Paint-it: Text-to-Texture Synthesis via Deep Convolutional Texture Map Optimization and Physically-Based Rendering 논문 리뷰
프로젝트 페이지
논문 링크
Abstract

이 논문은 Paint-it이라는 새로운 텍스트 기반의 고품질 texture map 생성 방법을 소개합니다.
SDS Loss를 픽셀에 적용하는 이전 방법과 달리, Deep Convolutional Physically-Based Rendering(DC-PBR) 방식으로 적용하는 방법을 제안했습니다. 15분안에 Text 기반의 좋은 Texture를 생성할 수 있습니다.
Introduction
현실적인 3D Asset을 생성하는건 많은 분야에서 중요한 요소로 작용됩니다. 사람이 실제로 3D Asset에 painting을 하는 작업은 많은 시간과 노력이 소모됩니다.
이러한 부담을 덜어주고자 3D Asset을 생성하는 많은 연구들이 나왔습니다. 하지만 여전히 만족스럽지 않은 결과를 내고 있습니다. 기존 방법들은 Texture map을 직접 생성하는 대신 이미지로부터 색상을 추출해 Mesh에 back-projection합니다. 이 과정에서 재질 특성이나 복잡한 반사를 제대로 Modeling하지 못해 품질이 떨어집니다.
Paint-it은 Texture map을 optimization하는 과정에서 pixel 기반 파라미터화 대신, DC-PBR(Deep Convolutional Physically-Based Rendering) 파라미터화를 도입합니다. DC-PBR은 Physically-Based Rendering(PBR) Texture map을 convolution-based neural kernels로 재파라미터화하여, 높은 주파수 노이즈 신호를 필터링하는 역할을 합니다. 이로 인해 더 현실감 있는 텍스처 맵을 생성할 수 있습니다. DC-PBR은 분리된 Texture map(diffuse map, roughness, metalness map, normal map)을 재파라미터화하여, bidirectional reflectance distribution function(BRDF)와 같은 물리적 특성을 시뮬레이션할 수 있습니다
이논문이 기여한점은 아래와 같습니다.
- 텍스트 기반 PBR texture map을 만들어서 test-time application을 도와줍니다.
- pixel 기반의 파라미터화 대신 DC-PBR이 SDS Loss에 적절하다는 것을 발견했습니다.
Related Work
Text-driven 3D Asset Generation
text와 3D asset 페어의 많은 데이터가 부족해서 3D asset을 2D로 렌더링 한 후 2D 이미지 기반 학습을 진행했습니다. CLIP과 text-to-image diffusion 모델이 사용됐습니다.
이후 다시 3D asset으로 변형하기 위해서 Volume-based 방법과 mesh-based 방법을 사용했습니다. Volume-based 방법은 3D point에 대해서 occupancy나 SDF같은 방법들을 기반으로 최적화합니다. Mesh-based방법은 explicit mesh와 vertex texutre나 texture map을 이용합니다. Mesh를 이용하는 방법이 더 빠르고 효율적입니다. 또한 그래픽스와의 호환도 더 좋고, texture 변환이나 애니메이션도에도 더 적절합니다. 이에 Volume기반의 방법으로 형성하더라도 이를 다시 Mesh로 변환하는 이유입니다.
이에 Paint-it에서는 mesh 기반, 특히 Texutre map synthesis에 집중해서 연구를 진행했습니다.
Text-driven Texture Map Synthesis
Texture map이 그래픽스 파이프라인에서 가장 많이 사용되는 방법이지만, 높은 퀄리티의 연구들은 별로 없습니다.
Text2Tex, TEXture, Latent-paint, TexFusion이 높은 퀄리티의 Texture map을 연구한 논문들입니다.
특히 Fantasia3D 연구는 PBR matrerial을 이용했다는 점에서 Paint-it과 비슷하지만, Point와 Mesh라는 차별점이 존재합니다.
Paint-it: Text-Driven PBR Texture Synthesis via Neural Re-parameterized Optimization
Preliminary: Score-Distillation Sampling
3D Model을 직접적으로 생성하기 보다는, 렌더링된 이미지를 Diffusion 모델을 이용해서 학습하는 방법으로 진행됩니다. 이때 장면은 differentiable image parameterization (DIP) θ로 표현됩니다. 이미지는 카메라 메트릭스와 transformation function g를 통해서 나타낼 수 있습니다.
Dreamfusion에서는 Imagen 모델을 이용해서 위의 방법을 성공적으로 수행했습니다. score estimation function인 (: noise image, y: text embedding, t: timestep)를 기반으로 학습을 진행합니다.
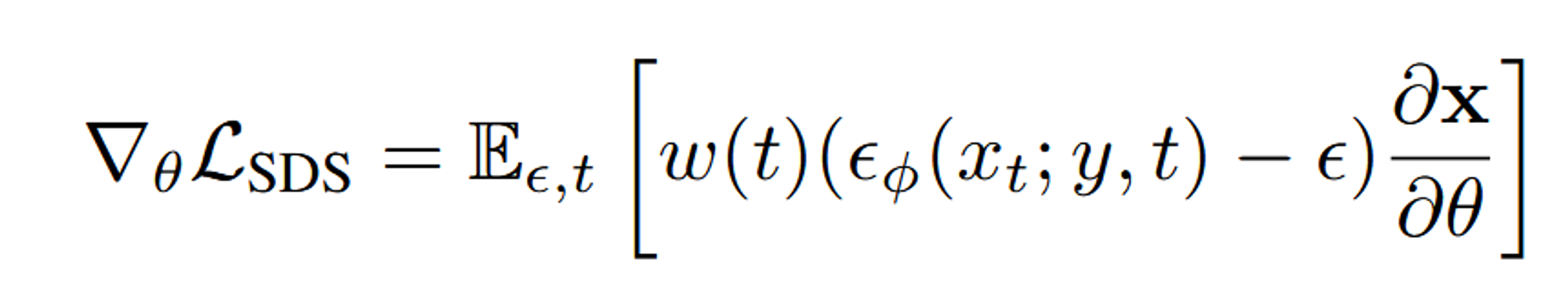
ε: Gaussian noise, w(t): weighting function
SDS를 통해서 text와 3D asset 페어가 많이 존재하지 않더라도, texture map을 학습시킬 수 있습니다.
Goal of Paint-it
입력값으로 Texture가 없는 3D Mesh(M)와 텍스트 설명(y)이 들어가면, 텍스트 설명에 부합한 텍스처가 적용된 3D Mesh를 생성하는 것을 목표로 하고 있습니다. 구체적으로 설명하면 texture는 PBR texture map이고 자세한 설명은 아래와 같습니다.
- Diffuse Map (): Mesh의 기본 색상이나 질감을 나타냅니다.
- Roughness & Metalness Map (): 표면의 거칠기와 금속성을 나타냅니다. 이 Map은 물체가 어떻게 빛을 반사하는지를 정의합니다.
- Detail Surface Normal Map (): 표면의 미세한 굴곡과 세부적인 질감을 표현합니다. 이 Map은 표면이 실제로는 평평하지 않고, 작은 패턴이나 텍스처가 있는 것처럼 보이게 합니다.
DC-PBR: Deep Convolutional PBR Texture Map Re-parameterization
random으로 initialized된 U-net 모델()을 이용해서 random sampled된 code z를 기반으로 texture들을 예측합니다. 이때 z는 HxWx3차원입니다. H와 W는 각각 texture map의 높이와 너비이고 z값은 최적화 과정동안 고정되어 있습니다.
→ , ,
위의 식을 토대로 U-net 모델은 입력값은 3차원, 출력값은 8차원인 것을 알 수 있습니다.
Text-driven DC-PBR Optimization
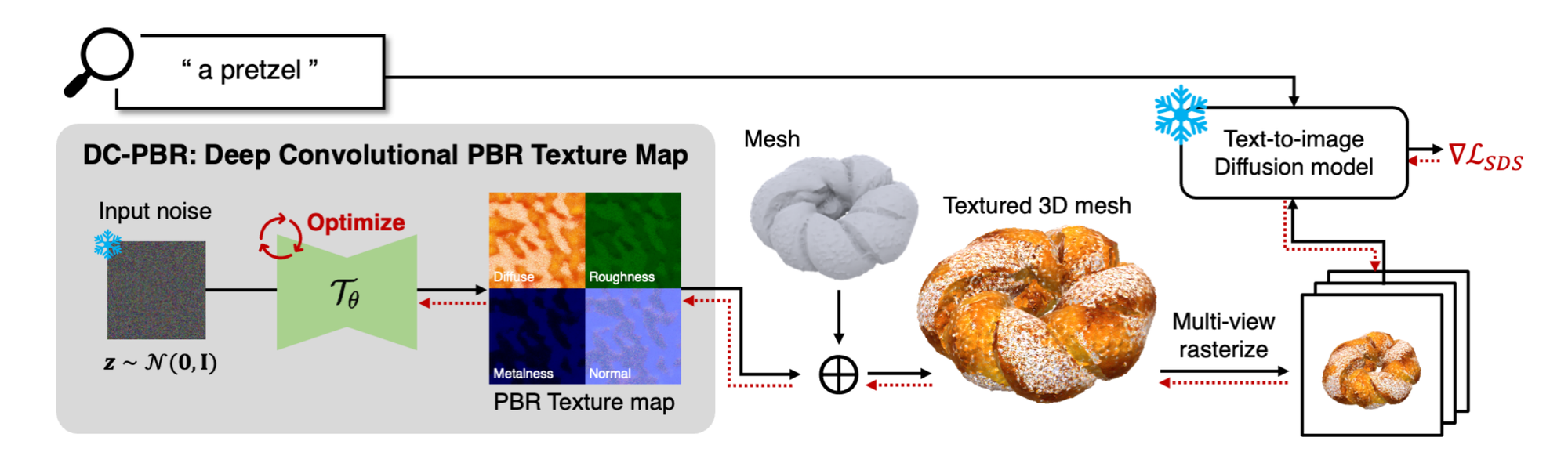
Overall Pipeline
- initialize: 고정된 노이즈
z를 DC-PBR에 입력하여 Kdθ (diffuse 맵), Krmθ (roughness 및 metalness 맵), 그리고 Knθ (normal 맵)를 예측합니다. - rendering: 얻어진 Texture 맵을 사용해 주어진 Mesh를 텍스처링한 후, 다중 뷰 이미지로 렌더링합니다.
- Update: 텍스트로 가이드된 확산 모델을 사용해
∇LSDS에 따라 신경망 파라미터θ를 업데이트합니다.
Rendering Mesh with PBR Texture Maps
생성된 Texture map을 기반으로 Mesh를 텍스처링하고, 이를 Rendering 해서 값을 업데이트 합니다.
Specularity 계산
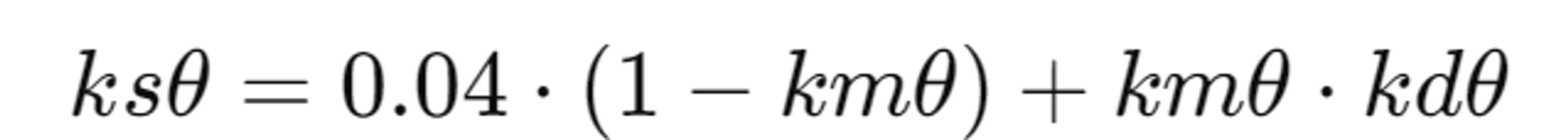
Specularity는 물체의 표면에서 반사되는 정도를 나타내며 아래의 렌더링 방정식에서 사용됩니다.
렌더링된 점 p의 색상 계산
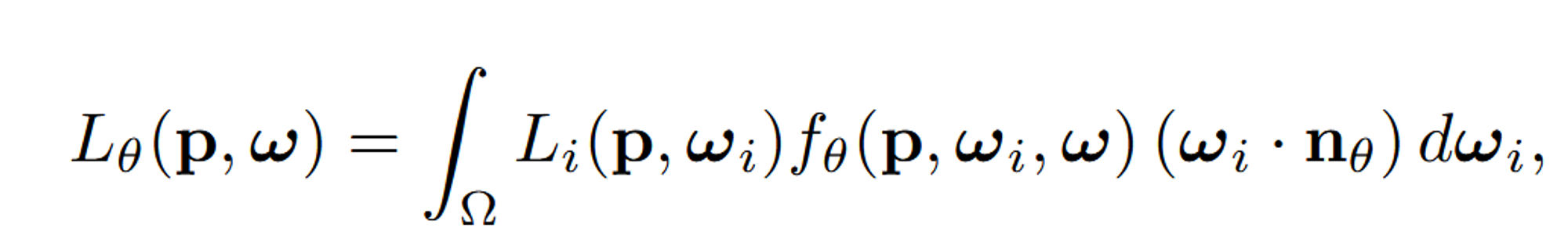
p: 하나의 점을 나타내고, w: view direction를 나타냅니다.
fθ(p, ωi, ω): bidirectional reflectance distribution function (BRDF)
위의 수식은 Cook-Torrance을 사용해서 아래와 같이 다시 세분화할 수 있습니다.
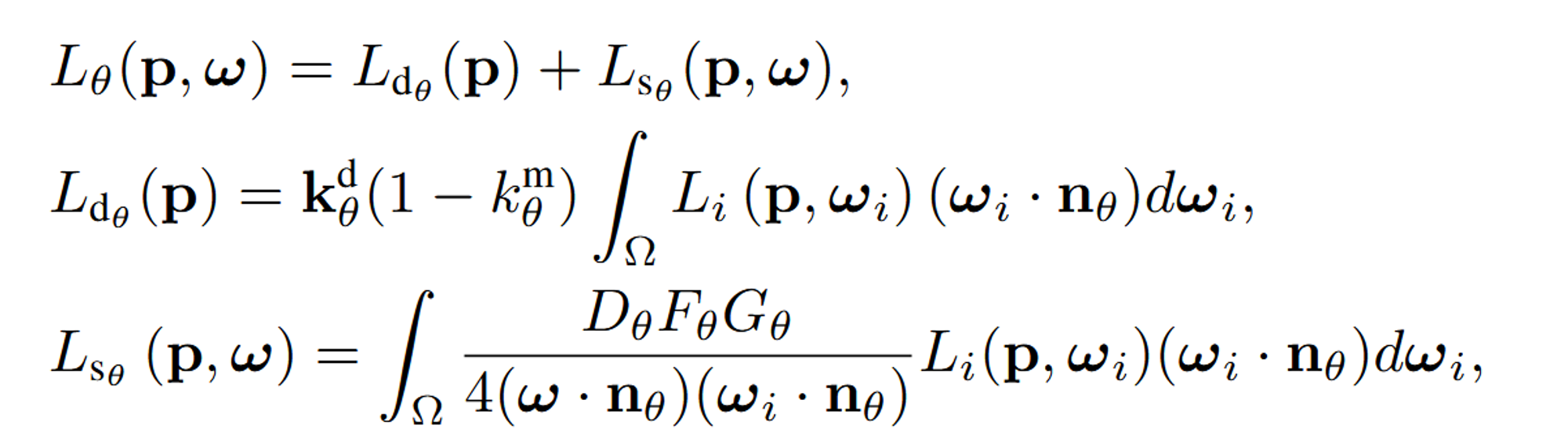
결론적으로 위의 과정은 생성된 texture map을 3d 모델에 mapping해서 최종적으로 렌더링된 이미지를 얻는 과정입니다. 즉 Mesh 이미지()를 생성하는 데 사용됩니다. (은 NVDiffRast를 이용해서 계산됩니다.)
Diffusion-guided DC-PBR Optimization
초기 texture map은 노이즈가 많은 형태이지만, 학습을 진행하면서 점차 적절한 texture map으로 변할 것입니다.
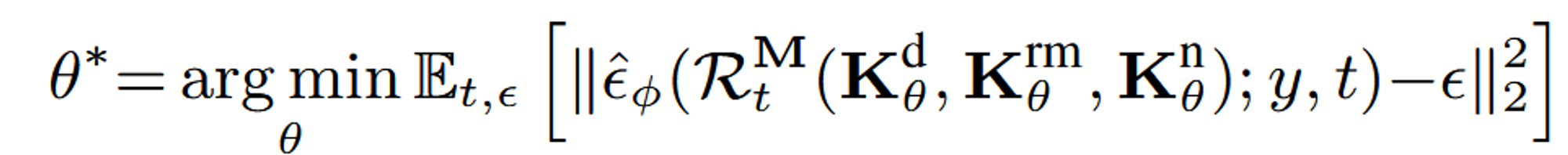
학습을 할 때 사용하는 방법은 위에서도 말했지만, SDS Loss를 이용합니다.
t-dependent weighting function m(t)를 간략화하기 위해서 생략했습니다.
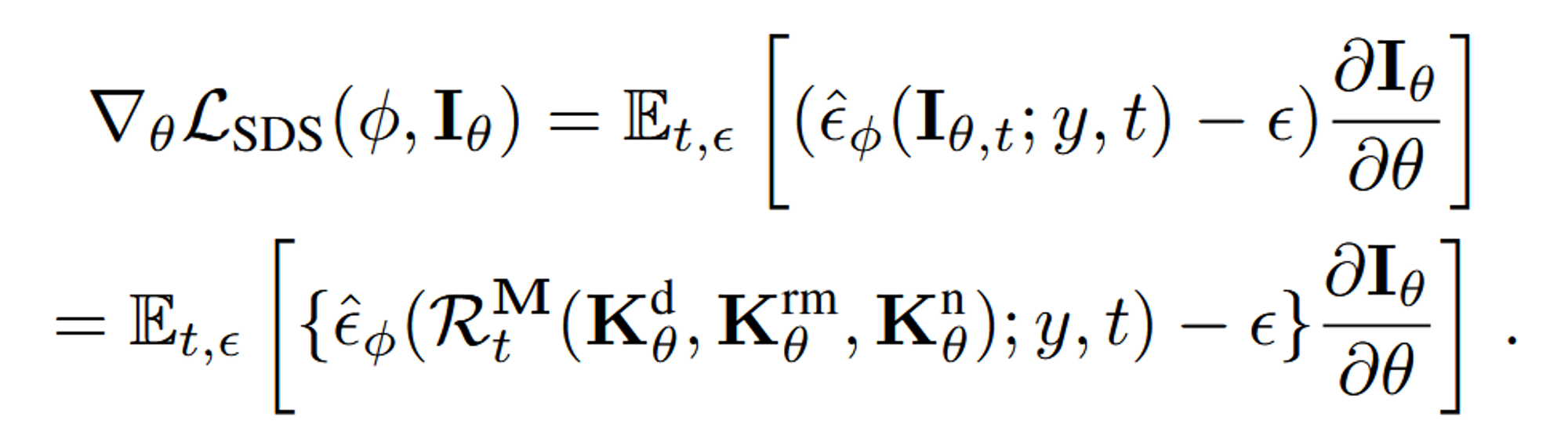
Analysis: Effect of the Deep Convolutional Re-parameterization for PBR Texture Maps
Analysis of Fitting Behavior
해당 부분에서는 픽셀기반과 Nueral Network기반의 SDS Loss를 비교하면서 어떤 것을 사용할지 비교했습니다.
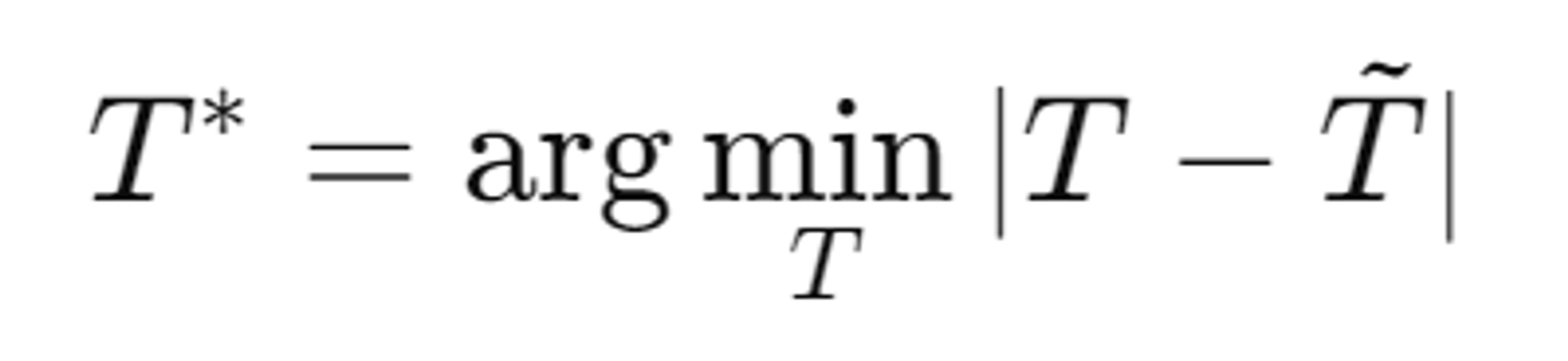
- 픽셀기반 최적화
- Texture Map T와 Ground Truth T̃ 사이의 차이를 최소화하는 것입니다.
- 픽셀 값 자체를 직접 업데이트합니다
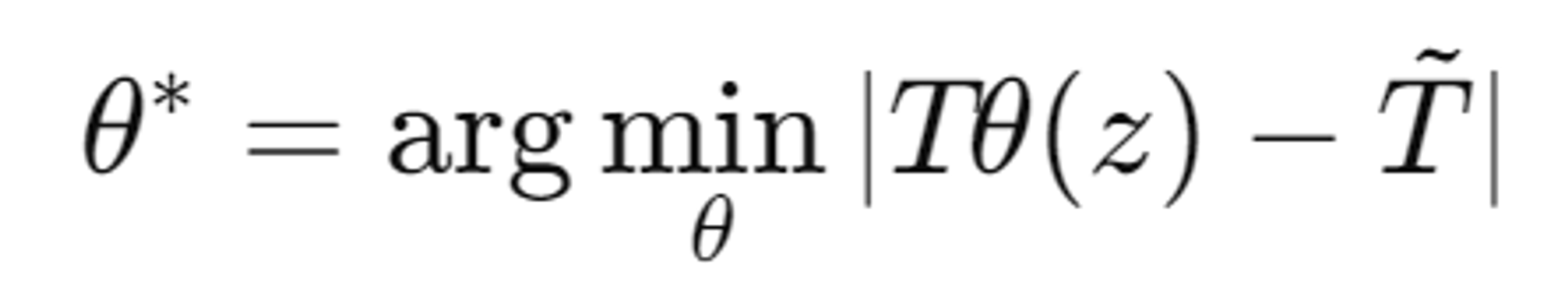
- Nueral Network기반 최적화
- Texture MapT는 신경망 로 표현되며, θ는 네트워크의 파라미터, z는 고정된 노이즈
- 픽셀 대신 Neural Network의 파라미터를 업데이트합니다
Frequency Band Energy Analysis
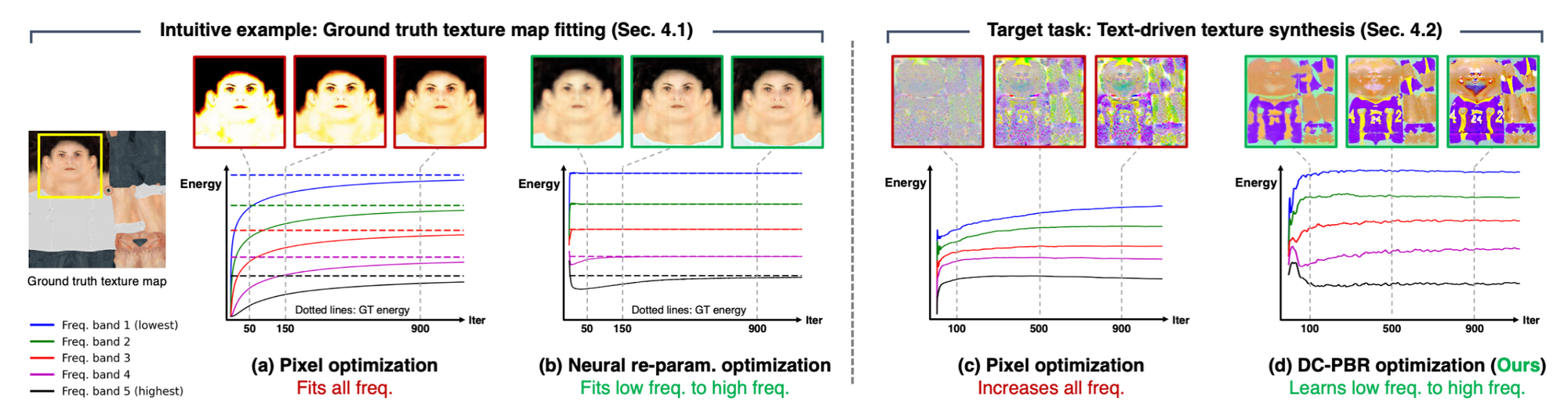
위의 그림은 픽셀기반 최적화와 neural 파라미터 기반 최적화의 차이를 보여줍니다.
픽셀기반 최적화시 저주파~고주파까지 모든 주파수 대역을 동시에 맞추려고합니다. 이는 전체적인 콘텐츠와 세부 사항을 동시에 학습하게 되어 노이즈가 포함된 신호를 잘못 학습할 위험이 있습니다.
neural 파라미터 기반 최적화시 저주파 성분을 먼저 학습하고, 고주파 성분을 나중에 학습합니다. 이는 네트워크가 먼저 이미지의 전체적인 내용(저주파)에 집중하고, 이후 세부 사항(고주파)을 맞춰가는 방식입니다.
Analysis of Optimization with the SDS Loss
SDS Loss는 다양한 요소들로 인해 매우 불규칙한 그래디언트를 생성합니다. 따라서, 최적화 과정에서 한 번에 많은 고주파 노이즈를 처리해야 하므로 최적화가 더 어렵고 불안정할 수 있습니다.
이전 단락의 설명과 마찬가지로 픽셀 기반 최적화를 했을 때는 모든 주파수 대역을 동시에 학습하기 때문에 노이즈가 최적화되어 결과의 품질이 저하됩니다.
따라서 DC-PBR 기반의 netwokr 파라미터를 최적화하면서 학습을 진행함으로서 저주파대역을 먼저 학습하고 고주파 대역을 점진적으로 학습하도록 설정했습니다.
Experiment
추후에 업데이트하겠습니다.
