Instant Neural Graphics Primitives with a Multiresolution Hash Encoding 논문 리뷰
project page: https://nvlabs.github.io/instant-ngp/
Summary
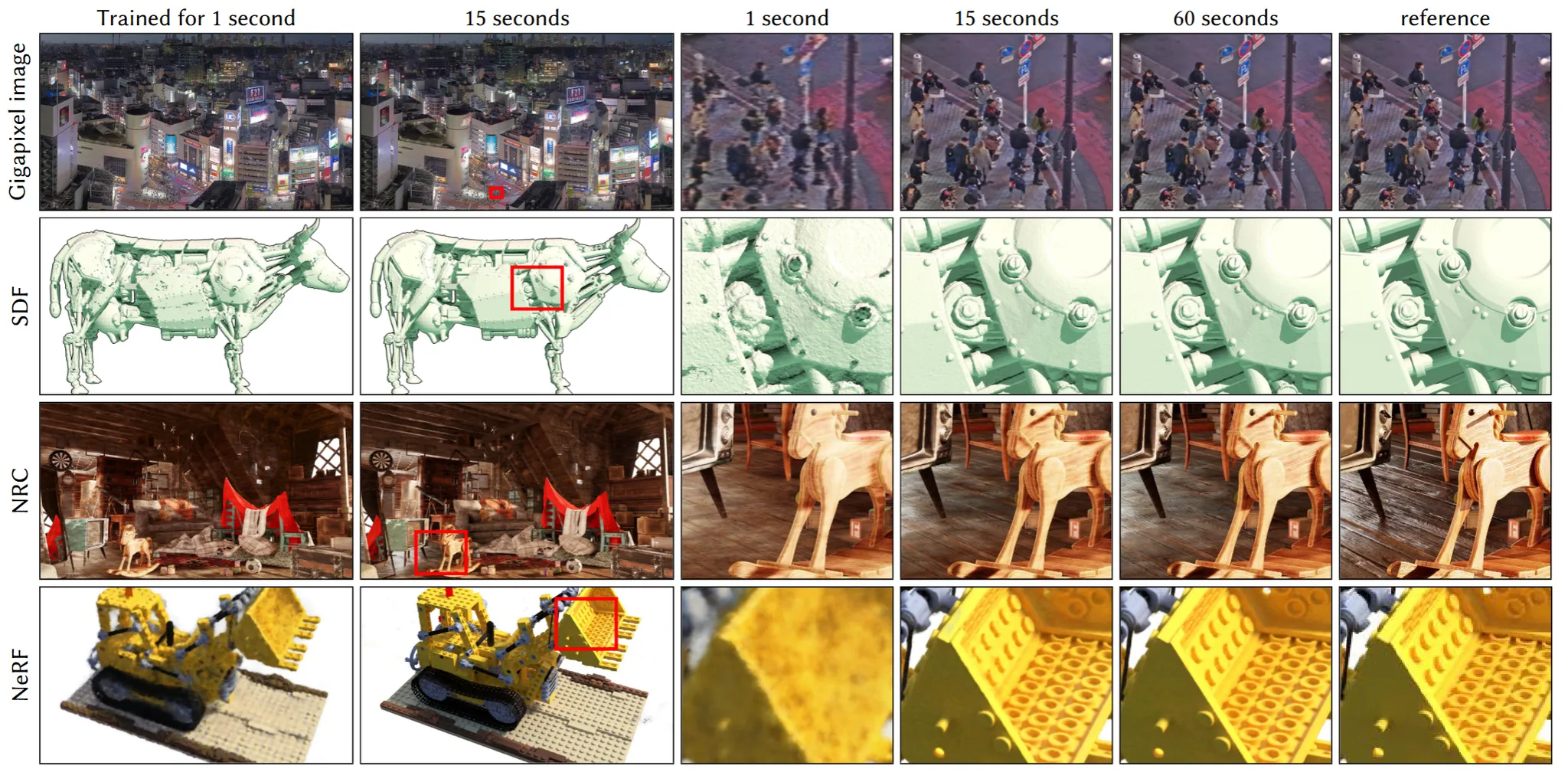
Instant NGP는 3D Reconstruction 모델의 입력 데이터를 더 효율적으로 인코딩하고, 학습 속도와 품질을 모두 향상시키는 역할을 합니다. 직접적으로 Reconstruction 결과를 생성하지는 않지만, 모델이 더 빠르고 정확하게 학습할 수 있도록 기반을 제공합니다.
MLP를 이용해서 3D 표면의 질감과 그림자 같은 복잡한 부분의 학습을 하는 NeRF와 같은 연구들이 많이 나왔지만, 세부 정보를 학습하기 위해서는 모델이 커져야 하고, 계산비용이 많습니다. 이러한 문제를 극복하기 위해서는 MLP가 학습하기 쉬운 형태로 변환해주는 인코딩의 역할이 필요합니다. 인코딩 관련 연구들은 높은 성능을 보였지만 구조를 변경하기 어렵고 경험에 의존한다는 점, GPU의 성능이 안 좋다는 단점이 있습니다. 왜냐하면 기존 연구들에서 사용하는 방식은 특정 작업에 특화되어 있고, 이를 변형하기 위해서는 추가적인 학습 없이는 적응이 어렵습니다. 또한 Tree 구조와 같은 이전 방법들은 CPU에 특화되어있기 때문에 병렬 GPU를 사용할 수 없습니다.
이러한 문제를 해결하기 위해서 해당 논문에서는 multiresolution hash encoding 방식을 제한했습니다. 해상도가 낮을 경우 1:1 매핑, 해상도가 높을 경우 N:1 매핑(높은 gradient 갖는 값을 기준으로 선택)을 통해서 자동적으로 업데이트 할 수 있으며 병렬적 GPU 사용으로 이라는 빠른 계산 시간이 가능하게 됐습니다.
이를 검증하기 위해서 4가지 representation task(Gigapixel image, SDF, NRC, NeRF)에 적용한 결과를 위의 그림을 통해서 확인할 수 있습니다.

위의 그림은 여러가지 인코딩을 사용했을 때의 결과 입니다.
- (a)그림: 아무것도 안했을 때의 결과이고, 사진만 봐도 알 수 있듯이 중요 부위를 전혀 파악하지 못했습니다.
- (b)그림: 8 hidden layers, each 256 wide를 사용해서 적당한 사이즈의 네트워크를 사용한 경우입니다.
- (c)그림: 의 많은 grid를 사용한 경우로 16차원의 feature vectors를 사용해서 총 33.6 million의 엄청난 수의 파라미터를 사용했습니다. 결과가 당연히 좋을 수 밖에 없습니다.
- (d)그림: multi resolution의 경우로서 하나의 점에 대해서 여러가지 resolution의 grid를 사용해서 전역, 지역적인 정보를 한번에 학습하고, 더 작은 차원의 feature를 사용해서 Dense grid보다 더 작은 수의 파라미터를 사용했습니다. 결과는 (c)그림과 비슷합니다.
- (e)와 (f)그림: Hash table을 사용한 논문의 방법으로서 (e)그림을 보면 (b)와 성능과 하이퍼파라미터 수는 비슷하지만 시간이 1/8 감소하고, (f)그림은 (e)그림에 비해서 파라미터 수를 증가시켰을 때 PSNR이 추가적인 시간 없이 증가한 것을 확인할 수 있습니다.
Method
우리가 관심있는 것은 fully connect neural network 에서 입력으로 들어가는 입니다. 따라서 우리는 weight 파라미터 Φ뿐만아니라 encoding 파라미터 도 학습시켜야 합니다.
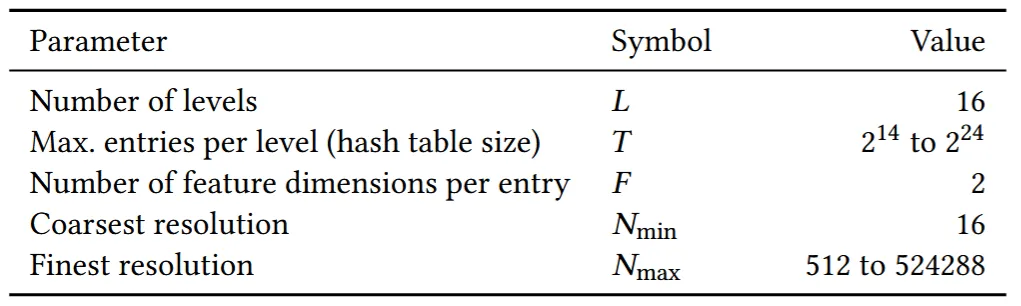
위의 테이블은 하이퍼파라미터 별로 설정할 수 있는 값들입니다. Multi-scale에서 level의 개수 L은 16개, hash table의 개수는 사용자가 설정할 수 있는데 부터 까지 설정할 수 있습니다. Feature vector의 차원 수 F는 2개로서 추후에 자세히 설명하겠지만 하나의 픽셀에 대해서 몇개의 멀티스케일을 적용할지의 값입니다. 과 는 차원의 최소와 최댓값을 나타냅니다.
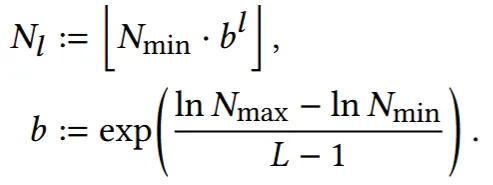
처음 resolution과 끝 resolution을 min과 max로 알고 있기 때문에, 중간값은 Level수(16)에 따라서 지수 함수를 따라서 증가하도록 위와 같이 식으로 나타냅니다. 논문에서 진행한 연구를 그대로 따라할 경우 b의 값은 [1.26,2]의 값을 갖도록 설정됩니다.
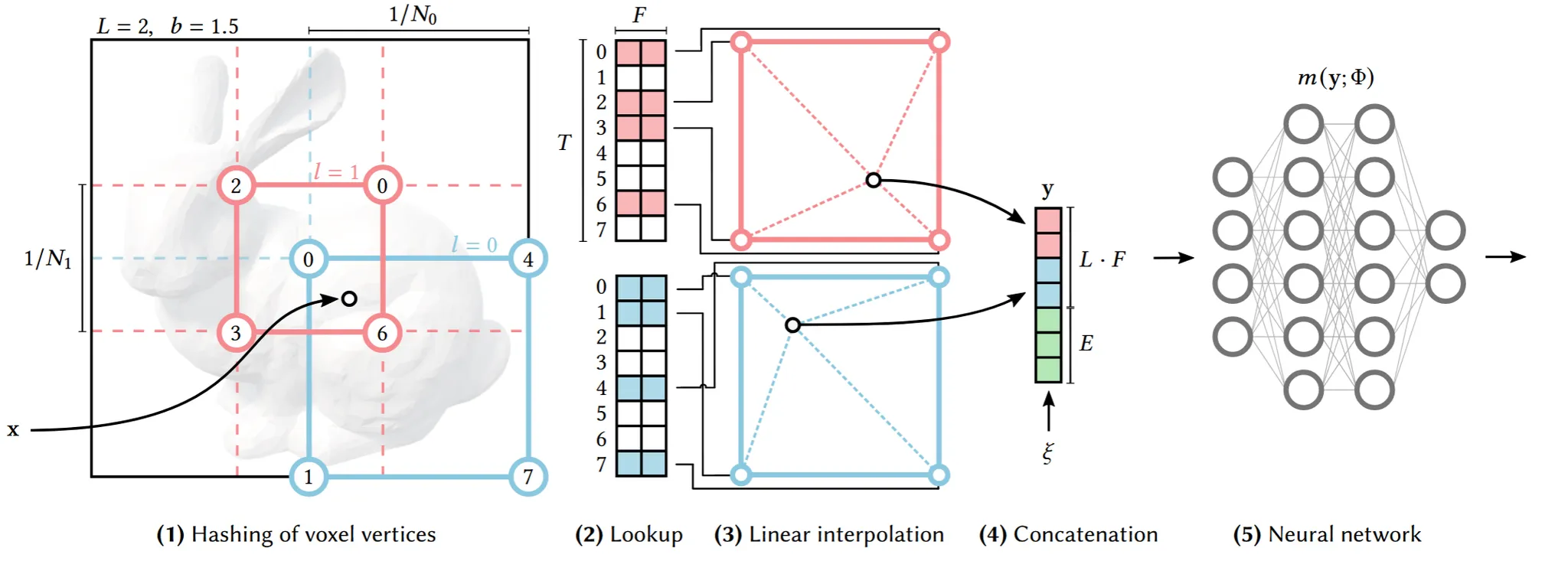
이제 전체적인 알고리즘을 아키텍처 기반으로 살펴보도록 하겠습니다. Hash table을 만들기 위해서 일단 16개의 해상도에 맞는 값을 얻어야합니다. 위의 예시에서는 빨강과 파랑 2가지 해상도만 갖도록 설정했습니다. 참고로 빨간색이 작은 사각형으로 더 적은 영역을 나타내기 때문에 고해상도, 파란색이 더 많은 영역을 나타내므로 저해상도 입니다. 지금 예시에서는 2차원이기 때문에 점의 개수가 라서 4개입니다. 만약 3차원일 경우 픽셀이 정육면체 안에 있기때문에 점은 8개가 될것입니다.
돌아와서 4개의 점은 어떻게 나타낼 수 있느냐 하면 스케일링 후 해당 값보다 크거나 작은 정수 2개를 이용합니다. 예시를 통해서 설명해드리면 하나의 좌표가 (0.3, 0.7) 일 때 해상도 N=10인 경우 좌표에 해상도 값을 곱해서 (3, 7)가 됩니다. 3이하의 값중 최대 정수는 3, 3초과의 값중 최대 정수는 4입니다. 따라서 x좌표는 3,4 마찬가지로 진행하면 y좌표는 7,8이 됩니다. 그러면(3,7), (4,7),(3,8),(4,8) 총 4개의 경우가 나오고 각 경우가 사각형의 꼭짓점이 될것입니다.
이렇게 서로다른 해상도 N을 통해서 좌표 4개를 얻으면 각 좌표는 hash table을 기반으로 vector 값을 갖게 됩니다. 저해상도()는 1:1 매핑이 될것이고, 고해상도의 경우 hash table이 겹칠 수 있는데 이는 자연스럽게 gradient가 큰, 즉 모델에 영향을 많이 주는 점으로 선택되게 됩니다. 어쨌든 이렇게 선택된 값을 기반으로 interpolation을 통해서 해당 점에서의 벡터 값을 얻게 됩니다.지금 벡터의 차원(F)가 2이기때문에 그림처럼 빨간색 블록 2개, 파란색 블록 2개가 나오고 이를 concate해서 MLP의 입력으로 들어가게됩니다. 각 Level에서 feature 값을 얻는 과정은 독립적으로 실행됩니다.
전체적인 알고리즘은 이해가 되셨으니 조금더 디테일한 부분을 설명해드리겠습니다. 해상도가 클 경우 더많은 hash table을 필요로 하게됩니다. 해상도가 크다는 것은 N이 크다는 것이므로 up down 했을 때 경우의 수가 N이 클수록 더 많아지게 됩니다. 예시를 들자면 0.01과 0.02에 대해서 N=10이면 0.1과 0.2 가 되어서 down 0 up 1이지만 N=100이면 1과 2가되어서 down과 up한 결과가 다르고 다른 결과로 인해서 다른 hash table이 필요합니다.
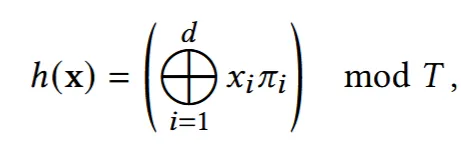
고해상도의 더 많은 hash table의 필요함에 따라 이를 배정하기 위해서 hash function을 사용합니다. ⊕는 비트 XOR 연산자 이고 는 각차원의 독립성을 유지하면서 소수를 나타내도록 π1 := 1, π2 = 2 654 435 761, and π3 = 805 459 861. 이렇게 3개의 값을 지정했습니다. 이후 T에 대해서 나눈 나머지를 이용해서 hash table에 지정해줍니다.
추가적으로 그림을 보면 빨간색 파란색 외에도 초록색 vector가 마지막에 concate되는데, 이는 보조자(Auxiliary) 입력입니다. 해당 벡터는 NeRF와 같은 추후 모델이 추가 정보를 학습할 수 있도록 도와줍니다. 예를 들어서 NeRF에서 View Direction이나 Texture 정보가 들어갑니다.
Hash table size(T)에 따른 결과 분석
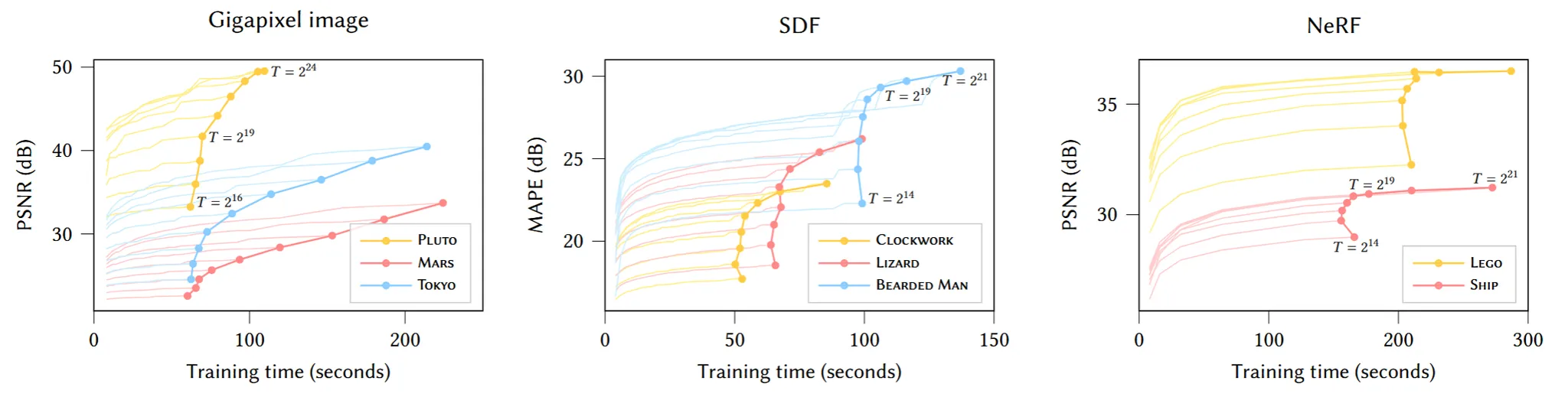
3가지 모델 Gigapixel image, SDF, NeRF에서 T의 값에 따라서 PSNR과 시간을 나타냅니다. 논문에서는 간단하게 T가 증가할수록 time은 선형적으로, PSNR는 비선형적으로 증가하는 것을 확인했다고 나와있습니다. 추가적인 분석은 T가 작은값에서 증가하는 초기보다 후기에는 PSNR의 개선이 더뎌지는 것을 확인할 수 있습니다.
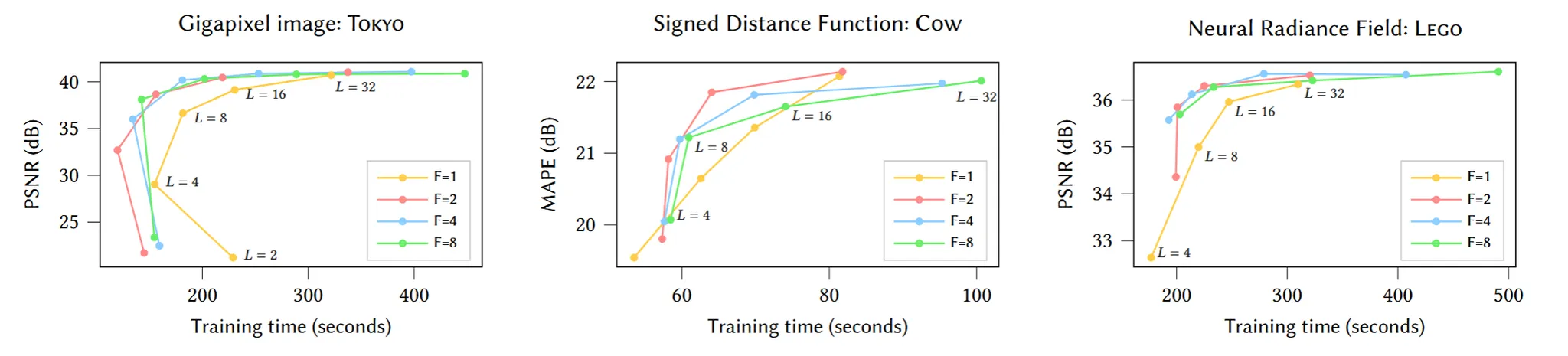
T의 값 뿐만아니라 feature의 개수를 나타내는 F와 Level의 개수를 나타내는 L도 결과에 영향을 미칩니다. L과 F가 증가할수록 PSNR은 증가하는데 신기한 점은 L과 F가 증가한다고 학습시간이 증가하는 것은 아닙니다. 따라서 실험적으로 F=2, L=16인 값이 가장 이상적인 결과를 나타내고 이를 default 값으로 설정했습니다.
Hash collision
저차원의 경우 hash collision이 발생하지 않고(hash table을 필요로 하는 양이 적어서), 고차원의 경우 hash collision이 종종 발생합니다. 따라서 하나의 픽셀에 대해서 고차원에서 hash collision이 발생하지만, 모든 차원에서 동시에 발생하지 않습니다. 또한 hash collision이 발생하더라도 더 중요한(mesh를 잘표현하거나, texture를 잘 표현하는 부분)에서 gradient가 많이 변하고, 해당 부분들이 hash table을 사용하도록 설정했기 때문에 성능에 미치는 영향이 적습니다. 즉 논문에서는 hash collision이 발생하더라도 문제가 없다는 점을 말합니다.
Online adaptivity
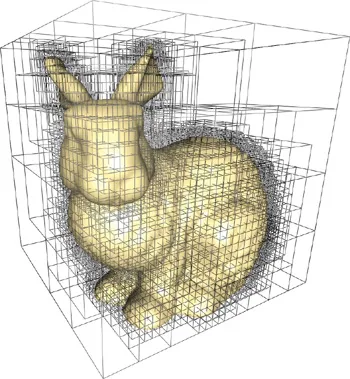
방금 설명한 hash collision이랑 비슷한 설명인데, 학습하다보면 위의 이미지처럼 실제로 물체가 있는 위치는 특정 지역으로 좁혀질 것입니다. 하지만 지금 여러가지 level의 resolution을 다루기 때문에 작은 지역에 대해서도 high resolution이 학습할 수 있다, 즉 영역이 변해도 우리 모델은 학습이 가능하다는 설명입니다.
d-linear interpolation
이 부분도 간단합니다. 이전에 아키텍처에서 4개의 점(벡터)를 하나의 값으로 interpolation해서 최종적인 값을 얻었는데, 이때 interpolation이 아니라 min, max 혹은 그냥 가까운 값을 선택했다면 이는 불연속적인 학습이 될 것입니다. 하지만 interpolation을 사용해서 연속적인 학습으로 end-to-end 학습이 가능하게 될것입니다.
결론
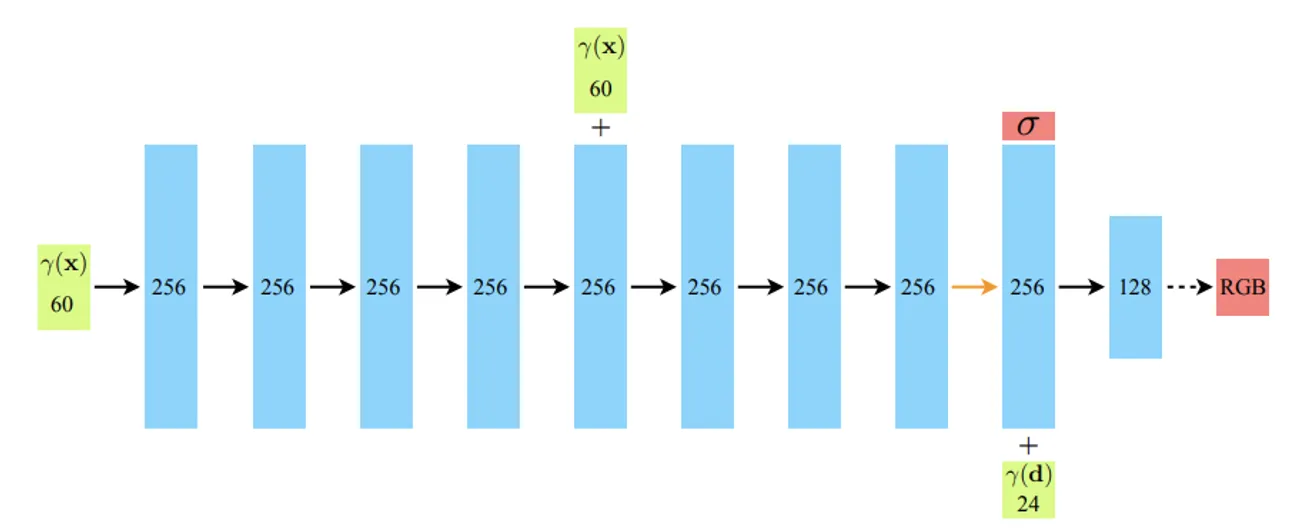
위의 구조는 NeRF에서의 MLP가 사용되는 방법입니다. 입력으로 x,y,z 픽셀의 위치 정보와 direction 정보 2개가 들어가고 출력값으로 density와 RGB 값을 예측합니다.
Instant NGP에서는 입력으로 들어가는 x,y,z를 multiresolution hash encoding을 통해서 더 정밀한 정보로 변환해줍니다.
이렇게 입력값을 NeRF에서 퓨리에 변환을 거쳐서 얻은 x,y,z 값 대신 multiresolution hash encoding을 통해서 간단하고 정밀한 값을 얻었기 때문에 결론적으로 3D Representation의 결과를 얻는 시간도 단축하고 성능도 개선할 수 있었습니다.
위의 영상은 gigapixel image, Neural SDF, NeRF, Neural volume에 Instant NGP를 적용했을 때의 결과를 나타냅니다.

NeRF에 instant NGP를 적용한 추가 자료인데 확실히 hashtable 알고리즘을 사용할 경우 시간이 확실히 단축되는 것을 확인할 수 있습니다.
