PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction [2023 CVPR]
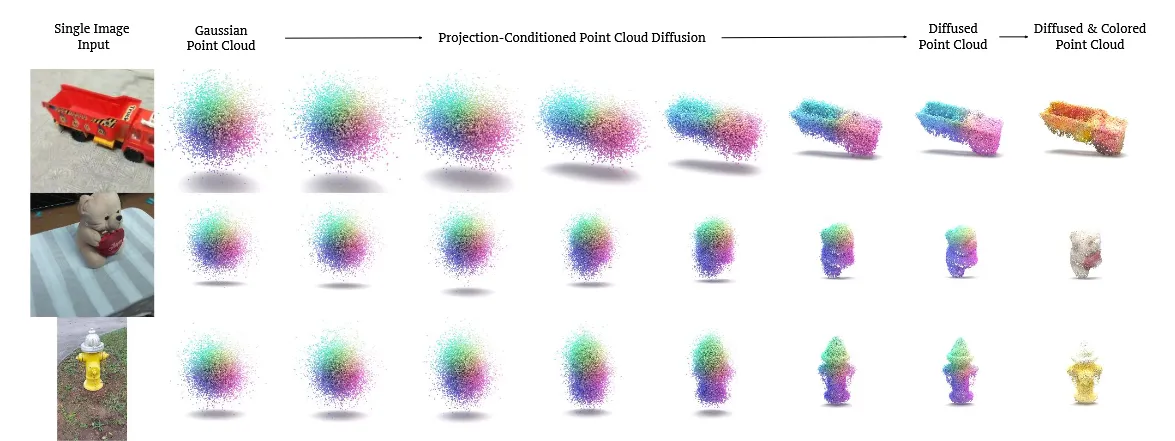
입력으로 RGB 이미지와 카메라 정보를 넣으면 이에 대해서 random gaussian point cloud에서 시작해서 점점 입력 이미지에 맞는 형태로 denoising을 진행하는 모델입니다. Point cloud를 어떻게 원하는 형태로 바꿀 수 있는지 확인해보도록 하겠습니다.
Model
Point Cloud Diffusion Models
N개의 3D point에 대해서 다루기 때문에 차원은 총 3N이 됩니다. 초기에는 분산이 모두 동일한 ‘spherical Gaussian ball’로 시작합니다. 그리고 초기 단계에서 우리는 각 점들이 어디로 이동해야 될지에 대한 offset을 예측합니다.
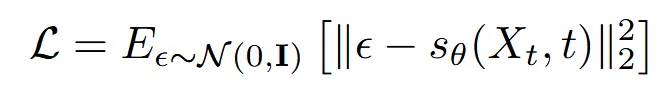
구체적으로는 L2 loss를 이용해서 노이즈를 예측합니다.
Conditional Point Cloud Diffusion Models
해당 논문에서 제안한 Diffusion 모델은 입니다. I는 입력 이미지, V는 대응되는 카메라 시점입니다.
기존에 condition 정보를 diffusion 모델에 전달하는 방식으로 global embedding 값을 사용했습니다. 이러한 방식은 물체의 대략적인 모양은 잡을 수 있지만, 입력 이미지와 정확히 일치하지 않습니다.
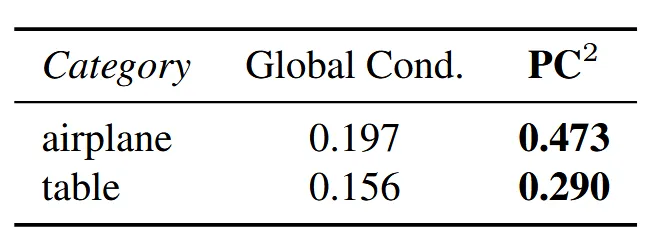
위의 표를 보면 기존 global embedding 방식을 사용햇을 때보다 F-score가 훨씬 더 좋아진 것을 확인할 수 있습니다.
에서는 입력이미지를 통해서 추출된 feature로 이미지의 형태 카테고리(의자, 차)를 분류합니다. 이후 분류된 카테고리에 맞춰, 해당 카테고리의 평균적인 3D 형태를 디코더가 생성합니다.
PC2: Projection-Conditional Diffusion Models
위에서 설명한 내용을 조금 더 자세히 설명하자면, 입력 이미지는 2D image model(CNN or ViT)를 통해서 feature로 변환됩니다. Feature의 차원은 가 됩니다.
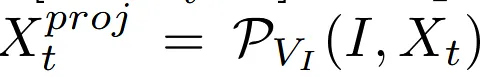
이렇게 얻은 I는 t시점의 노이즈와 함께 projection function에 들어가 새로운 값 를 얻게됩니다. 여기서 사용하는 projection function은 Pytorch3D의 Point Rasterizer를 사용했습니다. 단순 projection 보다 미미한 시간만 추가되지만 깊이 순서까지 고려한 더 정확한 결과를 얻을 수 있습니다.
정리하자면 Rasterizer를 통해서 3D 점을 2D의 픽셀 위치 정보를 얻고, 이에 대응되는 값을 이미지 feature에서 가져오게 됩니다.
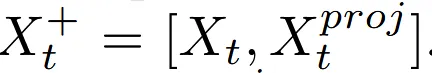
이후에 기존의 값과 다시 concat 돼서 t-1시점의 노이즈 예측을 하는데 입력값으로 사용됩니다.
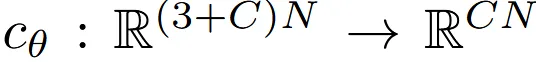
똑같은 방식의 projection-based conditioning 방식으로 color를 예측하는 별도 네트워크도 설계합니다.
PC2-FM and PC2-FA: Filtering for 3D Reconstruction
Diffusion 모델을 통해서 결과를 얻을 때 하나의 이미지로 여러개의 서로 다른 결과를 얻을 수 있습니다. 이렇게 얻은 각 후보군들 중 최상의 결과를 선택하는 과정을 아래와 같이 2가지 방법중 하나로 진행합니다.
3D point cloud의 점 하나하나를 반경이 작은 공으로 그리면, 최종적으로 그 점군의 실루엣 을 얻을 수 있습니다.
- With mask supervision (PC2-FM)
생성된 3D를 입력 이미지와 동일한 카메라 view(V)로 렌더링 해서 얻은 이미지에 대해서 Mask-RCNN을 이용해서 mask를 얻고, 입력 이미지의 실루엣과 비교해서 IoU값이 가장 높은 결과를 선택
- Without mask supervision (PC2-FA)
Mask-RCNN처럼 학습된 모델 없이 사용하는 방식으로 결과들에 대해서 실루엣을 비교해 가장큰 IoU를 갖는 결과를 선택
Experiments
Dataset
ShapeNet: WordNet의 객체 카테고리에 대응하는 3D CAD 모델들의 대규모 합성 데이터셋
- Subset: 3D-R2N2 논문에서 사용한 13개 카테고리
Co3D: 현실 세계에서 촬영된 다중 뷰 이미지 시퀀스로 이루어진, 매우 까다로운 데이터셋
- 실제 물건을 다양한 각도에서 촬영한 이미지들로 구성
- COLMAP을 이용해 point cloud 생성
Implementation Details
Diffusion model: Point-Voxel CNN (PVCNN)
- point-based branch: 각 점들에 대해서 개별적인 진행
- voxel-based branch: 인접 점들을 종합해서 진행
Result


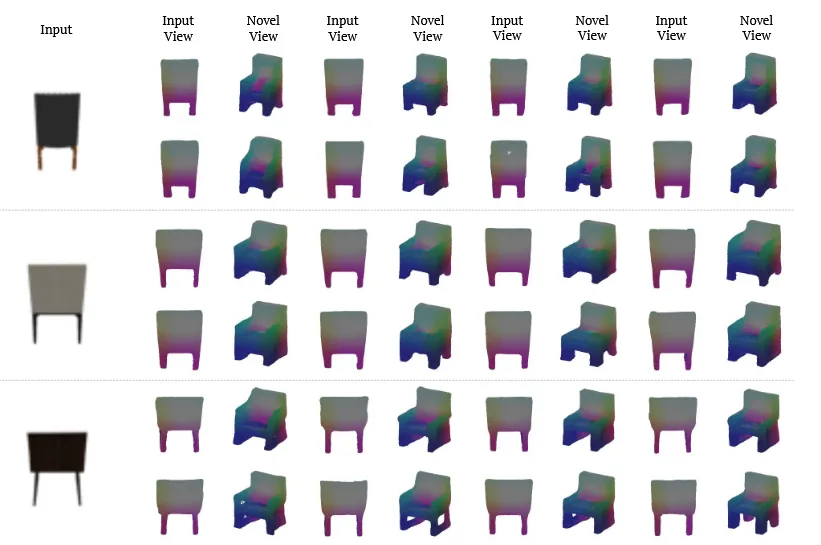
8개의 랜덤시드 결
Limitations
Train을 위한 ground truth point cloud가 필요한다는 점이 limitation입니다.
