Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model 논문 리뷰
프로젝트 링크: https://github.com/SUDO-AI-3D/zero123plus?tab=readme-ov-file
Zero 123 논문 리뷰: https://velog.io/@guts4/Zero-1-to-3-Zero-shot-One-Image-to-3D-Object-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0

Zero-1-to-3 한계와 해결방안
각 뷰를 diffusion 모델을 이용해서 독립적으로 생성하기 때문에 inconsistency 문제가 발생
→ 6개의 뷰를 타일링해서 하나의 이미지로 결합
stable diffusion의 기능을 100% 활용하지 못함
→ conditioning 기법을 이용해서 stable diffusion 능력을 최대한 활용하도록 설정
Improving Consistency and Conditioning
Multi-view Generation
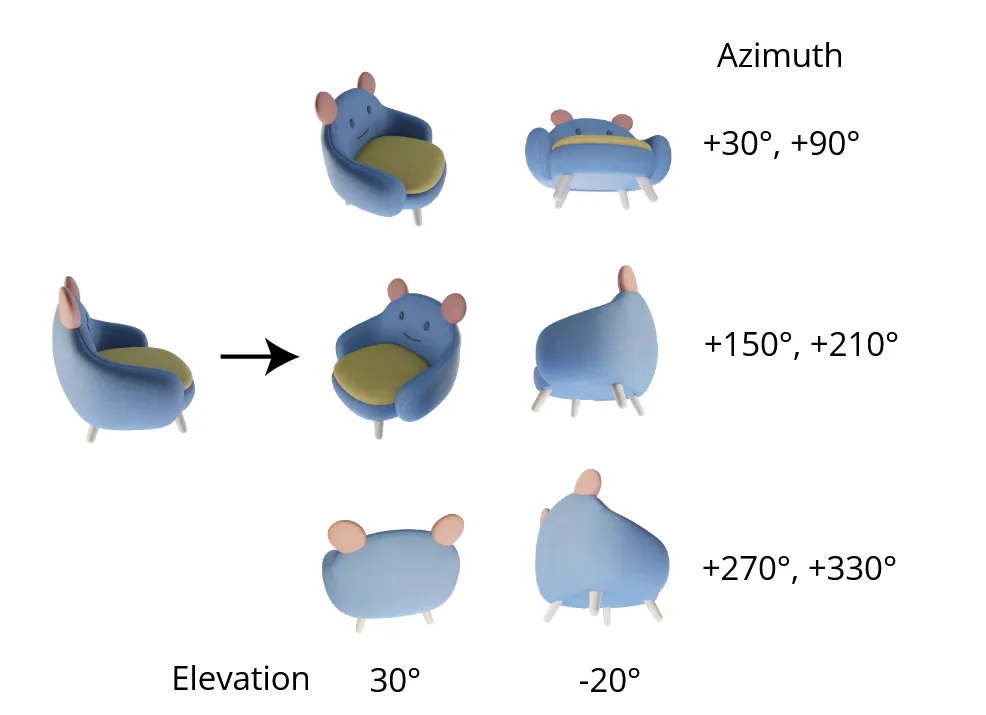
고도를 측정할 때 오차가 발생하면 이는 결과에 큰 영향을 미칩니다. 따라서 고도를 30도와 -20도 2가지로 고정합니다. 이후 방위각은 30도에서 시작해 60도씩 더해갑니다.
Consistency and Stability: Noise Schedule

해당 부분에서는 Stable diffusion에서 사용하는 Scaled Linear방식으로 노이즈를 추가하는 것이 아닌 Linear 방식을 이용해서 노이즈를 추가하는 이유를 설명합니다.
우선 가장 큰 이유는 Scaled Linear를 사용하면 지역적인 부분을 잘 학습하고, Linear를 사용하면 글로벌한 정보를 잘 학습합니다. 멀티뷰 정보를 학습하는 현시점에서는 글로벌한 정보를 잘학습하는 Linear가 더 적절합니다.
위의 표를 살표보면 a가 t시점에 들어간 노이즈의 양을 나타내고, SNR은 Singal-to-Noise Ratio로서 신호대 잡음비입니다. 한마디로 SNR이 높을수록 이미지가 선명하고, 낮을수록 노이즈가 많이 포함된 것입니다. Scaled Linear는 초반에 SNR이 Linear보다 낮게 생성되므로 글로벌한 정보를 학습할 시간이 충분하지 않습니다.

해당 그림은 Stable Diffusion을 LoRA로 fine-tuning한 후 text로는 “police car”를 입력했지만 결과적으로는 흰색 이미지를 생성하도록 모델을 학습합니다. 결론적으로 Sclaed Linear를 사용했을 경우 실패하고, Linear를 사용했을 경우 성공한 것을 알 수 있습니다. 이를 통해서 Scaled Linear가 글로벌한 정보를 학습하는데는 적절하지 않다는 것을 알 수 있습니다.
추가로 diffusion 논문에서 고해상도 이미지가 저해상도에 비해서 노이즈가 덜 낀 것처럼 보인다고 합니다. 이는 고해상도 이미지가 인접 픽셀들이 비슷한 정보를 공유하기 때문입니다. 따라서 저해상도 이미지를 기준으로 노이즈를 추가하면 글로벌한 정보가 강조되게 됩니다.

스케줄러를 변경했을 때 성능을 비교한 사진입니다. 왼쪽은 v-prediction 모델, 오른쪽은 ε-prediction 모델입니다. 따라서 성능이 더 좋은 v-prediction 모델을 사용했다고 논문에서 밝혔습니다.
Local Condition: Scaled Reference Attention
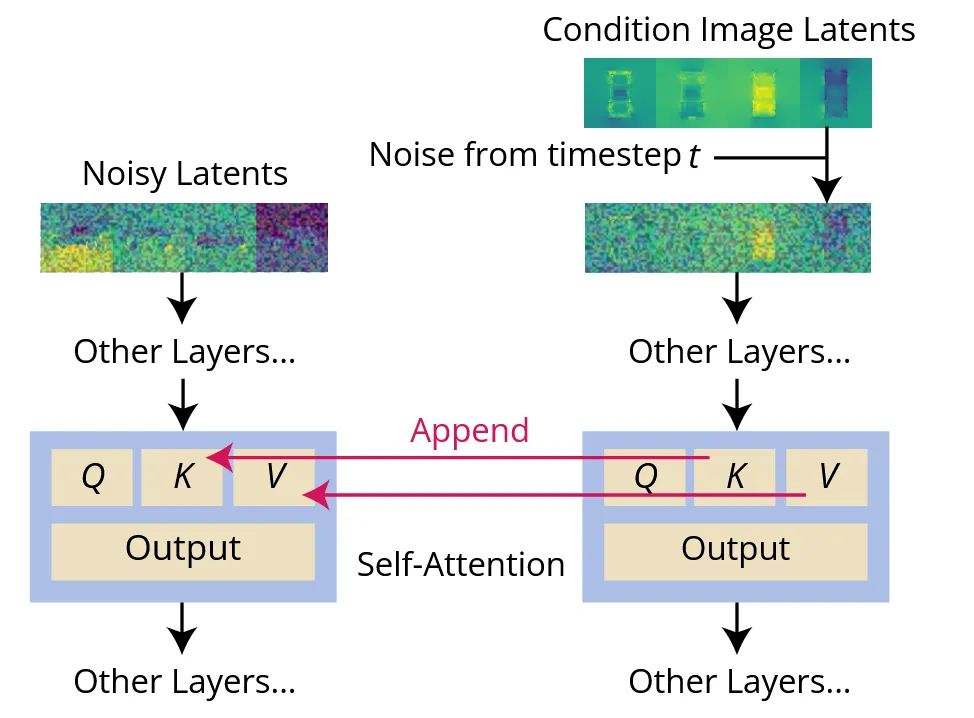
해당 부분은 zeor-1-to-3가 diffusion prior의 능력을 완벽히 사용하지 못한다는 단점을 극복하기 위한 방법입니다. zero-1-to-3에서는 reference 이미지를 단순히 concate했기 때문에 생성할 이미지와 reference 이미지의 시점은 동일하지 않습니다. 따라서 두 이미지는 incorrect pixel-wise spatial correspondence. 이를 극복하기 위해서 위 그림의 Reference Attention을 도입했습니다.
Reference Attention의 내용을 정확히 이해하지 못했지만 이해한 부분에 대해서 설명해드리자면 condition으로 들어오는 이미지에 대해서도 노이즈를 추가하고, 해당 이미지의 Self-ATT의 Key&Value 값을 학습하고자 하는 이미지의 Self-ATT의 Key와&Value로 사용하는 것입니다. 그림만 보면 Cross-ATT 방식처럼 동작하는거같은데 이에 대한 설명은 따로 없었습니다.

해당 그림을 통해서 Reference Attention을 fine-tuning 하지 않아도 충분히 성능이 좋았지만, 스케일링(x5)를 적용하면 더 좋은 성능을 얻을 수 있다고 밝혔습니다.
Global Condition: FlexDiffuse
Global한 정보를 더 잘 반영하기 위해 FlexDiffuse 모델을 사용했습니다. 이역시 자세한 설명은 나와있지 않지만 간단하게 설명하면 CLIP모델을 이용해서 이미지 임베딩 값을 얼마나 반영할지 가중치를 학습하는 과정입니다.
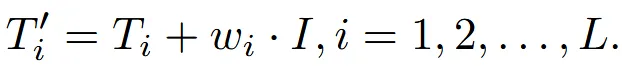
수식은 위와 같고 T는 text embedding, I는 image embedding입니다. 하지만 Zero123++는 text가 없으므로 empty prompt를 통해서 T를 생성하게 됩니다.

결론적으로 효과는 위와 같습니다. 글로벌한 정보를 더 잘 반영할 수 있습니다.
