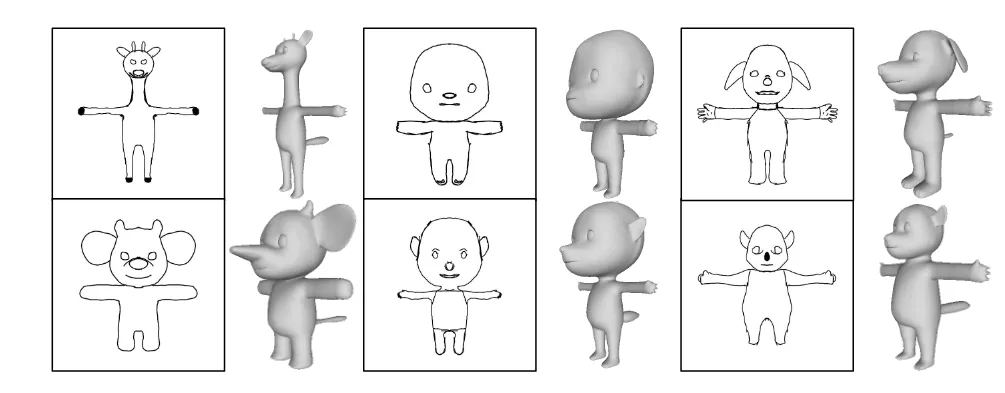
RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset[2023 CVPR]

게임이나 애니메이션에서 자주 나오는 두발로 걷는 만화 캐릭터(biped cartoon character)를 생성하는 연구에 대해서 제안했습니다. 하나의 이미지 심지어 스케치로도 3D 캐릭터를 만들고, 그 캐릭터로부터 3D 애니메이션을 생성할 수 있습니다.
기존의 모델에서 얼굴의 코나 귀처럼 작고 중요한 부분이 뭉개지는 문제를 도입하기 위해 부위별 정보를 더 잘 반영하는 part-sensitive texture reasoner도 도입했습니다.
https://github.com/zhongjinluo/RaBit/issues/4
참고로 해당 코드를 돌려보려고 했는데… 저작권 이슈로 BiCarNet은 공개하지 않을 계획이라고 저자가 밝혔습니다. 데이터셋 역시 현재는 404가 뜨고 있습니다.
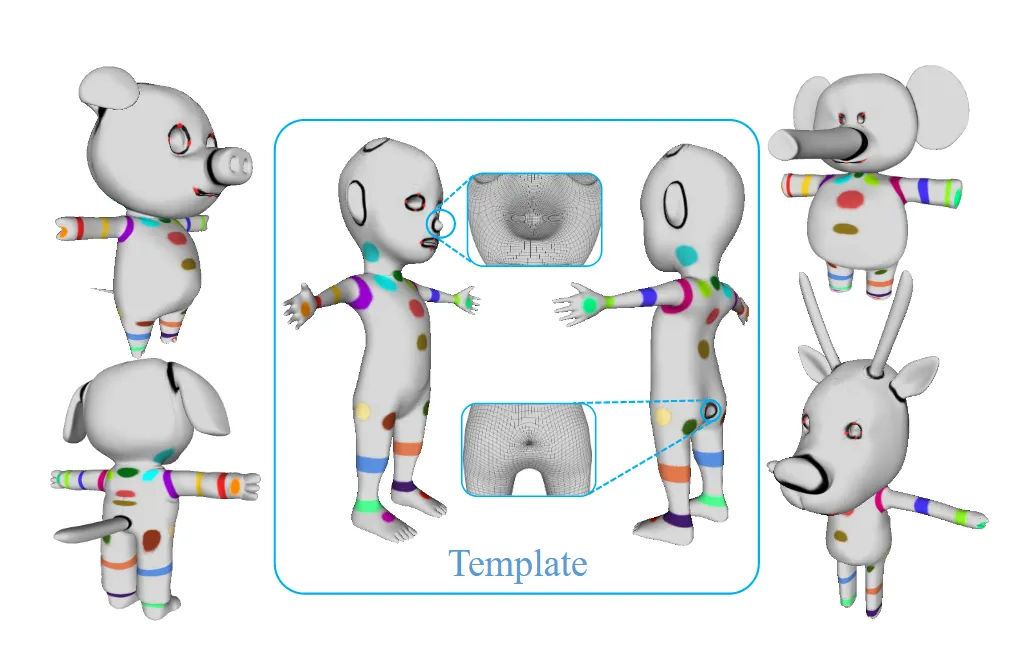
Dataset

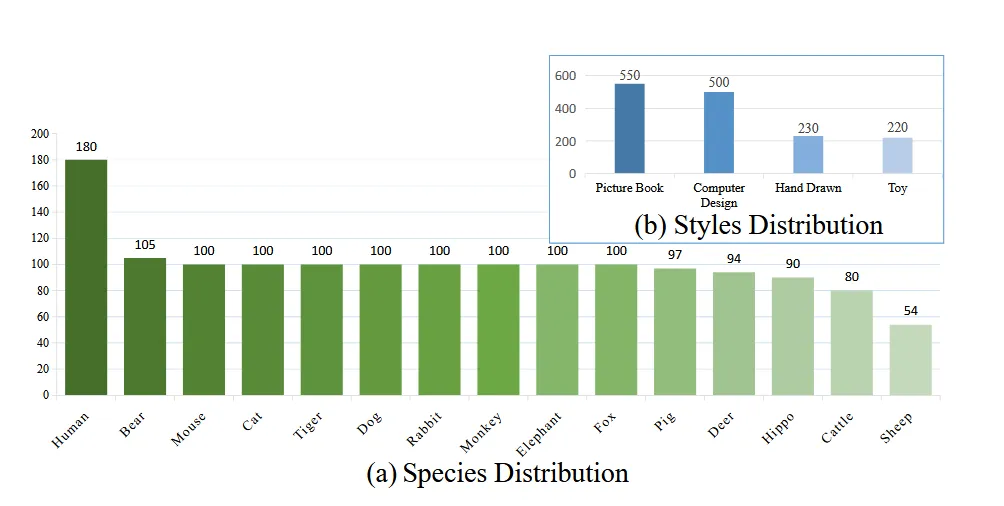
Data가 위와 같이 정말 다양하게 존재한다는 것을 시각화 한 것입니다. 아쉽게 현재는 데이터셋을 이용할 수 없어 해당 부분의 설명은 생략하도록 하겠습니다. 총 데이터의 개수는 1500개로 두발로 서있는 카툰 이미지를 타겟화 해서 만든 3D Object라고 생각하시면 됩니다.
Parametric Modeling
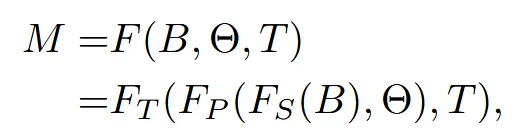
생성되는 캐릭터는 위와 같이 정체성을 나타내는 B, 포즈를 나타내는 마지막으로 색깔 정보인 texture를 반영하는 T 이렇게 3가지 파라미터로 구성되어 있습니다. 마지막 수식에 나타난 것처럼 B를 이용해서 물체를 만들고, 여기에 pose 정보를 반영한 뒤 마지막으로 texture 정보를 입히도록 모델을 구성했습니다.
Shape Modeling
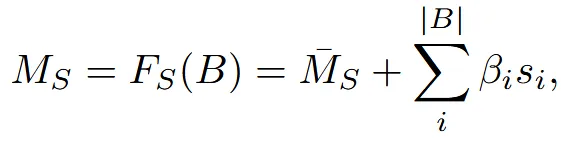
SMPL에 영감을 받아서 사람이나 캐릭터는 결국 어떠한 baseline을 기반으로 조금씩 형태가 변형된 결과라는 생각으로 위와 같은 수식을 만들었습니다. 는 평균 shape를 기반으로 각 변화 방향에 대해 얼마나 바꿀지에 대한 파라미터 와 각기 다른 방향의 모양 변화 벡터(코가 길어지는 변화 등) 를 이용해서 우리가 원하는 최종적인 값을 구합니다. 일반적으로 B는 100개로 설정했다고 나와있습니다. 는 3DBiCar 데이터셋 1050개를 PCA 학습을 통해서 나타냈습니다.
가운데 template mesh로부터 PCA를 이용해 얼마나 mesh를 변형할지 학습하게 됩니다.
Pose modeling
Rabit 모델은 캐릭터의 자세를 바꾸기 위해 Linear Blend Skinning(LBS) 기법을 사용합니다. 3DBiCar 데이터셋에는 이미 skeleton과 skining weights가 적용되어 있기 때문에 여기에 LBS를 적용해서 우리가 원하는 포즈를 얻겠다는 것 입니다.
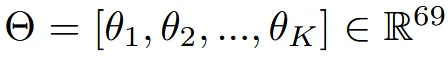
바꾸고 싶은 pose에 대한 정보는 위와 같이 축 기반으로 표현되기 때문에 3차원 정보를 갖는 23개의 joint 총 69차원의 파라미터를 이용해서 들어옵니다. 각 joint의 3차원 정보는 Rodrigues’ formula를 통해서 Rotation mtatix로 변환할 수 있습니다.
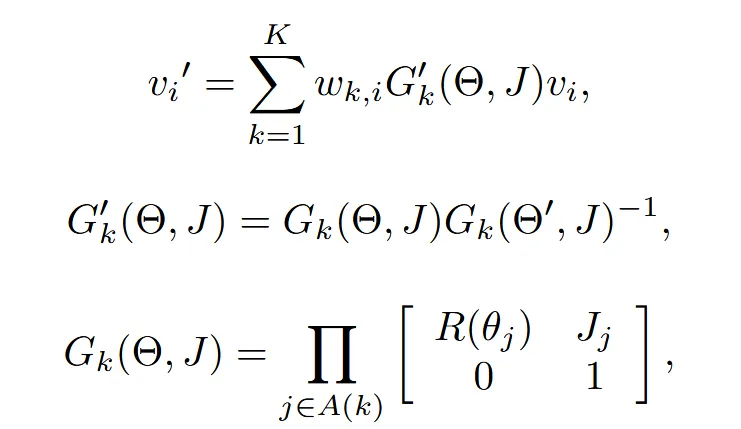
입력 vertex 는 위와 같은 과정을 거쳐서 포즈 정보가 반영된 을 얻습니다. 위의 수식을 간단히 설명드리면 는 k번째 global transformation으로 자신의 회전뿐만 아니라 부모 관절의 누적 회전도 포함하는 값입니다. 이후 2번째 수식에서 는 포즈가 바뀐 정도만 반영하도록 정규화 하는 과정이고, 마지막 linear blend matrix W와 함께 포즈 정보가 반영된 vertex를 얻습니다. 이건 흔히 SMPL에서 포즈 정보를 반영하기 위해서 사용되는 방식입니다.
Texture Modeling
기존의 3D 모델은 눈과 같은 디테일한 부분의 texture를 적절하게 반영하지 못하는 경우가 있습니다. 이를 극복하기 위해서 해당 논문에서는 StyleGAN2 논문을 사용했습니다.
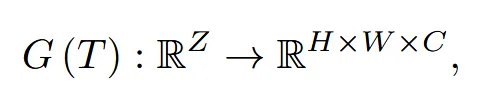
Latent code T를 입력으로 받아 generator는 1024x1024 texture image를 생성합니다.
Single-View Reconstruction
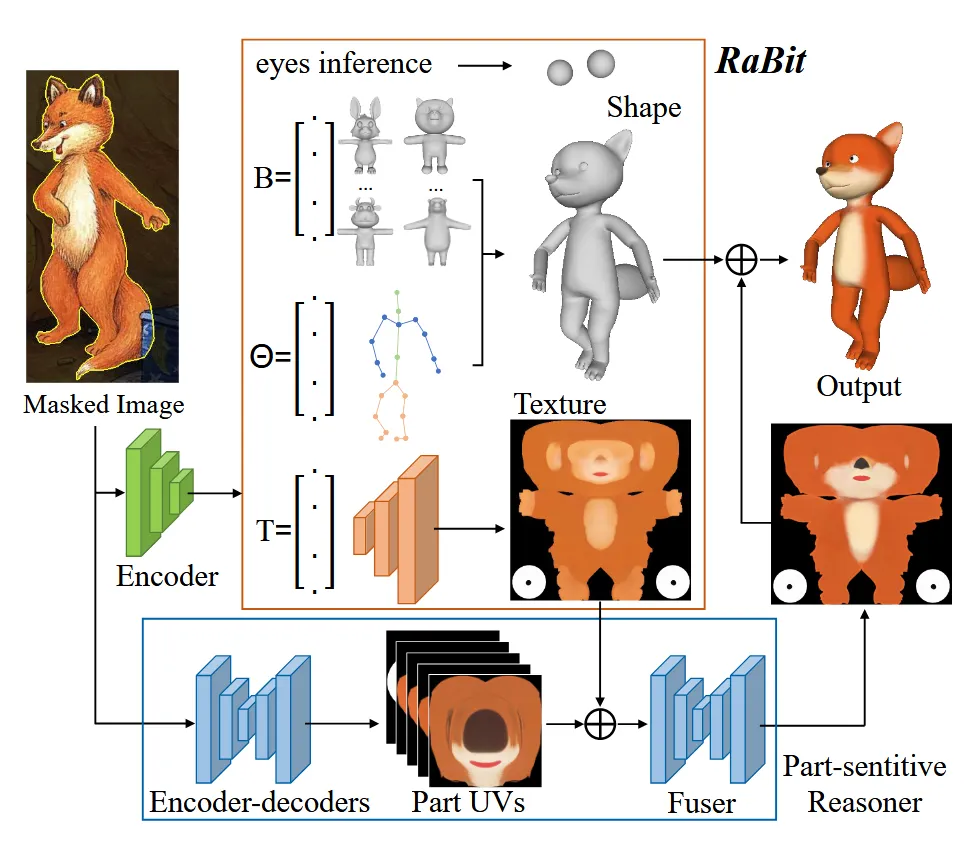
BicarNet
2D 입력 이미지 1장만 보고 3D의 모양, pose, texture를 예측하는 모델입니다.
입력 이미지에서 Shape을 만들기 위해서 필요한 3가지 파라미터 값을 HMR(Human Mesh Recovery) 모델에서 사용된 이미지 인코더 구조를 사용해서 예측합니다. 예측된 모양에서 눈코입은 적절하게 나오지만, texture는 디테일한 부분이 나오지 않은 문제점이 발생했습니다.
눈, 코, 입 같은 디테일한 부분의 texture를 입히기 위해서 part-sensitive texture reasoner(PSR)을 제시했습니다. 5가지(코, 귀, 뿔, 눈, 입) 개별적인 UV map(Part UVs 그림에서 파란색 부분)으로 생성하는 방식이 PSR입니다. 입력이미지를 encoder-dcoder 방식으로 UV를 생성하게 하는 방법을 채택했습니다.
이렇게 5개의 texture와 원본을 합치면 seam(경계)가 발생합니다. 이를 극복하기 위해서 Fuser를 적용했습니다. 자세한 내용은 Supplementary를 참고하시면 됩니다.
Experiments
1500개의 데이터중에서 1050개는 학습에 450개는 test에 사용했다고 밝혔습니다. 여러 시점의 이미지를 렌더링 한 이미지들도 robust한 결과를 위해서 학습됐습니다.