요약
- 각 뷰에서 Diffusion을 이용해서 texture를 업데이트 → Consistency를 일치 시키기 위해서 UV space에서 weighted combination을 사용
- U-Net의 Self-Attention의 입력으로 인접 시점과 고정 시점을 넣어서 consistency 일치


이전의 Texture generation 논문들은 2D diffusion모델의 condition으로 depth or normal을 이용해서 렌더링된 정보를 text prompt에 알맞게 수정하고 다시 이를 projection 시킵니다. 하지만 이러한 과정에서 각 시점의 생성결과가 일관성이 부족하고 Seam(첫번째 사진)이나 Fragmentation(두번째 사진)과 같은 현상이 발생합니다.

(a)가 MVD를 사용한 결과, (b)가 MVD를 사용하지 않은 결과입니다. 퀄리티도 퀄리티인데, Seam이나 Fragmentation이 확실히 적고 시점간의 일치가 확실히 높아진 것을 알 수 있습니다.
Synchronized Multi-View Diffusion

기본적인 틀은 기존 논문들과 비슷하지만 어떻게 consistnecy를 해당 논문에서는 잡았는지를 집중해서 보시면 도움이 되실 것입니다. 핵심 개념은 각 시점에서 diffusion 모델을 이용해서 이미지들을 생성할 때 서로 정보를 공유하는 것입니다. 정보 공유는 각 time step마다 진행이 됩니다.
Multi-View Diffusion in Texture Domain
기존에 사용하는 screen-space warping 대신 UV mapping을 하는 방식을 설명합니다.
screen-space warping은 text prompt를 guidance로 이용하면서, 해당 시점의 depth나 normal을 이용해서 texutre가 입혀진 해당 시점의 이미지를 얻는 기존의 방법입니다. 모든 denoising 과정은 개별적으로 진행됩니다.
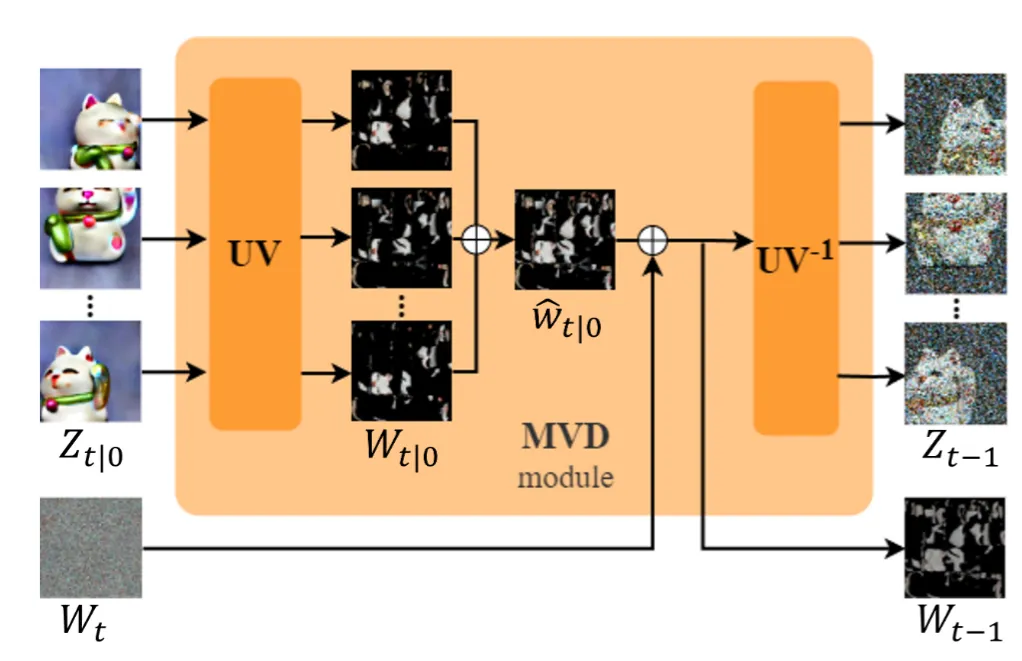
반면에 UV mapping은 모든 time step의 결과를 UV map에서 consistency를 일치시키고, 해당 결과를 기반으로 다시 각 뷰의 denoising 과정을 진행합니다. 그림을 통해서 설명 드리면 T step에서 원본을 예측한 는 MVD module consistency를 일치시키고 다시 T시점의 정보와 함께 T-1시점을 예측(DDIM 방식)하게 됩니다.
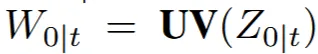
MVD module 방법을 수식적으로 설명해드리자면, 을 screen space에서 UV space로 변환해주는 UV함수를 사용해서 를 얻습니다.

이렇게 변환하는 과정에서 겹치는 영역은 보이는 부분만 가중 평균해주게 됩니다. 분자의 값은 각 시점에서 얻은 texture를 UV map으로 변환된 결과, 분모는 triangle visibility mask로서 분자의 값 중에서 보이는 부분만을 나타내는 영역입니다.

이렇게 진행할 경우 카메라에 보이지 않는 영역의 texture는 비어있다는 단점이 존재합니다. 이를 극복하기 위해서 Voronoi-based filling 방법을 사용했습니다. 해당 방법은 비어 있는 픽셀은 유효한 픽셀 중 가장 인접한 픽셀을 선택하는 방식입니다. Voronoi-based filling 방법을 통해서 두번째 사진처럼 모든 픽셀이 채워졌지만 이중에서 필요한 부분만 얻기 위해서 다시 triangle visibility mask 부분만을 사용해서 맨 오른쪽 결과를 얻게 됩니다.
Self-attention Reuse
Textmesh에서 여러개의 이미지를 concate해서 denoising시에 사용하면 결과가 비슷해진다는 것을 증명했습니다. 이 방법을 사용하기 위해서 해당 논문에서는 U-Net의 Self-Attention을 사용할 때 인접 뷰들을 사용하는 것입니다.
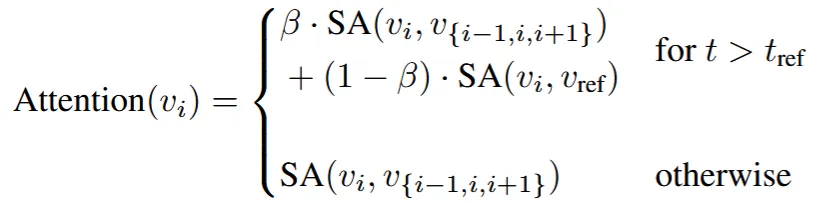
초기에는 인접 뷰들의 입력도 사용하고(), 고정적인 뷰(기본값은 정면, )도 사용해서() 뷰들을 일치시킵니다. 시점 이후부터는 고정적인 뷰와 안보이는 뷰를 일치시키면 성능이 떨어지는 요인이 되기때문에 인접 뷰들만 Self-Attention에 사용합니다.

참고로 Attention U-Net에서 Self-Attention은 intermediate layers에서 사용됩니다.(왼쪽에서 오른쪽으로 넘어가는 부분)

Self-Attention을 공유 하지 않았을 때가 왼쪽, 했을 때가 오른쪽의 결과입니다. 확실히 view consistency가 일치하는 것을 확인할 수 있습니다.
Finalizing the Texture
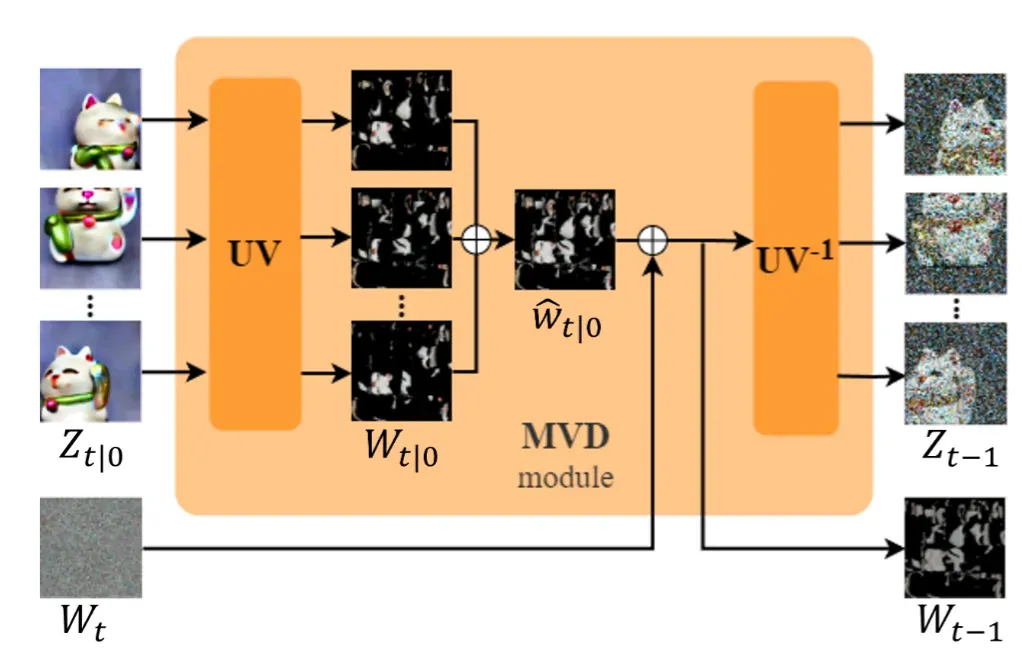
Denoising 과정을 자세히 보면 UV space에서 평균화한다음에 다시 을 통해서 screen space로 변환한 후 denoising을 진행합니다. 왜 UV space에서 denoising을 진행할 수 있는데 screen space에서 진행할까요?
첫번째로, UV space는 screen space의 결과를 늘리고 회전시켜서 나온 결과이기 때문에 기존에 학습된 VAE Decoder의 분포와 맞지 않아서 좋지 않은 결과를 야기합니다.
두번째로, 마지막 고주파 디테일을 생성할 때 UV space에서 디테일이 완전히 조화되지 않는다고 합니다. 왜냐하면 첫번째와 마찬가지로 늘림과 회전이 발생했기 때문입니다.
두가지 이유때문에 screen space에서 최종적으로 denoising 과정을 진행했습니다.
또한 이전에 설명한 Voronoi-based filling 방법을 사용하면 고주파 디테일이 흐려지기 때문에, 최종적으로 weighted combination 방식을 사용했습니다.
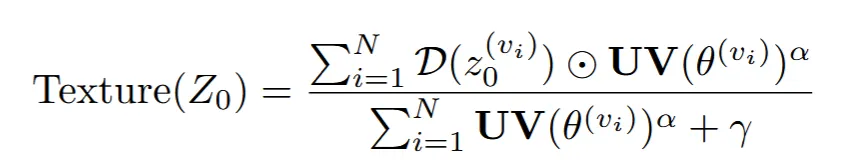
Weighted combination의 수식은 위와 같습니다. Texutre에서 한 픽셀의 법선 벡터와, view direction의 벡터의 코사인 유사도가 가중치가 되어서 가중치 합을 구하는 것입니다.
