Meta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects

Meta 3D TextureGen의 결과들입니다. Mesh에 text prompt와 알맞은 texture를 생성하는 모델입니다.
요약
- Stage 1: 기존의 depth 기반 texture 생성 방식 → Position & normal(X,Y,Z) 사용
- Stage 2: Inpainting을 할 때도 Position & normal 사용
- SyncMVD에서 사용한 가중합 이용
- Option: Diffusion을 나눠서 생성할 때 consistency를 위해서 Multidiffusion을 1D → 2D로 변환
Preliminaries and data processing
논문의 방법을 소개하기 전에 논문에서 어떻게 데이터를 처리하는지, 그리고 용어들을 정리해 둔 부분입니다.
Shape renders
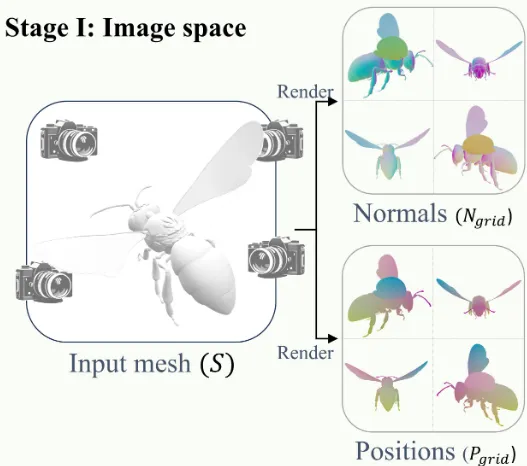
그림에서 보이는 것처럼 4개의 시점의 이미지를 하나의 single image로 만듭니다. 이때 4개의 시점을 여기서는 4개의 채널이라고 부릅니다.
Combined pass(beauty pass) : 학습시에만 사용하는 렌더링 할 때 material(metal, wood, plastic)과 lighting effect를 고려해서 렌더링 하는 방법을 말합니다.
- 조명을 고려하기 위해서 Blender라는 소프트웨어를 이용해서 even lighting(모든 방향에서 동일한 빛을 내도록 하는) 방법을 사용했습니다.
Position and normal passes : 학습과 추론 모두에 사용하는 방법으로, 각 픽셀의 XYZ 값을 나타냅니다. 두 값 모두 [0,1]로 정규화 되어있고 조명 없이 렌더링 됩니다.
UV maps
해당 연구에서 사용하는 UV map은 mesh당 하나만 필요로 하기 때문에, 하나만 있지 않는 경우 Blender의 Smart project 방법을 사용해서 하나로 합칩니다. Smart project 방법이 실패할 경우 해당 데이터는 사용하지 않도록 했습니다.
Baked channels
이전에 Combined, Position, normal 3개의 pass에 대해서 정의했었습니다. 우선 combined pass의 ground truth를 알기 위해서 3D의 texture를 2D uv map으로 baking을 통해서 값을 얻습니다. Position과 normal 값은 3차원의 정보를 그대로 가져와서 학습에 사용됩니다.
Method
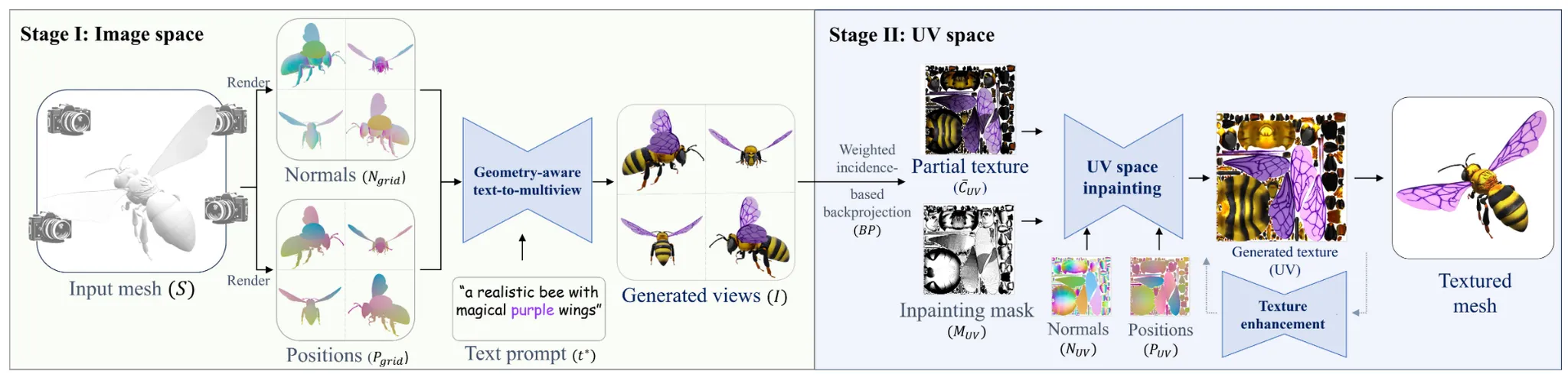
입력값으로 Mesh&Text prompts가 들어오면, 위의 사진처럼 two-stage approach를 통해서 마지막 텍스처링된 mesh가 생성됩니다. 2stage 이후에 추가 optional한 방법도 있는데, 해당 부분에서는 MultiDiffusion을 1D → 2D로 변경함으로서 texture map의 해상도를 4배 증가시킬 수 있다고 언급했습니다.
첫번째 스테이지에서는 4개의 멀티뷰 정보를 이용해서 text prompt에 맞게 텍스처가 생성되고, 두번째 스테이지에서는 첫번째의 결과를 기반으로 global하게 texture가 겹친 부분은 제거하고, 비어있는 부분은 채워가는 형식으로 진행됩니다. 이제 각 스테이지를 자세히 알아보도록 하겠습니다.
Stage 1: Generation in image space
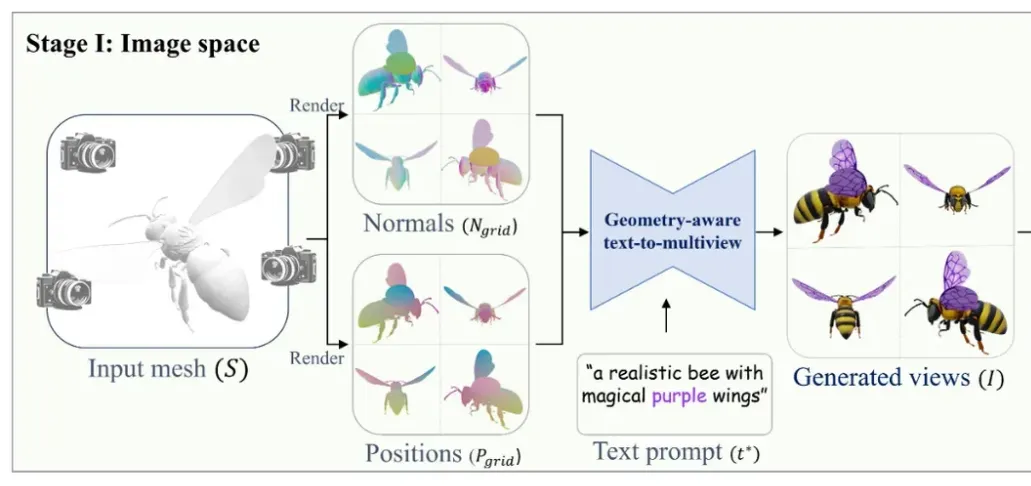
우선 360도를 4등분 한 0,90,180,270 이렇게 4개의 방위각과, 고도는 20도를 사용해서 약간 내려다보는 값을 사용해서 총 4개의 채널을 얻습니다. 이렇게 얻은 4개의 채널은 1개의 이미지로 합쳐집니다. Preliminaries 부분에서 학습에 사용되는 pass는 normal과 position이라는 것을 배웠기 때문에 normal과 position을 grid로 합친 2개의 이미지와 text prompt까지 3개의 정보를 이용해서 각 채널별로 text prompt에 맞는 texture 이미지가 생성됩니다.
Geometry-aware 2D conditioning
TEXture과 같은 논문에서는 depth map을 이용해서 texture를 생성했지만, 해당 연구에서는 normal과 position을 이용해서 texture를 생성했습니다. 그에 대한 첫번째 이유는 point 정보를 사용하면 view-dependent 하지 않고 global하게 사용할 수 있고, 두번째 이유로 normal 정보를 사용하면 depth에서보다 더 기하학적인 디테일들을 얻을 수 있다고 합니다.

위의 그림을 보시면 (a)가 depth map, (b)가 point, (c)가 normal 입니다.
Depth map vs point : 첫번째 행에 있는 depth map에서는 토끼의 얼굴이 검정색이지만, 두번째 행에 있는 depth map에서 토끼의 얼굴은 약간 회색입니다. 반면에 point는 두행 모두 진한 정도가 비슷하게 나타는 것을 확인할 수 있습니다. 이를 통해 point가 depth에 비해서 global consistency를 잘 유지한다고 확인할 수 있습니다.
Depth map vs normal : 확실히 그림을 보면 normal 부분이 볼록한지, 오목한지, 경사가 있는지에 대한 기하학적 디테일들을 더 잘 표현된 것을 확인할 수 있습니다.
Multi-view image generation from text
2개의 이미지와 text prompt를 입력으로 받는 diffusion 모델은 U-Net기반의 LDM(latendt diffusion model)입니다. LDM중에서 Meta에서 개발한 Emu(텍스트와 다양한 이미지 조건을 이용해서 이미지를 생성)를 기반으로 fine=tuning을 시켰습니다.
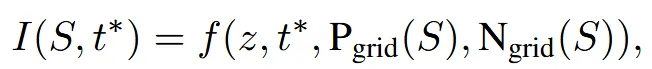
수식은 위와 같습니다. 최종적으로 생성하는 이미지는 I는 S(texture가 없는 mesh)와 text prompt()를 기반으로 생성됩니다. f는 이전에 말한 Emu 모델, z는 2D noise map, 는 position, 는 normal값을 각각 나타냅니다. 실제로 모델의 입력으로 time step(t)도 사용되지만 간결하게 나타내기 위해서 생략했습니다.
Stage 2: Generation in UV space
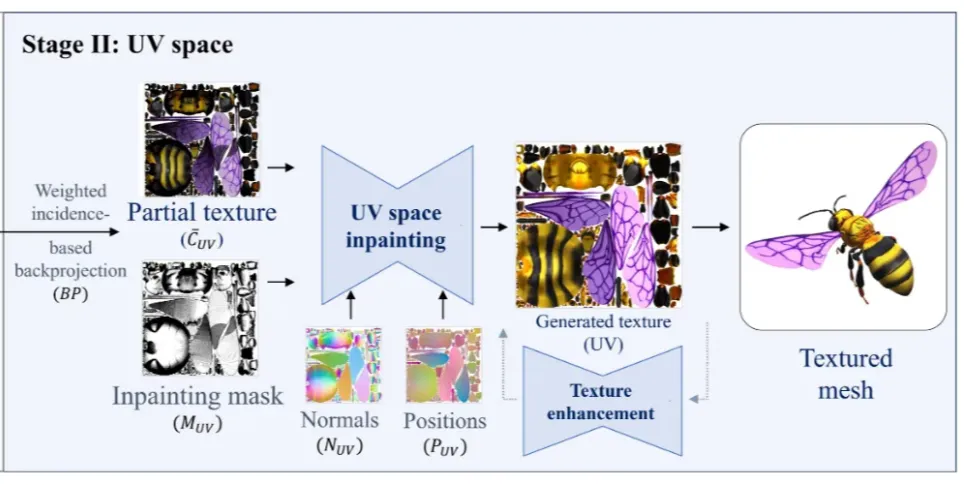
두번째 스테이지의 목표는 첫번째 스테이지의 결과를 이용해서 missing 부분을 채우고, 전반적인 texture의 퀄리티를 높이는 과정을 진행합니다.
Backprojection and incidence-based weighted blending
Backprojection은 2D 이미지를 3D model의 UV map으로 변환해주는 방법을 말합니다. 변환 과정에서 픽셀끼리 겹치는 과정이 발생하는데 이때 단순히 평균을 취해서 넣으면 artifacts가 발생하기 때문에 SyncMVD에서 사용한 가중치 평균을 사용합니다.
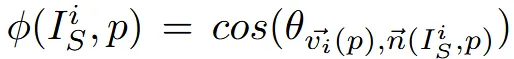
가중치는 픽셀의 normal vector와 view direction간의 코사인 유사도 계산을 통해서 구하게 됩니다. 왼쪽의 가 가중치를 나타내고, 이를 구하기 위해서 p(view direction)과 n(normal vector)의 코사인 유사도를 나타내는 식이 위의 사진입니다.
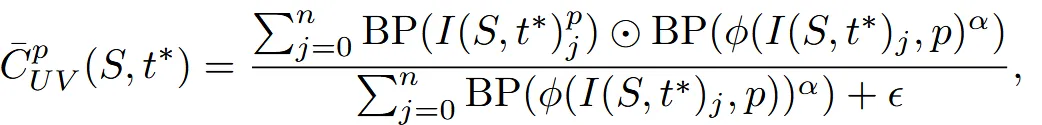
Backprojection을 BP라고 했을 때 위의 수식처럼 UV map의 각 픽셀에서의 texture는 BP의 가중치 평균을 통해서 얻게 됩니다. j는 몇번째 시점인지를 나타내고, p는 픽셀 값을 나타냅니다. 채널(시점)이 4개니까 n=4, =6을 실험을 통해서 설정했습니다.
UV-space inpainting network
카메라가 못보는 영역과, 3D과 UV map이 일대일 매칭이 되지 않는 부분에서 texture가 비어있는 부분들이 발생하게 됩니다. 완전한 texture를 얻기 위해서 inpainting 과정을 진행합니다.
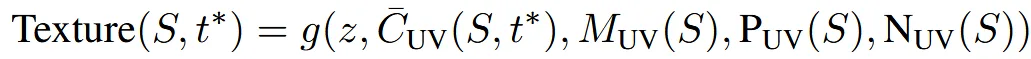
Stage1과 비슷하게 U-net 기반의 LDM기반을 pre-trained 시킵니다. Condition으로는 부분적인 texture를 갖고있는 를 사용하고, inpaint할 mask 와 , 각각 position과 normal을 나타내는 값을 함께 입력해서 최종 texture map 를 얻습니다.
Texture Enhancement Network
스테이지 2가 끝나면 최종적으로 1024 X 1024 해상도의 UV texture map이 생성됩니다. 더 높은 4k(4096 X 4096)의 이미지를 얻기 위해서 추가적인 작업을 진행합니다.
GPU 메모리의 한계를 극복하기 위해서 patch-based 방식을 사용합니다. 하지만 해당 방식은 패치간의 불일치가 나타날 수 있다는 단점이 존재합니다. 이를 극복하기 위해서 MultiDiffusion을 1D에서 2D로 바꾸고 각 diffusion time step마다 weighted Gaussian average를 적용시키고 마지막으로 tiled-VAE를 사용해서 타일간의 불일치를 완화시켰습니다.
Experiments
Ablation study
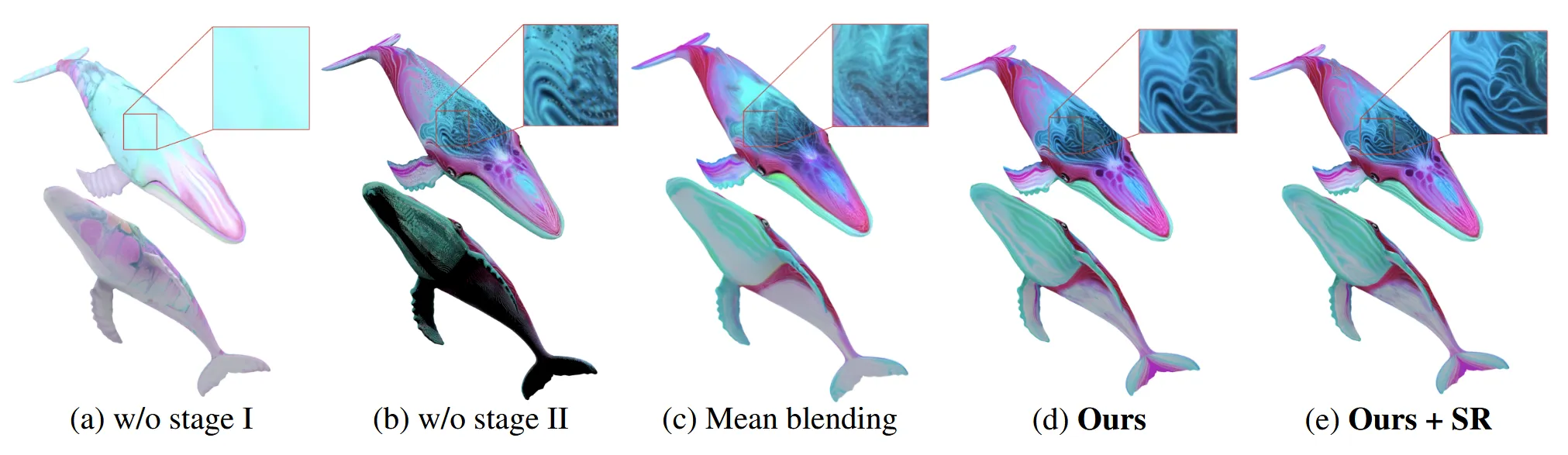
Text prompt: A whale with a pastel pink skin with swirls of mint green, lavender and blue creating a marbled effect
(a)그림은 스테이지 1을 수행하지 않고 바로 스테이지 2의 UV space에서 diffusion 모델로 텍스처를 생성한 경우입니다. 확실히 나머지에 비해서 text prompt와 불일치한 것을 알 수 있습니다.
(b)그림은 스테이지 2를 수행하지 않고 나온 결과입니다. 확실히 카메라가 4개의 뷰만으로는 커버가 되지않아서 아래 부분의 결과가 좋지 않은 것을 확인할 수 있습니다.
(c)그림은 가중치 평균이 아닌 그냥 평균을 했을 때 결과인데 먼가 흐릿한 결과가 나타납니다.
(d)그림은 Super Resolution(SR)없이, (e)그림은 SR까지 진행한 결과입니다.
Limitations
- PBR map(tangent normals, metalic, roughness)를 사용하지 않은 점
- 실시간으로 활용할만큼 빠르지 않은 점
