Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material[2025 arXiv]

Tencent에서 이전 Hunyuan3D 2.0버전에 이어서 새롭게 2.1버전을 출시했습니다. 현재 리뷰를 하는 시점에서 2.5버전까지 나와있으니 이번 리뷰 이후에 2.5버전까지 진행해보도록 하겠습니다. Abstract에 나와 있는 내용은 이전 2.0버전과 동일하게 Shape generation 부분인 Hunyuan3D-DiT와 texture synthesis 부분인 Hunyuan3D-Paint 부분으로 나눠져 있습니다.
2.0과의 차이점에 대해서 결론만 먼저 말하면 DiT부분에서는 MoE가 추가된점이 전부인거 같고, Texture 부분이 크게 바꼈습니다. 물론 샘플링하는 개수도 바뀌는 디테일 부분이 있지만 차이점만을 원하시면 DiT의 MoE가 추가된 아키텍처 그림과 Texture 설명만 보셔도 됩니다.
Data Processing
다른 논문들과 다르게 데이터와 관련된 부분이 Introduction 다음으로 하나의 문단을 형성했습니다. 그만큼 중요한 부분인거 같으니 자세히 리뷰 해보도록 하겠습니다. 사실 중요한 내용은 아니고 입력 데이터를 모두 같은 형태로 만들었다! 라고 생각하시고 넘어가셔도 됩니다.
Dataset collection
Shape generation을 위해서 ShapeNet, ModelNet40, Thingi10K, Objaverse에서 texture된 것과 되지 않은 것을 합쳐서 100K+개를 수집했습니다.
Texture synthesis를 위해서 사람이 직접 70K+개의 데이터를 필터링 해서 얻었습니다.
Data preprocessing for shape generation
Normalization
모든 3D 데이터셋에 대해 먼저 축과 평행한 bounding box를 생성합니다. 그 다음, 이 bounding box의 중심 좌표를 계산해 모든 점에서 해당 중심 좌표를 빼주면, 물체가 정확히 (0, 0, 0) 위치에 오게 됩니다. 그리고 모든 물체의 크기를 동일하게 맞추기 위해, bounding box의 가장 긴 변의 길이로 모든 좌표 값을 나눠줍니다. 이렇게 하면 모든 물체가 길이 1인 큐브 안에 위치하게 되고, 신경망이 기하학적 패턴을 더 효과적으로 학습할 수 있습니다.
Watertight
3D 데이터셋에는 종종 구멍이 있거나, 표면이 제대로 연결되지 않은 결함이 있는 데이터들이 존재하는데, 이런 데이터들을 watertight(물이 세어나가지 않을 정도로 촘촘 → 완벽!)하게 생성하기 위한 과정을 진행합니다.
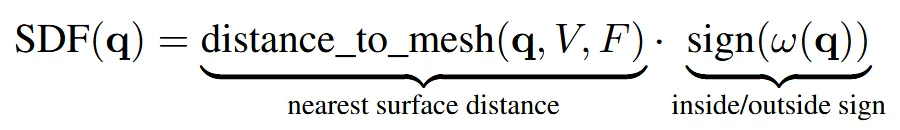
IGL은 위와 같이 진행되는데, 3D grid(격자) 형태로 데이터셋을 나눠서 SDF를 계산합니다. SDF는 위와 같이 2가지 절댓값과 부호로 나눠집니다. 절댓값은 mesh 표면까지의 최단거리로 해당 점이 mesh에서 멀어질수록 큰 값을 갖고, 부호는 winding number를 이용해서 mesh 내부이면 + 외부이면 -를 갖습니다. 참고로 위의 수식에서 V는 vertex, F는 face, q는 query로 격자에 해당하는 값입니다.
이렇게 만들어진 SDF에서 0이 표면이라는 점을 알기 때문에 marching cubes 알고리즘을 이용해서 SDF 값이 0인 등고선을 연결해 새로운 watertight mesh를 생성합니다.
SDF Sampling
SDF값을 얻기 위해서 grid로 데이터를 나눈다 했는데 이과정을 Sampling이라고 합니다. Sampling은 물체의 표면 근처를 조밀하게 sampling해서 물체의 디테일한 요소를 파악하는 방식과 전체 공간을 균등하게 sampling해서 전체적인 이해를 돕는 방식이 있습니다. 해당 논문에서는 2가지 방식을 혼용해서 모든 장점을 사용할 수 있었습니다.
Surface Sampling
2.0에서 사용한 방식과 동일하게 Uniform sampling과 곡률이 큰(high-curvature)부분을 sampling 하는 방식을 5:5로 혼용해서 사용합니다. 이를 통해 모든 디테일과 구조를 효율적으로 학습할 수 있게 됩니다.
Condition Render
Image-to-3D를 사용할 때 condition으로 들어가는 image를 학습에 사용할 때 어떤 형식으로 만들지 설명하는 부분입니다. 입력 이미지로 다양한 각도가 들어올 수 있기 때문에 150개의 카메라를 Hammersley sequence라는 수학적 알고리즘을 사용해서 공간 전체에 균일하게 퍼지도록 배치합니다. 이후 Field of View(FoV)값을 10~70도로 무작위로 정하고, 카메라와 물체의 거리도 1.51~ 9.94로 다양하게 해서 모델이 여러 image condition에 대해서 학습할 수 있도록 합니다.
Algorithm

위에서 설명한 5가지의 data preprocessing을 알고리즘 적으로 표현한 것입니다. 2.0의 코드를 돌렸을 때 point는 8912개씩 sampling했는데 여기서는 거의 10배 더 sampling 하는 것이 조금 놀라운 점입니다.
Data Preprocessing for texture synthesis
학습하는 Texture의 퀄리티는 모델의 성능에 중요한 영향을 주기 때문에 70K+ 데이터를 사람들이 직접 검토해서 필터링 했습니다. 렌더링 할 때 고도는 -20,0,20, 랜덤 이렇게 4개를 사용했고, 각 고도마다 360을 24등분해서 다양한 방위각에서 이미지를 생성하도록 했습니다.
렌더링 된 이미지는 RGB외에도 albedo + metalic + roughness + HDR를 512 x 512 해상도로 만들었습니다.
추가적인 랜덤성을 부여하기 위해서 고도를 (-30,70) 범위 안에서 랜덤하게 뽑고, 조명도 30%확률로 point lights를 사용하도록, 70% 확률로 HDR maps을 사용하도록 했습니다.
Training
Hunyuan3D-Shape
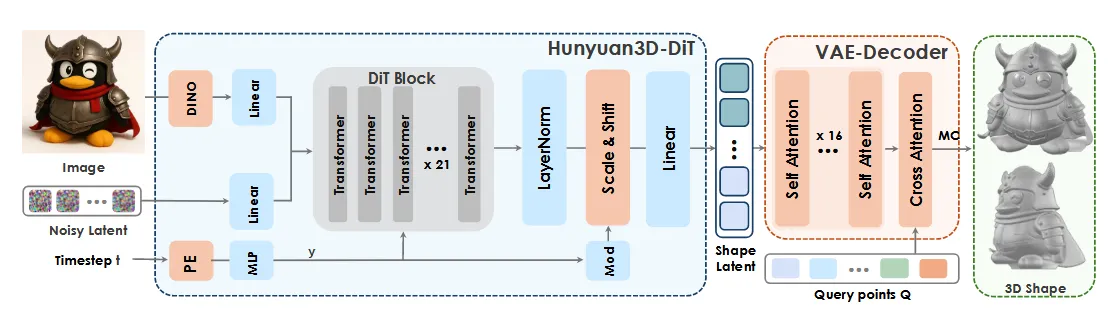
3D 데이터를 latent space로 압축시키고 이를 다시 decoder로 3D 데이터로 복원하는 Hunyuan3D-ShapeVAE와 condition을 기반으로 VAE에서 생성한 latent처럼 생성하는 diffusion 모델인 Hunyuan3D-DiT로 이루어져 있습니다. 여기까지는 2.0 버전이랑 비슷한데 각 모델이 어떻게 2.1에서는 바뀌는지 확인해보도록 하겠습니다.
Hunyuan3D-ShapeVAE
한마디로 2.0과 도일합니다.
3D latent는 3DShape2VecSet이라는 기술과 Dora에서 사용한 벡터 집합 방식을 이용해 3D 형태를 표현합니다. 아래에서 정확히 다루겠지만 현재 입력으로 기존 3D Position(위치)와 함께 normal vector를 갖는다고 설명되어 있습니다. Decoder는 이전처럼 SDF를 예측하고 이를 기반으로 Mesh를 생성하도록 설계 됐습니다.
Encoder
Mesh로부터 unifom sample point cloud()와 importance sample point cloud()를 생성합니다. 가장 먼점을 선택하는 알고리즘인 Farthest Point Sampling(FPS)를 와 에 각각 적용해서 query point 와 를 생성합니다. 이후 각 값들을 Foruier positonal을 각각 적용하고 cross-attnetion, self-attention layer를 거쳐서 hidden shape representation 를 얻습니다. 는 mean 와 variance 를 예측하도록 설계됩니다.
Decoder
Encoder의 결과로 얻은 를 Decoder의 transformer 차원으로 변환하는 linear projection을 진행하고, 여러개의 self-attention 레이어를 통해 처리됩니다. 이후 Point preceiver module에서 3D 공간을 일정한 grid로 나눈 query (HXWXDX3)를 통해서 neural field 값()을 예측합니다. 마지막 linear projction은 마지막으로 를 SDF값인 로 변환하는 역할을 합니다.
Training Strategy & Implementation
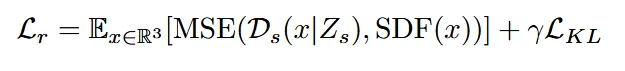
loss도 기존과 동일하게 SDF끼리 비교하는 MSE loss와 latent끼리 비교하는 KL divergence loss를 사용합니다.
Hunyuan3D-DiT
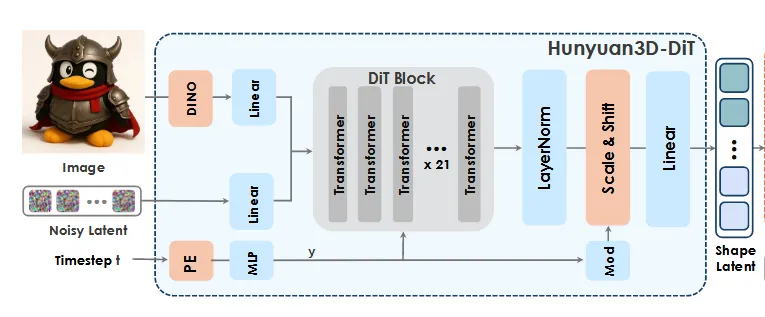
아키텍처만 보면 DINO가 들어간점? PE가 들어간점이 다르게 보입니다.
Condition Encoder
DINO를 통해서 518 X 518 이미지 feature를 얻습니다. 배경은 제거하고 흰색으로 채우는 과정도 진행합니다.
DiT block
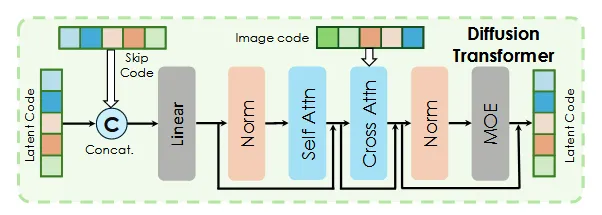
이 부분이 아마 가장 많이 바뀐 부분 같습니다. DiT의 각 block에서 latent code와 skip code를 cocnat하고 마지막 layer에 MOE를 추가합니다.
Training & Inference
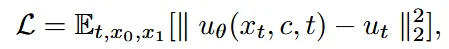
Loss 부분은 이전 부분과 동일하게 flow matching에서 사용한 loss를 그대로 사용했습니다. 똑같이 1차 Euler ODE Solver를 사용했습니다.
Hunyuan3D-Paint
DiT 부분과 다르게 Paint 부분은 2.0 버전과 많이 다른거 같습니다. 일단 시작부터 RGB가 아닌 PBR material texture를 사용한다는 점이 다릅니다.
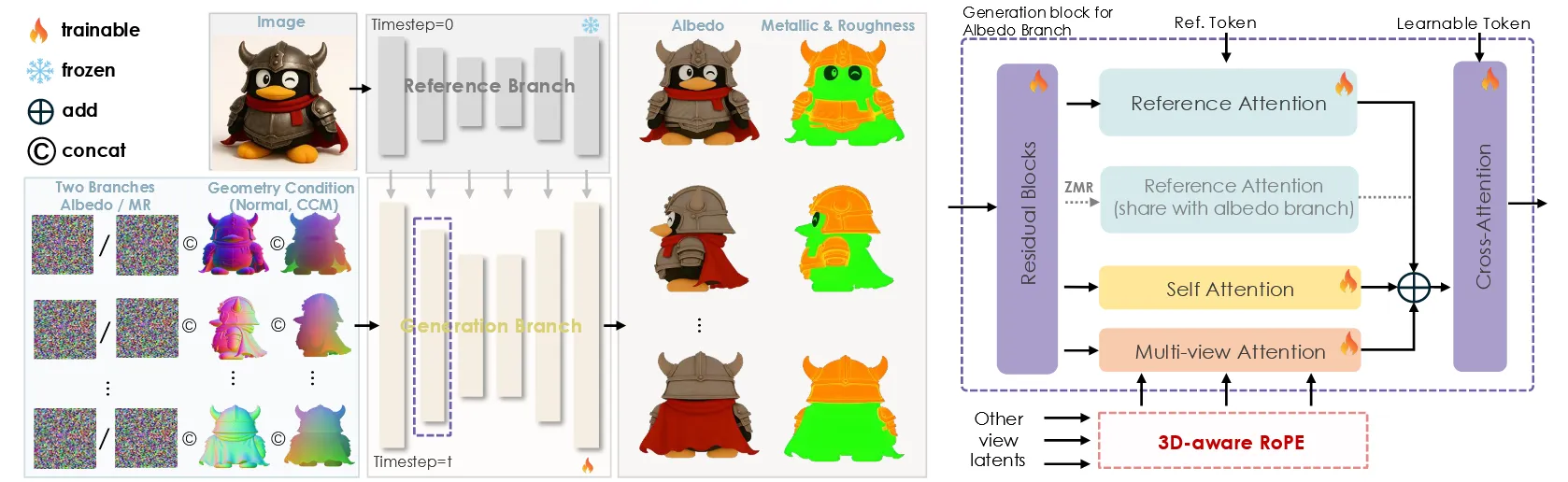
그림의 왼쪽 부분을 보면 RGB가 아닌 Disney Principled BRDF model 방법을 사용한 것을 알 수 있습니다. Image 정보를 얻기 위해서 윗부분의 ReferenceNet을 사용했고 아래에서 기존 latent에 normal와 CCM(canonical coordinate map)을 concat 해서 입력에 넣은 것을 확인할 수 있습니다. 아래에서 더 자세히 설명하도록 하겠습니다.
Spatial-Aligned Multi-Attention Module
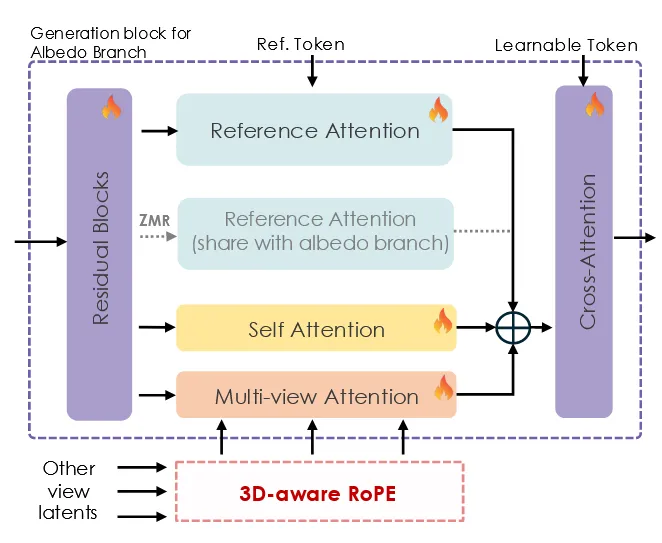
여기서 조금 헷갈리는 내용인 dual branch가 나옵니다. 일단 이해한 바로 정리하자면 입력으로는 이전에 설명한 것처럼 latent + normal + CCM 정보가 들어가고 출력으로는 albedo와 metalic&roughness가 나옵니다. 2개의 결과가 나오기 때문에 dual branch라고 설명 했습니다.
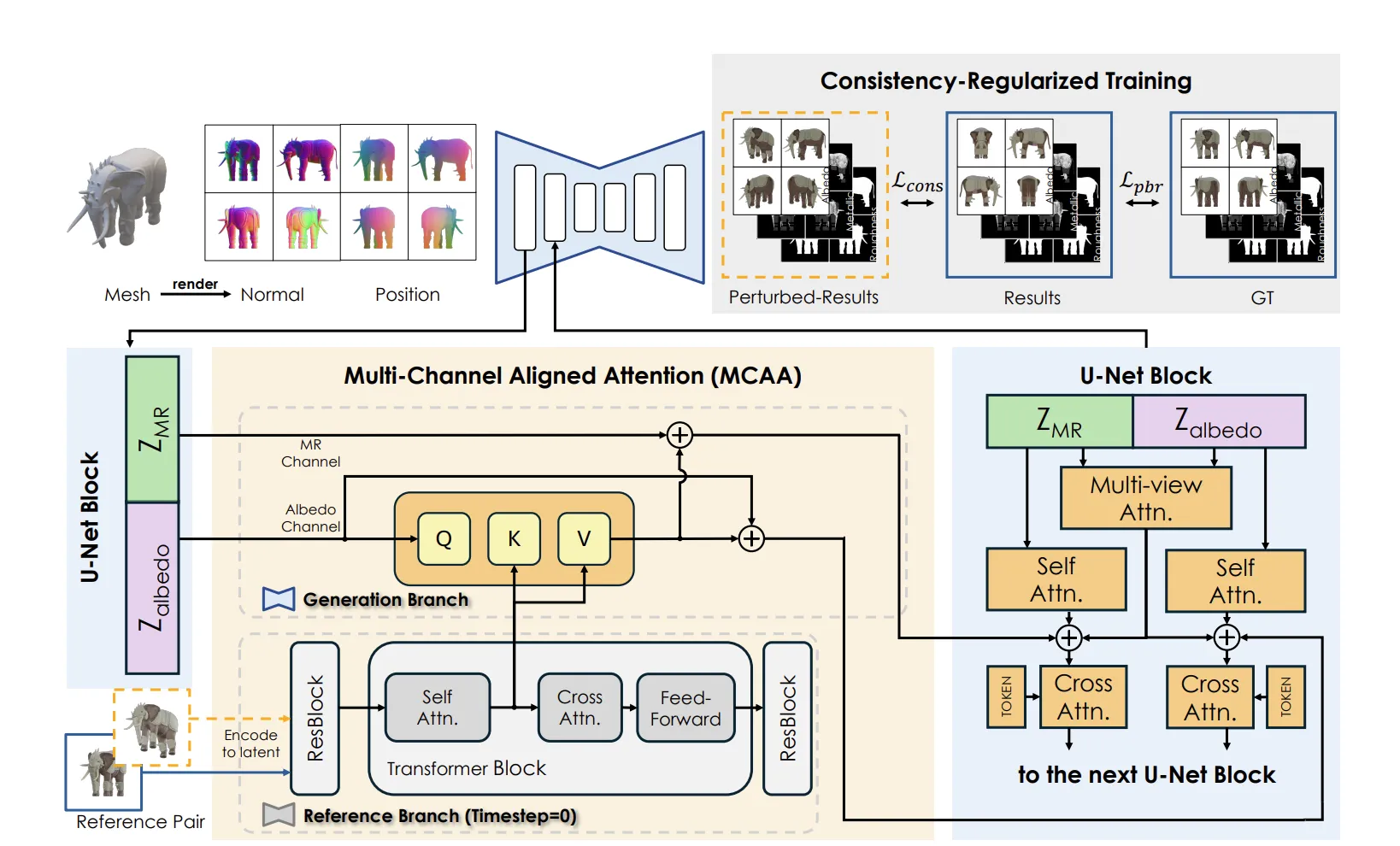
해당 그림이 동일한 저자인 tencent 회사에 낸 Materialmvp 방식이고 이 방식을 이용해서 multibranch unet을 생성했는데 논문을 안읽어서 자세히는 모르겠지만 맨 오른쪽에 learnable token 2개가 각각 MR과 albedo가 되어서 학습이 진행되는거 같습니다. 처음 UNet에 들어가는 입력이 latent + normal+ position인데 이게 아마도 encoder를 통해서 2개의 branch로 분기되도록 설계 되지 않았을까 추측합니다. (자세한 방법은Materialmvp 참고)
3D-Aware RoPE
3D 좌표 데이터를 여러 해상도로 downsampling 한 뒤, U-Net layer의 해상도에 맞게 단순히 벡터의 합을 해줍니다. 이렇게 하면 transformer가 공간 정보를 명확하게 이해해서 여러 시점의 정보를 잘 통합하게 됩니다.
Illumination-Invariant Training Strategy
해당 논문의 목표는 light와 shadow가 일정한 순수한 albedo map과 MR map을 생성하는 것입니다. 이를 위해서 동일한 물체를 서로 다른 조명 아래에서 학습하는 Illumination-Invariant Training Strategy으로 consistency loss를 계산하며 학습을 진행했습니다. (자세한 방법은Materialmvp 참고)
Experiments



4개의 댓글

또한 DiT 모든 Block 이 skip connection 과 MOE 로 이루어져 있는 구조가 아닙니다.
21 DiT Block 중 앞 11개 block 에 대해서는 vanilla DiT 로 이루어져 있으며, 11th Block 부터 skip connection 이, 15th block 부터 MoE 가 추가됩니다.
여기서 MoE 는 TripoSG 의 MoE 와 거의 같은 구조인데, FF layers 에서 fc1 을 parallel 한 8개의 fc 로 늘리고, 이를 선택하는 gate network 와 shared expert 인 fc2 로 이루어져 있습니다.
이 때문에 vanilla DiT block ~60M 대비 ~340M 정도로 block 당 param size 가 늘어나게 되고, 총 3B 정도의 모델 사이즈를 갖게 되는 것입니다.
2.0 에도 DINO 와 PE 는 똑같이 들어갑니다.
Image-to-3D 모델을 학습할 때 image condition 을 주기 위한 방법으로 DINO feature 를 뽑아 X-attention 에서 injection 해주는게 기본적이며, timestep 에 대한 PE 또한 timestep embedder 로써 일반적인 Diffusion, Flow model 에서 많이 취하는 방법입니다. (단순 scalar 를 input 으로 취하지 않습니다).