Garment3DGen: 3D Garment Stylization and Texture Generation[2025 3DVision]
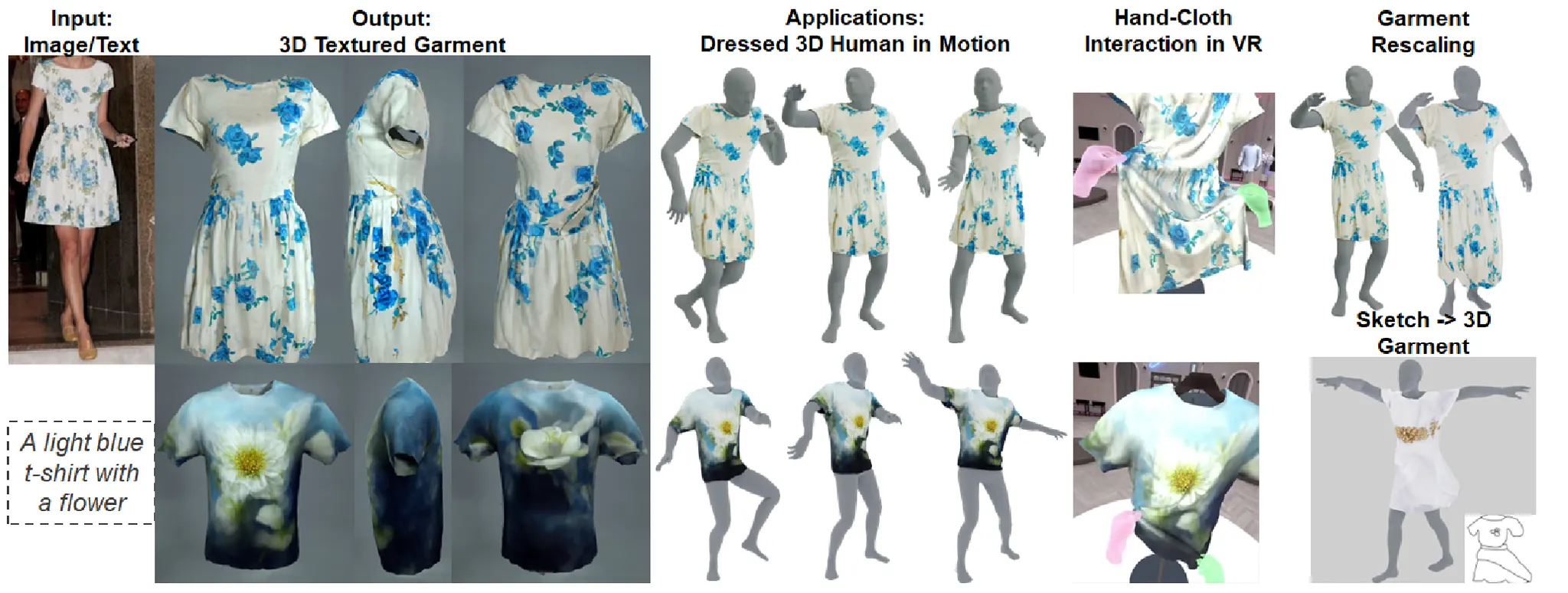
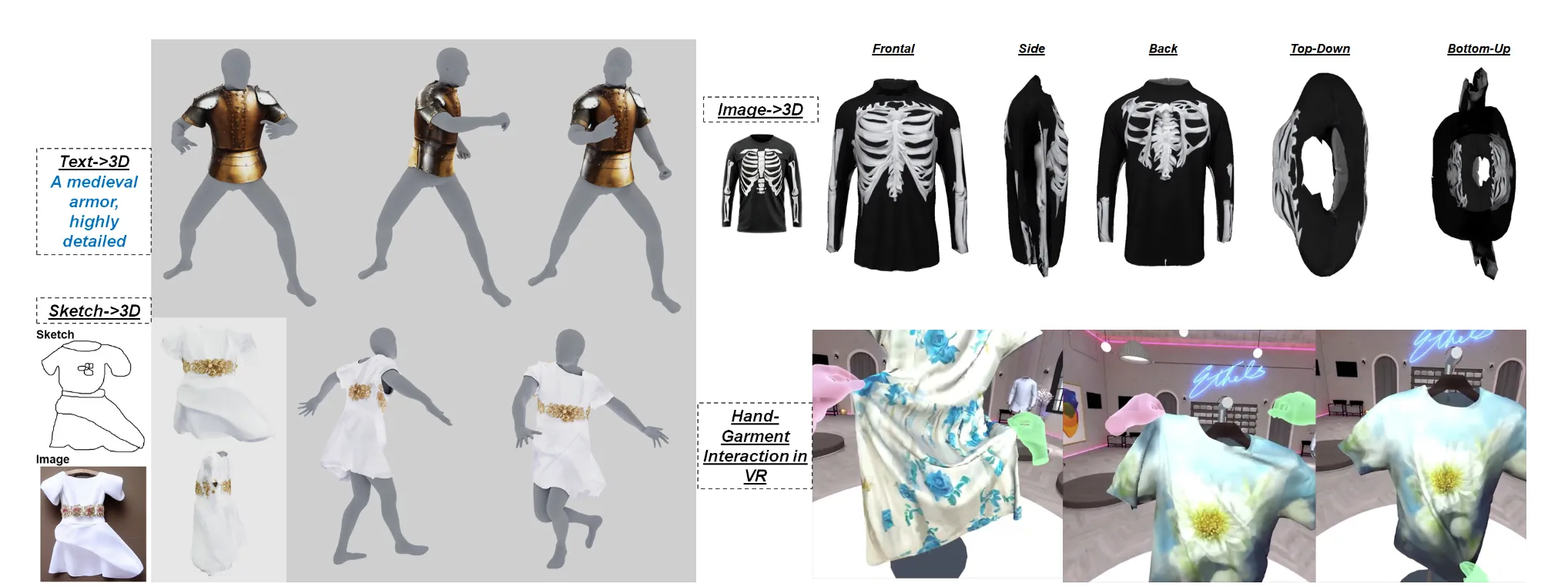
Input으로 Image혹은 Text로 내가 원하는 형태의 옷을 넣으면 해당 input을 기반으로 사람이 옷을 입고 있는 결과가 나오는 모델입니다. 3D Deformation을 궁금해하던 중 아이디어를 가져올 수 있을거같아서 Deformation 부분을 중심적으로 읽어보도록 하겠습니다.
Methodology
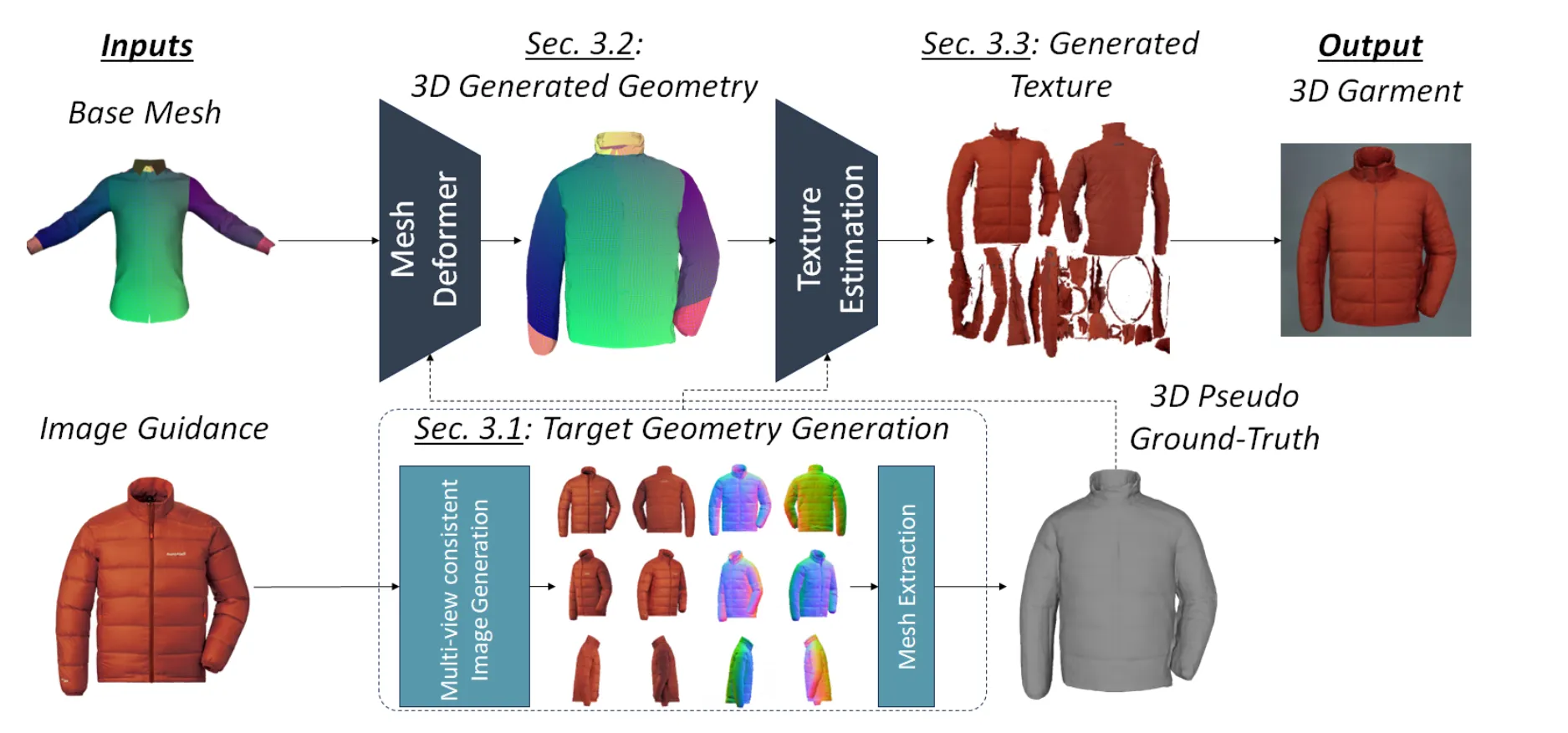
Target Geometry Generation

이 부분에서 어떻게 입력이미지의 신호를 잘 이용해서 Deformation을 진행할 수 있는지 설명합니다. 간단하게 요약하면 입력 이미지로부터 3D Geometry guidance 값인 를 생성하고, 이를 deformation 대상이 되는 base meh 을 향해 supervise하는 것 입니다.
Textdeformer: Geometry manipulation using text guidance 논문에서는 하나의 이미지를 기반으로 3D를 Deformation했는데 이럴 경우 단순히 CLIP 만을 이용하기 때문에 제약이 부족하고, 결과가 어색하거나 과도하게 변형되고, 미세한 디테일을 놓치게 됩니다. 따라서 Zero123++나 Wonder3D를 이용해서 새로운 시점의 6개 RGB와 normal을 생성한 뒤, 이를 기반으로 LRM(Large Reconsturction Model)을 이용해서 3D Pseudo Ground-Truth를 생성한 후 이를 기반으로 Deformation을 진행하는 것 입니다.
Topology-Preserving Deformations
한마디로 요약하자면 입력 base mesh 에 대해 topology를 보존하면서 변형하려면, 삼각형 단위의 미세한 변형을 매끄럽게 이어주는 방식이 필요합니다. 이를 위해 Neural Jacobian Fields (NJF) 기법을 사용해 per-triangle Jacobian을 도입하고, 최적화 과정에서 이들 Jacobian이 나타내는 target 변형을 따르는 deformation map Φ를 계산합니다.
조금 더 자세히 설명하자면 Topology를 바꾸지 않기 위해 vertex 단위가 아니라 삼각형 단위로 deformation을 정의하고 이 deformation은 per-triangle Jacobian으로 표현됩니다. 그리고 이 Jacobian들이 나타내는 변형을 반영하는 전체 mapping 함수가 deformation map Φ이고 이는 Poisson 최적화 방식으로 진행됩니다.
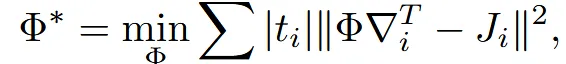
Deformation map은 위와 같은 수식을 통해서 구할 수 있고, 여기서
- : 삼각형 에서의 실제 변형의 Jacobian
- : 우리가 설정한 목표 변형 행렬
- : 삼각형의 면적 (큰 삼각형의 영향력 더 큼)
3D Supervision
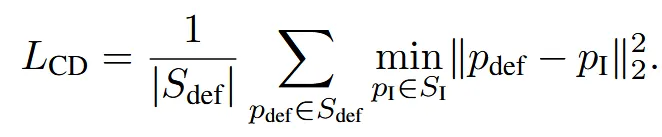
1차원 Chamfer Distance(CD) loss를 통해서 최종 출력되는 Mesh가 pseudo-ground-truth mesh의 형태를 따르도록 학습합니다. Chamfer distance는 방향성이 존재하고 논문에서는 단방향으로 deformation 결과가 target을 따라가도록 유도합니다. 여기서 유도하는 값은 point cloud 간의 geometric similarity입니다.
Regularization
CD loss만 사용하면 mesh가 target 모양을 따라가지만 너무 날카롭거나 뒤틀리는 현상이 발생하기 때문에 추가적인 loss를 진행
Laplacian Smoothing ($L_{\text{Lap}}$)
Vertex들이 주변 이웃의 평균 위치와 너무 다르지 않도록 유지 → smoothness 유지
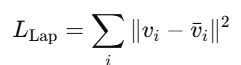
Triangle Area Regularization ($L_{\text{triag}}$)
너무 작은 삼각형 방지 → mesh가 지나치게 압축되거나 degenerate triangle이 생기지 않도록 유지
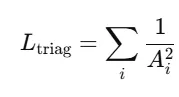
2D Supervisions
Deformation mesh와 pseudo-ground-truth mesh랑 여러 시점에서 렌더링한 이미지끼리 비교해서 loss를 계산합니다.
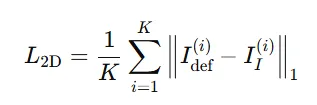
렌더링된 2개의 이미지를 L1 loss를 통해 loss값 계산. L1 loss는 MSE보다 shapr difference(모서리, 실루엣)에 더 민감하게 작동하기 때문.
Embedding Supervisions
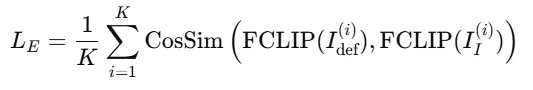
기존 CLIP이 아닌 의류 데이터로 fine-tuning한 FashionCLIP을 통해서 정확하게 스타일 차이를 표현하는 embedding을 제공. 이를 통해서 스타일이나 느낌이 비슷하면 loss값이 줄어드는 Soft supervision이 가능합니다.
Final loss
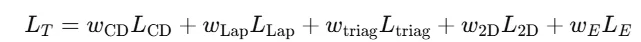
최종적으로 CD, Laplacian, triangle, 2D Supervision, Embedding loss를 모두 더하도록 loss를 설계 했습니다.
Texture Estimation: 생략
Experiments

Signle image를 바로 생성하는 triplane이랑 성능이 비슷…

Wonder3D + LRM 성능도 좋다?
추가적인 실험