Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation [2025 arXiv]

Hunyuan3D 2.0은 크게 3가지 모델로 분류됩니다.
Hunyuan3D-DiT: shape generation modelHunyuan3D-paint: texture synthesis modelHunyuan3D-Studio: user-friendly production platform
각 모델은 어떻게 구성되어 있고, 어떻게 이렇게 좋은 퀄리티의 결과를 생성할 수 있는지 알아보도록 하겠습니다.
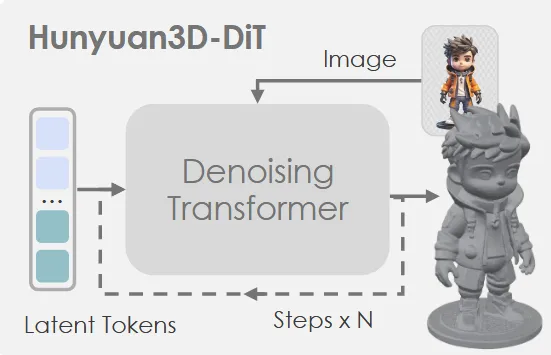
Generative 3D Shape Generation(Hunyuan3D-DiT)
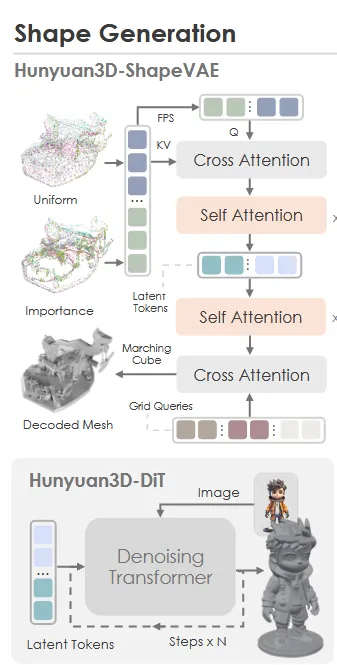
위의 그림과 같이 3D asset을 latent space로 보내는 Hunyuan3D-ShapeVAE와 flow-based diffusion model인 Hunyuan3D-DiT로 이루어져 있습니다. 각각의 경우가 어떻게 동작하는지 하나씩 살펴보도록 하겠습니다.
Hunyuan3D-ShapeVAE
요약: 3D shape를 압축된 latent space에 인코딩한 뒤, SDF로 디코딩하여 mesh를 복원
- Point 3D 좌표 + normal 벡터 → 접에 대한 SDF 예측 → marching cubes로 mesh 생성
Importance Sampled Point-Query Encoder
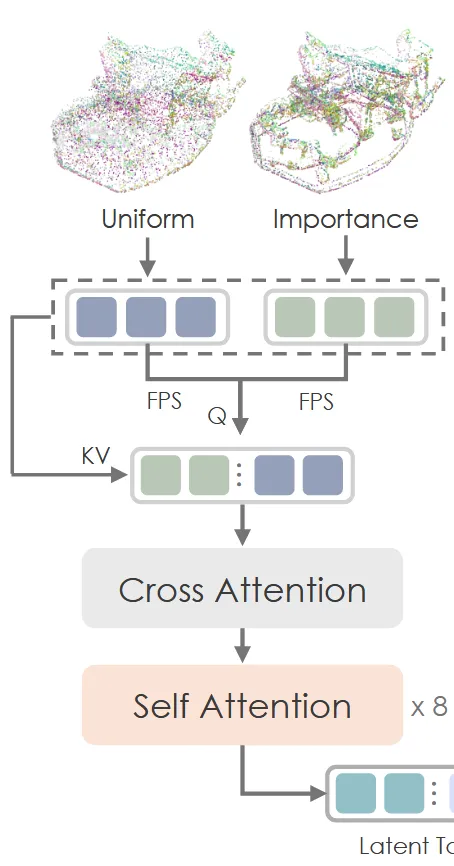
Encoder()는 3D shape에서 대표적인 feature를 뽑는 것을 목표로 합니다. 처음으로 attetnion 기반 encoder를 설계 해서 동일하게 point cloud를 뽑도록 했습니다. 하지만 이는 물체의 복잡한 요소를 뽑기에는 부족했습니다.
저자들은 importance sampling 방법을 통해서 uniform sampling이 아니라 중요한 부분(edge, corner)을 더 많이 샘플링 하는 방식을 택했습니다. 우선 mesh로부터 uniform sample 방식으로 point clouds 를 추출하고, importance sample point cloud 를 추출합니다.
Farthest Point Sampling (FPS)를 에 각각 적용해서 uniform point query 와 importance point query 를 얻습니다. Final point cloud P는 초기 와 를 concate, point query Q는 와 를 concate해서 얻습니다. P와 Q에 Fourier positional encoding를 적용해 마지막 로 바뀝니다.
이후 3dshape2vecset에서 사용했던 방식처럼 P와 Q를 cross attention와 self attention를 통과시켜 hidden shape representation 를 얻습니다. 이렇게 얻은 에 추가적인 linear projection을 통해서 mean과 variance(Autoencoder니까)를 예측합니다.
Decoder
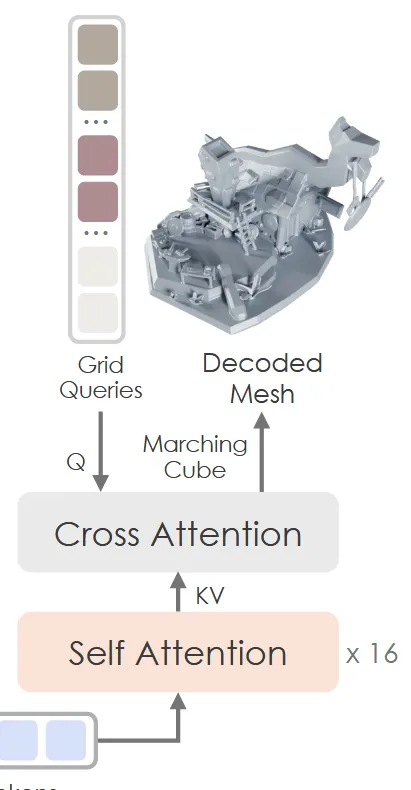
이전 결과로 나온 에 대해 transformer를 사용하기 위해 차원을 맞추는 projection layer를 이용해서 차원을 → d로 변환합니다. 이후 16개의 Self attention을 통과해 hidden embedding을 얻습니다. Cross Attention에서 queries로 사용할 는 모든 격자점이므로 차원이 HXWXDX3입니다. Self attention의 결과와 를 cross attention을 통해 나온 결과 는 추가적인 linear projection으로 SDF 를 얻고, 이는 marching cubes 알고리즘을 통해서 mesh를 생성하게 됩니다.
Training Strategy & Implementation
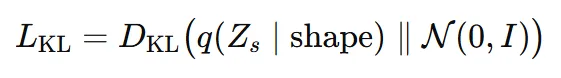
Reconstruction loss: 예측한 SDF 와 ground truth SDF(x)와 MSE loss
KL-divergence loss: Encoder의 결과 임베딩 벡터의 평균과 분산을 표준정규분포에 가깝게 만든다.
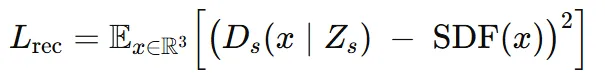
2개의 loss로 이루어진 전체 loss는 위와 같습니다.
추가적으로 multi-resolution strategy로 attention의 token 차원을 미리 정해진 여러개로 정합니다. 가장 긴 길이는 3072로 정했습니다.
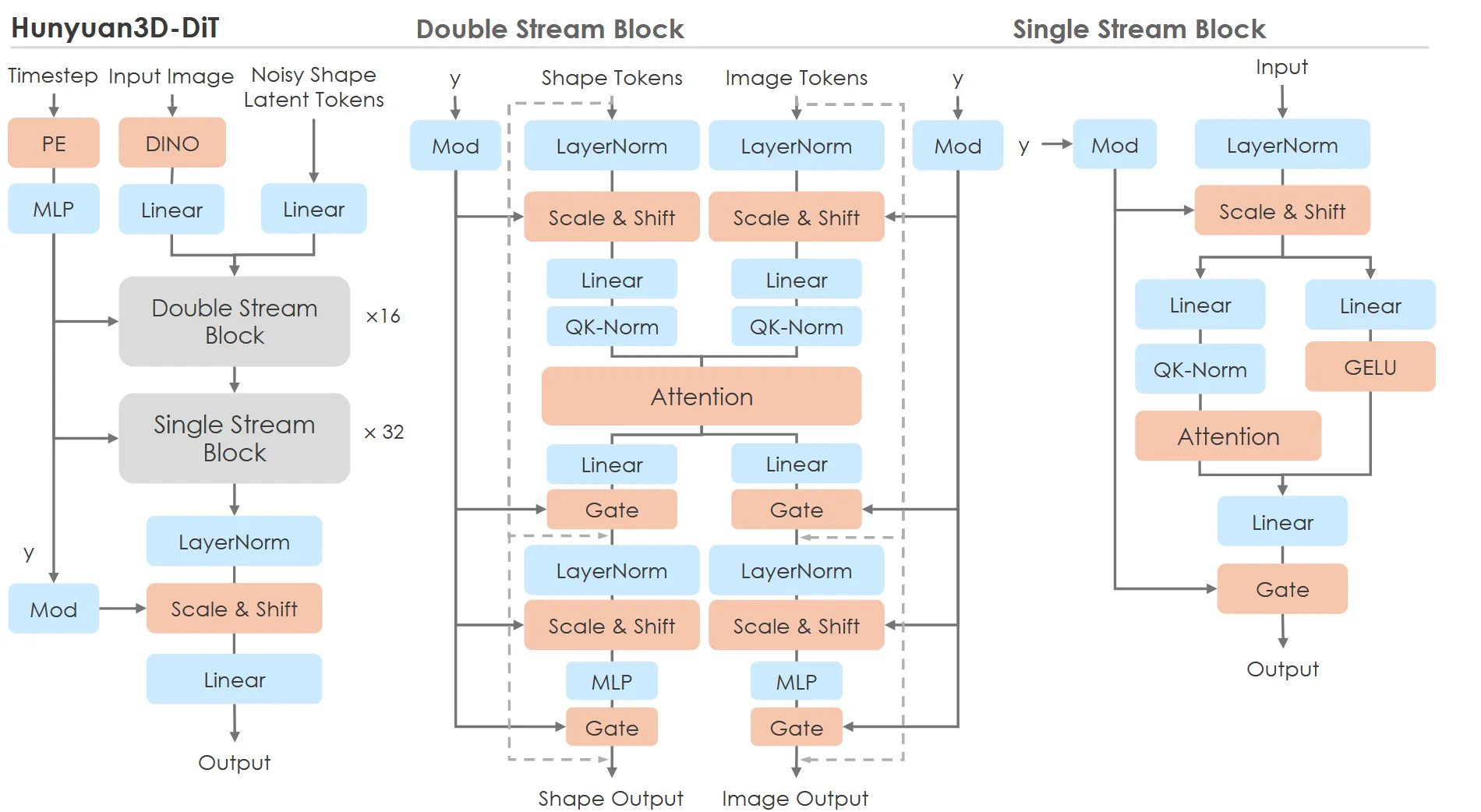
Hunyuan3D-DiT
Network Structure
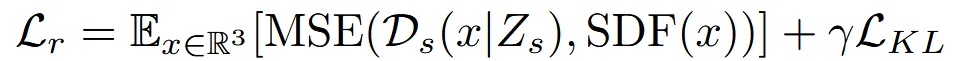
FLUX 모델에서 영감을 받아 dual- 과 single-stream network 구조를 위와 같이 구성했습니다.
Double Stream Block :latent token과 condition token이 QKV와 MLP에서 분리돼서 동작합니다.
Single Stream Block: latent token과 condition token이 concate돼서 진행됩니다.
Timestep Embedding: Diffusion의 현재 timestep을 Modulation 모듈에만 주입
- 여기에서 γ,β파라미터를 타임스텝 임베딩에서 뽑아온다.
positional embedding: 생략
Condition Injection
Image Encoder: DINOv2 Gaint
Image Size: 518 x 518
Background: Remove & White
Training & Inference
이전에도 언급한 것처럼 flow matching 방식을 적용했습니다. Conditional optimal transport schedule과 함께 affine path를 사용해서 예측을 진행했습니다.
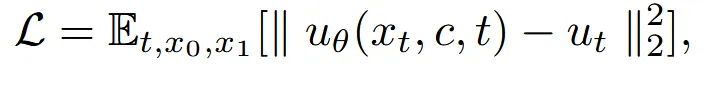
따라서 위와 같이 condition(c)와 함께 으로 예측하게 됩니다. 추론시 초기에는 Gaussian noise에서 시작하다가, 1차 ODE solver를 이용해서 데이터를 예측하도록 진행합니다.
Generative Texture Map Synthesis

Texture가 없는 3D mesh와 image prompt만으로 고해상도 seamless UV texture map을 만드는 과정입니다.
Pre-processing
Image Delighting Module
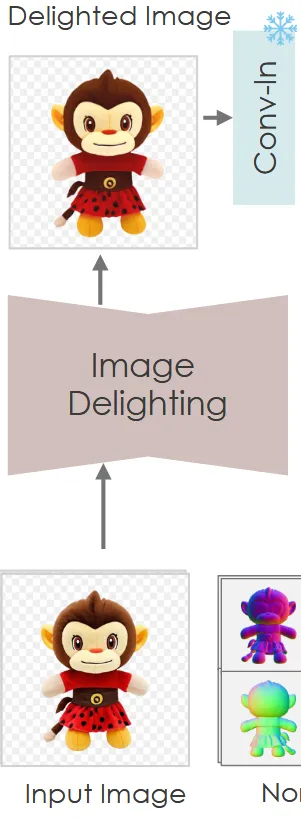
입력으로 들어오는 이미지는 다양한 조명과 그림자를 갖고 있습니다. 이를 바로 multi-view generation framework에 사용하게 된다면 illuminiation과 shadow 정보가 texture map에 전달될 것 입니다. 따라서 모든 이미지에 Instructpix2pix에서 사용한 image-to-image 방법을 사용해서 delighting을 적용했습니다.
많은 3D 데이터셋에 대해서 랜덤한 조명을 갖는 HDRI enviromental map과 균일한 white light를 페어 데이터로 학습을 진행했습니다. 이렇게 학습된 값을 통해서 Delighting 결과로 균일한 white light 이미지를 얻을 수 있게 됩니다.
View Selection Strategy
Texture를 입히기 위한 전략은 한번에 많은 영역을 칠함으로써 최소한의 viewpoint를 사용해서 cost를 줄이는 것입니다. 경험적으로 view는 8~12개를 선택하도록 합니다.
초기에 4개(정면, 뒤, 오른쪽, 왼쪽) orthogonal viewpoint를 이용해서 많은 영역을 칠합니다. 다음 view를 고르기 위해서는 greedy search approach를 사용합니다.
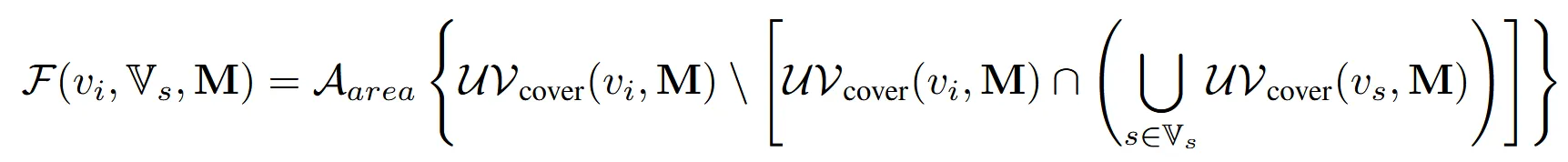
- 뷰포인트 v에서 메쉬 M를 렌더링했을 때
- UV 공간 상에서 보이는(투영된) 텍셀(texel)들의 집합
- 이미 선택된 뷰들 이 커버한 텍셀들의 합집합
- 차집합
- 새로운 후보 가 아직 커버하지 않은(unseen) 텍셀들만 골라냄
- 주어진 텍셀 집합의 면적(pixel 수 또는 실제 UV 면적) 계산
한줄 요약: 후보 $v_i$가 추가되었을 때 얻어지는 새로운 UV 영역 면적
이전 한줄요약과 같은데 이를 알고리즘에 대해서 정리한 것입니다. 정리하자면 초기에 4개의 뷰를 정하고 최대 뷰는 12개입니다. 이때 면적을 계산해서 가장 많은 면적을 갖고 있는 뷰를 선택하도록 합니다. 어떤 뷰가 제일 많은지 모르기 때문에 greedy search approach 방식으로 정합니다. 이때 완전한 랜덤뷰로부터 greedy하게 찾는게 아니라 정해진 reference viewpoint 안에서 랜덤하게 greedy 방식으로 선택합니다.
Hunyuan3D-Paint
Double-stream Image Conditioning Reference-Net

이미지 정보를 반영하기 위해서 reference-net conditioning 방식을 사용했습니다. 원본 이미지에 노이즈를 추가할 경우 디테일이 손상될 수 있기 때문에, VAE로부터 얻은 feature를 바로 사용합니다. 원본 이미지를 사용했기 때문에 reference branch의 timestep은 0입니다.
3D 렌더링 데이터셋에 style bias를 피하기 위해서 shared-weight reference net을 사용했습니다. 그 결과 이미지가 soft regularization되고, 실제 사진 스타일로부터 크게 벗어나지 않도록 합니다.
정리하자면 이미지를 SD2.1 VAE로 이미지 임베딩을 얻고, 이를 이용해서 timestep 0일 때의 Reference Branch(frozen SD2.1)의 여러 feature를 얻습니다. 이 feature들을 Generation branch(trainable SD2.1)에 넣으면서 이미지 condition 정보가 반영됩니다.
Multi-task Attention Mechanism

Reference Attention: 이미지 prompt 정보를 반영
Multiview Attention: 다른 뷰의 정보를 카메라 임베딩과 같이 반영
위에서 설명한 Generation과 Reference Branch에 대해서 조금 더 자세히 그림과 함께 설명을 드리겠습니다. 이전에 말한 것처럼 Reference Branch의 모든 요소들은 frozen을 시켰습니다.
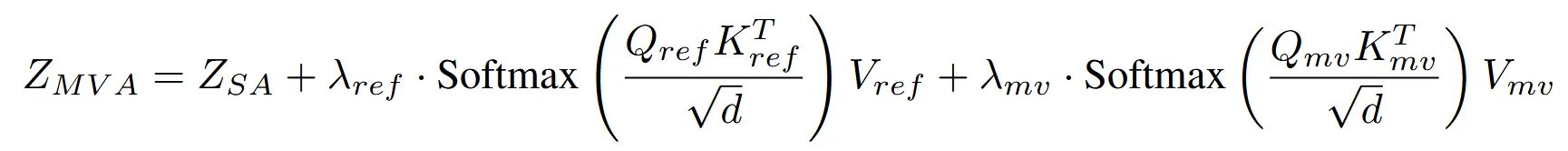
수식적으로는 위와 같습니다. 3가지 attention block에 대해서 기존의 self-attention 값에 각 condition의 계수를 곱해서 최종적인 를 생성합니다.
Geometry and View Conditioning
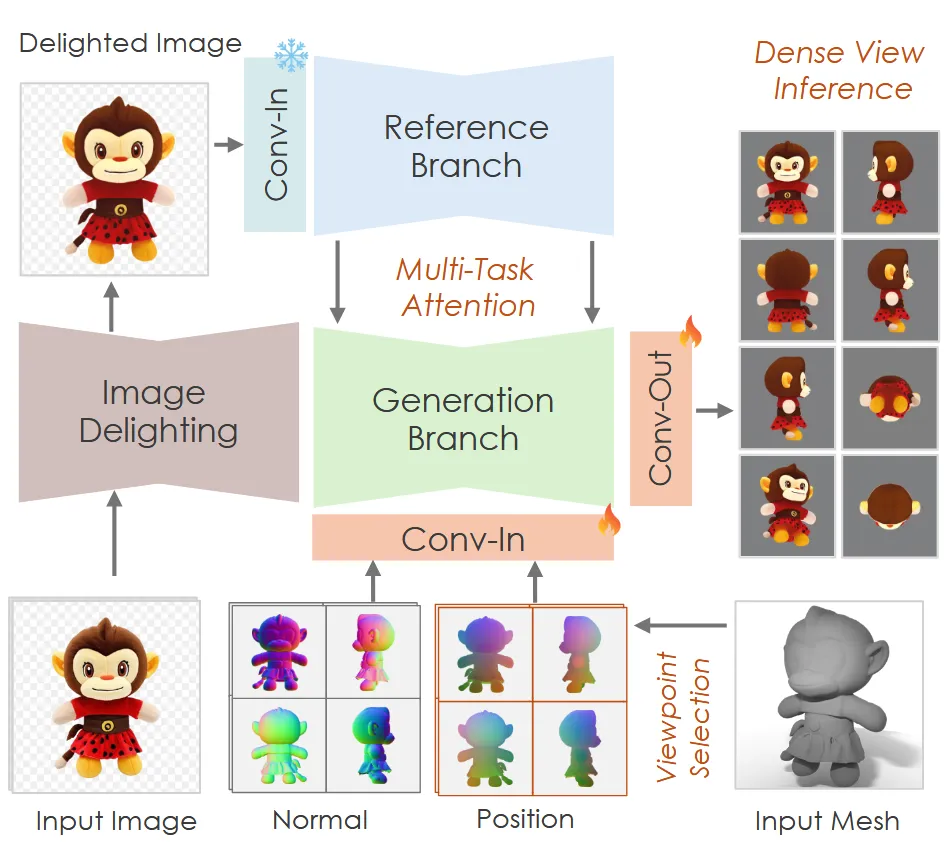
Texture map을 생성할 때 3D Mesh의 Normal과 Position(CCM)을 알면 픽셀 단위로 어떻게 색칠해야 될지 모델이 더 명확히 예측할 수 있습니다.
Canonical Normal map: 법선 벡터를 RGB 이미지 형태로 렌더링 한 것
Canonical Coordinate Map(CCM): 3D 좌표를 RGB 채널로 인코딩한 맵
Normal Map과 CCM을 VAE에 입력해서 feature를 얻고, 2가지 feature는 입력 latent noise와 concate해서 들어가게 됩니다.
추가적으로 카메라 정보를 넣는 Camera Embedding도 학습을 통해서 매 diffusion step의 Modulation layer에 더해집니다. 미리 정의된 N개의 카메라에 대해서 고유한 정수 ID를 부여해서, 이 ID를 임베딩 값으로 변환합니다.
Texture Baking
Dense-view inference
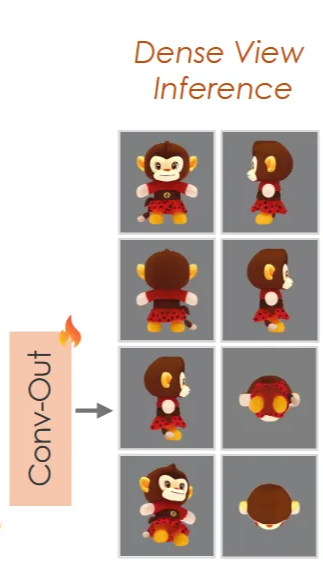
일반적으로 첫번째 단계에서 multi-view generation을 통해서 texture를 생성하고, 보이지 않는 부분에서 채워지지 않는 영역(self-occlusion)은 inpainting을 통해서 보완합니다. 하지만 Hunyuan3D에서는 view dropout strategy를 통해서 multi-view generation만으로도 self-occlusion 현상을 예방할 수 있습니다.
view dropout strategy는 44개의 미리 정해진 viewpoints에서 배치별로 랜덤하게 6개를 선택해서 diffusion backbone network를 학습합니다. 결과적으로 추론할 때 어떤 시점에 대해서도 dense한 이미지를 생성할 수 있어 self-occlusion을 예방할 수 있게 됩니다.
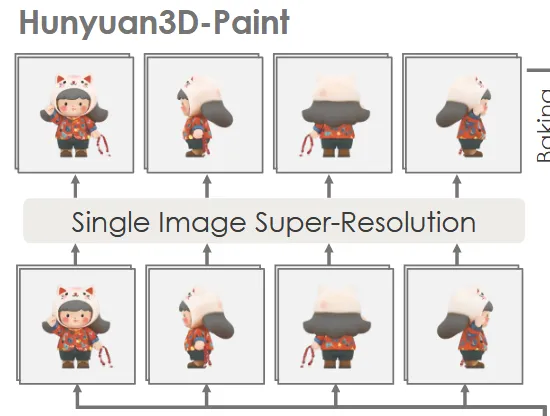
Single Image Super-resolution

Esrgan 방식을 통해서 single-image super-resolution을 적용합니다. 이를 통해서 texture의 quality를 높이게 됩니다.
Texture Inpainting
Dense-view inference를 진행했어도 여전히 UV texutre map에 색칠 되지 않은 부분이 있을 수 있습니다. 따라서 inpainting을 추가적으로 진행합니다.
우선 이미지 채워진 UV map의 texture를 mesh의 vertex에 projection합니다. 그다음에 채워지지 않은 texel은 인접한 vertex의 texture에 대해서 거리 역수 가중치로 합산해서 값을 채웁니다.
Implementation Details
Multi view generation framework: ZSNR checkpoint SD 2 v-model
T2I model: ControlNet & IP-Adapter를 적용해서 텍스트나 이미지로부터 뷰별 텍스처 이미지 생성
Experiments




