논문링크
Summary

Voxel을 이용해서 왼쪽의 사진처럼 Local적으로 내가 원하는 부분만 텍스트를 통해서 바꿀 수도 있고, 오른쪽처럼 global하게 object를 바꿀 수도 있다. 기존 3D-object-editing에서는 geometry를 수정하거나, appearance(texture)를 수정하거나 둘중 하나만을 수정했다면 이 모델은 2가지를 한번에 수정할 수 있다. 또한 Voxel이라는 새로운 표현법을 통해 적은 연산량과, 변형 전후의 비교가 용이하다.
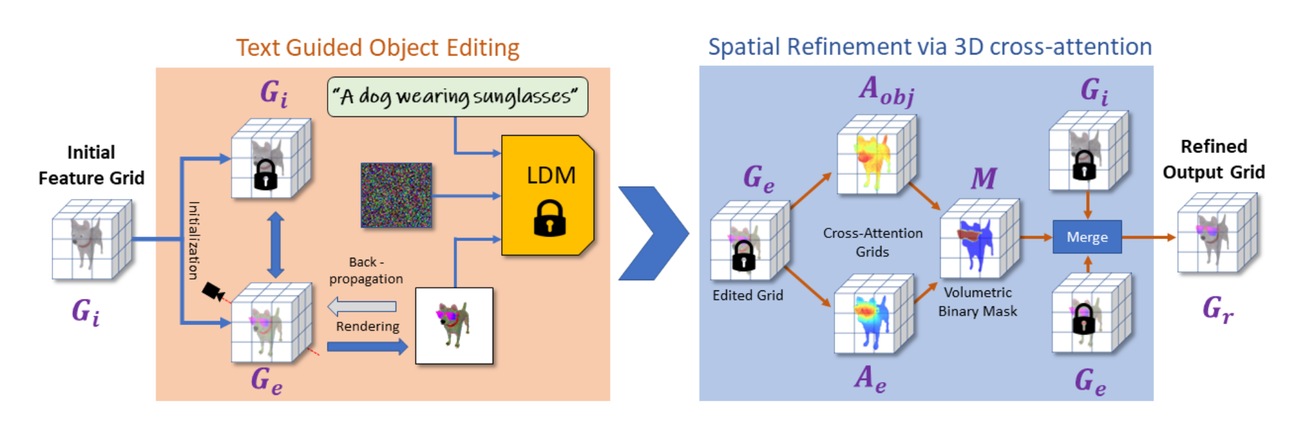
모델의 아키텍처는 다음과 같다.
- NeRF방식을 이용해 다양한 뷰의 이미지들을 기반으로 Voxel을 생성한다. 이때 각 Voxel은 4D feature vector로 표현되는데 density + Color(RGB) 값이다.
- 이후 Text Guided Object Editing(주황색 박스)를 진행한다
- 해당과정에서 우리는 의 결과를 원한다(초기값은 와 동일)
- 를 렌더링한 이미지를 LDM(Latent Diffusion Model)을 이용해서 text prompt를 적용한다.
- LDM의 출력값을 이용해서 DreamFusion의 SDS Loss로 와 Back-propagation을 진행한다.
- 값을 이용해서 Spatial Refinement via 3D cross-attention을 진행한다
- 기존의 Voxel값이 density + Color였다면 해당 과정에서는 Color 대신 probability map(cross attention결과)로 4D-vector를 이룬다.
- 위의 4D-vector의 결과로 나온 는 우리가 수정하고 싶은 부분의 영역이다. 해당 값을 기반으로 Binary Mask를 생성한다. Mask에서 우리가 수정하고 싶은 부분은 1로 수정하고 싶지 않은 부분은 0으로 생성한다(Binary Mask)
- 이후 Mask를 이용해서 0인 부분은 1인부분은 를 사용해서 최종적인 를 얻는다.
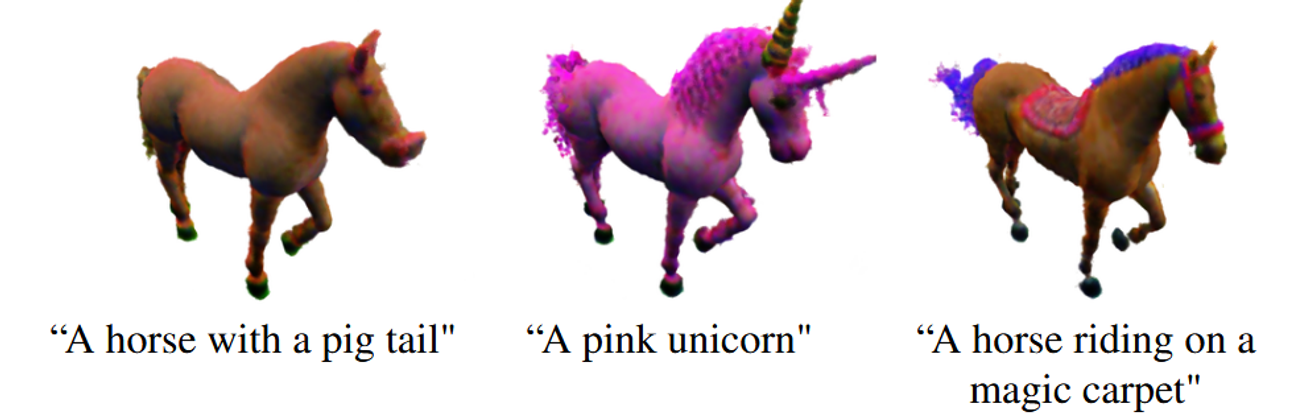
해당 모델의 한계는 NeRF에서 사용하는 View Dependent를 사용하지 않았기 때문에 시점마다 일관되지 않은 편집이 발생할 수 있다. 또한 Diffusion의 사용으로 텍스트 프롬프트가 잘 반영되지 않거나, Voxel Grid 자체의 한계로 인해서 품질이 떨어질 수 있다고 언급한다.
개인적으로 해당 모델에서 가장 유용했던 부분은 Spatial Refinement via 3D Cross-Attention 부분으로, 내가 원하는 부분에 대해서만 수정할 수 있도록 설정한 것이다.
Background
Voxel
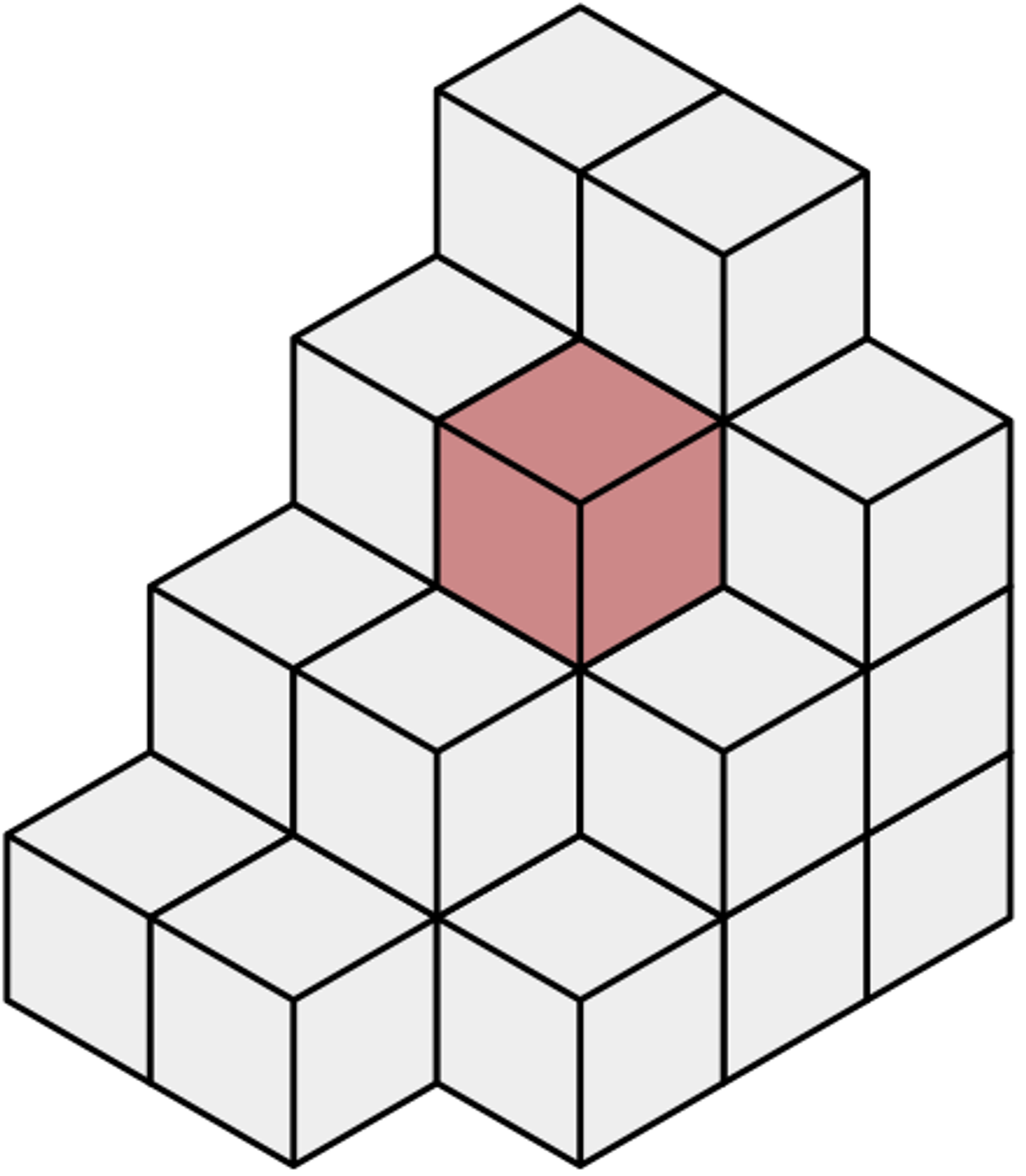
3차원 공간에서 정규 격자 단위의 값을 나타낸다. Voxel이라는 용어는 부피 (volume)와 픽셀 (pixel)을 조합한 혼성어이다. 이것은 2차원 이미지 데이터가 픽셀로 표시되는 것에 대한 비유이다. [위키백과]
친근한 예시로는 마인크래프트에서 우리가 집을 만들 때 블록을 하나하나 이용해서 만드는데, 이때의 블록 하나가 픽셀값이라고 생각하면 되고 최종적으로 완성된 집이 Voxel이라고 생각하면된다.
Voxel을 변형하기 위해서는 픽셀들의 값만 변형하면 되기때문에 변형이 쉽다.
하지만 Voxel의 경우 해상도가 증가하면 픽셀들이 많아져 연산량과 저장공간이 많아지고, 차지하지 않고 있는 픽셀 값들도 계산하기때문에 불필요한 부분의 계산이 존재한다. 그리고 표면의 외부만을 다루고자 할 때 Voxel은 내부까지 표현하고 있어 이또한 불필요한 부분을 표현하고 있는 것이다.
Geometry vs Appearance
Geometric Edits (기하학적 수정)
- Geometric edits는 3D 오브젝트의 구조나 형태, 모양을 변경하는 것을 말한다. 예를 들어, 물체의 크기, 위치, 회전, 또는 표면의 형태를 바꾸는 작업이 여기에 포함된다
- 예시: 예를 들어, 자동차 모델에서 휠의 크기를 키우거나, 캐릭터 모델의 팔을 늘리거나, 물체에 구멍을 뚫는 등의 작업이 가능하다.
Appearance 수정 (외관 수정)
- Appearance 수정은 3D 오브젝트의 색상, 텍스처, 반사율, 조명 등 시각적으로 보이는 표면의 외관을 변경하는 것을 의미한다. 오브젝트의 물리적인 형태는 그대로 두고, 어떻게 보이는지를 바꾸는 작업이다.
- 예를 들어, 같은 캐릭터 모델에 빨간색 옷을 입히거나, 나무 텍스처를 금속 텍스처로 바꾸는 것, 또는 표면에 광택을 더해 반사 효과를 추가하는 작업이 해당된다.
Abstract
- 텍스트-기반 확산 모델: Diffusion 모델은 텍스트를 입력으로 받아서 이미지를 생성할 수 있는 모델이다. 이 논문은 Diffusion모델을 3D 오브젝트 편집에도 사용하고자 한다..
- 기존 3D 오브젝트 편집: 이 방법은 이미 존재하는 3D 오브젝트를 가져와서, 그 오브젝트의 특정 각도에서 촬영된 2D 이미지를 입력으로 받는다. 그런 다음, 이 2D 이미지를 바탕으로 그 오브젝트의 3D 구조를 볼륨 기반으로 표현한다.
- 목표 텍스트에 맞춰 변형: 오브젝트의 3D 표현을 텍스트에 맞춰 변형하기 위해, "Score Distillation Sampling (SDS)"이라는 손실 함수(loss function)를 사용한다. 간단히 말해, 이 손실 함수는 모델이 텍스트에 적합한 3D 오브젝트를 생성하도록 유도하는 역할을 한다.
- 3D에서의 정규화 손실: 기존의 3D 오브젝트를 크게 변형시키지 않으면서도 텍스트에 맞게 편집하는 것이 어려운 점 중 하나이다. 이 논문에서는 2D 이미지가 아닌 3D 공간에서 직접 적용할 수 있는 새로운 정규화 손실을 제안한다. 이 정규화 손실은 원본 오브젝트와 편집된 오브젝트의 전체적인 구조가 서로 일치하도록 도와준다.
- 크로스-어텐션 볼륨 최적화: 마지막으로, 크로스-어텐션(volumetric grids)를 사용해 편집된 오브젝트의 공간적인 세부 사항을 더 정교하게 다듬는 방법을 제안하고 있다.
Introduction
3D object Editing의 어려움
- 전문적인 3D Software를 다룰줄 알아야하고, 수정과정에서 많은 시간과 노력이 필요하다
- 기존 연구들은 주로 2가지에 집중되어있다. 2가지 방법 모두 사용자가 3D 모델의 특정 부분을 조정해야 된다.
- 모델의 외관(텍스처, 스타일)을 바꾸는 것
- 모델의 모양(지오메트리)를 변형하는 것
해당 논문에서 제시하는 점
- 논문의 모델: 텍스트의 입력만으로 모델의 외관과 모양을 동시에 수정할 수 있다.
- 2D 확산 모델을 활용: 이 논문에서는 텍스트에 따라 이미지를 수정하는 데 뛰어난 성능을 보이는 2D 확산 모델을 3D 모델 편집에 활용한다. 이를 위해 Score Distillation Loss 방법을 사용해, 텍스트에 맞게 3D 모델을 변형하도록 도와준다.
- 3D 공간에서의 정규화: 모델을 변형할 때, 원래의 모양과 구조를 너무 크게 바꾸지 않으면서도 텍스트에 맞게 수정하는 것이 중요하다. 그래서 이 논문에서는 3D 공간에서 직접 이 변형을 정규화(즉, 조정)하는 방법을 사용한다.
- 가벼운 볼륨 기반 표현: 해당 논문에서는 제목에서도 알 수 있듯이 Voxel이라는 표현법을 이용해서 3D 객체를 표현했다. 첫번째로 Voxel은 계산량이 적어서 빠른 reconstruction이 가능하다. 두번째로 모델의 변형 전후에 대해서 비교가 용이하다. 2가지 이유를 기반으로 Voxel 표현법을 사용했다고 밝혔다.
- 2D 크로스-어텐션 활용: 편집할 영역을 더 정확하게 정교화하기 위해 2D 크로스-어텐션 맵을 사용했다. 이 맵은 텍스트에 따라 수정될 영역을 대략적으로 표시해주고, 이 정보를 3D 공간으로 옮겨서 더 정확한 편집이 가능하도록 했다. 이를 통해 텍스트에 따라 수정해야 할 부분과 그대로 유지할 부분을 잘 구분할 수 있게 됐다.
Related Work
Text-driven Object Editing
CLIP이나 Diffusion모델을 기반으로 텍스트를 이용해서 2D 이미지를 수정한 연구는 많이 존재했다. 하지만 3D 이미지에 대한 연구는 많지 않았다.
Geometric 변형
기존에 텍스트를 이용해서 3D object를 편집한 연구로는 LADIS와 ChangeIt3D가 존재했지만, 해당 논문들은 모두 특정 데이터셋에 특화되어있었다. 또한 geometric의 변형은 가능했지만 appearance의 변형은 불가능하다.
Appearance 변형
일부 방법들은 3D 모델의 2D 이미지 Projection을 이용해, 텍스트와 일치하는지 확인하면서 3D 모델을 수정해왔다. 예를 들어, Text2Mesh와 Tango 같은 방법들은 텍스트를 기반으로 3D Mesh의 스타일을 바꾸거나 조명을 수정하는 작업을 했다.
또한 TEXTure 모델에서는 depth-to-image diffusion model을 이용해서 3D mesh의 텍스처를 변형했다.
하지만 이들 방법은 주로 텍스처링에 집중되어 있어서, 모델의 모양을 크게 바꾸거나 새로운 구조를 추가하는 데는 한계가 있다.
Neural Field Editing
NeRF같은 경우 여러 View에서 찍은 이미지들을 이용해서 물체나 장면을 3D로 표현한다.
이 방식은 스타일 변환이나 텍스트 기반 편집에 사용되었고, 2D 이미지를 편집함으로써 3D 모델을 수정하는 방법도 있었다. 하지만 이런 방법들은 3D Mesh를 직접 수정하기에는 여전히 어려움이 있었다.
NeRF모델 자체가 3D Mesh에 대하나 표현이 아닌 하나의 뷰에서 봤을 때의 3D object의 color나 density값을 갖고 있기때문에 NeRF의 결과를 Mesh로 변환한 후 해당 값을 기반으로 수정을 진행해야되나 이는 부정확하거나 비효율적이다.
Text-to-3D
DreamFields나 DreamFusion같은 모델들은 radiance fields를 optimize하면서 Text를 기반으로 object의 geometry한 부분이나 color를 결정했다. Magic3D는 DreamFusion의 느린 Optimization 속도를 극복하기도 하며 이 분야는 꾸준히 발전되고 있었다.
하지만 해당 논문들은 모두 Text를 기반으로 새로운 3D Object를 만드는 것이었다면, 이 논문은 이미 주어진 Object에 대해서 Text를 기반으로 수정하는 것이다.
Method
Grid-Based Volumetric Representation
사용되는 3D grid G는 각 Voxel마다 4D feature vector를 갖고 있다. RELU를 기반으로 생성되는 spatial density(geometry 정보), Sigmod를 기반으로 생성되는 RGB 3가지 정보(appearance 정보)
일반적인 방식과 다르게 View dependent 효과를 사용하지 않았다고 한다. View dependent는 어느 view에서 보느냐에 따라서 색깔값이 달라지는 효과인데, 해당 방식을 이용했을 때 2D diffusion 모델에서 부자연스럽게 보이는 결과 때문에 사용하지 않았다고 한다. 조금 더 자세히 설명하면 diffusion 모델 자체가 단일 이미지 생성에 초점을 맞췄는데, View dependent 효과를 추가한다면 특정 view에서는 자연스럽게 보일 수 있지만, 다른 각도에서는 부자연스러운 결과를 제시한다.
입력한 Object를 Grid로 변형하기 위해서 NeRF에서 사용하는 방식과 유사하게 이미지와 카메라의 위치 정보를 활용한다. 이 과정에서 여러 각도에서 찍은 사진을 바탕으로 3D 오브젝트의 구조를 재구성한다. 하지만 이때 Positional Encoding(PE)는 사용하지 않는다. Grid로 변환할 때 MLP방식을 사용하는 것이 아니라 interpolation방식을 사용하기 때문이다.
Grid로 변형하는 과정에서는 L1 Loss를 이용해서 생성된 이미지와 입력 이미지간의 차이를 측정한다. 이부분도 처음에 헷갈렸는데 입력값으로 3D object가 들어가는게 아니라, 3D 오브젝트를 촬영한 이미지들이 들어가기 때문에 해당 이미지와 생성된 이미지간의 차이를 측정하는 것이다.
Text-guided Object Editing
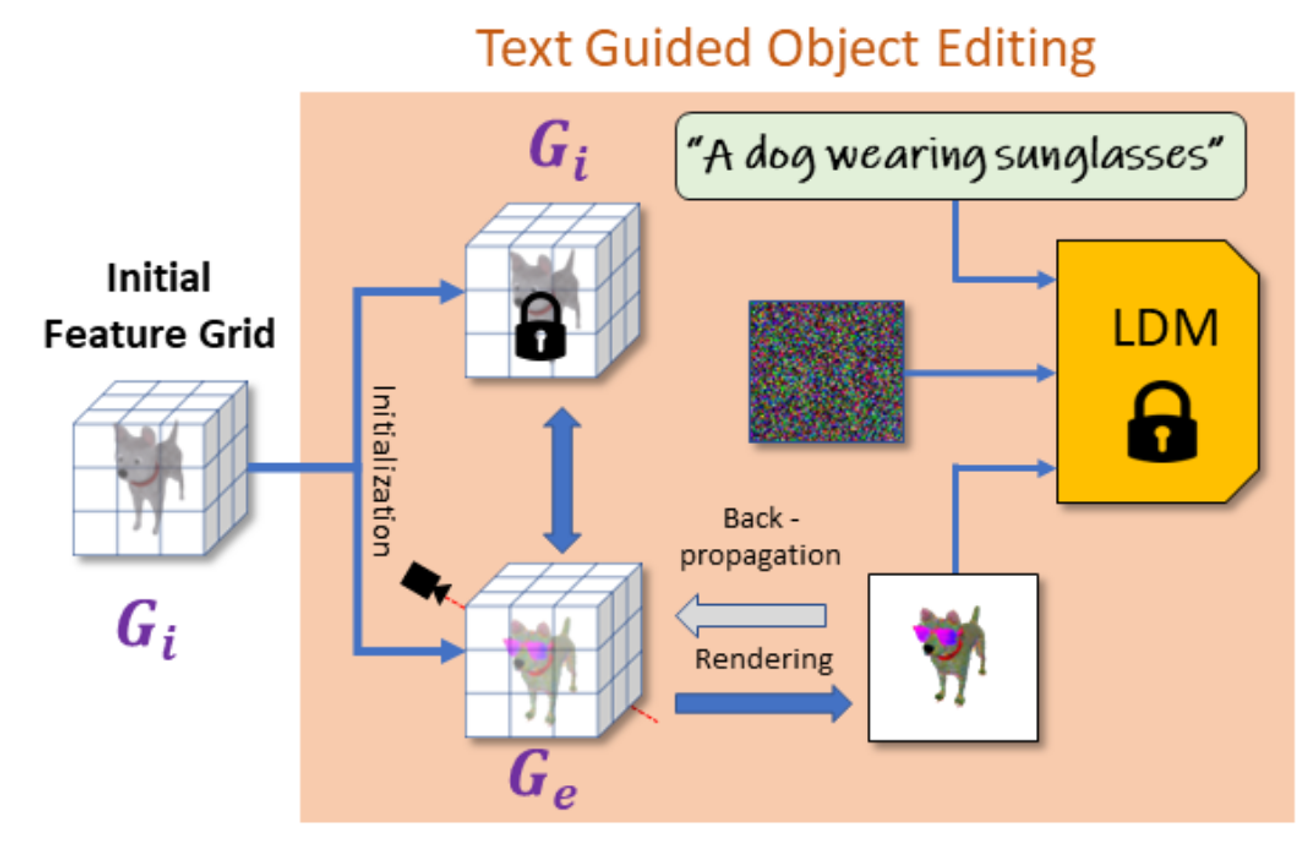
그림에 대한 설명을 진행하고 각 부분이 어떻게 학습됐는지 자세히 아래에 설명하겠다.
- 이전에 생성한 Grid 값인 를 복제해서 초기값인 를 생성한다.
- 의 Grid값을 Rendering을 진행해 2D image로 변형한다.
- 이후 2번의 결과 이미지와 Text prompt를 사용해서 LDM(Latent Diffusion Model)을 이용해서 렌더링된 이미지가 text에 부합하게 생성되도록 변형한다.
- LDM의 결과와 렌더링된 이미지를 SDS Loss를 기반으로 Back-propagation을 진행한다.
목표: 값을 Text prompt에 적합한 형태로 변형한 를 생성하자!
Generative Text-guided Objective
SDS(School Distillation Sampling) loss
DreamFusion에서 나온 loss값으로 2D 이미지를 생성하는 모델의 지식을 3D 오브젝트로 전이(distill)하는 데 사용된다.
SDS loss에 대한 수식은 아래와 같다. 우선 노이즈가 추가된 이미지()를 생성한다.
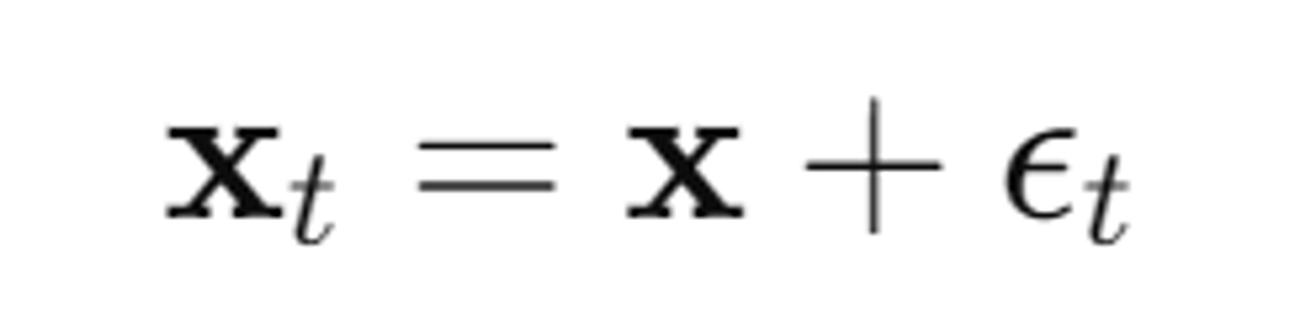
- : 시간 단계 t에서 노이즈 ϵt가 추가된 이미지
- : 원본 이미지(생성된 이미지)
- : 시간 단계 t에서 노이즈를 추가하는 함수 Q(t)의 출력값
다음으로 SDS loss의 Gradient를 계산한다.
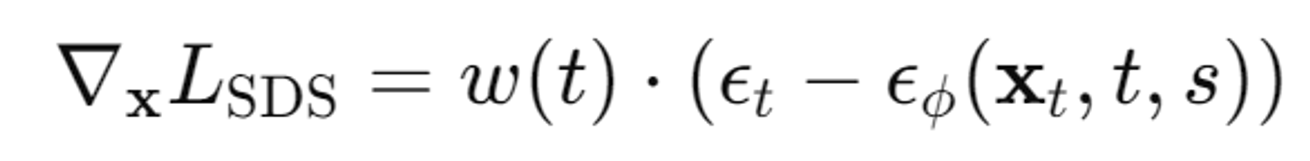
- : 손실 함수 LSDS의 그래디언트(즉, 각 픽셀별 손실의 변화율)
- w(t): 시간 단계 t에 따른 가중치 함수. 이 함수는 특정 시간 단계에서 손실에 더 큰 영향을 주거나 줄이는 역할
- : 이전 단계에서 추가된 실제 노이즈
- : 사전 학습된 DDPM 모델이 예측한 노이즈. 이 모델은 입력 이미지 xt, 시간 단계 t, 텍스트 프롬프트 s를 기반으로 노이즈를 예측
해당 논문에서는 annealed SDS loss를 사용했다. SDS loss와의 차이점은 학습 초기에는 큰 t(time step)를 사용해서 이미지의 전반적인 특징(low frequency)에 집중한다. 학습 후반에는 t값을 줄여서 이미지의 세부적인 특징(high frequency)를 학습할 수 있도록 해준다. 한마디로 차이점을 설명하면 t를 점진적으로 줄인다는 점이다.
논문에서의 설명은 여기서 끝났지만, 위의 그림에서 대략적인 구조를 통해서 설명했듯이 annealed SDS loss는 결론적으로 렌더링된 이미지가 text prompt가 반영된 LDM의 결과와 비슷해지도록 학습하는 과정에서 사용된다.
Volumetric Regularization
원본 Object와 너무 많이 바뀌거나, 뷰에 따라서 너무 많이 변하는 것을 방지하기 위해서 논문에서는 Volumetric Regularization을 사용했다고 한다.
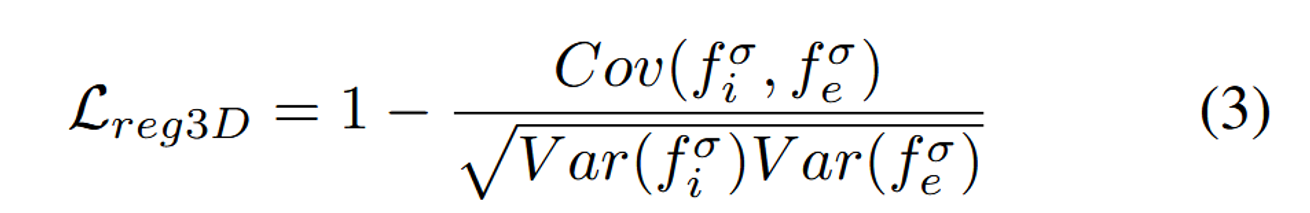
의 density feature값인 와 의 density feature값인 의 상관관계를 비교하면서 진행된다.
상관관계가 높을수록, 수정된 그리드가 원래 그리드와 더 유사하게 유지된다. 따라서 오른쪽 분수에 음수값을 붙여서 해당 값이 클수록 Loss가 작아지도록 진행된다.
Spatial Refinement via 3D Cross-Attention
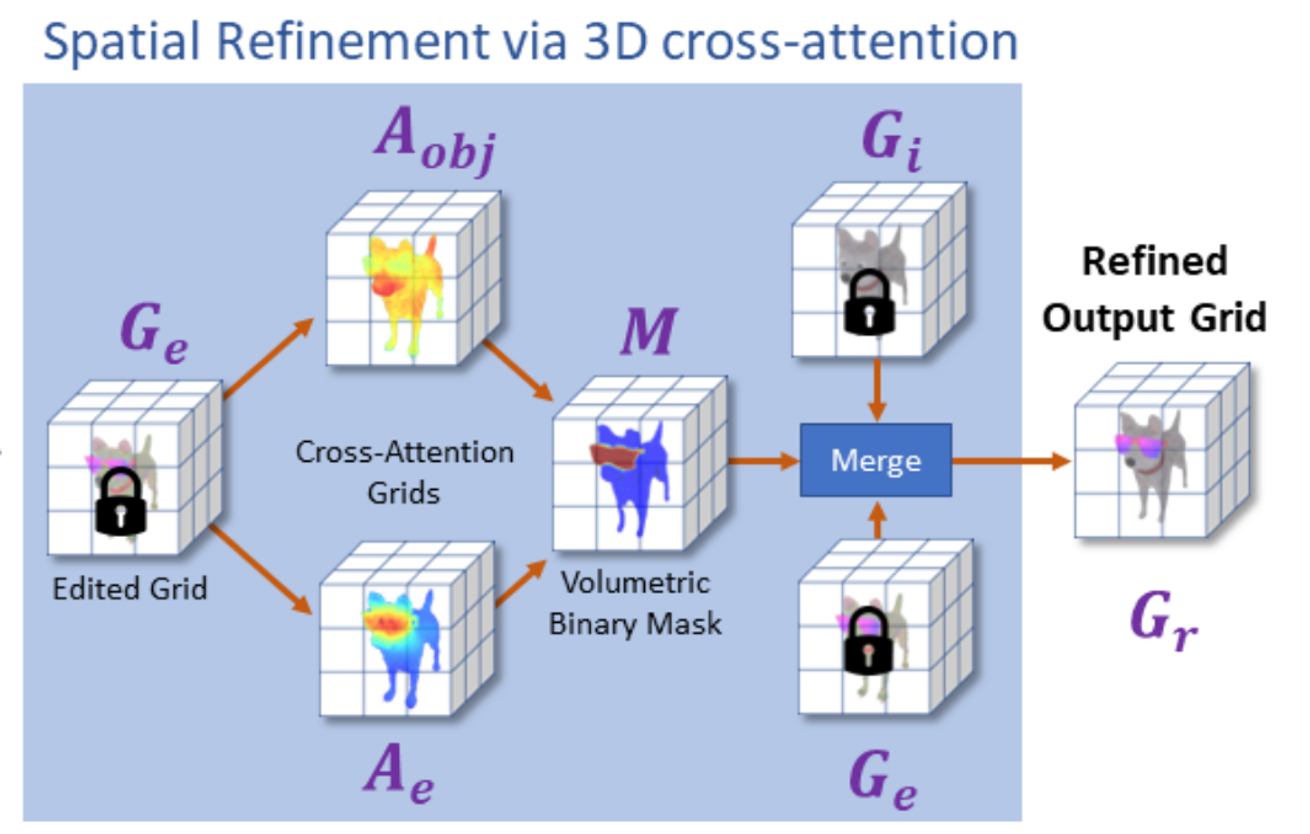
해당 과정에대해서도 전반적인 구조를 보고 아래에 더 자세한 설명을 하겠다.
우선 이전 Text-guided Object Editing 과정을 통해서 우리는 Text에 알맞은 형태의 Object를 생성할 수 있었다. 하지만 우리는 Object중에서 특정 부분만을 수정하길 원한다. 예를들어서 기존 강아지 Object에 대해서 “선글라스를 쓴 강아지를 만들어줘!”라고 하면 강아지는 그대로 두고 선글라스만 생성해야된다. 결론적으로 Spatial Refinement via 3D Cross-Attention은 우리가 원하는 부분에 대해서만 수정하기 위해서 수정할 부분에 대한 Mask를 생성하고 해당 부분만 나타내는 것이다.
- Cross-Attention Grids를 통해서 우리가 원하는 부분에 대한 Binary Mask를 얻는다.
- 해당 Mask를 기반으로 이전단계에서 생성된 와 를 합쳐서 최종 결과 를 얻는다.
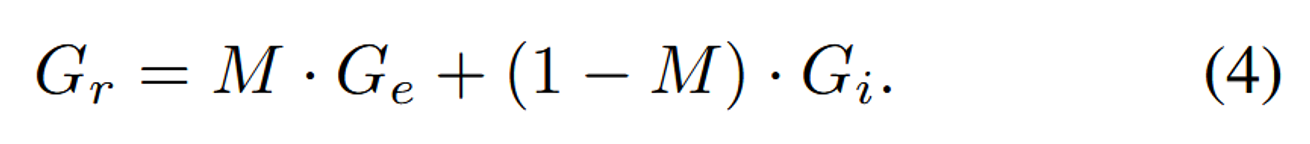
위에서 설명한 모델 단계에서 2번에 해당하는 수식이다. Binary Mask(M)을 이용해서 우리가 변경하고싶어하는 부분(M)에 대해서는 를 적용하고, 우리가 변경하고 싶지 않은 부분(1-M)에 대해서는 를 적용하는 것이다.
Cross-Attention Grids
Cross-Attention은 텍스트 프롬프트의 각 단어가 이미지의 어느 부분과 관련 있는지를 나타내는 정보를 제공한다. 예를들어서 선글라스라는 단어는 이미지에서 선글라스 위치와 관련된 영역을 강조한다.
이렇게 Cross-Attention을 통해서 얻은 probability Map과 초기에 우리가 를 생성한 것처럼 density를 ReLU 함수를 양수로 만들고 기존에는 우리가 Color를 사용해서 4D-vector로 이용했다면 이번에는 probability Map을 이용해서 L1 Loss를 진행한다.
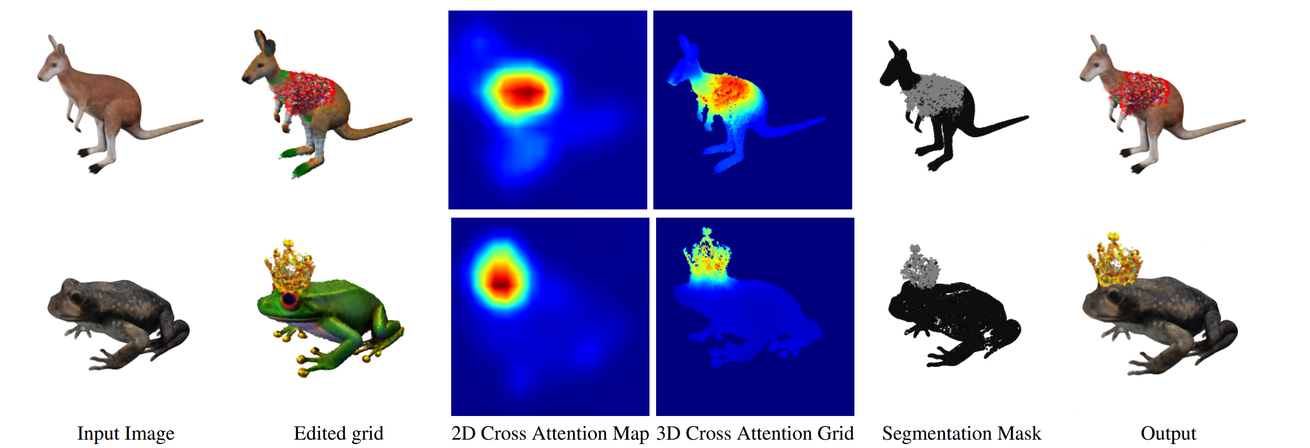
그림을 보면서 조금더 자세히 설명 하겠다.
1번째 열에서는 우리의 입력값을 Grid형태로 나타낸 이다.
2번째 열에서는 Text-guided Object Editing의 결과인 이다.
3번째 열은 2D image에 대해서 Cross Attention Map을
4번째 열은 위의 probability Map을 이용해서 생성한 3D cross attention grid
5번째 열은 우리가 변경하고 싶은 부분을 나타내는 Segmentation Mask
6번째 열은 최종 결과이다.
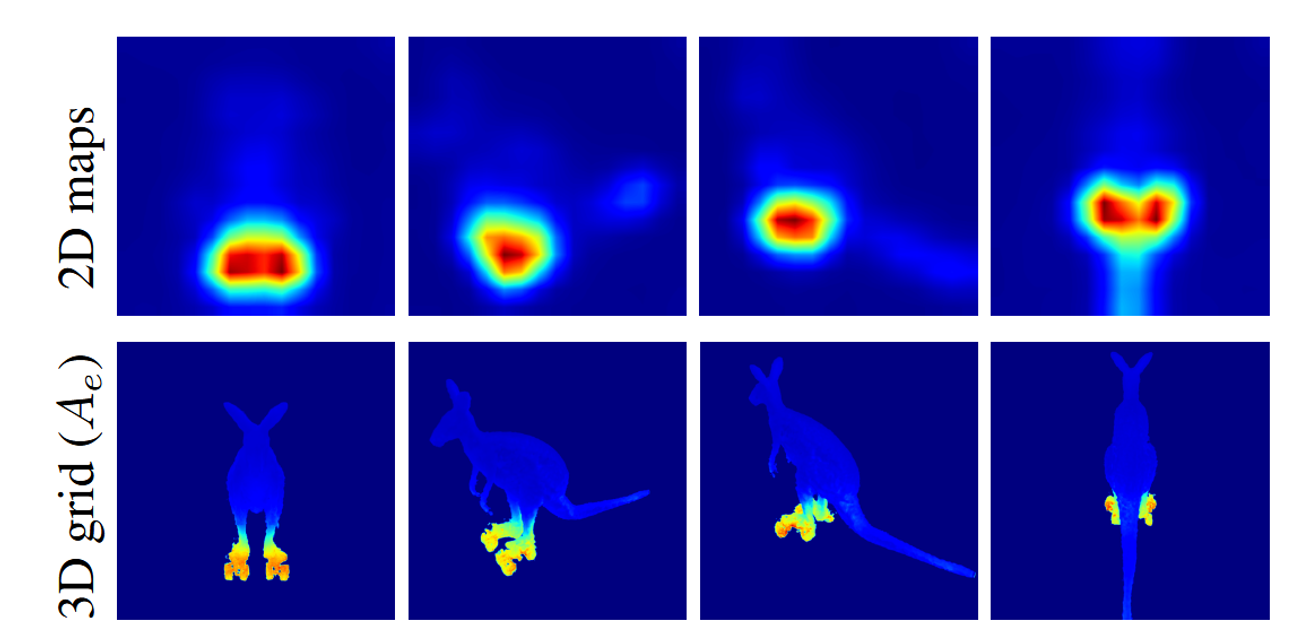
이그림을 통해서 다양한 시점의 이미지들을 통해서 Probability Map을 얻고 이를 기반으로 3D grid를 생성했을 때의 결과를 보여준다. 해당 이미지는 “캥거루가 롤러스케이트를 신고있어”에 대한 결과이다.
Binary Mask
위의 결과로 나온 3D probability fields를 이용해서 우리는 Binary Mask(M)을 얻는다.
Binary Mask를 생성하는 과정에서는 energy minimization에 기반한 seam-hiding segmentation 알고리즘이 사용된다
energy minimization는 2개의 Term이 존재한다.
- unary term: 각 Voxel이 텍스트 프롬프트와 얼마나 관련이 있는지를 평가. 이를 통해 수정해야 할 부분을 결정한다. 예를 들어, "sunglasses"라는 텍스트 프롬프트가 주어졌을 때, 유니터리 항은 각 Voxel이 선글라스 부분에 속하는지를 판단한다.
- smoothness term: 수정된 영역과 수정되지 않은 영역이 자연스럽게 이어지도록 하는 역할을 한다. 즉, 마스크의 경계를 부드럽게 만드는 데 기여한다.
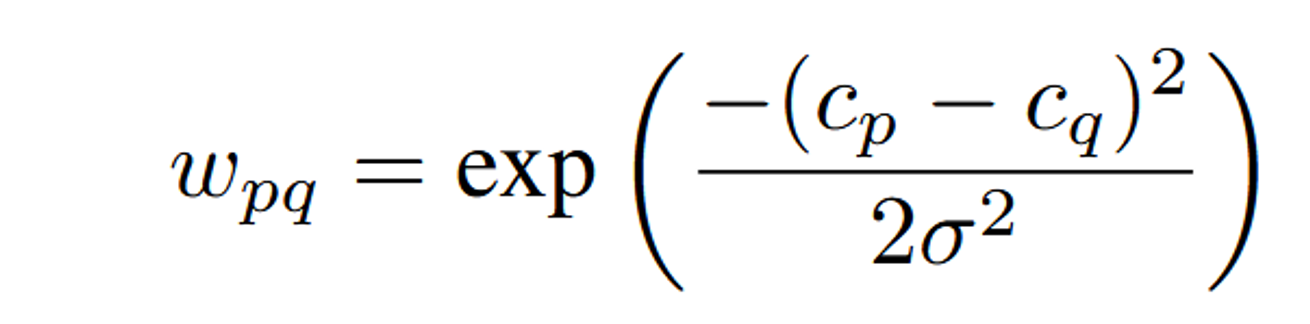
위의 수식은 smoothness term을 나타내는데 인접한 픽셀 p와 q에대해서 색깔값의 차이를 기반으로 가중치를 구하는 것이다. σ값이 클수록 색상 차이에 덜 민감하게 되고, 작을수록 색상 차이에 민감하게 되는데 여기서는 실험적으로 0.1로 설정했다.
: 우리가 기존에 Cross-Attention Grids를 통해서 얻은 값으로 텍스트 프롬프트에서 수정하고자 하는 특정 부분(예: "sunglasses")과 관련된 영역을 강조한다. 이 맵은 주로 unary term에서 사용된다.
: 오브젝트 전체와 관련된 영역(예: “dog”)을 나타낸다. 이 맵은 오브젝트의 기본적인 구조를 강조하며, smoothness term에서 사용된다.
Experiments
5가지 텍스트 프롬프트를 이용해서 학습을 진행했다.
- “A ⟨object⟩ wearing sunglasses”.
- “A ⟨object⟩ wearing a party hat”.
- “A ⟨object⟩ wearing a Christmas sweater”.
- “A yarn doll of a ⟨object⟩”.
- “A wood carving of a ⟨object⟩”.
위의 3개는 local edits & 아래 2개는 global edits
평가지표
CLIP Similarity()
CLIPSim은 편집된 3D 오브젝트와 타겟 텍스트 프롬프트 사이의 의미적 유사성을 측정한다. 즉, 편집 결과가 주어진 텍스트 프롬프트와 얼마나 잘 일치하는지를 평가하는 것이다.
코사인 유사도 측정
텍스트 프롬프트와 출력된 3D 오브젝트의 이미지 벡터 간의 코사인 유사도(cosine similarity)를 측정한다. 이 유사도는 두 벡터가 얼마나 비슷한 방향을 가지는지를 나타낸다.
- 0에 가까우면 의미적으로 비슷하지 않다는 것을 의미하고, 1에 가까우면 의미적으로 매우 비슷하다는 것을 의미한다.
CLIP Direction Similarity()
CLIPDir은 편집된 3D 오브젝트가 원래의 오브젝트에서 목표 텍스트 프롬프트로 어떻게 변화했는지를 평가한다. 이 지표는 변화의 방향이 텍스트 프롬프트의 의미와 얼마나 일치하는지를 측정한다.
코사인 유사도 측정
- 여기서는 각 인코딩된 벡터의 변화 방향을 측정한다. 즉, "a dog"에서 "a dog wearing a hat"로 가는 텍스트의 변화 방향과, 원래 이미지에서 편집된 이미지로의 변화 방향이 얼마나 유사한지를 평가한다.
- 코사인 유사도는 두 방향이 얼마나 일치하는지를 나타낸다. 두 벡터의 방향이 유사할수록 CLIPDir 점수는 높아진다.
FID: Inception network를 이용해서 feature를 추출하고 이 추출된 값을 기준으로 측정되는 지표
FIDInput: 편집 후의 출력 이미지와 원래 입력 이미지 사이의 시각적 차이를 평가합니다. 편집이 얼마나 큰 변화를 가져왔는지 알 수 있다.
FIDRec: 편집 후의 출력 이미지와 초기 재구성 그리드에서 생성된 이미지 사이의 시각적 차이를 평가합니다. 모델의 표현력이 얼마나 강력한지 알 수 있다.
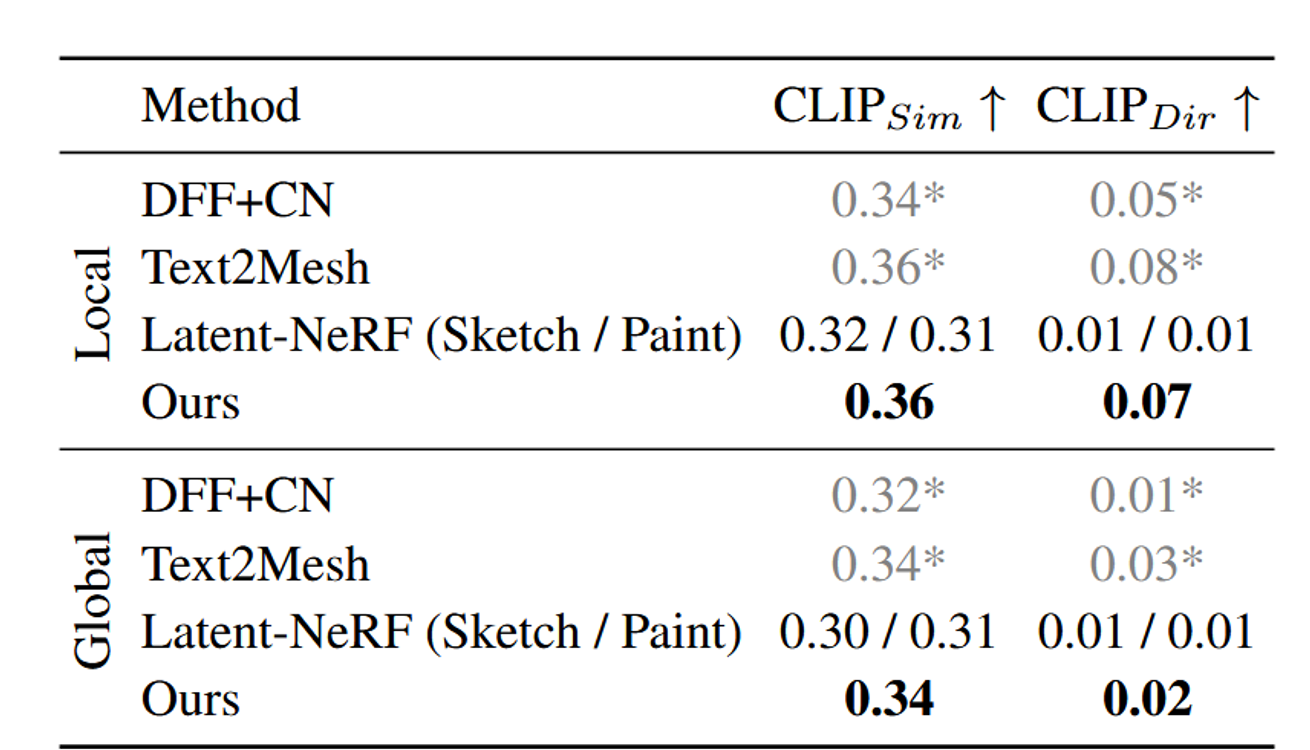
다른 모델들과 비교해서 원본에 대한 유사도도 높거나 비슷하고, 변화 방향에 대한 일치도도 높거나 비슷한 것을 확인할 수 있다.
추가적인 실험 설명은 생략하고 결과에 대해서 시각적으로 아래에 제시하도록 하겠다.


위의 사진은 RF(ReLU-Fields)와 DVGO(ReLU-Fields와는 다른 3D 표현 방식)을 비교 했다.
해당 비교를 통해서 논문에서는 다양한 Voxel 기반 표현 방식에서도 효과적으로 동작할 수 있음을 보여준다. 즉, 제안된 방법은 3D 장면을 표현하는 방식에 구애받지 않고 여러 방법에서 잘 작동한다는 것을 의미한다.
Ablation Study


위의 사진과 Table의 결과를 통해서 와 SR(Spatial Refinement via 3D Cross-Attention)의 중요성을 강조하고 있다.
를 제거한 경우 L2 Regularization Loss를 사용했다. 의 유무에 따라서 우선 이미지를 보면 노이즈가 많이 껴있는 것을 볼 수 있다. 또한 Table에서는 수치들 중 특히 부분의 성능이 높아진 것을 통해 원본과의 유사도를 확실히 높일 수 있는 방법인 것을 증명했다.
SR의 값의 유무를 통해서는 이미지를 보면 선글라스 부분을 제외하고도 다른 부분이 많이 변하는 것을 확인할 수 있다. 그러나 SR 모듈이 있을 때, 편집된 결과가 텍스트 프롬프트와의 유사성이 약간 떨어질 수 있다. 이는 편집 신호보다 입력 오브젝트와의 유사성을 더 중요시하기 때문이다.
Limitation
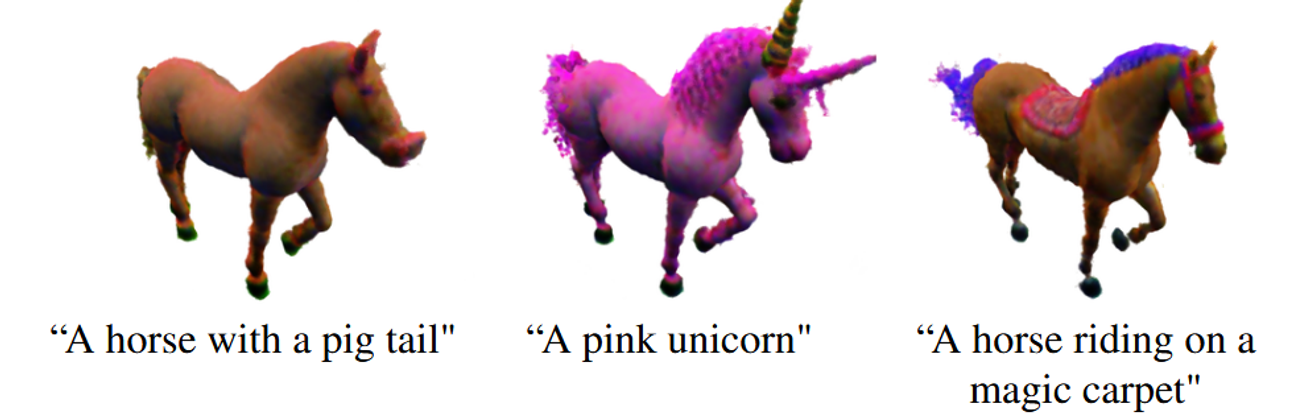
- 시점 간 불일치 문제: 다양한 시점에서 오브젝트를 편집할 때, 동일한 오브젝트의 다른 위치에서 일관되지 않은 편집이 발생할 수 있다.
- 속성 연결 오류: 모델이 텍스트 프롬프트에서 속성을 잘못된 대상에 적용하는 경우가 발생할 수 있다. 이는 대규모 Diffusion 기반 모델에서 자주 발생하는 문제다.
- Voxel Grid 표현의 한계: 복잡한 장면을 모델링할 때 Voxel Grid 표현 방식의 한계로 인해 품질이 떨어질 수 있다. 다른 기술을 사용해 이 문제를 해결할 수 있다.
