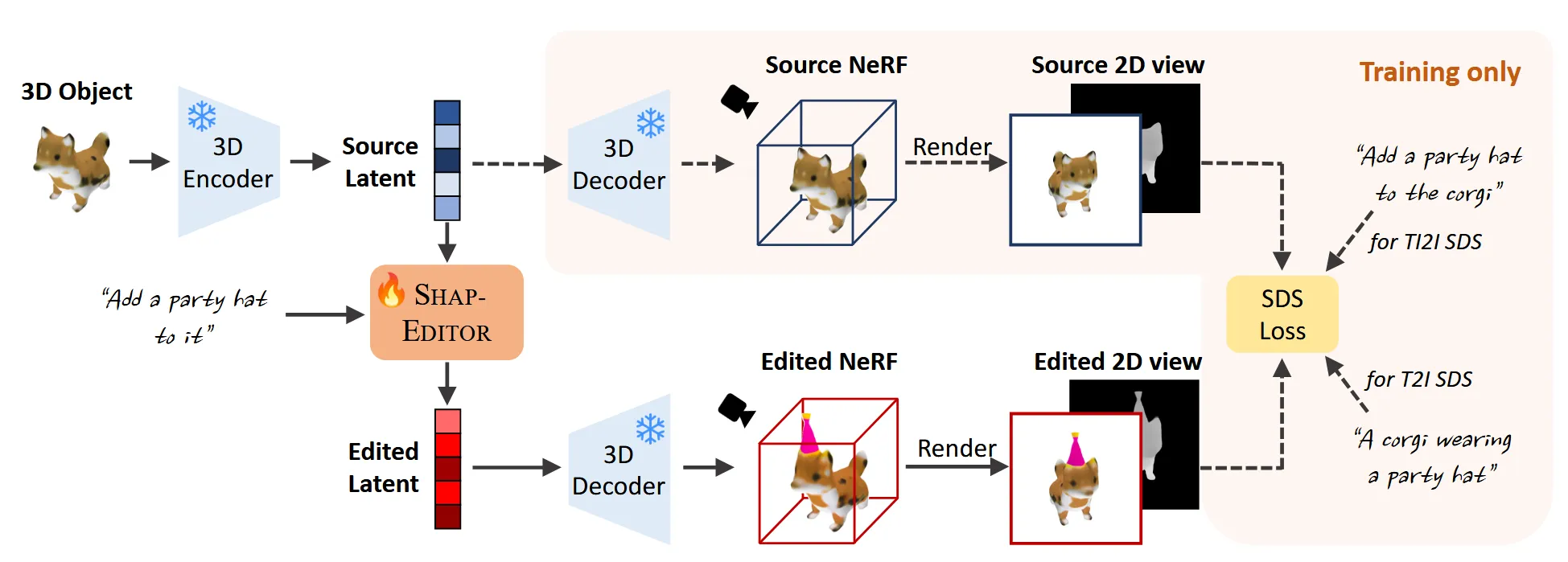
3D editing을 학습하려면 원본 3D mesh, 편집된 3D mesh, text prompt 이렇게 3가지 데이터셋이 존재해야합니다. 하지만 실제로는 이런 데이터셋은 존재하지 않습니다. 따라서 대부분의 모델은 2D 이미지 편집 모델을 활용합니다. SHAPE-EDITOR는 training time에는 2d diffusion 모델을 이용해서 함수 g를 간접적으로 학습하고, inference time에는 사용하지 않도록 합니다.
Training the latent editor
Shap-E를 통해 latent 벡터 𝑟를 얻는 방법은 두 가지가 있습니다. 첫 번째는 text prompt 없이 기존 3D 오브젝트 를 인코더 h(⋅)에 통과시켜 직접 인코딩하는 방식이며, 이는 학습 시 사용됩니다. 두 번째는 text prompt를 이용해 latent를 확률적으로 샘플링하는 방식 으로, 이는 주로 inference시 사용됩니다.
이후에는 아래와 같은 SDS 기반 loss를 사용해, 2D 이미지 상에서 text prompt에 따라 latent를 업데이트하는 방법을 학습합니다:
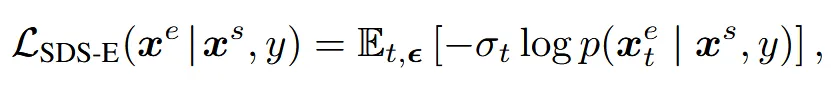
학습 시에는 를 각각 3D 오브젝트로 디코딩한 뒤, 랜덤한 시점에서 렌더링하여 얻은 이미지를 기반으로 loss를 계산합니다.
The choice of g
SHAP-EDITOR는 latent 편집 함수 g를 처음부터 새로 학습하지 않고, Shap-E 내부의 denoising network를 활용하여 초기화합니다. 이를 위해 노이즈가 섞인 latent와 원본 latent를 함께 입력으로 사용하고, denoiser는 이를 기반으로 편집된 latent를 예측합니다. 다만 Shap-E의 원래 목적은 단순 복원이기 때문에, 이 초기값은 편집 작업에는 최적화되어 있지 않으며, 이후 훈련을 통해 목적에 맞게 보정됩니다.
2D editors
논문에서는 mesh의 style은 바꾸지만 전체적인 구조는 유지하는 global edits와 부분적인 구조는 바꾸지만 나머지 부분은 유지하는 local edits를 진행하기 위해서 image-to-image를 distillation 해서 사용합니다.
Global Editing
Text-guided Image-to-Image(TI2I) loss
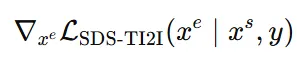
InstructPix2Pix(2D diffusion 모델)을 사용해서 SDS gradient를 추정하고 이를 이용해서 function g를 학습합니다. 또한 distillation 성능 향상을 위해서 CFG(classifier-free guidance)도 적용했습니다.
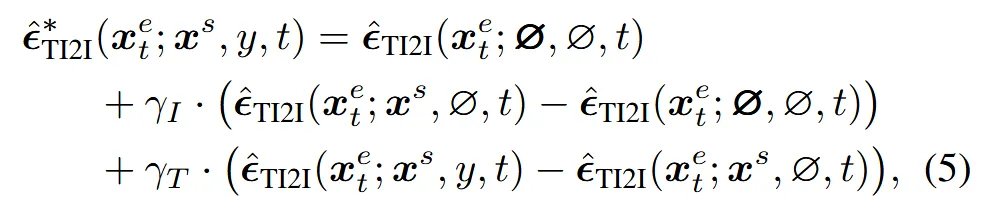
Appendix에 나와있는 CFG 수식은 위와 같고 I와 T의 guidance scale은 각각 (2.5, 50)을 썼다고 나와있습니다. Text prompt의 guidance scale은 잘 아실텐데 image guidance sclae이 왜 나왔는지 궁금하신 분들은 수식을 자세히 보시면 condition으로 만 들어간 것을 확인할 수 있습니다. 따라서 해당 수식은 편집된 결과가 원본 object를 얼마나 따라가야 하는지를 조절하는 역할입니다.
Depth regularisation for global editing
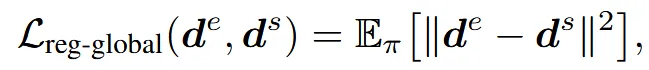
Object의 전체적인 형태를 유지하기 위해서 렌더링한 depth map사이의 depth regularization을 추가합니다.
Local Editing
T2I loss
너무 많이 변형되는 문제를 방지하기 위해서 편집된 상태 전체를 설명하는 텍스트 를 추가 condition으로 넣어서 SDS gradient를 계산합니다.
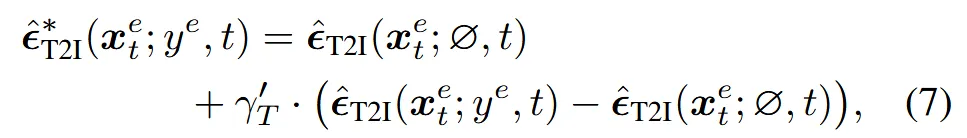
수식을 보면 기존에 추가적인 term 하나만 더 붙은 것을 확인할 수 있습니다. 이때는 guidance_scale이 총 3개인데 이미지, 텍스트, 전체적인 텍스트(방금 설명한 내용) scale은 각각 (2.5, 7.5, 50)으로 전체적인 텍스트의 중요도가 상당히 높은 것을 알 수 있습니다.
Masked regularisation for local editing
우리가 수정하고 싶은 부분의 mask를 생성하기 위해 필요한 cross-attention map은 TI2I 모델의 SDS loss 학습 과정에서 U-Net feature를 통해 얻을 수 있습니다. 예를 들어 “Add a party hat to the corgi”라는 문장이 있을 때, “hat”이라는 text embedding과 이미지 feature 간의 cross-attention map을 추출하여 mask m을 생성합니다.
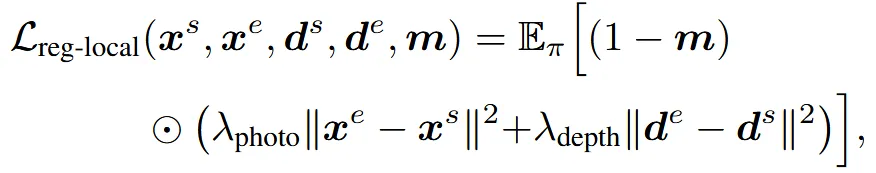
이후 위의 수식과 같이, mask m에 해당되지 않는 영역 (1−m)이 원본과 유사하게 유지되도록 photometric 및 depth 기반 정규화 손실을 추가합니다.
Experiments
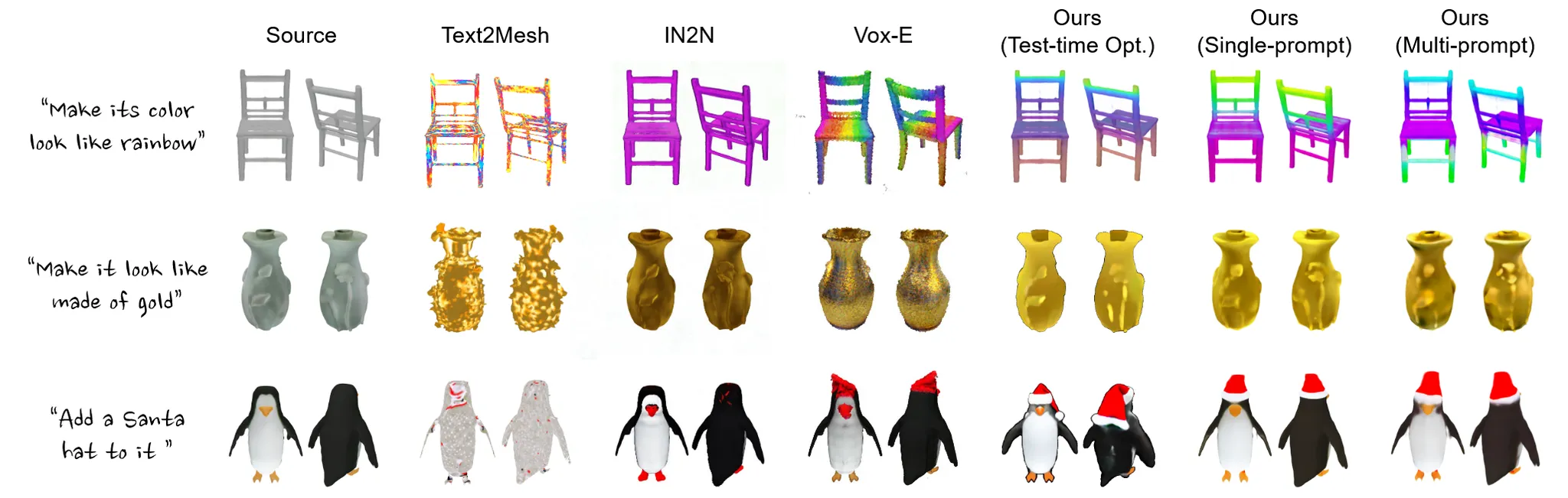


Limitations
Shap-E 모델의 latent space를 기반으로 학습을 했기 때문에 해당 모델의 퀄리티를 넘어서기 어렵습니다. 또한 어떠한 텍스트 prompt도 반영할 수 있는 open-ended editor는 구현하지 못했습니다.
