IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models [2023 arXiv]
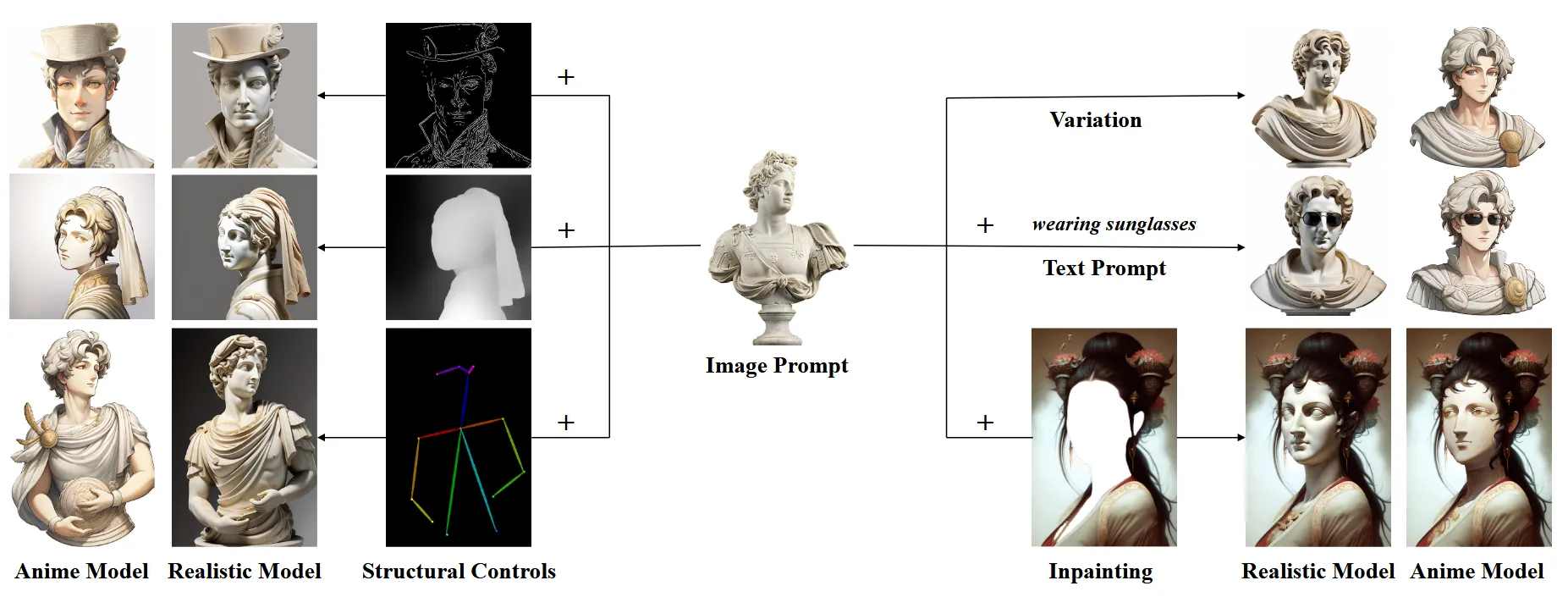
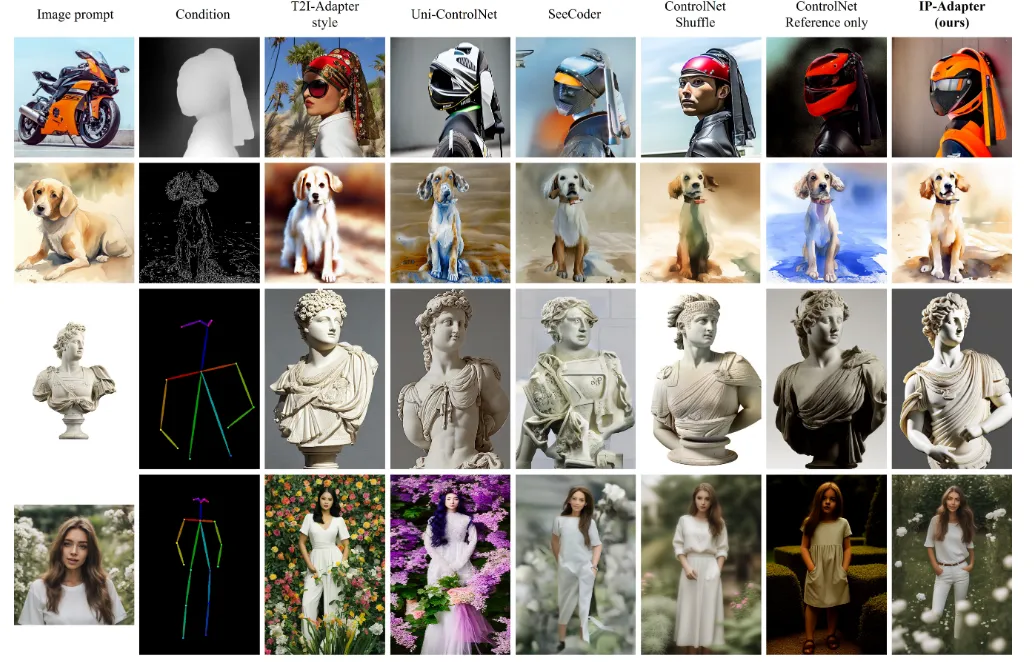
IP-Adapter는 CLIP image 임베딩을 텍스트 임베딩 공간에 투영해, reference image 하나만으로도 기존 text-to-image diffusion model에 “image prompt”를 자연스럽게 끼워 넣어 주는 초경량 모듈입니다. 위의 그림처럼 다양한 image generation task에 쉽게 적용할 수 있는 IP-Adapter를 알아보도록 하겠습니다.
Method
Image Prompt Adapter
현재 대부분의 Text-to-Image Diffusion 모델에 이미지 프롬프트를 활용하려면 별도의 추가 학습이 필요합니다. 그 이유는, 이미지 정보가 기존 diffusion 모델에 효과적으로 주입되지 않기 때문입니다. 이를 해결하기 위한 기존 접근 방식은, 텍스트 임베딩과 이미지 임베딩을 단순히 concat 하거나, 이미지 임베딩을 frozen된 cross-attention layer에 그대로 넣는 방식이었습니다.
하지만 기존 cross-attention layer는 텍스트 프롬프트에 맞춰 학습되어 있기 때문에, 이미지 임베딩을 그대로 주입하면 정보가 왜곡되거나 제대로 반영되지 않는 문제가 발생합니다.
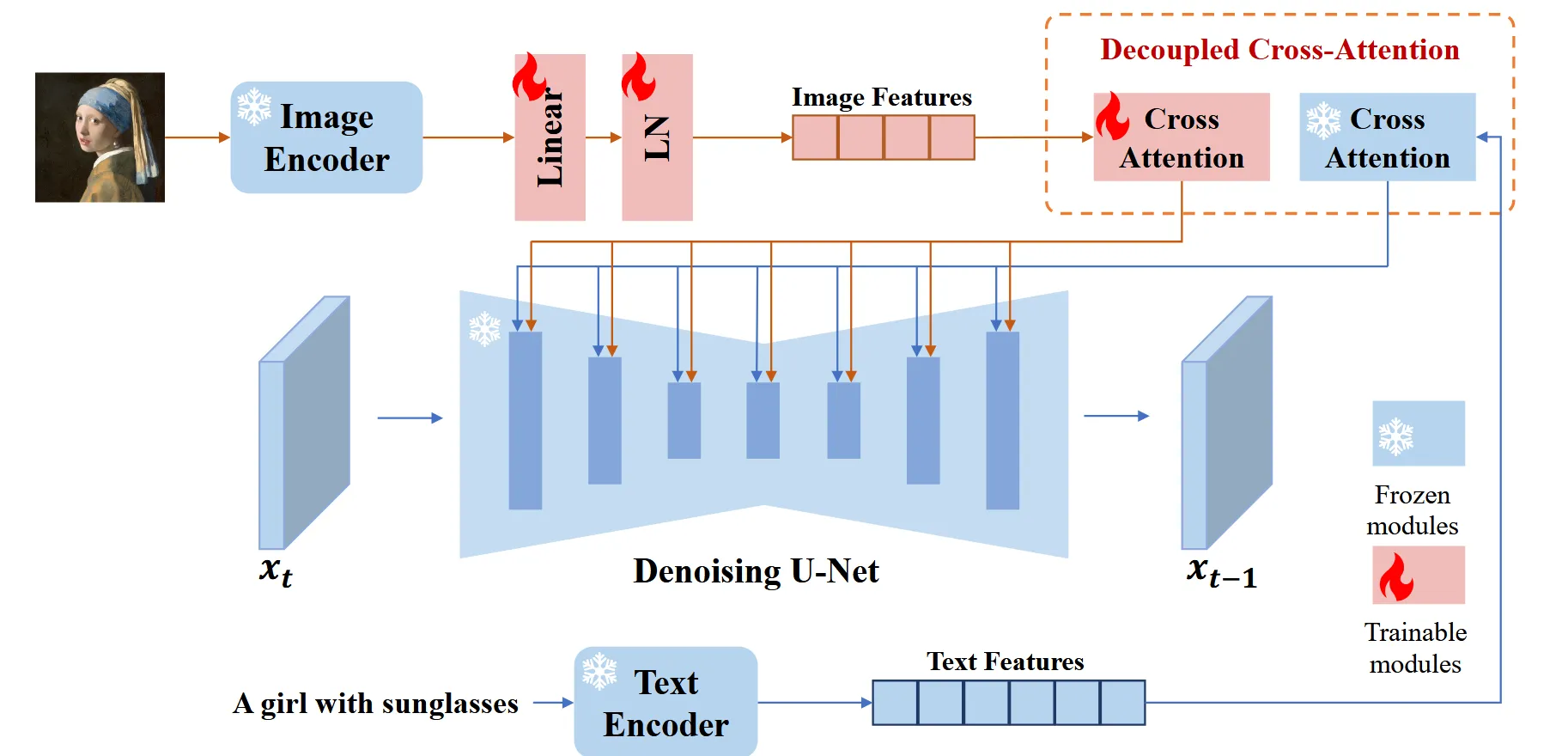
IP-Adapter는 이러한 문제를 해결하기 위해 decoupled cross-attention 구조를 제안합니다. 이는 기존 텍스트용 cross-attention은 유지한 채, 이미지 프롬프트를 위한 별도의 cross-attention layer를 새롭게 추가하는 방식입니다. 아래에서 이 구조에 대해 자세히 설명하겠습니다.
Image Encoder
다른 방법들과 유사하게 pretrained 된 CLIP image encoder를 사용했습니다. 일반적으로 CLIP image encoder로 추출된 임베딩은 하나의 벡터(1X768)인데 Cross-attention에서 사용하는 임베딩은 sequence(token)이기 때문에 하나의 임베딩을 여러개의 임베딩으로 쪼개는 작고 학습 가능한 네트워크를 도입했습니다. 결과적으로 이미지 임베딩은 길이가 N(=4)인 4개의 feature 벡터로 생성됩니다.
Decoupled Cross-Attention
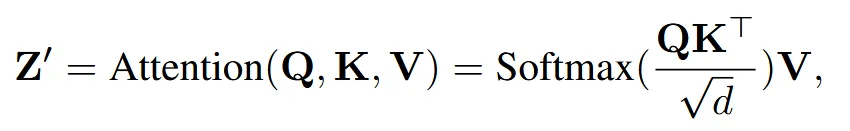
Text prompt가 SD(Stable Diffusion)에 들어갈 때 위의 수식처럼 Cross attention의 Key와 Value도 text features()가 들어갑니다.
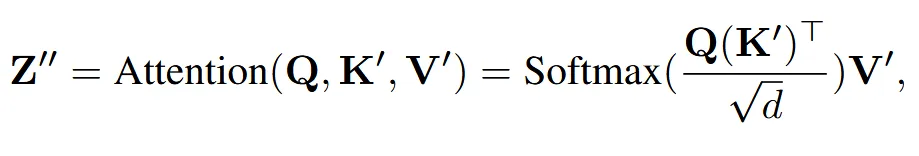
Image prompt도 마찬가지로 기존 layer가 아닌 새로 추가된 cross attention에 Key와 Value로 들어갑니다.
기존 방식들과 차이점은 1개입니다. Image prompt를 위한 cross-attention layer가 추가된 것입니다. 이를 위해서 학습할 matrices는 Key와 Value에 해당하는 W값들 입니다. 초기에 사용할 가중치는 빠른 수렴을 위해서 Text prompt의 가중치를 그대로 가져옵니다.
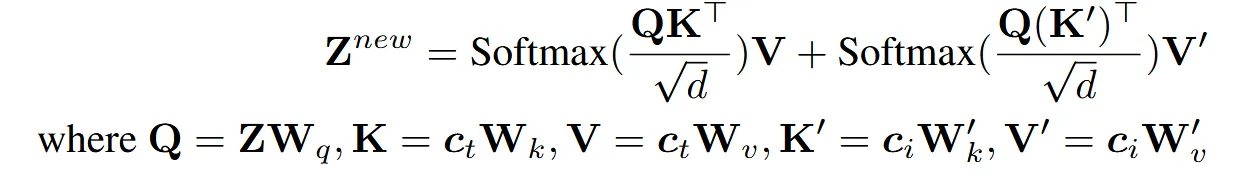
마지막으로 나온 결과는 2개의 layer에서 나온 softmax 값을 단순히 더해주면 됩니다.
Training and Inference
① 학습 시 diffusion 모델은 freeze하고 IP-Adapter만 학습
② classifier-free guidance를 위해 학습 중 일부에서 image prompt를 랜덤하게 제거
③ 추론 시 이미지 조건의 반영 정도를 λ로 직접 조절 가능
Experiments