프로젝트 페이지(영상 3:30 스케치 과정)
논문 링크
Summary
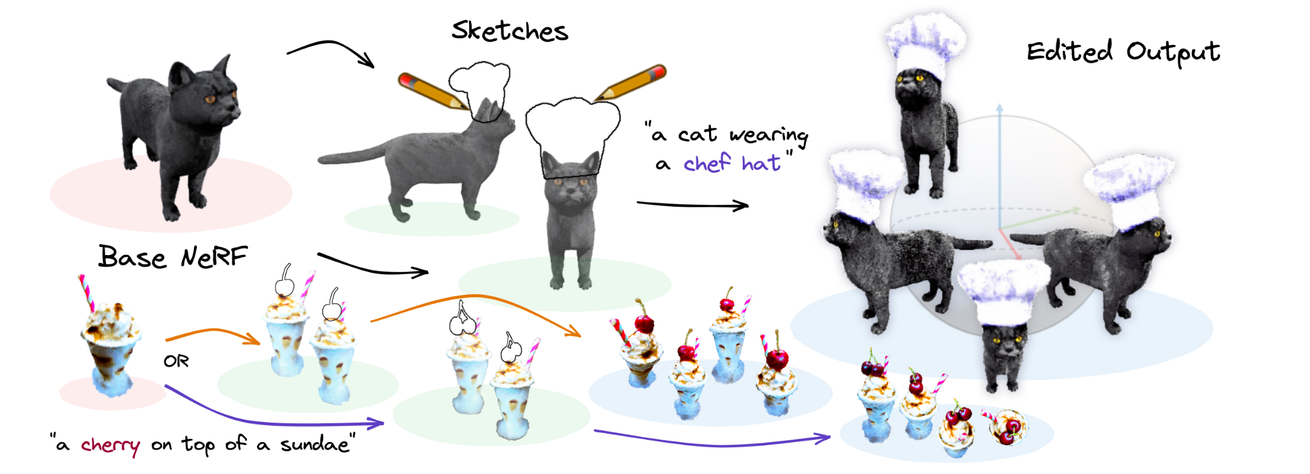
입력값으로는 특정 뷰에서 본 이미지와, 해당 이미지에서의 sketch 값 2개가 들어갑니다.
NeRF를 이용해서 멀티뷰의 이미지를 3D 정보로 수정하고 Sketch한 부분에 대해서만 Text prompt에 맞게 수정해 최종적으로 저희가 원하는 형태의 3D Object를 얻는 것입니다.

Base NeRF
- 멀티뷰의 이미지를 입력하면 3D Object를 생성해주는 역할
- 학습하지 않는 모델
Sketches
- 는 렌더링된 이미지이고 는 해당 시점에서의 sketch 값입니다.
Editing NeRF
- Base NeRF의 복사본으로서 학습가능한 NeRF입니다.
큰틀은 위의 과정이 전부입니다. 하지만 NeRF에서 optimization을 진행했던 것처럼 위의 과정으로는 좋지 않은 결과를 내기때문에 2가지 Loss를 추가하는 optimization 과정을 진행했습니다.
Preservation Loss
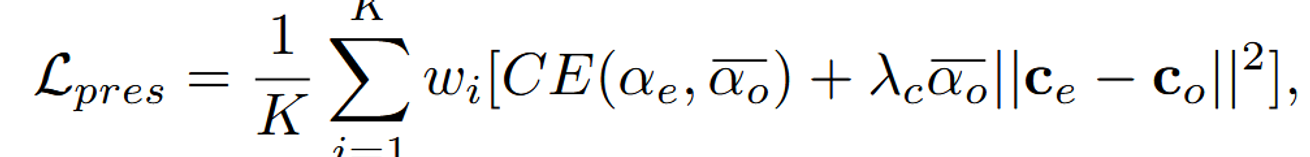
Base NeRF와 Editing NeRF의 차이를 최소화합니다.
Silhouette Loss
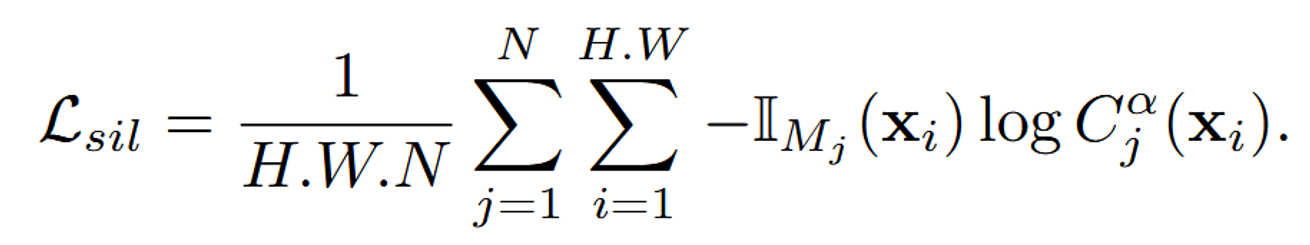
스케치 영역안에 존재하는 픽셀에 대해서만, 값을 키워야 하는 것이므로 스케치 영역안의 픽셀은 밀도를 높이는 과정입니다.
Conclusion & Limitations

2가지 loss를 추가함으로서, 내가 원하는 부분을 스케치로 정의하고 해당 부분만 수정이 가능한 모델입니다. 위의 결과도 단 2가지 뷰에 대해서의 이미지와 스케치만 존재하는데 좋은 결과를 보여주고 있습니다.

하지만 SDS Loss를 사용할 때 흔히 발생하는 문제인 Multiface issue가 발생했습니다. 이 문제는 모델이 입력된 텍스트나 스케치로부터 3D 모델이나 이미지를 생성할 때, 하나의 객체에 여러 개의 얼굴 또는 특징이 반복적으로 나타나는 현상을 의미합니다. 위의 사진이 이에 대한 결과입니다.
Abstract
Text-to-image 분야는 최근에 Text-to-3D로 발전되고 있습니다. 그러나 사용자가 단순히 입력한 Text만으로 지역적인 조정을 하는 것은 상당히 어렵습니다. user guided sketches를 통해서 사용자는 더 직관적인 조정이 가능합니다. 하지만 NeRF에서 렌더링된 이미지에 condition을 적용하는 것 역시 어려운 과제 입니다.
이에 해당 논문에서는 SKED를 통해서 NeRF에 의해 나타나는 3D shape를 Editing 합니다. NeRF에서 렌더링 된 이미지에 대해서 적어도 2개 이상의 이미지를 이용합니다. 생성된 값이 스케치 값을 잘 따르고 기본적인 density와 radiance는 보존하기 위한 새로운 loss를 생성했습니다.
Introduction
AI의 발전으로 인간이 그림에 대한 창작 할 수 있는 부분이 줄어들었고, 이부분에 살리고자 Text 기반의 이미지 생성이 발전됐습니다. 또한 이 분야는 더 발전되어 3D 까지 적용됐습니다. Text 뿐만 아니라 sketch-guided를 이용해서 사용자가 설정한 부분을 기반으로 생성할 수 있는 연구들이 활발히 진행중입니다.
2D에서 적용된 기법들이 3D에서도 적용될 수 있을지는 의문이었습니다. DreamFusion이나 Magic3D 같은 경우 text-to-image를 기반으로 훈련이 진행됩니다. 그러나 이러한 모델들은 NeRF를 최적화하는 과정에서 여러 시점의 2D 뷰에서 그래디언트를 계산하므로, 일관된 스케치를 제공하는 것은 어려운 문제입니다.
이에 해당 논문에서는 SKED(SKetch-guided 3D EDiting) 기술을 제시했습니다.
해당 기술에서 최소 2개이상의 스케치와 text prompt가 입력으로 들어갑니다. 이에 대해서 출력값으로 우리가 원하는 형태의 3D shape이 나오게 됩니다. 이 작업은 복잡하기 때문에 두 가지 더 간단한 하위 작업으로 나눌 수 있습니다. 첫 번째는 순수한 기하학적 추론에 의존하고, 두 번째는 생성 모델의 풍부한 의미적 지식을 활용합니다. SKED를 사용하여 원본 신경 필드에 다양한 액세서리, 객체, artifact를생성하고 매끄럽게 결합할 수 있습니다.
Related Work
Sketch-Based 3D Modeling
애니메이션이 발전되면서 해당 분야의 연구는 활성화 됐습니다. 사람이 스케치를 그리고 어떠한 조건을 추가한다면 해당 조건을 기반으로 depth와 같은 정보를 추정하고 스케치를 기반으로 3D shape을 생성하는 분야입니다. 데이터 기반 접근법에서는 다중 시점 스케치를 사용하여 객체를 재구성하는 방법이 제안되었습니다. 그러나 본 논문에서는 이러한 전통적인 접근과 달리, 생성 모델을 스케치된 영역 내에서만 작동하도록 제한합니다. 이를 통해 복잡한 tuning inflation parameters이나 대규모 데이터셋 수집 없이도 texture와 shading을 동시에 예측할 수 있습니다.
Diffusion Models
Diffusion model은 Text-to-image 분야에서 SoTA를 달성하고 있는 모델입니다. Text 뿐만아니라 다양한 Condition을 넣어도 잘 학습되도록 설계됐습니다. 본 논문에서는 Codition으로 스케치를 넣어서 활용합니다. Diffusion 모델을 3D로 직접 적용하려는 시도도 있었으나, 이 경우 대규모 3D 데이터가 필요하여 확장이 어려운 문제가 있습니다.
Neural Fields
딥러닝을 이용해서 3D를 표현할 수 있는 NeRF는 엄청난 주목을 받았습니다. 이에 이를 발전시키는 다양한 연구들이 나왔습니다. 하지만 geometric한 정보 없이 NeRF를 기반으로 3D를 표현하다 보니 다중시점에서 일관된 표현을 하지 못한다는 한계가 존재했습니다. DreamFusion과 같은 모델들은 대규모 2D 데이터셋에서 학습된 Diffusion 모델을 활용하여 3D 데이터를 생성하고 최적화하는 방법을 제안했습니다. 이러한 접근법은 다중 시점에서 NeRF를 최적화하여 객체를 생성합니다. 이 논문은 DreamFusion과 같은 프레임워크를 단순화하여, 전통적인 스케치 기반 모델링 제약을 최신 생성 모델의 힘과 결합하는 것을 목표로 합니다.
Method
기존에 설명했던 것처럼 크게 2가지 부분으로 나뉩니다.
- 기하학적인 형태를 정의하는 제공된 sketch
- 주어진 text prompt를 SD(Score Distillation) Loss 기반으로 Latent Diffusion model 학습
스케치를 기반으로 shape를 바꾸기 위해서 2가지 objective function을 제시했습니다.
- original density와 radiance fields를 유지하기 위한 방법
- 주어진 sketch를 유지하면서 변형을 하기 위한 방법
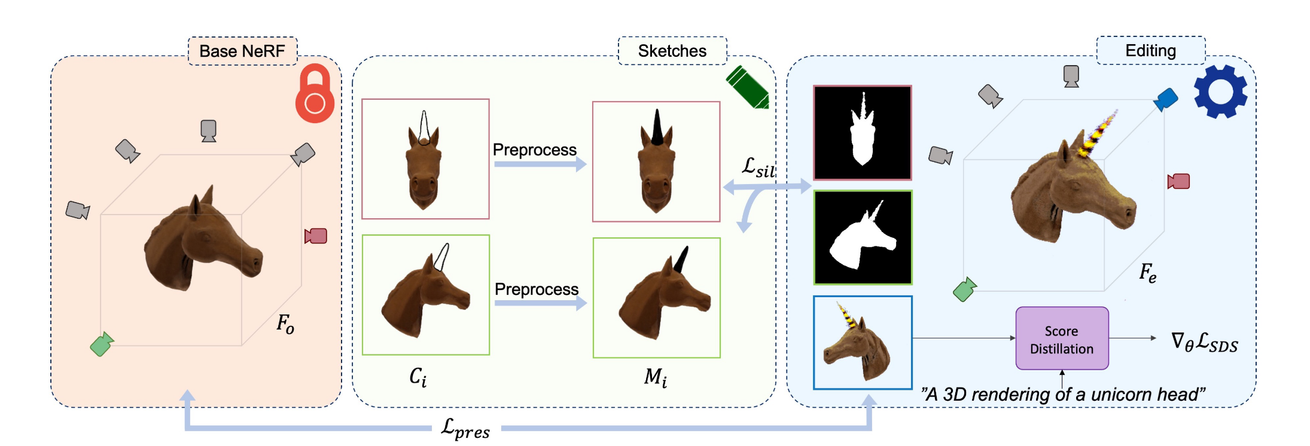
Fo : (p, ˆr; θ) → (co, σo)
기본적인 NeRF모델으로서 입력값은 3차원 공간의 위치 정보와 방향 정보이고, 출력값으로는 해당 픽셀의 Color 정보와 density 정보입니다.
랜덤한 뷰에서 렌더링한 이미지에 대해서 원하는 부분에 대해서 그려주는 Sketch 작업을 진행
- {C}N i=1: NeRF로부터 렌더링된 N개의 이미지
- 각각의 이미지에 대해서 수정하고 싶은 부분에 대한 마스크 혹은 닫힌 곡선(시작점과 끝점이 연결된 곡선)을 그립니다. 해당 스케치의 안쪽 영역이 수정 가능한 부분입니다.
- {M}N i=1: 위에서 설정한 스케치된 부분. 해당 영역을 sketch canvases라고 칭하고, 해당 시점의 뷰를 sketch views라고 칭했습니다.
는 의 복사본으로서 수정가능한 Base NeRF 모델입니다.
- NeRF 모델에 대해서 Score Distillation 기반으로 text prompt를 반영하다 보면 우리가 스케치 영역에서 많이 바뀌는 것을 확인했습니다. 이에 새로운 Loss를 제시해서 스케치한 영역과 유사하게 학습하도록 진행했습니다.
Preservation Loss
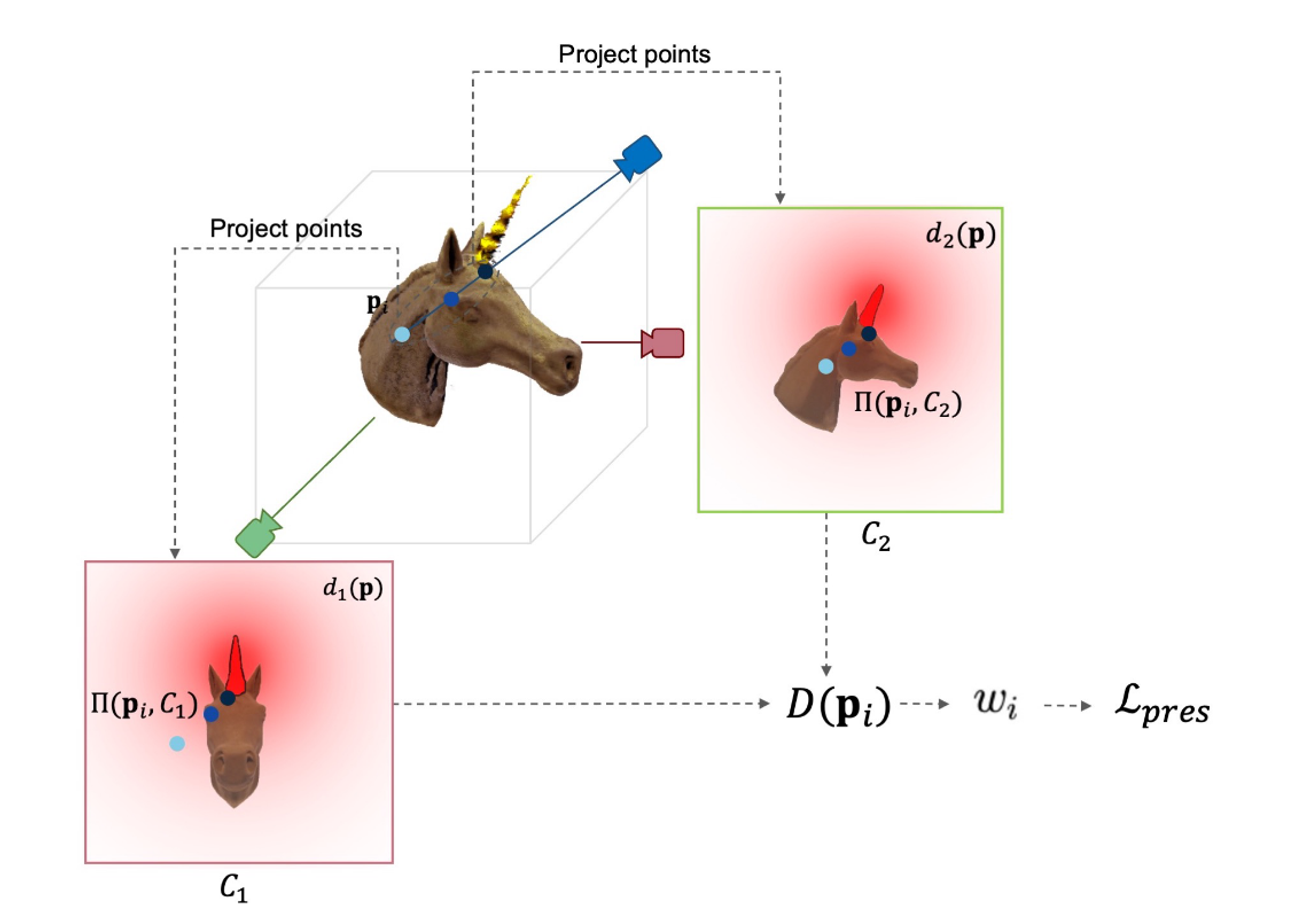
Preservation Loss()를 통해서 기존 NeRF로부터 렌더링된 이미지와 유사하게 생성하도록 loss를 추가했습니다. 핵심적인 아이디어는 3차원에서 Sampling Point 와 스케치된 부분의 거리를 계산해 해당 부분을 변경할지 정합니다. 위의 그림에 대한 설명이 없어 임의의 해석이 추가된 설명을 해드리자면 샘플링된 포인트 하늘색, 파란색, 남색에 대해서 각 뷰에 Projection시킵니다. 이후 빨간색 영역까지의 최단 거리를 계산해보면 남색은 작고, 하늘색은 클 것입니다. 이러면 남색은 수정될 가능성이 높아지고 하늘색은 수정될 가능성이 낮아질 것입니다.
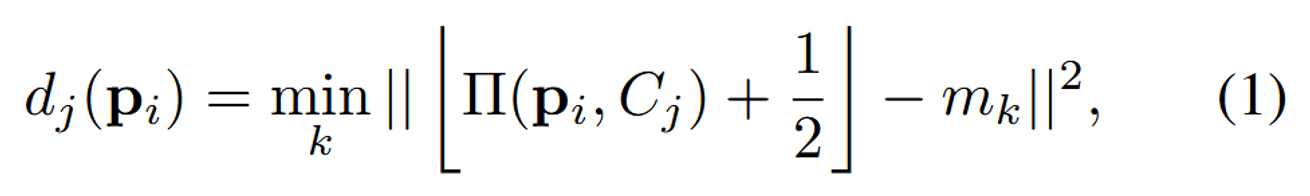
를 각 스케치 뷰 에 투영합니다. 이후 투영된 점과 마스크에서 제일 가까운 점이 값이 됩니다.

모든 픽셀에 대해서 계산한 후 평균을 취한 값이 가 됩니다.
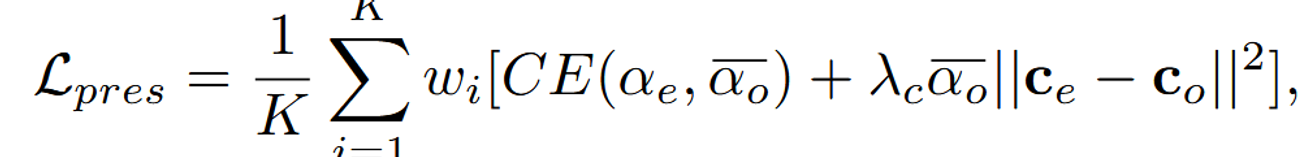
와 는 Base NeRF에서의 결과입니다. 각각 alpha blending과 color값을 나타냅니다.
와 는 우리가 학습하고 하는 NeRF의 결과입니다.
2개의 값을 비교해서 원본과 유사하도록 학습하는 Loss라고 생각하시면 됩니다.
CE는 크로스 엔트로피를, 는 색상 보존의 중요도를 제어하는 하이퍼파라미터입니다.
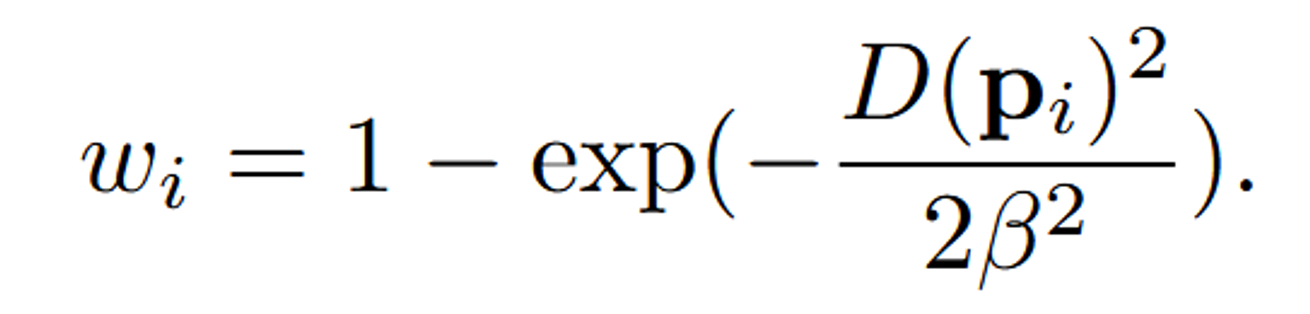
가중치를 조절할 때는 위에서 구했던 거리가 클수록 가중치값이 커지게 됩니다. 즉 원본 값을 복원하도록 설정되는 것입니다. β를 통해서 이 수치를 조절할 수 있으며 값이 작을수록 스케치된 부분만 수정하려고 할 것입니다.
Silhouette Loss
Silhouette Loss는 우리가 스케치한 영역을 수정하도록 하는 loss입니다.
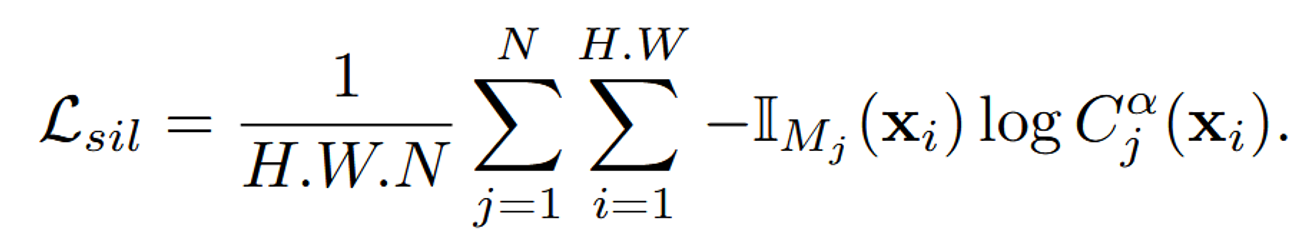
: Indicator 함수로서 픽셀 가 스케치 영역 안에 존재한다면 1, 아니면 0을 반환합니다.
: 우리가 학습하고자하는 NeRF()의 alpha blending 값으로, 해당 픽셀이 얼마나 불투명한지를 나타냅니다. 이 값이 높을수록 그 픽셀에 더 많은 객체 밀도가 존재함을 의미합니다.
Loss를 해석해 보자면 스케치 영역안에 존재하는 픽셀에 대해서만, 값을 키워야 하는 것이므로 스케치 영역안의 픽셀은 밀도를 높이는 과정입니다.
Optimization
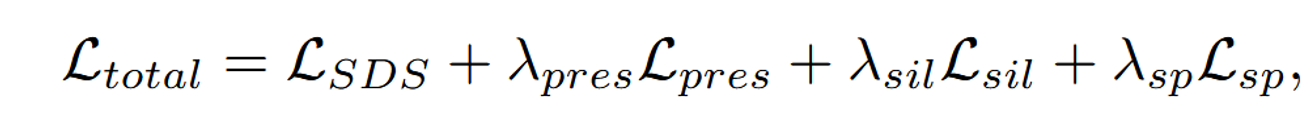
에 대한 설명은 논문에 없어 찾아본 내용을 간단히 설명해드리자면, Sparsity Loss로서 객체의 밀도가 필요한 부분에만 집중되도록 하고, 불필요한 영역에서 밀도가 발생하는 것을 억제하는 역할을 합니다.(λpres, λsil, λsp and λc to 5 × 10−6, 1, 5 × 10−4 and 5 respectively → Result)
Instant-NGP를 이용해서 neural rendering을 했습니다.
- Instant-NGP는 NeRF 모델의 학습과 렌더링을 위한 고성능 신경 렌더러입니다. 이 프레임워크는 성능과 메모리 효율성 측면에서 우수합니다.
- Occupancy Grid: Instant-NGP는 raymarching 과정에서 빈 공간을 효율적으로 건너뛰기 위해 Occupancy Grid를 사용합니다. 이 그리드는 빈 영역을 추적하여 샘플링을 효율화합니다.
- Occupancy Grid의 수정: 편집 과정에서, 기존의 Occupancy Grid를 그대로 사용하면 스케치된 영역이 샘플링되지 않아 올바른 gradient flow를 방해할 수 있습니다. 이를 방지하기 위해 스케치 마스크 M의 경계 상자를 찾아 3D 공간에서 교차점을 정의하고, 해당 영역의 Occupancy Grid를 수동으로 활성화합니다.
- Warm-up Period: 학습 초기에는 Occupancy Grid의 pruning을 피하기 위해 warm-up 기간을 정의합니다. 이 기간 동안 모델은 편집된 영역을 solidify(굳히는)하고, 빈 공간으로 간주되지 않도록 합니다.
Results
Stable-DreamFusion
- guidance scale: 100
- timesteps: (20, 980)
warm-up period
- 1000 iterations
algorithm
- 10, 000 iterations
- 30-40 minutes on a single NVIDIA RTX 3090 GPU

PSNR의 결과 지표 Table. PSNR 값은 원본이미지와의 유사도를 측정하는 지표입니다.
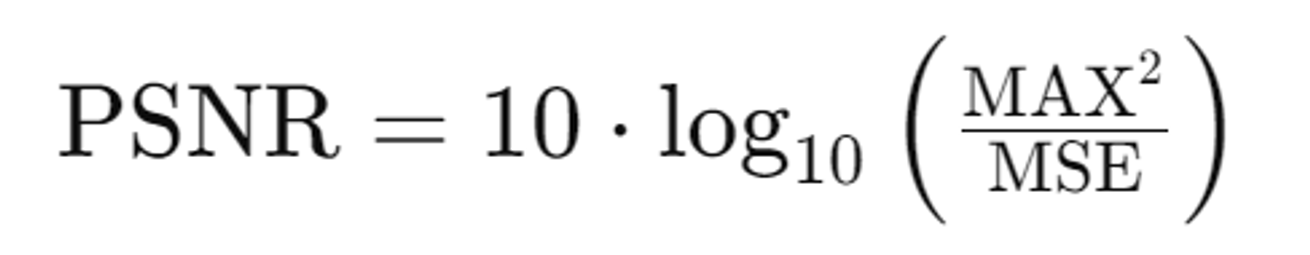
no-preserve: 를 적용하지 않은 SKED
Text-Only: Dream Fusion의 결과

해당 사진들은 2개의 뷰에서 스케치를 추가한 결과들입니다.

해당 사진은 모델을 2Step으로 사용해서 첫번째로는 빨간 넥타이를 추가했고, 두번째로는 요리사의 모자를 추가했습니다.

해당 Table은 Intersection-over-Sketch의 결과를 나타낸 것입니다. 이는 우리가 스케치 한 영역과 바뀐 부분의 교차점입니다.
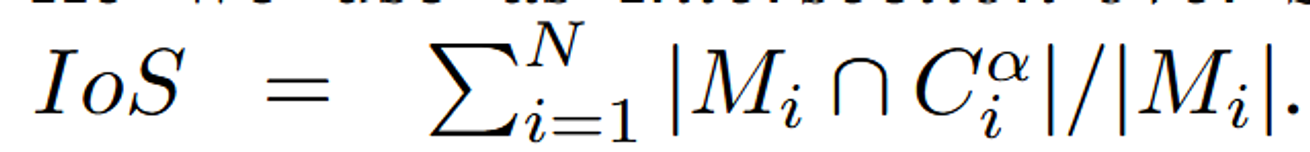
no-slilh: 를 사용하지 않은 SKED의 결과입니다.

해당 테이블은 Clip-similarity의 결과입니다. 출력된 이미지 임베딩과 입력한 텍스트 임베딩이 얼마나 유사한지를 나타내는 지표입니다.

해당사진은 Ablation study 부분입니다.
맨왼쪽에 Base Model에서 입력 이미지와 스케치를 나타내고, 이후의 Text Only는 DreamFusion모델, ,나머지 과정은 Loss를 하나씩 제거하면서 결과를 나타낸 것입니다.
확실히 preserve Loss를 추가하면 원본이랑 비슷해지고, silhouette Loss를 추가하면 스케치된 영역이 변하는 것을 알 수 있습니다.
Conclusion & Limitations
원본을 잘 보존하면서 우리가 원하는 부분에 대해서 스케치를 통해서 수정하는 모델입니다. 다른 모델들은 원하지 않은 부분도 수정했지만 해당 모델은 2가지 Loss를 추가함으로서 원하는 부분에 대해서만 수정이 가능했습니다.

하지만 SDS Loss를 사용할 때 흔히 발생하는 문제인 Multiface issue가 발생했습니다. 이 문제는 모델이 입력된 텍스트나 스케치로부터 3D 모델이나 이미지를 생성할 때, 하나의 객체에 여러 개의 얼굴 또는 특징이 반복적으로 나타나는 현상을 의미합니다. 위의 사진이 이에 대한 결과입니다.
코드구현
아쉽게 프로젝트 페이지에서 봤던 것처럼 직접 스케치하는 부분은 제공하지 않습니다.
데이터 역시 고양이 하나만 존재하고, 스케치도 하나이기 때문에 다른 text prompt를 적용하지는 못했습니다.



첫번째 뷰에서의 base, shape, sketch



두번째 뷰에서의 base, shape, sketch 사진들입니다.

최종적으로 결과는 demo 페이지에서 보이는 것처럼 나올 것입니다.
