
프로젝트 링크
논문 링크
Summary
해당 논문은 3D Scene에서 Segmentation을 진행하는 연구입니다. 기존 연구들은 대부분 NeRF를 이용해서 진행했지만 이 연구에서는 3D Gaussian을 이용한다는점과 SAM(Segment Anything Model)을 이용한다는 점이 차별점입니다. 이 논문을 통해서 우리가 원하는 물체 혹은 부분에 대해서 Segmentation을 진행하고 해당 부분을 Editing 하는 것도 좋은 방법이라는 생각이 들었습니다.
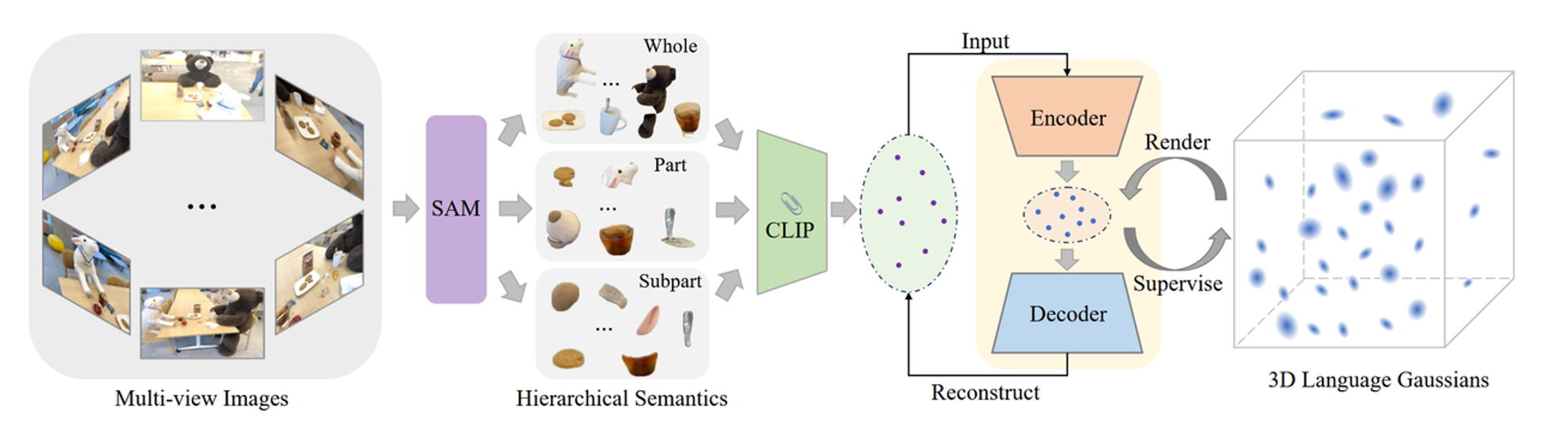
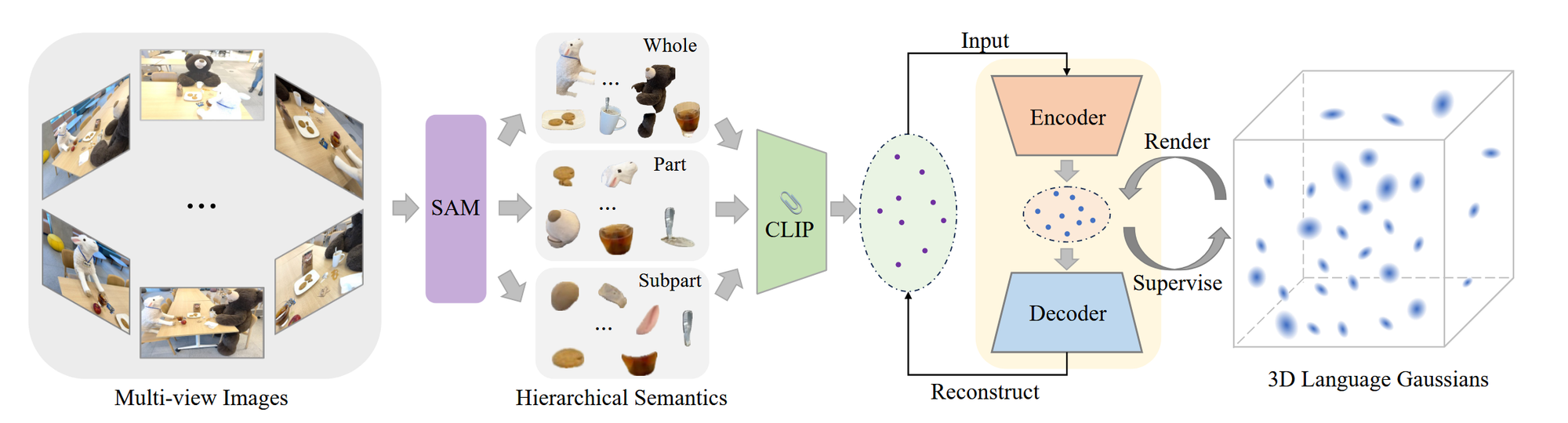
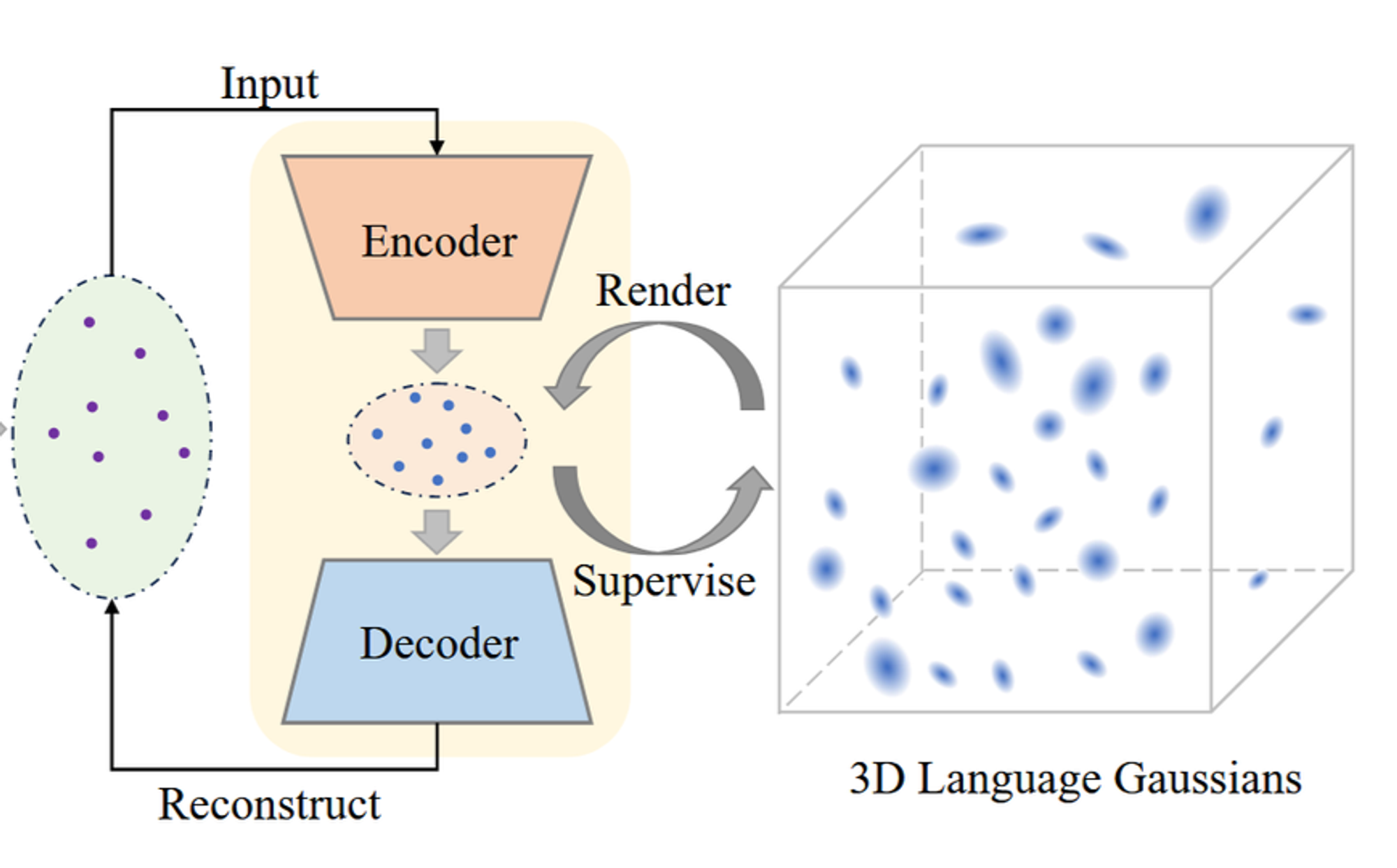
전체 아키텍처는 다음과 같습니다.
입력값: 여러가지 View에서 본 이미지들
- SAM을 이용해서 3가지 계층적인 2D Segmentation 값을 얻습니다.
- Whole: 물체의 큰 부분 (고양이)
- Part: 물체의 부분 (고양이 머리)
- Subpart: 물체의 가장 작은 부분 (고양이 눈)
- 각 계층의 Segmentation 값에 대해서 CLIP 이미지 인코더를 통해서 featrue를 추출합니다.
- 추출된 feature는 autoencoder를 통해서 3차원의 값으로 변경됩니다.
- 3차원 값을 기반으로 3D Gaussian 값을 생성합니다.
학습은 Autoencoder의 Reconstruction loss와 3D Gaussian이 잘 학습되는지를 나타내는 Langauge Loss 2가지를 기반으로 학습됩니다.
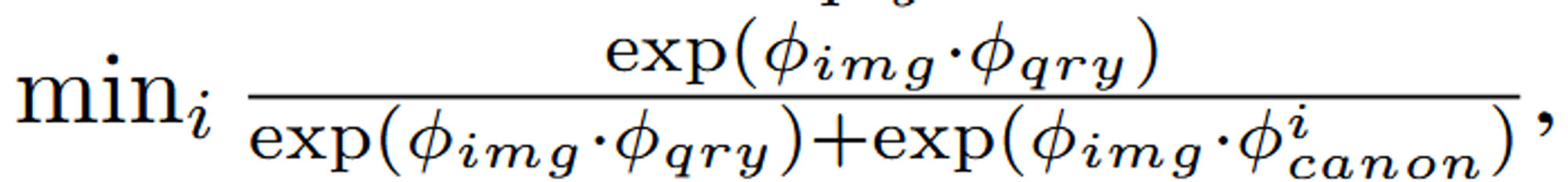
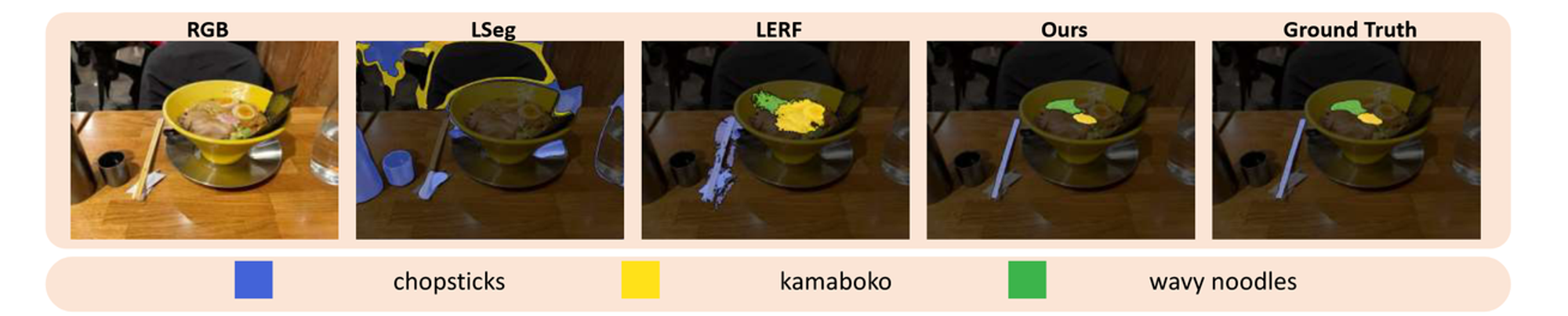
위의 수식은 Relevancy score로 원하는 부분에 대해서 프롬프팅(Ramen)을 하면 해당 쿼리와 가장 유사한 이미지를 선택해주는 과정입니다. 이때 cacnon은 object, things, stuff, texture와 같이 미리 정의된 문구인데 이를 기반으로 큰 물체, 작은 물체 혹은 질감과 같은 부분에 집중할 수 있도록 설정해준다고 합니다.
결과적으로 이전 연구들에 비해 3D Gaussian을 이용해서 더 빠른 속도와 더 좋은 결과를 냈습니다.
Abstract
3D 장면에서 질문을 통해서 해당 객체를 정확하게 찾아내는 연구는 활발하게 진행되고있습니다. 이전까지의 연구들은 대부분 NeRF와 CLIP을 이용해서 진행됐지만 LangSplat에서는 gaussian splatting을 이용해서 시간단축과 성능개선을 이루어냈습니다. 기존 방법들이 정확한 객체 경계를 식별하지 못하는 문제를 해결하기 위해, SAM (Segment Anything Model)을 사용하여 계층적 의미론을 학습합니다.
Introduction
3D language field는 사람과 컴퓨터가 3D 공간에서 언어를 사용해 상호작용하고 쿼리할 수 있도록 하는 기술입니다. 최근에는 CLIP과 같은 vision-language 모델을 사용해 3D 공간에 언어 필드를 구축하려는 시도가 있었습니다. 하지만 이러한 기존 방법들은 속도와 정확성에서 큰 한계를 가지고 있어 실용성에 제약이 있었습니다.
3D point 데이터를 CLIP 임베딩을 이용해서 학습하는 방법은 픽셀기반이아닌 이미지기반이기때문에 모호할 수 있습니다. 예를들어, 곰의 코에 위치한 point는 ‘곰의 코’, ‘곰’, ‘곰의 머리’ 3개의 쿼리에 모두 해당된다고 학습될 것입니다. 이를 극복하기 위해 여러 스케일의 패치 기반의 CLIP임베딩을 사용하는 최근 연구들이 나왔습니다. 하지만 이는 비효율적이고 정확도도 떨어집니다. 이를 보완하기 위해 DINO를 이용했습니다.하지만 이역시 성능이 떨어진다는 단점이 존재했습니다.
이러한 단점들을 극복하기 위해 Langsplat을 제시했습니다.
- 3D Gaussian splatting with tile-based splatting
- 메모리 효율성을 위해 장면 전체의 언어 임베딩을 저차원 latent space로 mapping하는 장면별 language autoencoder를 학습합니다.
- 3d point 모호성 문제를 해결하기 위해 SAM 모델을 활용했습니다.
결론적으로 기존 SOTA 모델인 LERF에 비해 199에 더 빠르고 더 좋은 결과를 도출했습니다.
Related Work
3D Gaussian Splatting
실시간으로 기존 퀄리티를 유지하면서 1080p 화질의 렌더링을 가능하게 해준 모델입니다. 해당 모델을 기반으로 다양한 연구들이 나왔습니다. 이전 연구들과 달리 Langsplat에서는 3D Gaussian을 language 임베딩과 결합하여, 3D language field를 구축하고 이를 통해 3D 공간에서 언어 기반 쿼리를 수행할 수 있도록 확장했습니다.
SAM(Segment Anything Model)
Image segmentation 분야에서 foundation model입니다. SAM을 3D 분야에 적응시켜보려는 연구들이 있었습니다. 이전 연구들과 달리 Langsplat에서는 3개의 hierarchical semantics에서 SAM을 이용해서 정확한 mask를 얻고 3D language field를 학습시킵니다.
3D Language Field
3D Language Field는 3D 공간에서 language 정보를 사용할 수 있도록 하는 field입니다. 이전 연구들은 NeRF를 기반으로 DINO나 CLIP모델을 결합해서 사용하는 방식이었지만, Langsplat에서는 Gaussian을 이용한 방식으로 computational cost와 시간을 감소시켰습니다.
Proposed Approach
Revisiting the Challenges of Language Fields
입력값으로 , 즉 다양한 이미지들이 들어가고 이를 이용해 3D Language field인 Φ를 학습합니다. 기존방식들에서는 이미지를 CLIP을 이용해서 임베딩한 후 NeRF를 이용해서 학습을 진행했습니다.
하지만 CLIP모델은 pixel-align 모델이 아닌 image-align 모델입니다. 다시말해 이미지 기반 정보만 추출할 수 있지, pixel기반의 정보는 추출할 수 없습니다.
또한 pixel 기반으로 추출된 특징들도 point ambiguity 문제가 발생합니다. 고양이의 귀가 ‘고양이의 귀’, ‘고양이의 머리’, ‘고양이’ 3가지 쿼리 모두에 해당한다는 모호성입니다. 이를 해결하기 위해 crop된 이미지 패치로부터 계층적 특징을 추출했습니다. 이 방법역시 2가지 한계점이 존재했습니다. 첫번째로 이미지 패치에는 추가적인 정보가 담겨서 부정확한 결과를 낸다는 점입니다. 이를 완화하기 위해서 DINO를 사용했지만 여전히 부정확한 결과가 나왔습니다.
NeRF를 이용해서 3D Language field를 학습하는 방법 역시 많은 계산과 시간을 소요한다는 단점이 있습니다.
Learning Hierarchical Semantics with SAM
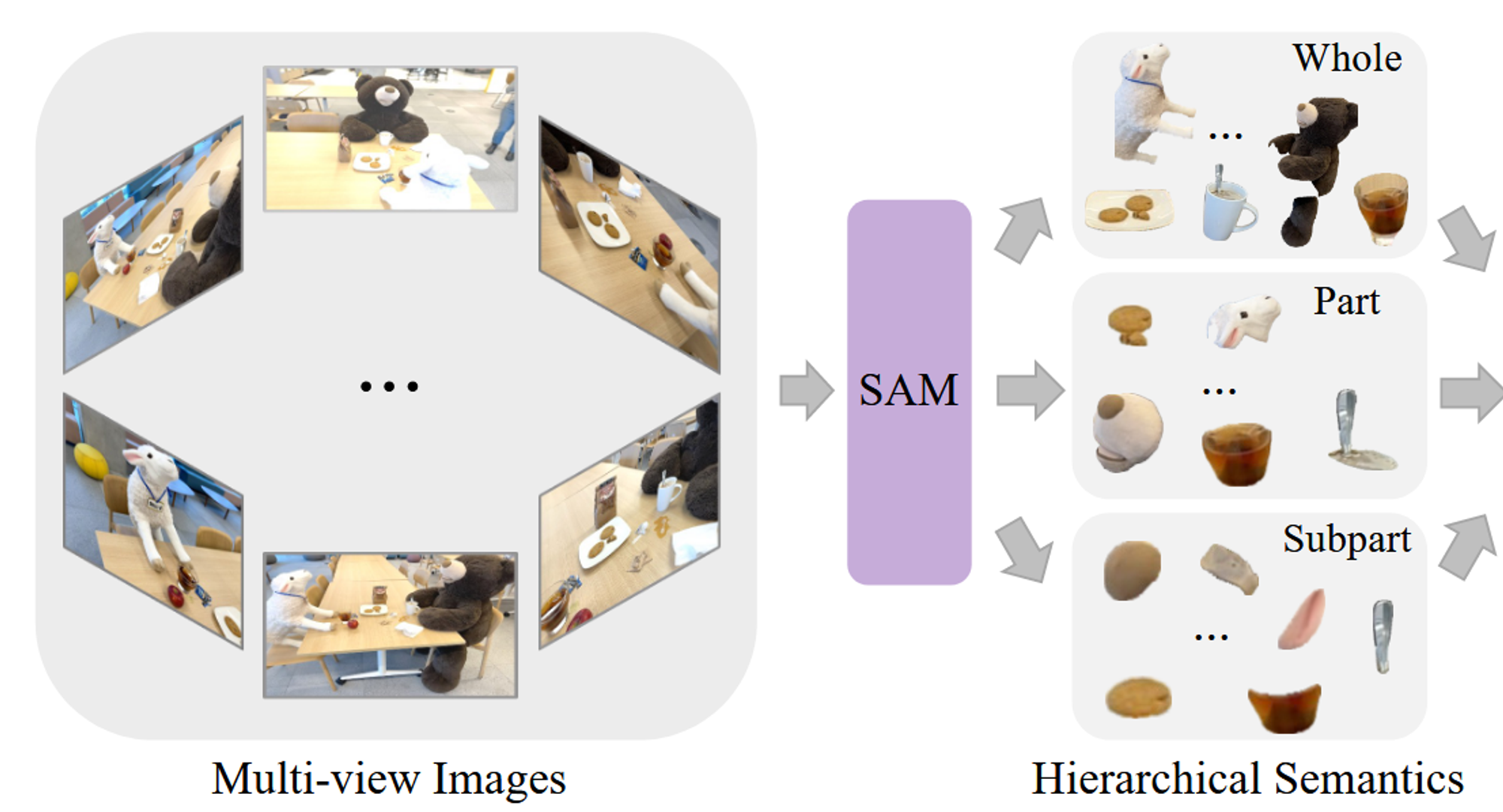
입력값으로 다양한 시점에서 찍은 이미지가 들어가면 이 이미지들을 SAM을 이용해서 3가지 계층적 mask(Whole, Part, Subpart)값으로 나눠집니다. 각 mask에 대해서 겹치는 정도(IoU)를 계산한 후 중복되는 요소들은 제거합니다. mask를 계층적으로 생성하는 방법은 프롬프팅을 이용하는 것입니다. 예를들어서 Whole에서는 고양이, Part에서는 고양이머리, Subpart에서는 고양이 눈 이런식으로 프롬프팅을 하는 것입니다.
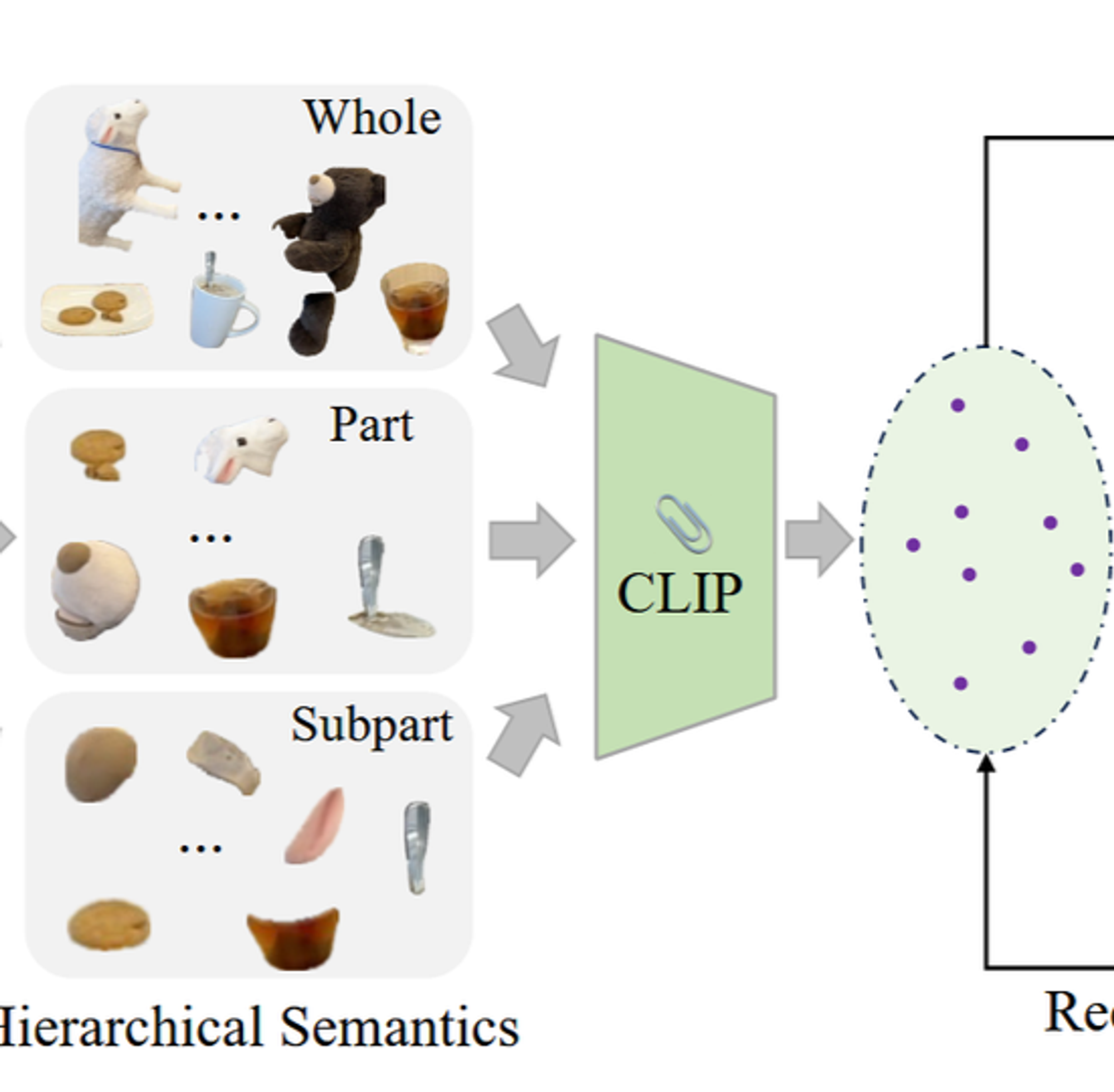
이후 각각의 mask에 대해서 CLIP을 이용해서 이미지 특징들을 추출합니다.
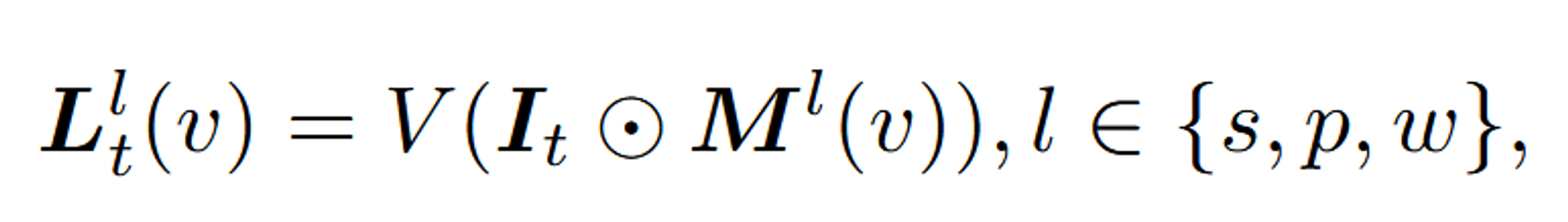
수식으로 나타내면 위와 같이 나타낼 수 있습니다. 수식에서 각 변수들이 의미하는 것들은 아래와 같습니다.
- : 특정 픽셀 v에서 의미 수준 𝑙 에 해당하는 language 임베딩
- V(): CLIP Image Encoder
- : 입력 이미지 t
- : 3가지 의미 수준(s,p,w)에서 픽셀 v가 해당하는 Mask 값
- ⊙: element-wise multiplication
이러한 과정을 거치면 모호성이 사라지고, language-based 쿼리에 대한 정확도가 높아집니다.
3D Gaussian Splatting for Language Fields
3D Gaussian 값들은 파라미터들을 optimize하기 위해서 2D Image로 렌더링됩니다. 이때 계산 효율성을 위해 tile-based-rasterizer를 사용합니다(병렬, 메모리 효율성). 수식적으로 나타내면 아래와 같습니다.
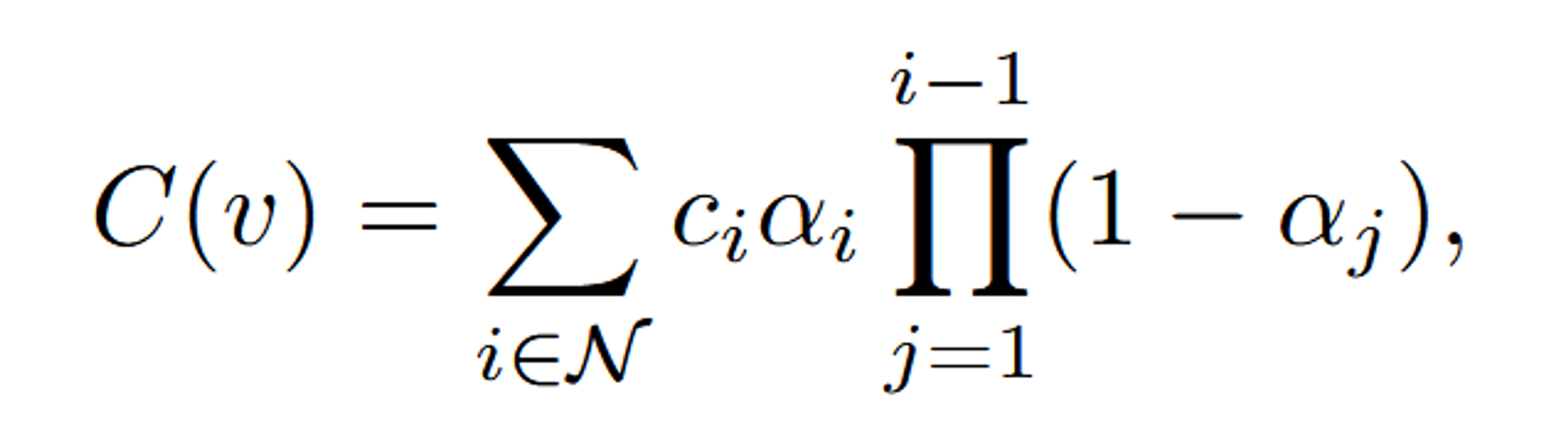
- C(v): 픽셀 v에서 최종적으로 렌더링된 색상 값입니다. 이는 여러 3D Gaussian들의 색상 정보가 종합된 결과입니다.
- : 픽셀 v에 기여하는 모든 Gaussian들의 집합 N에 대한 합을 나타냅니다.
- : i번째 Gaussian이 가지는 색상 값입니다.
- : i번째 Gaussian의 불투명도(opacity)입니다. 이는 해당 Gaussian이 픽셀 v에 얼마나 기여하는지를 나타냅니다.
- : i번째 Gaussian이 픽셀 v에서 기여할 때, 이전의 모든 Gaussian들이 기여한 색상 정보에 대해 얼마나 투명하게 섞일지를 결정하는 부분입니다. 쉽게 말해, 이 부분은 i번째 Gaussian이 앞서 합성된 Gaussian들의 효과를 "통과"한 뒤 얼마나 남게 되는지를 나타냅니다.
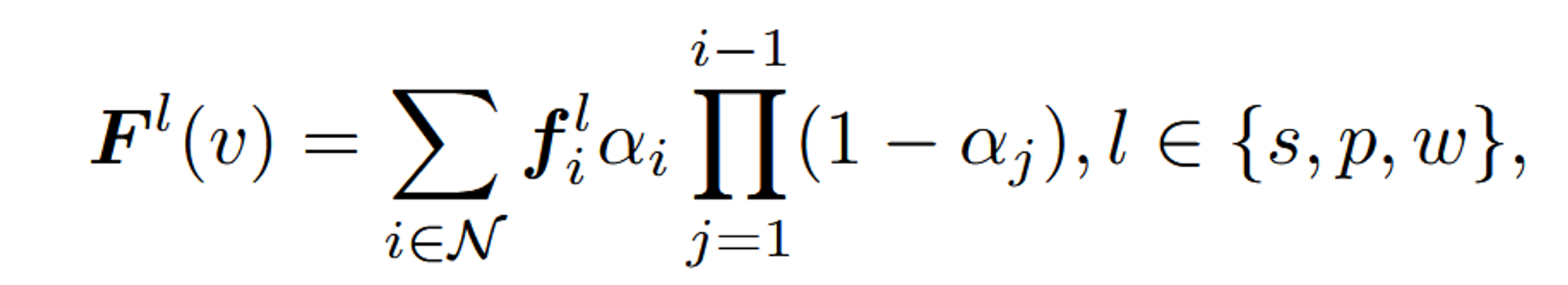
이전 tile-based-rasterizer를 현재 모델에서 사용하는 형태로 변형한 수식입니다. 즉 3D Gaussian Splatting에서 language 임베딩을 렌더링할 때 사용되는 수식입니다.
- : 픽셀 v에서 특정 의미 계층 l에 해당하는 language 임베딩의 최종 렌더링 값입니다.
- : i번째 Gaussian에 해당하는 특정 의미 계층 l에 대한 language 임베딩 값입니다.
계산 효율성을 위해 scenewise language autoencoder를 사용합니다. 이는 고차원 정보를 저차원으로 매핑시켜주는 Encoder를 사용하고, 이를 이용해서 3D Language Gaussian들을 학습시키는 것입니다.
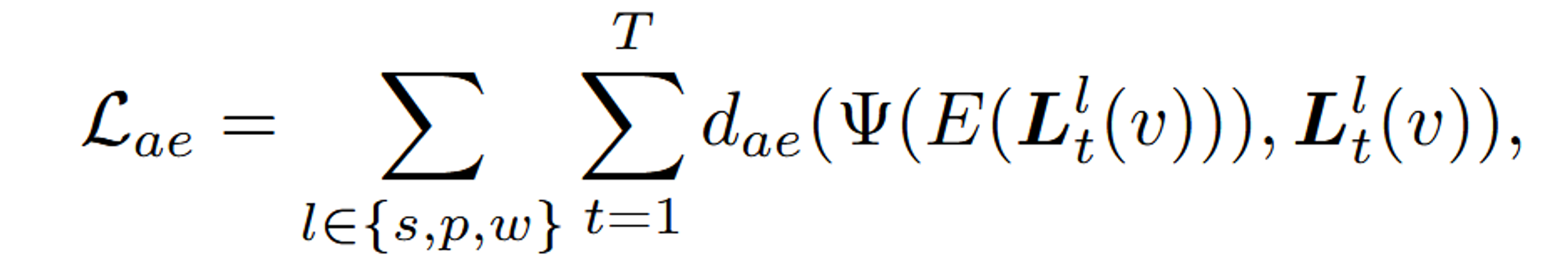
이 수식은 Autoencoder를 사용해 CLIP 임베딩을 재구성하는 과정을 나타내는 Reconstruction Loss를 설명하고 있습니다.
- : Autoencoder의 Reconstruction Loss를 나타냅니다. 이 값은 Autoencoder가 원래 CLIP 임베딩 을 얼마나 잘 재구성하는지를 평가합니다.
- : 세 가지 의미 수준(whole, part, subpart) l에 대해 손실을 계산합니다.
- : 모든 T개의 이미지에 대해 손실을 계산합니다.
- : 재구성 오차를 측정하는 거리 함수입니다. 이 함수는 원래 CLIP 임베딩 와 재구성된 CLIP 임베딩 간의 차이를 측정합니다. L1 distance나 cosine distance로 사용합니다.
- : 이미지 t의 특정 의미 수준 l에서의 원래 CLIP 임베딩을 나타냅니다.
- : 원래의 CLIP 임베딩 를 저차원 latent space로 인코딩하는 Autoencoder의 인코더 부분입니다.
- : 인코딩된 저차원 잠재 벡터를 다시 고차원 CLIP 임베딩으로 디코딩하는 Autoencoder의 디코더 부분입니다. 이는 재구성된 CLIP 임베딩을 나타냅니다.
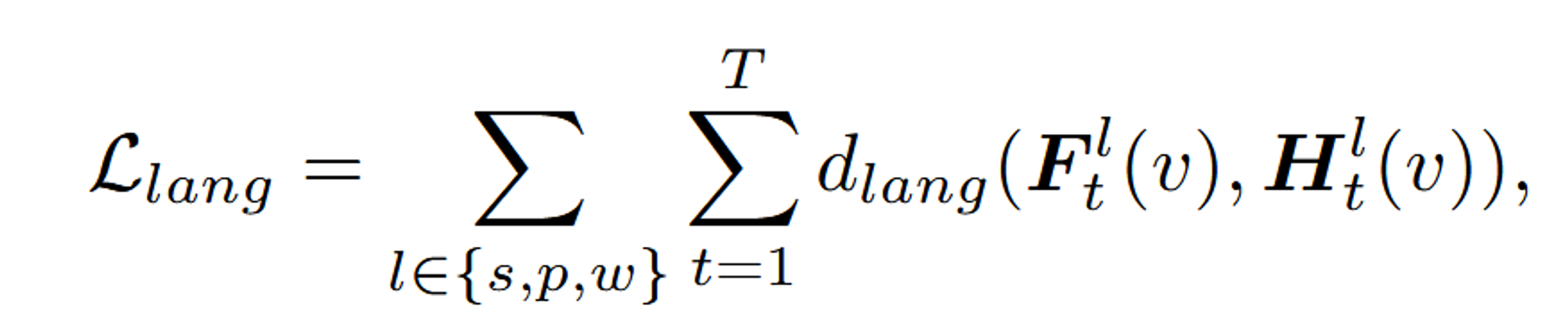
- : language 임베딩 학습을 위한 Loss입니다. 이 값은 모델이 학습한 언어 임베딩이 원래의 언어 임베딩과 얼마나 잘 일치하는지를 나타냅니다.
- : language 임베딩 간의 거리를 측정하는 함수입니다. 이 함수는 3D Gaussian Splatting을 통해 얻어진 language 임베딩 와 원래의 장면별 latent language 임베딩 간의 차이를 측정합니다.
- : 3D Gaussian Splatting을 통해 각 픽셀 v에서 얻어진 language 임베딩입니다. 이는 모델이 학습한 결과로 얻어집니다.
- : 원래의 장면별 latent language 임베딩입니다. 이는 Autoencoder를 통해 압축된 CLIP 임베딩에서 얻어집니다.
cf. 압축 차원은 3으로 설정
Open-vocabulary Querying
기존 연구들과 다르게 정해진 category가 아닌 임의의 category를 입력하더라도 mask를 잘 생성합니다. 기존 연구인 LERF와 동일하게 relevancy score를 각 text별로 계산합니다.
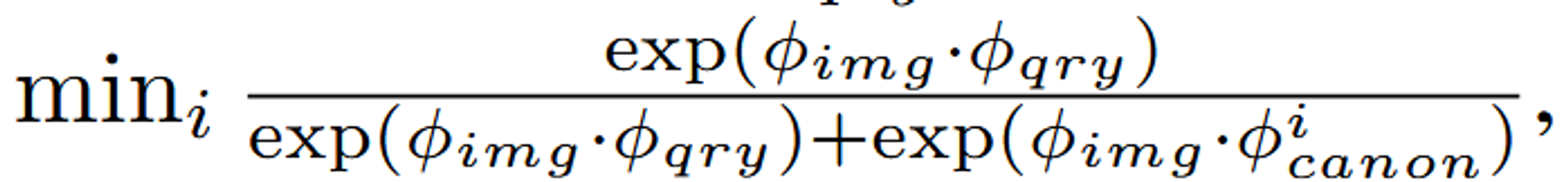
: 렌더링된 임베딩 값
: 각각의 text query
: “object”, “things”, “stuff”, and “texture” 중에서 하나에 속하는 미리 정의된 canonical phrase
가장 높은 relvevancy score를 선택합니다.
이미지의 개수가 T개 존재하고, canon은 4개 존재하므로 총 4T개 중에서 가장 높은 값을 선택하는 것 입니다. 다만 위의 수식에서 min이 써있는 이유는 canon의 4가지 값중에서 가장 작은 결과를 기반으로 이미지의 relevancy score가 정해지는 것입니다. img와 canon의 연관성이 클수록 분모가 커지고 따라서 전체적인 값이 작아지므로 min값을 선택하도록 하는것입니다.
Experiments
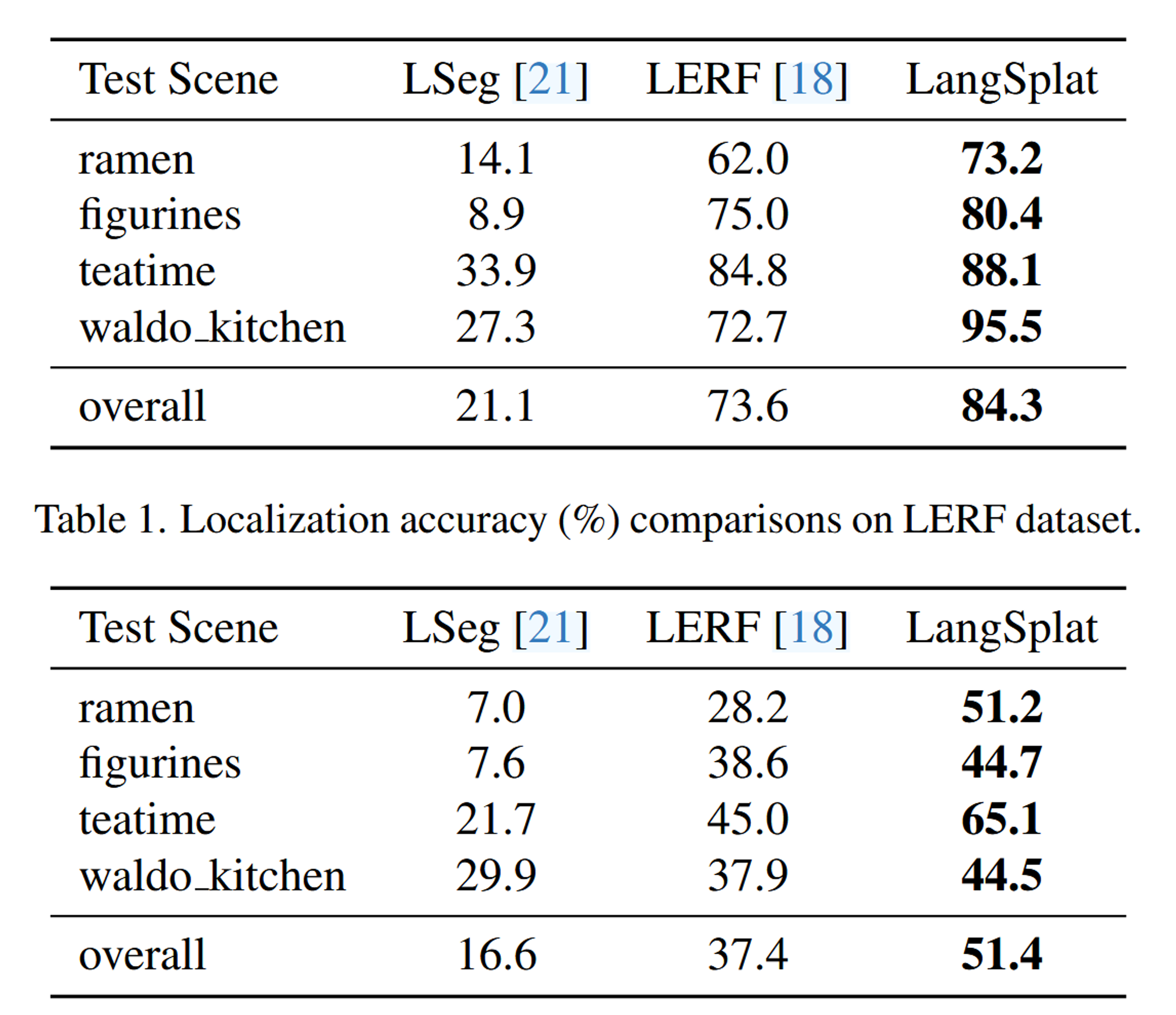
위의 Table은 얼마나 잘 겹치는지를 나타내는 IoU값을 나타낸 것입니다. 전반적으로 기존 연구들에비해서 좋은 결과를 나타내는 것을 알 수 있습니다.

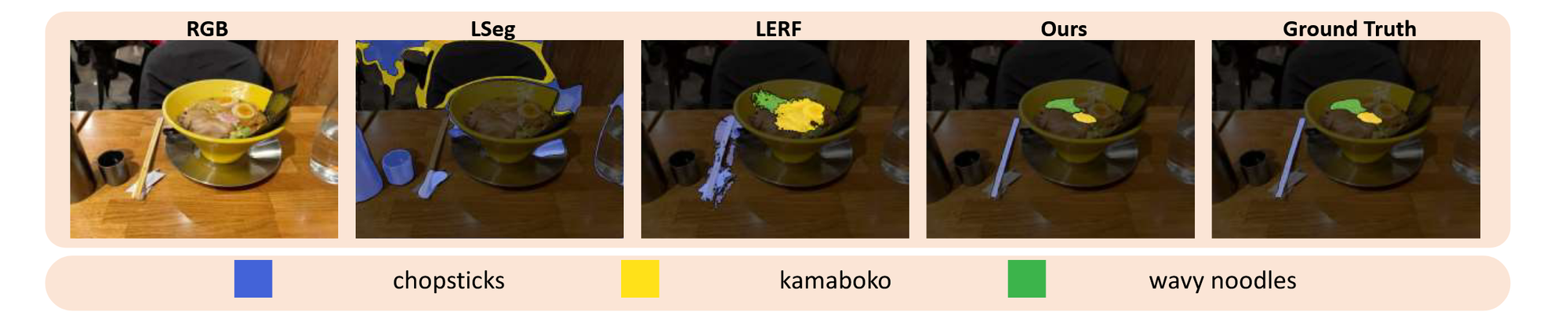
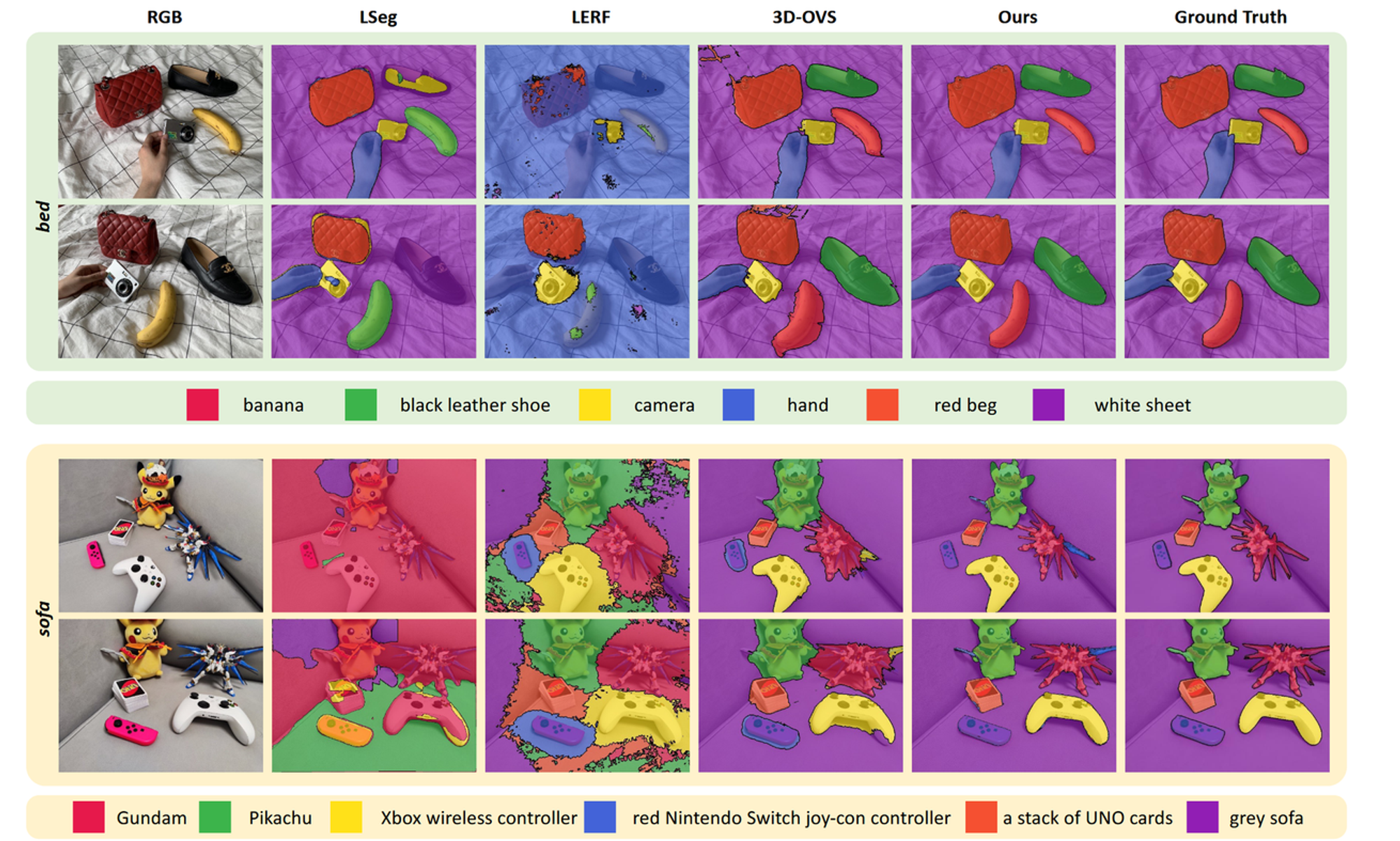
특정 물체를 입력하고 어디에 해당하는지를 시각화하는 자료입니다. LangSplat은 전반적으로 성능이 좋고, LSeg와 LERF는 특정 단어에 대해서만 성능이 좋아보이는 것으로 나타납니다.
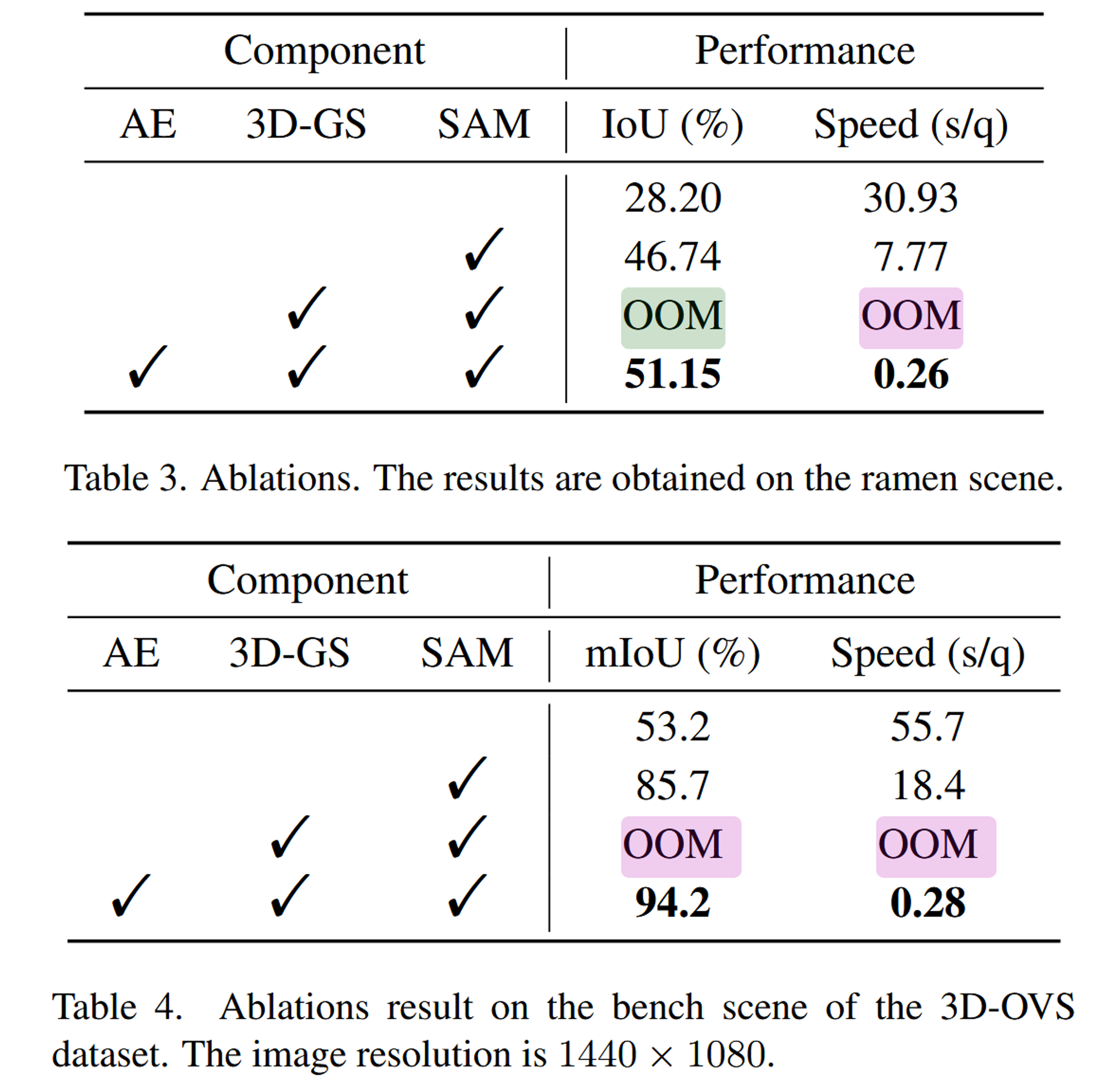
이 결과는 Ablation study인데 SAM이 성능에 미치는 영향과, AE가 메모리 효율성에 미치는 영향을 나타낸 것입니다. OOM은 Out Of Memory로 메모리가 부족하다는 것입니다.
