프로젝트 페이지
논문 링크
Abstract
기존 3D 생성 모델들에는 2가지 문제점이 존재했습니다.

- Janus issue: 특정 상황에서 객체가 앞뒤 모두를 동시에 나타내는 현상을 의미합니다. 즉 앞에서봐도 강아지의 얼굴이있고, 뒤에서봐도 강아지의 얼굴이 있는 상황입니다. 위의 사진에서 판다의 얼굴이 다양한 시점에서 확인되는 현상이 바로 Jansus issue입니다.
- time-consuming: 3D 객체를 생성하는데 많은 시간이 소요됩니다.
이에 GSGEN에서는 Gaussian splatting을 이용해서 위의 2가지 문제점을 해결했습니다. 또한 Text를 반영하기 위해 사용되는 2D SDS Loss를 3D로 변환한 3D SDS Loss를 사용해서 더 정교한 3D를 생성할 수 있게 했습니다.
Introduction
Diffusion을 통해서 Text-to-Image 분야의 성능은 기하급수적으로 좋아졌습니다. 하지만 3D 분야에서는 3D 자체의 복잡성 때문에 아직까지는 좋지 않은 성능을 보여주고 있습니다.
Dreamfusion을 통해서 3D 분야에서도 성공적인 사례가 나왔습니다. 하지만 NeRF와 DMTet을 사용해서 3D에 대한 prior 지식을 통합하기는 어렵다는 단점도 있습니다.
3D Gaussian Splatting은 NeRF와 DMTet과 같은 implicit representation 방법과 달리, Explicit하고 객체 중심적인 표현법이기 때문에 위의 단점을 극복할 수 있습니다.
해당 논문에서는 크게 2가지 방법을 이용해서 3D asset을 생성합니다.
- geometry optimization
- 대략적인 기하학적 구조를 형성하는 과정
- 3D point cloud diffusion prior + ordinary 2D image prior
- refinement stage
- 생성된 기하학 형태에 Texture같은 세부적인 표현을 더하는 과정
- SDS Loss + compactness-based densification
논문의 Contribution은 다음과 같습니다.
- Gaussian Splatting을 이용한 Text-to-3D 생성
- 2Stage 방식을 이용
- 3D + 2D diffusion prior를 이용한 대략적인 기하학적 구조 생성
- Texture와 같은 디테일을 표현하기 위한
- 기존의 성능들에 비해서 geometry, fidelity의 성능을 증가 시켰다. 특히 texture과 같은 디테일한 부분들의 성능을 크게 개선시켰습니다.
Related Work
3D Scene Representations
NeRF가 Novel view synthesis 분야에서 혁신적인 변화를 가져왔지만, 많은 시간과 메모리가 소요된다는 단점이 있습니다. 이에 Explicit한 방법을 이용한 3D Gaussian Splatting 방법이 나왔고 해당 방법을 이용해서 논문에서는 모델을 설계했습니다.
Diffusion Models
Diffusion model에 대한 대략적인 설명이 나온 부분입니다. forward process를 통해서 노이즈를 주입해가며 학습을 진행하고, reverse process를 통해서 노이즈를 제거하며 이미지를 생성해냅니다.
해당 논문에서는 Text를 사용할 수 있는 StableDiffusion 모델을 사용했습니다.
Text-to-3D Generation
Dreamfusion에서 사용한 방식인 Score Distillation Samplin은 렌더링된 이미지와 diffusioin prior와의 차이를 최소화하는 방식입니다. 이를 기반으로 Text-to-3D 생성 분야가 발전되기 시작했습니다.
Preliminary
Score Distillation Sampling
3D Model을 직접적으로 생성하기 보다는, 렌더링된 이미지를 Diffusion 모델을 이용해서 학습하는 방법으로 진행됩니다. 이때 장면은 differentiable image parameterization (DIP) θ로 표현됩니다. 이미지는 카메라 메트릭스와 transformation function g를 통해서 나타낼 수 있습니다.
Dreamfusion에서는 Imagen 모델을 이용해서 위의 방법을 성공적으로 수행했습니다. score estimation function인 (: noise image, y: text embedding, t: timestep)를 기반으로 학습을 진행합니다.
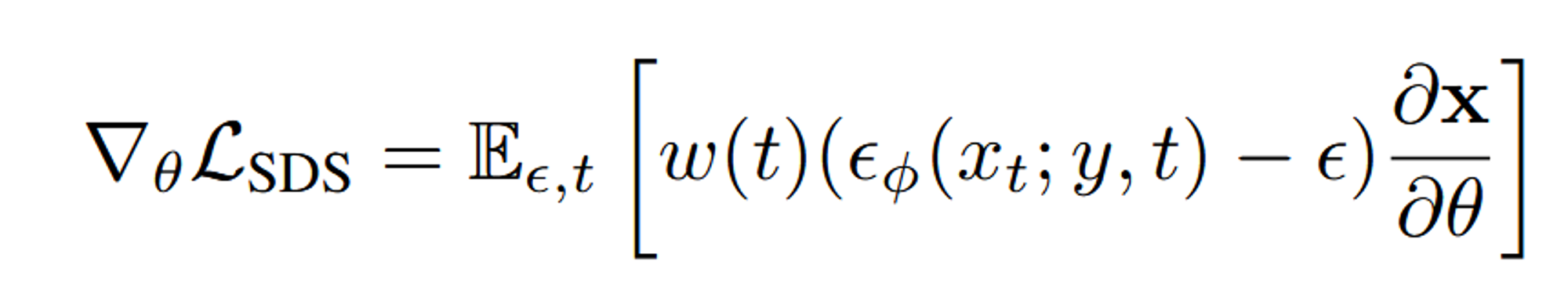
ε: Gaussian noise, w(t): weighting function
3D Gaussian Splatting
NeRF와 다르게 Anisotropic 3D gaussian으로 장면을 표현합니다. 이 Gaussian에는 위치, 공분산, 색상, 불투명도로 매개변수화 합니다.
3D gaussian들이 projection되면 2D gaussian으로 변환되고, 각 2D gaussian들은 개별 타일들에 할당됩니다.
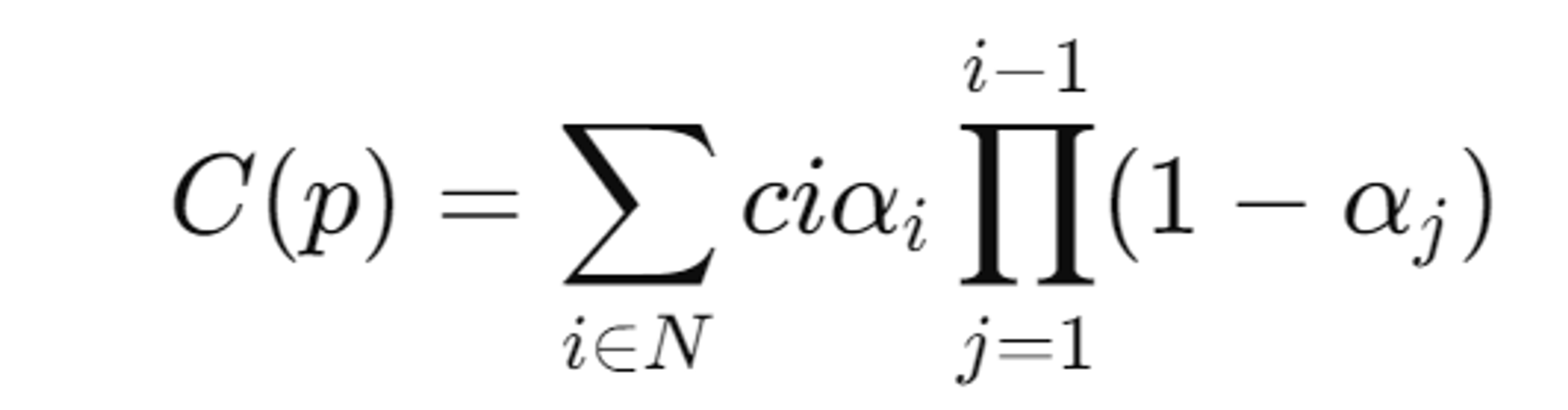
- C(p): 이미지 평면에서의 점 p의 색상
- : 점 p에서의 불투명도
- ci: i번째 Gaussian의 색상
- oi: 불투명도, μi: 위치, Σi: 공분산
- N: 해당 타일에 속한 Gaussians의 집합
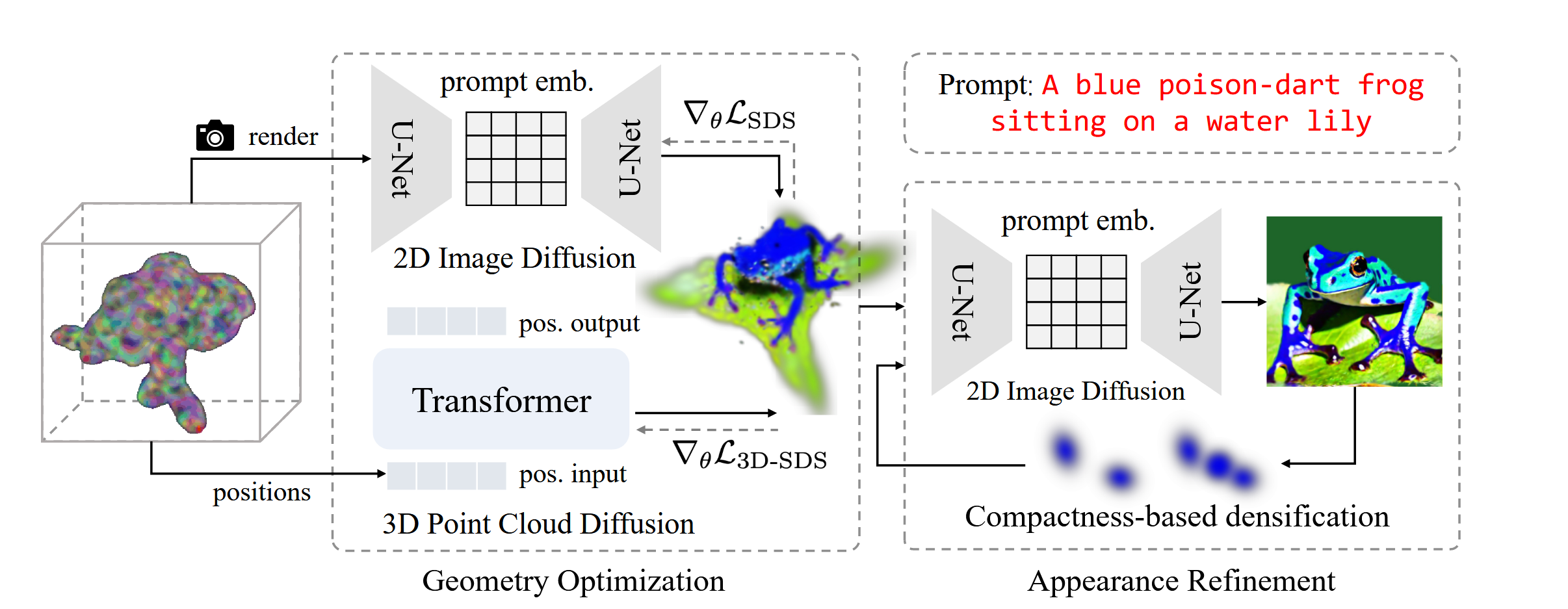
Approach
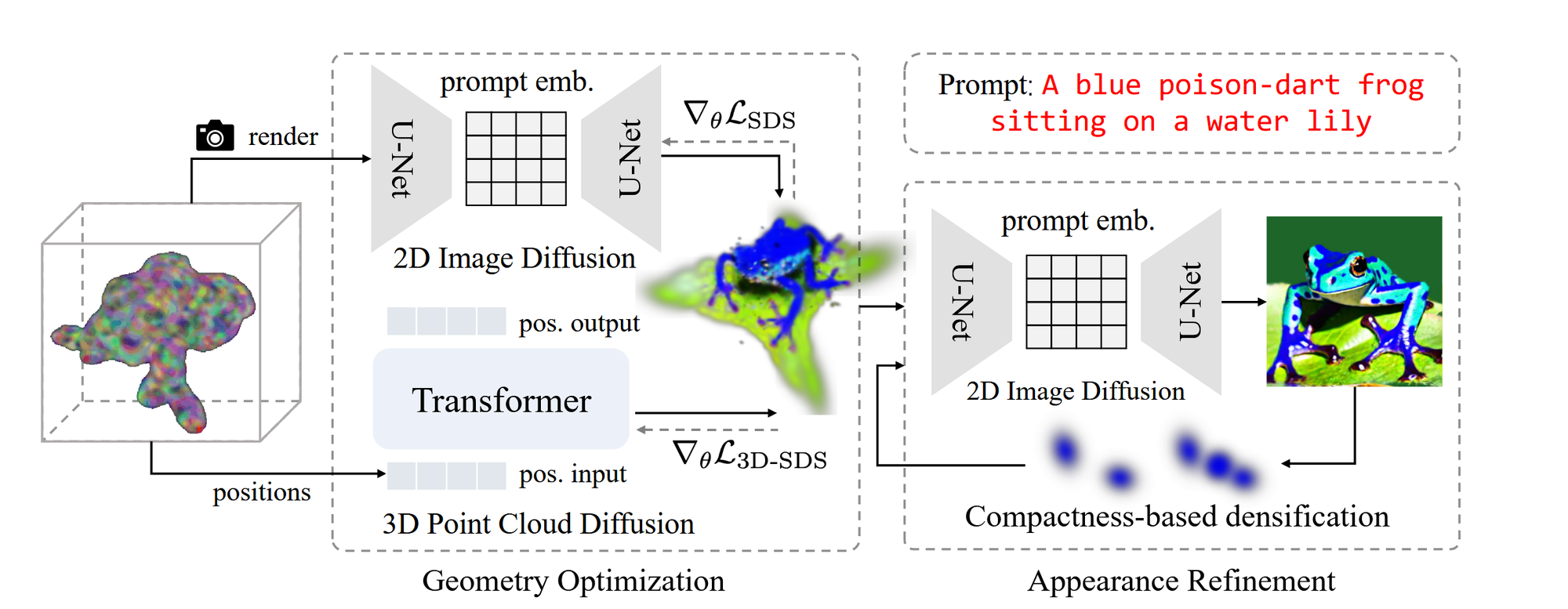
Geometry Optimization
NeRF에서 발생한 Janus 문제를 해결하기 위해 Gaussian Splatting 방법을 차용했습니다. Point-E 기반 학습을 진행했고, Point-E에서 생성된 Point Cloud와 Gaussian을 직접적으로 맞추려고 하기보다는, 이미지 확산에서 영감을 받은 3D SDS loss를 적용하여 Gaussian의 위치를 Guide합니다.
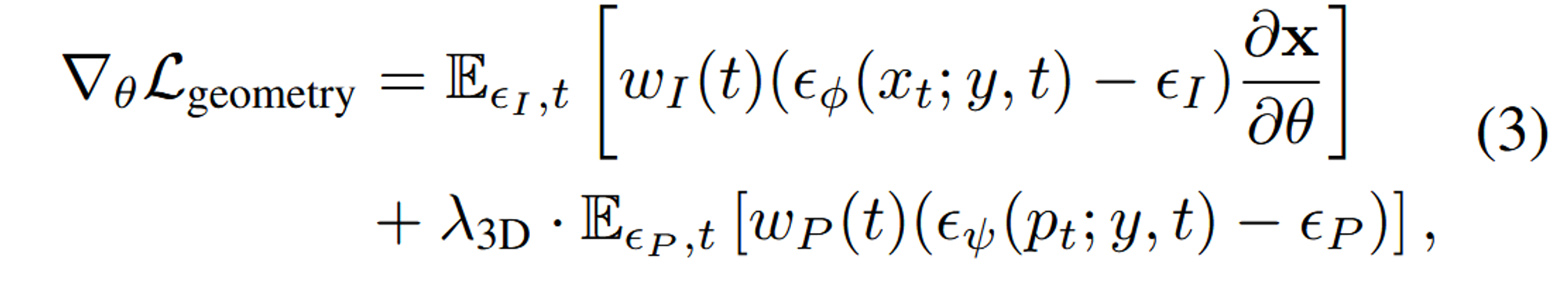
수식의 첫번째 항이 2D SDS Loss에 관한 식이고, 두번째 항이 3D SDS Loss에 관한 식입니다. Point-E가 text-point cloud diffusion 모델이기때문에 해당 모델을 기반으로 Guassian이 학습되면서 3D 형태가 변형된다고 보시면 됩니다.
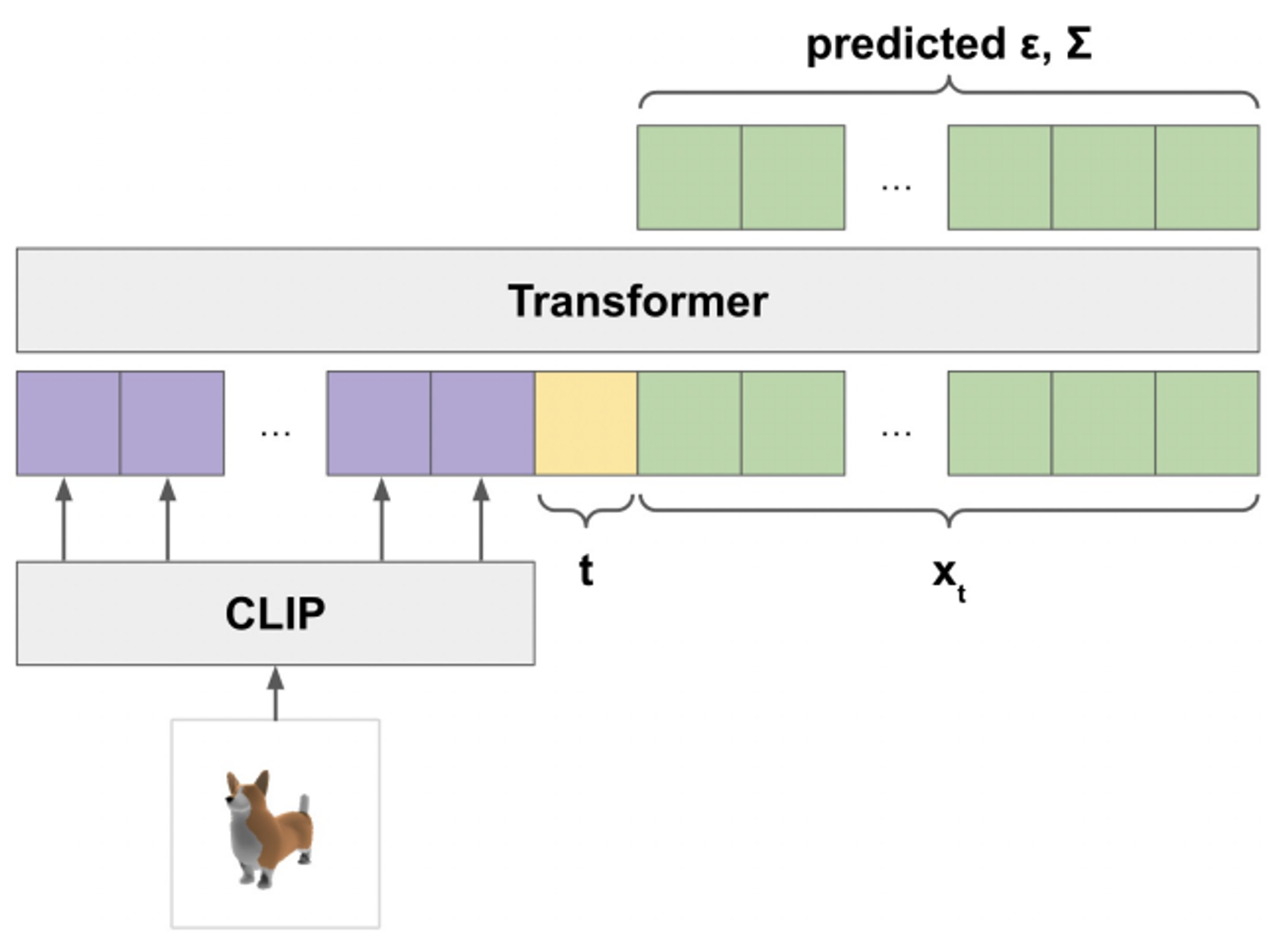
위 사진은 Point-E에 대한 모델의 아키텍처입니다. 정확한 내용은 해당 논문을 통해서 파악하고 해당 논문을 이해하기 위한 부분만 설명해드리겠습니다. GLIDE라는 2D 이미지 생성 모델을 통해서 텍스트에 알맞은 이미지를 생성한 후, CLIP 이미지 임베딩을 통해서 이미지의 피처를 얻습니다. 이후 이 이미지 피처를 256XD로 변환해줍니다. 이때 D는 6으로 (x,y,z), (R,G,B) 값으로 위치와 색깔값입니다. 256XD부분이 그림상에서 보라색 부분에 해당됩니다.
또한 노란색 부분의 timestep값도 MLP를 이용해서 D차원으로 변환해서 넣어줍니다.
마지막으로 초록색 부분은 예측해야되는 값으로 point cloud에서 point의 수인 K개만큼의 D차원 정보가 들어갑니다.
따라서 입력값으로는 (257+K) X D 가 들어가게 되고, 출력값으로는 K X D차원이 들어가게 됩니다.
Appearance Refinement
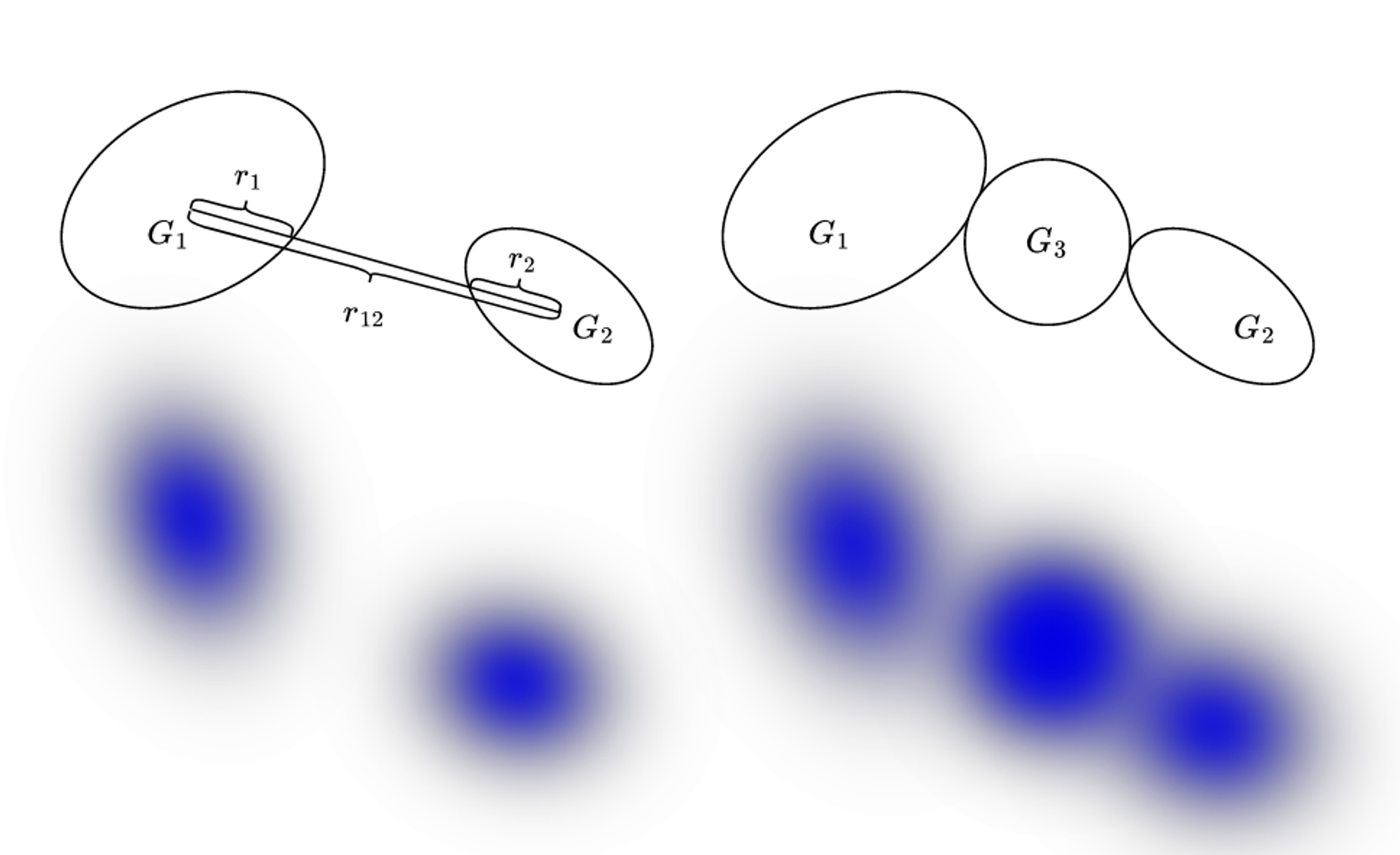
Compactness-based Densification 방법 제안
→ SDS Loss에서 임계값을 설정하는 어려움이 있었습니다. 임계값이 클 경우 외형이 흐릿해지고, 임계값이 작을 경우 큰 기울기에 의해 잘못된 방향으로 유도되어 Gaussian이 과도하게 생성됩니다.
위의 방법을 극복하기 위해서 Compactness-based densification이 제안됐습니다.
- KD-Tree: 각 Gaussain에 대해서 KD-Tree를 사용해서 K개의 가장 가까운 이웃을 선택
- 새로운 Gaussian 추가: 이웃 사이의 거리가 두 Gaussian의 반경 합보다 작은 경우, 그들 사이에 새로운 Gaussian을 추가합니다. 이 새로운 Gaussian의 반경은 두 Gaussian 사이의 남은 거리로 설정됩니다. 위의 사진에서 가 과 의 합보다 작기때문에 새로운 gaussian G3가 추가된 것입니다.
regularize opacity
불필요한 Gaussians를 제거하기 위해, 불투명도(opacity)를 규제하는 Loss를 추가합니다. 이는 Gaussian의 중심과의 거리에 비례하는 가중치를 부여합니다. 그리고 일정 주기마다 opacity가 특정 임계값보다 작은 Gaussians를 제거합니다.
Geometry consistency
refinement과정 동안 Gaussian의 일관성(consistency)을 유지하기 위해 이전 단계에서 얻은 위치에서 크게 벗어난 Gaussian들을 제거합니다.
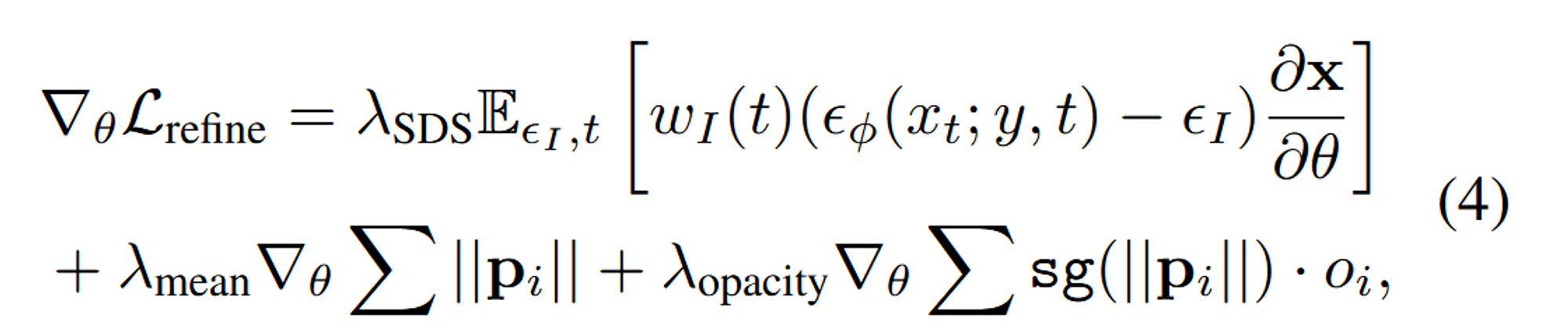
최종적으로 refinement의 Loss는 위와 같습니다.
- SDS: 이전 단계의 SDS Loss처럼 2D SDS Loss가 적용됩니다. 한번 더 적용되는 이유는 세부적인 디테일을 반영하기 위함입니다.
- mean: 모든 Gaussian의 위치 들의 크기를 합한 것입니다. 이 항목은 Gaussian의 위치를 제어하여 불필요한 이동을 방지하고, 위치가 지나치게 멀어지는 것을 막습니다.
- opacity: Gaussian의 불투명도를 조절하여, 너무 흐릿하거나 필요 없는 Gaussian들을 제거하는 데 사용됩니다.
Initialization with Geometry Prior
초기 Point Cloud를 설정하는 값은 결과에 많은 영향을 미칩니다. 따라서 사용자가 입력한 3D Shape을 기반으로도 시작할 수 있도록 하고 있습니다. 혹은 이전까지 설명했던 Point-E를 통해서 시작할 수 있습니다. Point-E의 출력값은 위치와 색깔 정보인데, 여기서 색깔은 실험적으로 랜덤값이 더 적절하다고 밝혔습니다. 추가적으로 rotation matrix는 identity matrix로 설정됩니다.
Experiments
Implementation Details
Stable Diffusion의 step은 100, Dreamfusion에서 사용한 view-dependent prompt 기술 사용합니다.
500 iteration마다 위치 변화율이 =0.02를 넘는 Gaussain을 삭제합니다.
그리고 1000 iteration마다 compactness-based densification를 실행합니다.
또한 200 iteration 마다 =0.05보다 낮은 opacity(불투명도)를 갖는 Gaussian을 삭제합니다.
하이퍼파라미터 값들
- λSDS = 0.1, λ3D = 0.01, λSDS = 0.1, λmean = 1.0 and λopacity = 100.0
Text-to-3D Generation
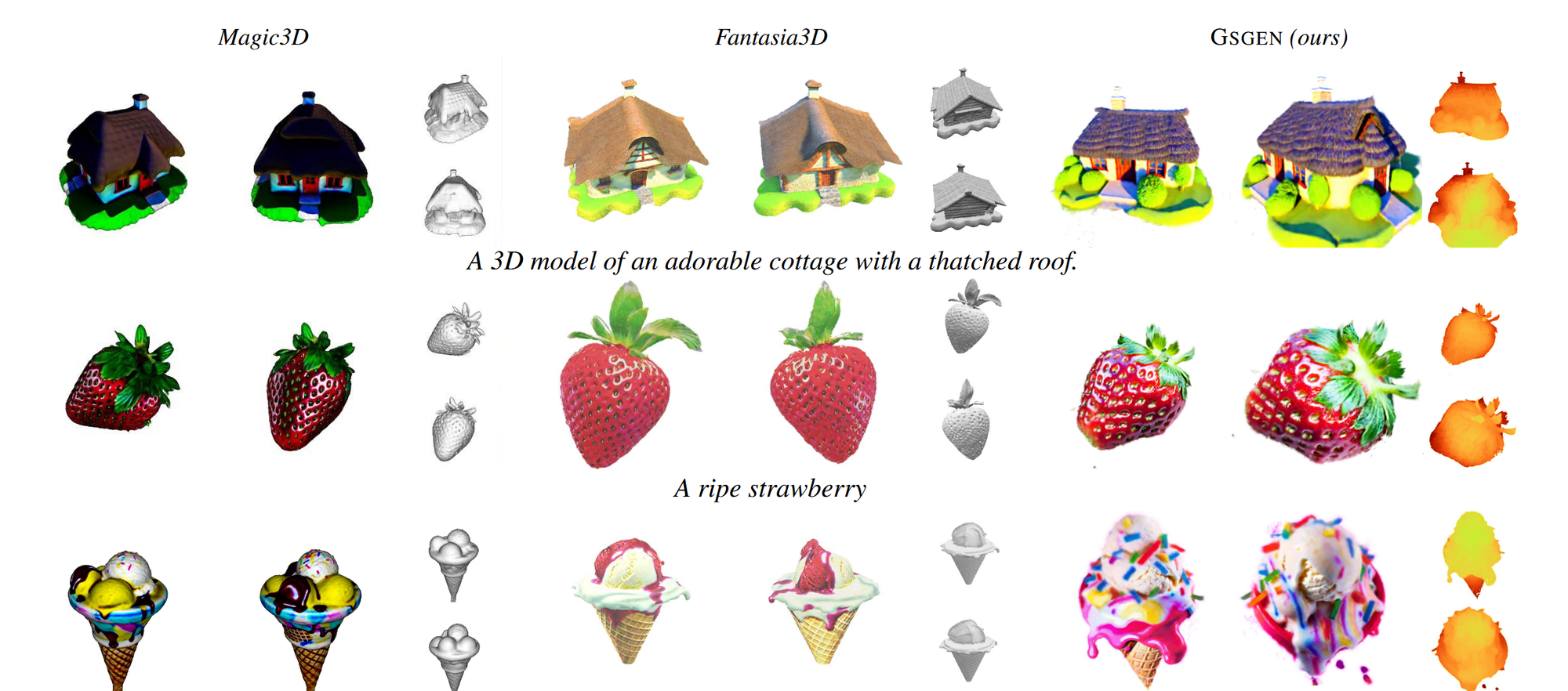
다른 모델들에 비해 외형적으로 더 디테일한 요소들이 반영되었습니다.
Ablation Study

(a): without initialization
- dengenration issue가 발생하는 현상을 볼 수 있습니다. 따라서 Point-E의 중요성을 나타냅니다.
(b): without 3D guidance
- 이부분 역시 3D SDS Loss에 해당하는 Point-E의 중요성을 나타냅니다. 제거했을 때 Janus 현상이 나타나는 것을 알 수 있습니다.
(c): without Coarse Model
- 2번째 단계의 refinement가 필요한 이유를 설명하고 있습니다. 외형적으로 더 디테일한 요소들을 추가할 수 있습니다.
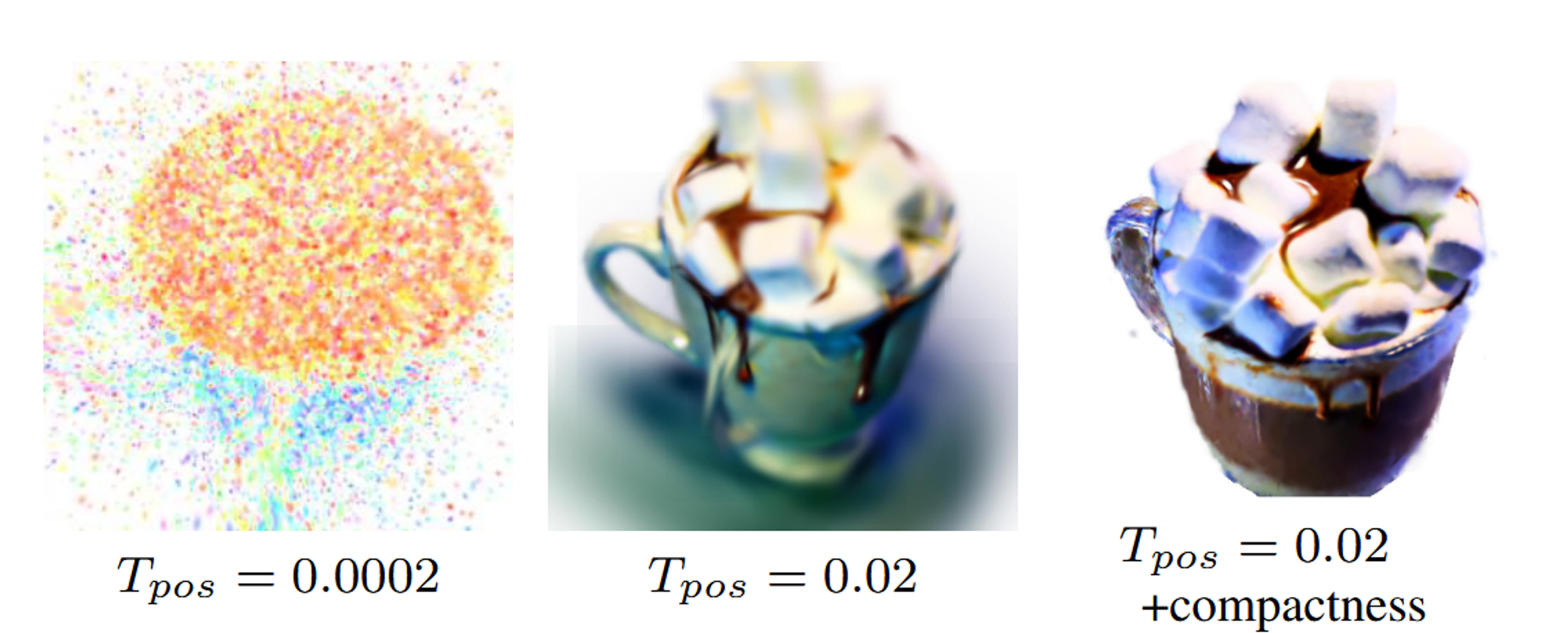
변화량이 보다 클 경우 Gaussian을 제거하는데 이때 임계값을 변경하면서 결과를 비교했습니다. 임계값이 너무 작을경우 unstable gradient 현상(왼쪽 그림), 임계값이 너무 크면 over-smoothed 현상이 나타난다고 합니다. 또한 compactness기술을 추가함으로서 SDS guidance기반 학습이 더 잘 진행됨을 나타냅니다.
Limitations and Conclusion
Limitations
복잡한 Text가 들어올 경우, Point-E와 Stable Diffusion의 CLIP Text Encoder의 능력 부족으로 좋지 않은 결과가 나옵니다. 또한 textual prompt가 과도하게 guidance diffusion모델에 biased되는 현상도 나타난다고 합니다.
Conclusion
3D Gaussian을 이용해서 2Stage학습을 진행했습니다. geometry optimization단계에서는 rough shpae을 생성하과, appearance refinement 단계에서는 Gaussian들이 디테일을 잘 표현하도록 변형됐습니다.
