Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers[2024 CVPR]
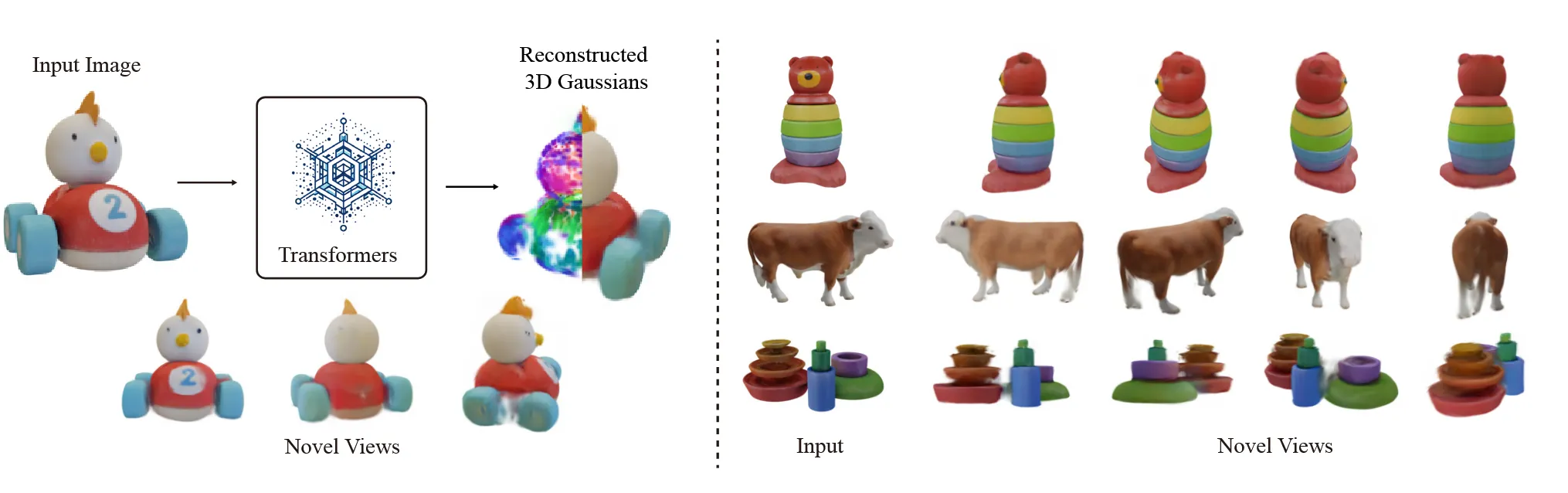
SDS를 통해서 2D diffusion을 이용한 3D Deformation이 가능했지만, SDS는 많은 시간이 걸린다는 단점이 존재했습니다. 이를 극복하기 위해서 Point cloud를 변형하는 많은 논문들이 나왔고 그중에 하나인 Triplance Meets Gaussian Splatting을 설명해드리겠습니다.
Method
Hybrid Triplane-Gaussian
3D Gaussian을 이용하면 빠른 렌더링과 좋은 퀄리티를 얻을 수 있지만, 1장의 이미지로부터 3D Gaussian의 많은 속성(위치, 크기 및 방향, 색상, 투명도)을 예측하는 것은 어렵습니다. 따라서 논문에서는 3D Gaussian 대신 점의 위치(Point Cloud)와 속성(Triplane)으로 이루어진 Triplane-Gaussian을 예측하도록 모델을 설계 했습니다.

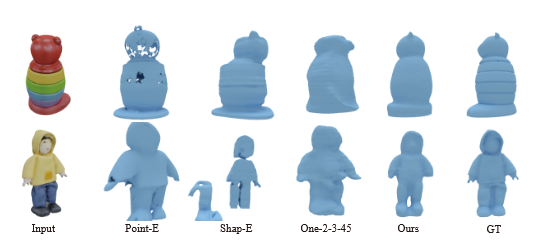
실제로 예측하는 값이 3DG(3D Gaussian), Triplane-NeRF, Triplane-Gaussian일 때의 퀄리티를 비교한 결과인데 확실히 Triplane-Gaussian의 퀄리티가 가장 좋은 것을 확인할 수 있습니다.
Triplane에 대해서 조금 더 구체적으로 설명해드리면 차원이 3XCXHXW인 implicit feature field 입니다. Triplane은 3개의 수직인 feature plane 로 구성되어 있습니다. Point cloud의 어떤 점 x를 xy,xz, yz 평면에 투영하면 점 가 나오고, 이를 이용해서 Tiplane을 trilinear interpolation 해서 feautre 를 생성합니다.
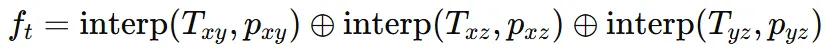
수식적으로 위와 같이 3개의 Triplane을 concat 한 값이 최종 feature 의 값 입니다.
3D Gaussian Decoder
위에서 설명한 feature와 point cloud 정보를 입력을 MLP에 넣어서 3D Gaussian 정보들을 예측합니다.
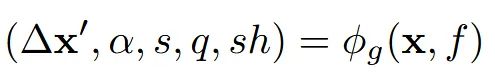
3D Gaussian 정보는 opacity, anisotropic covariance(scale, rotation), spherical harmonics이 존재하는데 추가적으로 position의 offset도 x’로 예측하도록 합니다.
이미지에서 직접 추출한 local image feature도 넣기 위해서 우리는 point cloud의 위치 x를 알 때 이걸 2D로 projection 시켜서 이에 대응되는 2D image feature 정보를 로 구할 수 있습니다. 이렇게 구한 이미지 feature를 기존 triplane feature()와 concat해서 f로 사용합니다.
Local features에는 RGB, DINOv2 feature, Mask, distance transform(마스크와의 거리) 정보가 존재합니다.
Rendering
위의 알고리즘을 통해서 Gaussian 값을 예측할 수 있고, 이를 이용해서 3D Gaussian Splatting 모델을 사용해서 빠르고 효율적이게 3D를 생성할 수 있습니다.
Reconstruction from Single-View Images
하나의 이미지를 Transformer 디코더 2개를 사용해서 point cloud와 triplane을 각각 생성하도록 진행하는 과정을 자세히 설명하도록 하겠습니다.
Image Encoder
입력 이미지를 DINOv2(pre-trained ViT based model)에 넣어 image feature tokens를 생성합니다. ‘LRM’ 논문에서 사용한 방법처럼 카메라 feature를 넣기 위해서 adaptive layer norml(adaLN)를 추가적으로 활용했습니다.
들어가는 카메라 파라미터는 Extrinsic Matrix(World 좌표계에서 카메라가 어디에 있고, 어느 방향을 보고 있는지를 나타내는 행렬) 4X4를 flatten해서 16차원으로, Intrinsic Matrix(카메라 자체의 내부 설정, focal length 등) 3X3를 flatten해서 9차원으로 변환한 뒤 2개를 concat해서 하나의 25차원 벡터로 만듦
이후에 DINOv2에 사용하기 위해 MLP layer를 통해서 25 → 768(예시 차원)로 차원을 변환하면서 DINOv2에서 사용할 수 있게 차원을 맞춰줍니다.
Transformer Backbone
우리는 point cloud와 tirplane feature를 각각 예측하기 때문에 동일한 transformer를 독립적으로 사용합니다.
Point Cloud Decoder
Point Cloud Decoder는 하나의 이미지를 입력으로 받아서 물체의 대략적인 3D 형태를 구성하는 point cloud 2048개를 Transformer입니다. 이 방식은 Point-E 방식과 유사하게 작동하지만 Point-E는 diffusion을 사용해서 시간이 오래걸렸지만 해당 모델에서는 6-layer transformer를 사용해서 속도와 효율성 면에서 우위를 가졌습니다.
Point Upsampling with Projection-Aware Conditioning
3D GS가 initial point cloud 개수에 퀄리티 영향을 받는데 2048개만을 사용했기 때문에 추가적인 작업이 필요합니다. 따라서 point upsampling을 하기 위해서 snowflake point deconvolution(SPD) 방식으로 2048 → 16384개의 point cloud로 upsampling 합니다. Upsampling 하기 위해서 입력 이미지 local feature를 shape code(PointNet)에 결합해 각 점을 주변으로 얼마만큼 이동시킬지 예측하면서 새로운 점들을 생성합니다. 이를 두 단계 반복해서 2048 → 8192 → 16384로 점의 개수를 늘리게 됩니다.
Triplane Decoder with Geometry-Aware Encoding
Feature filed를 생성하기 위해서 learnable positional embedding과 condition으로 들어가는 이미지 feature와 카메라 정보를 넣습니다. Point cloud decoder의 6-layer transform과 유사한 아키텍처이지만 10-layer를 사용한다는점이 다릅니다.
기하학적인 정보를 주기 위해서 initial learnable positional embedding값을 point cloud를 encode한 값을 이용합니다. 해당 값은 upsampling된 point들을 2D image feature에 projection시켜서 얕은 PintNet과 local pooling을 한 뒤 orthographic projection을 3개의 평면에 진행시킵니다. feature가 중복될 경우 average pooling을 통해서 하나로 만듭니다. 이렇게 나온 feature를 기존의 positional embedding에 더해서 초기값으로 사용하게 됩니다.
Training
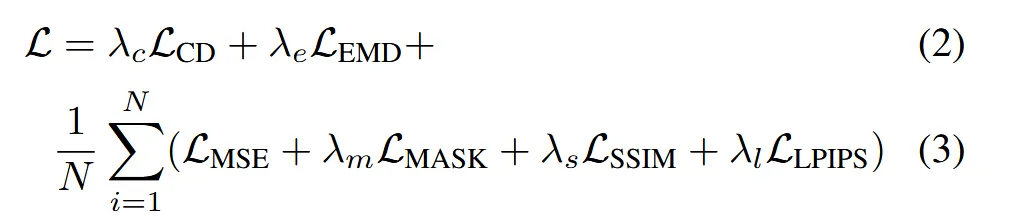
2D rendering loss
- : Chamfer Distance
- : Earth Mover’s Distance
3D point cloud supervision
Experiments