
Stable diffusion3 모델부터 U-Net 기반이 아닌 DiT 기반으로 작동하는데, 여기서 말하는 DiT가 transformer라는 점은 알고 있었지만 정확히 어떻게 사용되는지 확인해보기 위해서 논문을 읽게 됐다. 어떠한 이유로 U-Net을 transformer로 바꿨는지, 왜 성능이 증가하게 됐는지 아래에서 정리해보도록 하겠다.
Introduction
도입부에 Transformer가 많은 분야에 적용됐는데 아직 생성 모델에는 적용이 되지않았고, 그래서 적용하겠다라는 식으로 당위성을 입증했는데 내가 부족해서인지 나는 이 부분이 모호했다. 왜 transformer가 다른 분야에 적용됐고, 어떤 점이 좋았는지 찾아본 결과 아래와 같은 결론이 나왔다.
Transformer의 계산 복잠도(Gflops)를 높일수록 이미지 품질이 일관되게 좋아져!
그러면 왜 위와같은 결론이 나왔는지 생각해봐야 되겠다. 일단 이미지 분야에 특정된 결론이니 해당 분야에 대해서만 생각해보자. 첫번째 원인은 Inductive bias가 적다는 점이다. 기존 U-Net과 같은 CNN 모델들은 인접한 픽셀끼리는 연관되어 있다는 편향이 존재한다. 따라서 데이터가 적을 때는 이러한 편향 덕분에 좋은 성능을 냈지만, 데이터가 많아질 때는 오히려 이러한 편향이 성능을 증가시키지 못하는 한계점이 된다. 이에 비해서 Transformer는 Inductive bias가 CNN 모델보다 적기 때문에 데이터의 증가 즉 계산 복잡도가 높아질수록 성능이 높아진다. 두번째 원인은 Transformer 모델의 아키텍처에 있다. CNN은 커널을 통해서 왼쪽 위에서 오른쪽 아래까지 훑으며 특징을 뽑아서 이러한 특징들이 서로 종합되지 않지만, Transformer 모델은 Self-attention을 사용하기 때문에 멀리 떨어진 정보도 서로 상호교환하며 전연적인 문맥을 파악할 수 있다. 또한 CNN은 이미지가 바껴도 가중치의 고정된 필터를 사용하지만, Transformer는 attention이라는 값이 이미지마다 바뀔 수 있기 때문에, 이미지에 특화된 연산을 할 수 있다.
즉 위와 같은 결론과 이유를 기반으로 우리는 Transformer가 왜 비전 분야에 적용되고 있는지 알 수 있다. 돌아와서 저자는 생성 모델이 CNN기반으로 되어있기 때문에 위와 같은 이유로 Transformer를 적용하려고 한다. 심지어 저해상도 이미지를 처리할 때 Self-attention을 적용하는 논문이 나올정도로 기존 생성 모델들은 Transformer의 방식을 적용하려고 시도했다. 그럴거면 굳이 왜 CNN을 고집해야해? Transformer를 쓰자! 라는 생각으로 저자는 U-Net 대신 Transformer를 Diffusion 모델에 적용했다. 이렇게 적용된 모델을 Diffusion Transformers 줄여서 DiT라고 부른다. DiT를 통해서 계산 복잡도를 높일수록 이미지 품질이 좋아진다는 점을 찾았고, 이를 실험적으로 증명했다고 논문에서 밝혔다.
Related Work
Transformers
Transformer는 언어, 비전, 강화학습, 메타 러닝등 다양한 분야에 적용되고 있다. 이전에도 계속 언급했지만, Transformer는 연산량을 늘릴수록 성능이 증가한다. 이러한 현상을 scaling 속성이라고 하는데, 이 속성을 기반으로 diffusion의 backbone을 Transformer로 사용해 성능을 증가시키는 것을 보여줄 것이다.
Denoising diffusion probabilistic models (DDPMs)
이미지 생성 모델로서 Diffusion과 score 기반 생성 모델들은 GAN을 능가한 성능을 내며 좋은 방식으로 평가 됐다. 이러한 모델들은 U-Net을 백본으로 사용해왔고, 이 논문에서는 이를 Transformer로 바꿔보겠다고 제안했다.
Architecture complexity
이미지 생성 분야에서 복잡도를 측정하기 위해서는 파라미터 수를 측정하는 방식을 주로 사용해왔다. 하지만 파라미터 수는 고정되어 있어도 처리해야 할 이미지 해상도에 따라 실제 연산량을 다른데, 이를 복잡도를 나타내는 지표로 사용하는 것은 부적절하다라고 논문에서 밝혔다. 이에 따라 이 논문에서는 계산복잡도(Gflops)를 이용해서 진행하자고 하는 방식으로 복잡도를 측정했다.
Diffusion Transformers
Preliminaries
Diffusion formulation
들어가기 앞서 diffusion model(DDPM)에 대해서 정리한 부분이다. 잘 알겠지만 forward noising process를 통해서 실제 데이터에 노이즈를 더해간다. 수식적으로는
이렇게 작성할 수 있다. 여기서 는 하이퍼파라미터인데 우리가 아는 스케줄러라고 생각하면 된다.
역과정인 reverse process는
로 수식을 나타낼 수 있고, neural network 의 예측을 통해서 진행된다.
Classifier-free guidance
Conditional diffusion model은 추가적인 입력값을 받도록 설계한 모델이다. 해당 모델은 reverse process를 진행할 때 의 수식을 사용해서 condition(c)의 영향을 받는다.
는 unconditional 부분이고, c는 condition이 들어간 부분이라서 guidance scale(s)의 값이 1보다 클 경우 condition에 더 강하게 부합하는 이미지를 생성한다.
Latent diffusion models
큰 해상도에서 생성하는 모델들은 계산 비용이 많이 드니까, 더 저차원에서 계산을 진행하자고 제안한 모델이 Latent diffusion models(LDMs)다. Autoencoder의 Encoder를 통해서 이미지를 저차원으로 임베딩 시키고, diffusion model을 이용해서 이렇게 압축된 공간에서 학습을 진행한 후, Decoder를 통해서 다시 이미지를 생성한다.
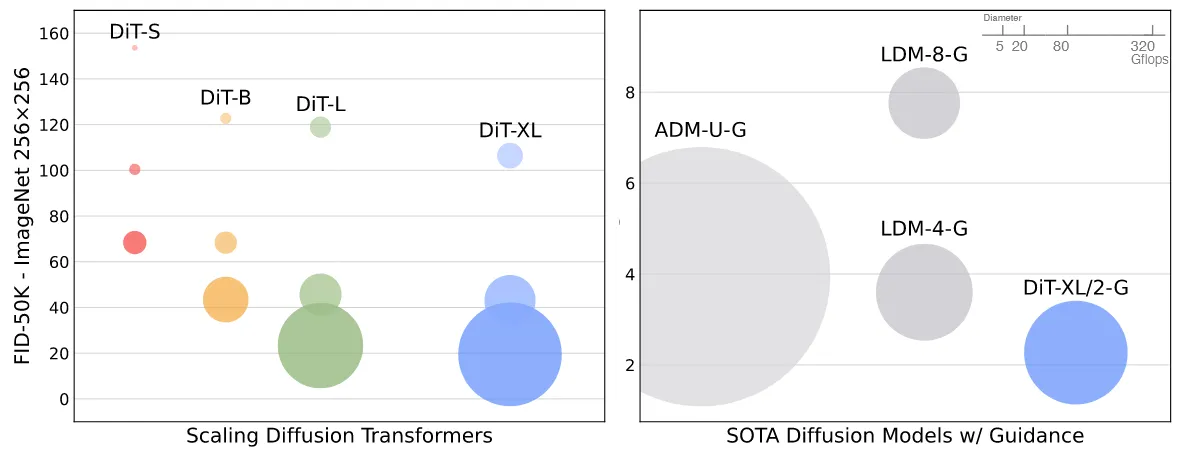
기존 ADM(Ablated Diffusion Model) 모델이 U-Net 기반 diffusion 모델에서 가장 좋은 성능을 기록했는데, LDM 모델은 픽셀 공간을 기반으로 생성하는 방식 대신 압축된 공간에서 학습을 진행하다보니, 연산량이 훨씬 더 적어졌습니다. 이러한 장점때문에 이 논문에서는 LDM의 압축된 공간에서 사용하는 아이디어를 이용했습니다.
Diffusion Transformer Desing Space
Diffusion Transformers(DiTs)는 Vision Transformer(ViT)의 아키텍처를 기반으로 설계했다.
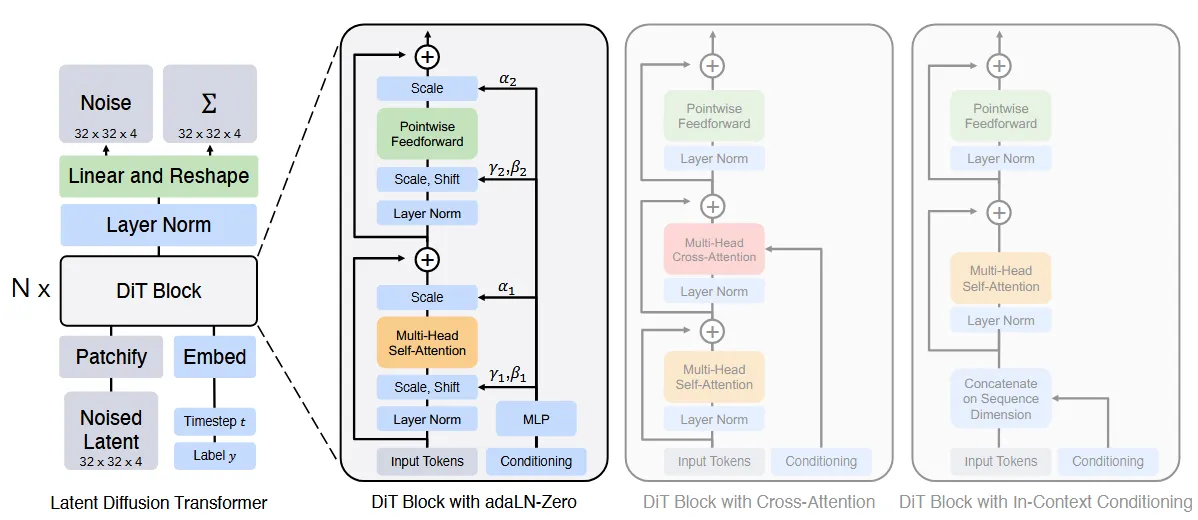
위의 그림은 DiT의 아키텍처이다. 이 파트에서는 우선 DiT의 forward pass를 설명하겠다.
Patchify
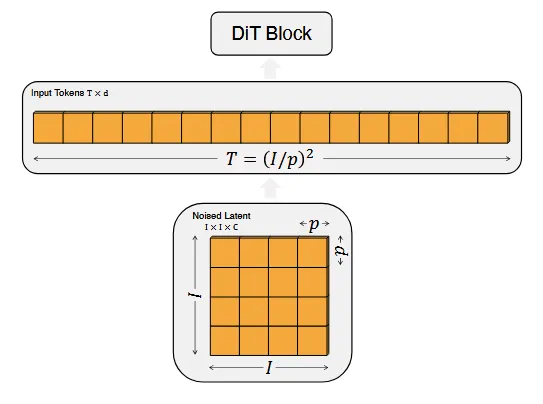
DiT의 입력은 압축된 정보인 spatial representaiton z(32 X 32 X4)를 사용한다. 따라서 기존 LDM 모델에서 사용하는 Encoder를 통해서 이미지를 압축된 정보인 z로 변환한다. 이렇게 압축된 정보는 transformer를 사용하기 위해서 DiT의 첫번째 layer인 patchify를 거친다. Patchify는 32x32 입력을 p x p인 작은 사각형 패치들로 자르는 과정이다. 이렇게 생성된 각 패치를 linear embedding하여 차원 d를 가진 벡터로 만든다. 이렇게 생성된 패치들이 모여 길이가 T인 토큰이된다. 생성된 토큰에 위치 정보(이 패치가 이미지의 어느 부분인지 알 수 잇는 정보)를 주기 위해서 ViT에서 사용한 frequency기반 positional embedding을 더한다.
DiT block design
Patchify 이후에는 일련의 transformer block들을 통과한다. 이 과정에서 timestep 와 class labels 를 condition으로 사용한다. Transformer block은 우리가 잘 아는것처럼 토큰들을 처리하지 condition은 처리하지 못한다. 따라서 논문에서는 4가지 방법을 제시하고 그중에서 한가지 방식을 선택하는 이유에 대해서 아래와 같이 설명했다.
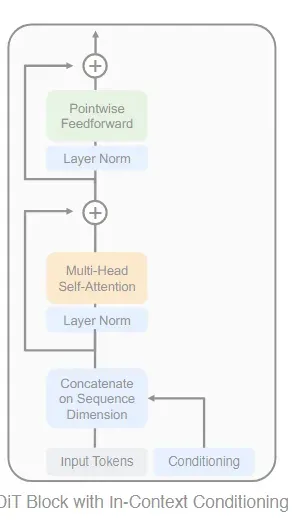
첫번째로 제시한 방법은 In-context conditioning이다. 해당 방식은 이미지 토큰의 마지막 부분에 timestep과 condition embedding을 붙이는 방식이다. ViT에서 사용한 cls 토큰과 비슷한 방식이기 때문에 해당 모델을 그대로 사용하고, 출력값에서 condition 토큰을 제거하는 방법을 이용했다.
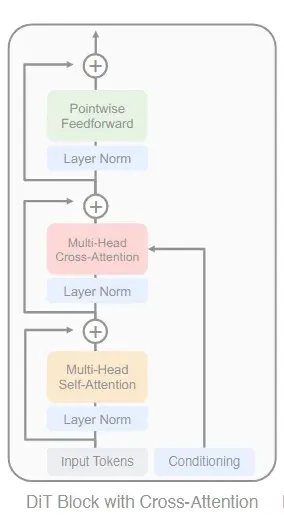
두번째로 제시한 방법은 Cross-attention block이다. Timestep과 condition embedding을 합쳐서 기존 transformer에 Multi-Head Cross-Attention을 추가해서 이미지 토큰과 합치는 방법이다. 이 방법은 LDM에서 condition을 넣는 방식과 유사하다. 이 방법은 Cross-Attention block을 추가했기 때문에 기존 방법보다 연산량이 15% 증가했다.
세번째로 제시한 방법은 Adaptive layer norm(adaLN)이다. 이전 U-Net에서 제안됐던 방법으로 layer normalization이 일반적으로 γ와 β를 학습 가능한 파라미터로 설정한 것과 달리, adaLN은 timestep과 condition의 임베딩 합으로부터 예측하도록 설정한 방식이다. 해당 방식은 지금까지의 방법들중 가장 적은 연산량이 필요로 한다.
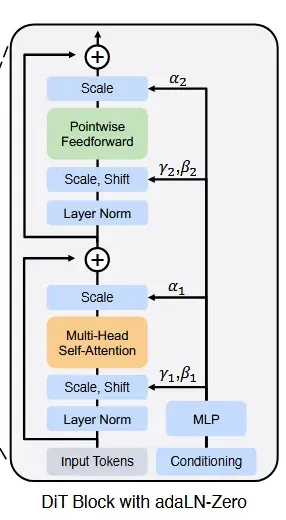
네번째 제시한 방법은 adaLN-Zero block이다. ResNet에서 제안한 residual block의 장점을 사용한 방식으로 기존 U-Net 아키텍처를 사용한 모델들이 모델의 마지막 block에서 zero-initialization한 방식을 세번째 방식에 적용한 것이다. 위의 그림을 보면 파라미터인 Scale을 추가로 예측하는 것을 알 수 있는데, 이 값은 residual connection과 유사한 방식이라고 보면 된다. 이전 토큰들은 화살표처럼 단순히 마지막 block에 더해지고 학습한 scale을 통해서 얼마나 학습된 정보를 많이 더할지 정하는 방식이다. 결론적으로 실험을 통해서 이 방법이 압도적으로 성능이 좋고 연산량이 적다는 것을 확인해서 최종 방법으로 선택했다.
Model size
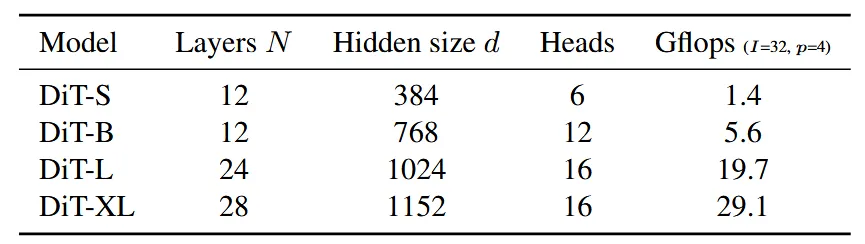
N개의 DiT block을 설정하고, 여기 차원은 d로 설정했다. 해당 논문은 DiT-S, DiT-B, DiT-L, DiT-XL 4개의 모델을 제시했다. 해당 모델들은 0.3부터 118.6 Gflops까지 다양한 계산량을 가졌기 때문에 스케일 확장을 통해서 더 높은 성능을 얻을 수 있다. N과 d 그리고 attention head에 따른 모델명과 Gflops를 위의 표를 통해서 확인할 수 있다. 패치사이즈에 따라서 모델의 연산량은 달라질 수 있다.
Transformer decoder
마지막 DiT block 이후 이미지 토큰을 decoder를 통해서 변환하면 예측한 이미지를 얻을 수 있다. 하지만 지금 이미지 토큰을 LDM의 decoder에 넣을 수 없기 때문에 DiT의 마지막 layer에 이미지 토큰을 32 x 32 x4의 representation으로 변환해야 한다. 일반적인 linear layer를 통해서 각 토큰을 p x p x 2C 크기의 텐서로 변환함으로서 LDM의 decoder에서 사용할 수 있는 형태를 얻는다. 여기서 마지막 차원이 2C인 이유는 노이즈와 공분산을 예측하기 위함이다. 노이즈와 공분산을 예측하는 이유는 잘 알겠지만 기존 APM 학습 방식을 그대로 적용하기 위함이다.
Experimental Setup
DIT모델에서 앞부분은 모델 사이즈고, 뒷부분은 패치의 크기이다. 예를들어서 DiT-XL/2는 XLarge 모델 사이즈와 패치 사이즈가 2인 것이다.
Training
학습은 256, 512의 이미지 해상도의 ImageNet 데이터셋을 이용했다. Data augmentation은 horizontal flip만을 이용했고, ADM 모델의 방식과 거의 유사하고 크게 바뀐 점은 없다.
Diffusion
Method 부분에서도 언급했지만 AutoEncoder(VAE) 모델은 Stable Diffusion 모델을 사용했다.
Evaluation metrics
성능 측정을 위해서 FID Score를 사용했다. 공정한 비교를 위해서 이전 연구들과 동일한 세팅을 진행했다. FID 외에도 Inception Score, sFID 그리고 Precision/Recall 값도 측정했다.
Experiments
DiT block design
이전에 우리는 DiT block을 4가지 방식으로 디자인 할 수 있다고 언급했다. 여기서 각 디자인에 대해서 복잡도를 언급하는데 in-context: 119.4, cross-attention: 137.6, adaLN: 118.6, adaLN-zero: 118.6 Gflops 라고 나와있다. AdaLN-zero가 alpha 파라미터 하나더 예측하지만 소숫점 첫번째짜리까지는 동일한 연산량이 나온점이 흥미로웠다.
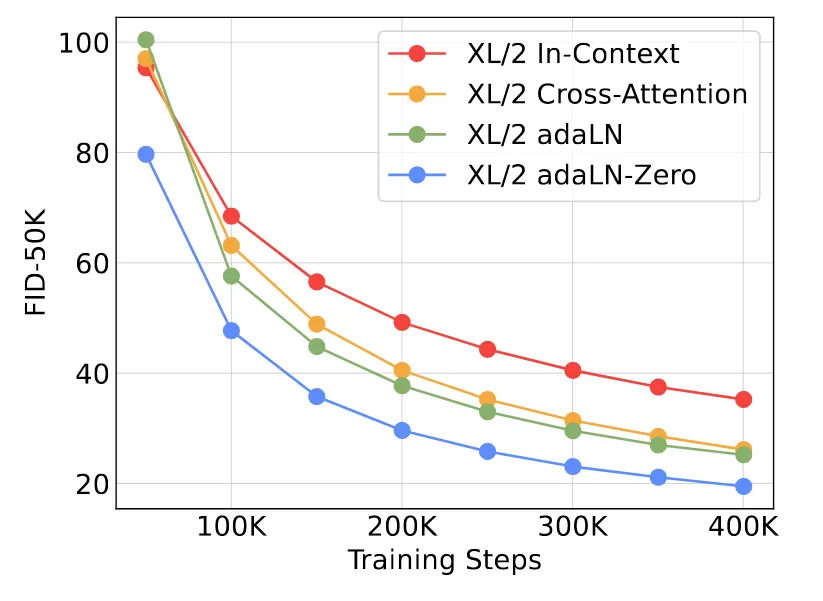
각 경우에대한 FID의 값은 위와 같은데 adaLN-zero의 성능이 가장 좋고, 이에따라 해당 모델을 선택하게 됐다. AdaLN이랑 adaLN-Zero랑 성능차이가 생각보다 많이 나는 점은 놀라웠던거 같다.
Scaling model size and patch size
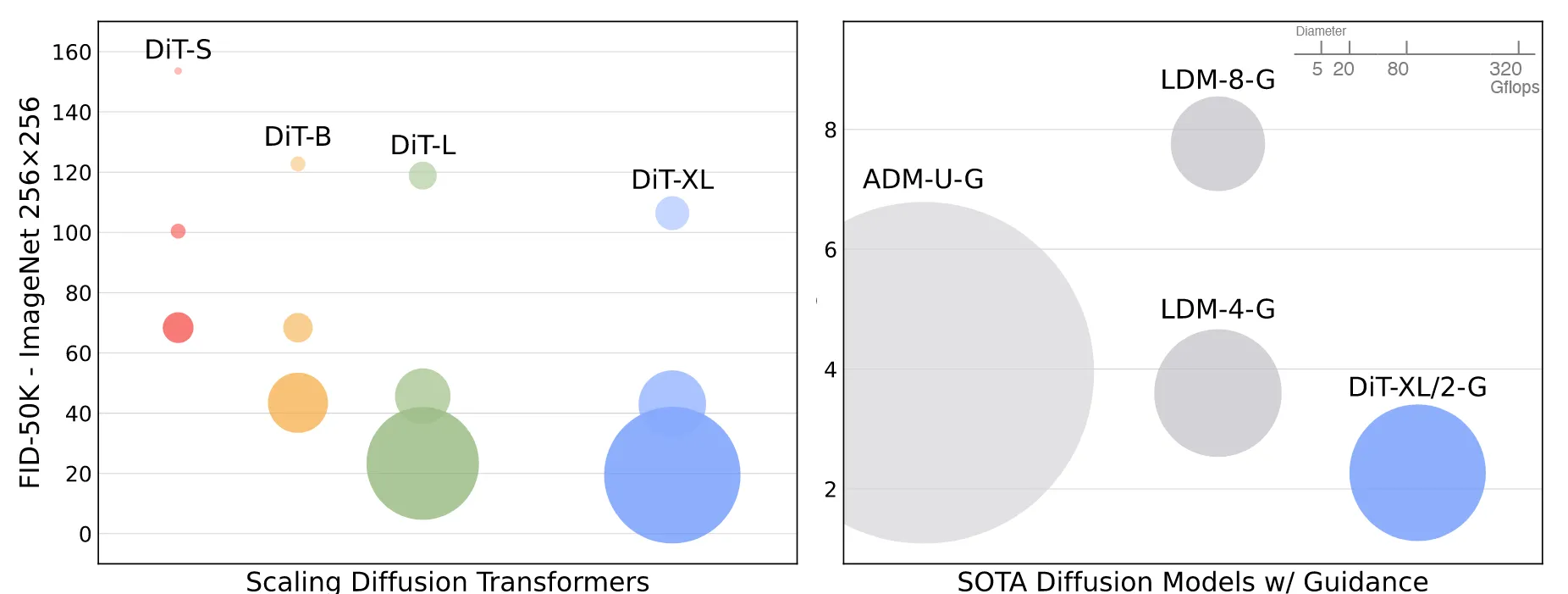
위의 그림은 모델의 사이즈별 FID와 Gflops를 나타낸다. 모델의 크기가 클수록, 패치의 크기가 작을수록 성능이 증가하는 것을 알 수 있다.
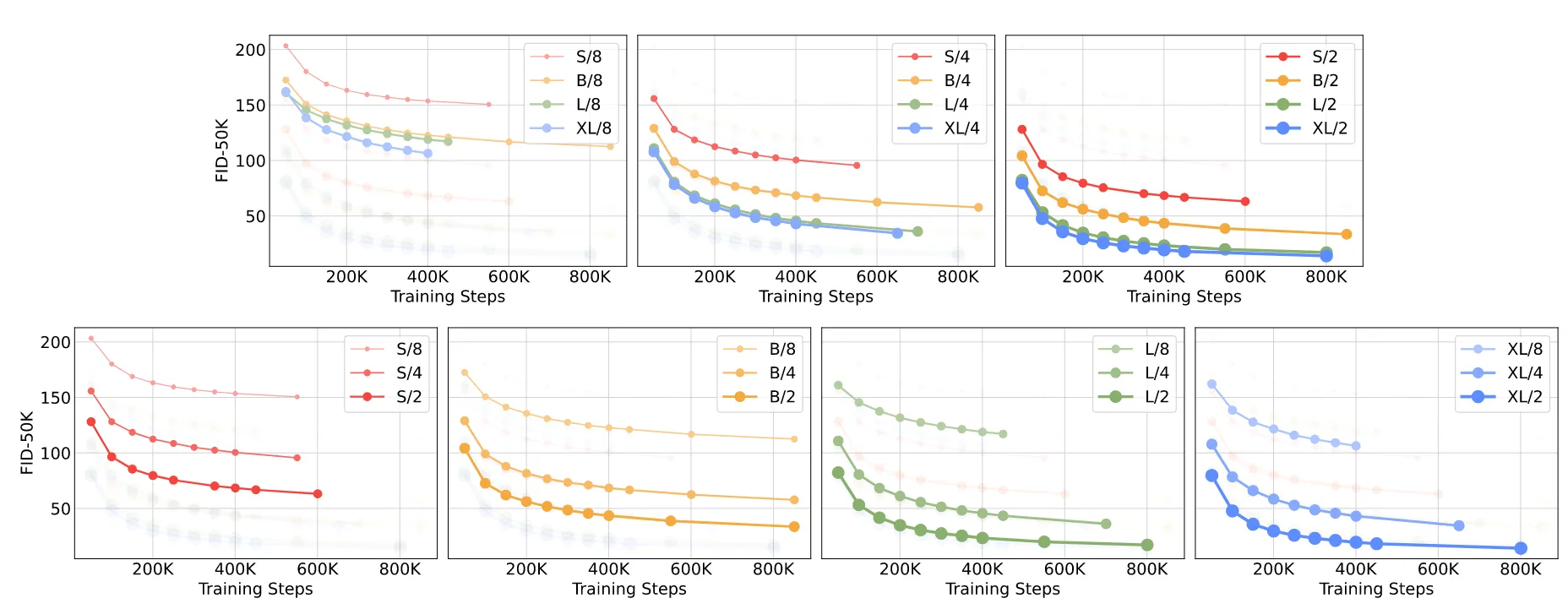
위의 그림은 이를 더 자세히 나타낸 것인데, 위의 그림은 모델의 사이즈별로 성능을 패치별로 더 자세히 나타낸 것이고, 아래의 그림은 동일한 모델에서 패치의 크기별로 성능을 나타낸 것이다. 이를 통해서 모델의 크기가 클수록, 패치의 크기가 작을수록 성능이 증가한다는 것을 다시 한번 확인할 수 있다.
DiT Gflops are critical to improving performance
또한 위의 그림의 아래부분을 통해서 패치크기를 통해서 성능이 증가할 수 있다는 것을 알았는데, 패치크기는 파라미터의 수는 바꾸지 않기 때문에 파라미터보다 Gflops이 성능에 영향을 준다는 것을 알 수 있다.
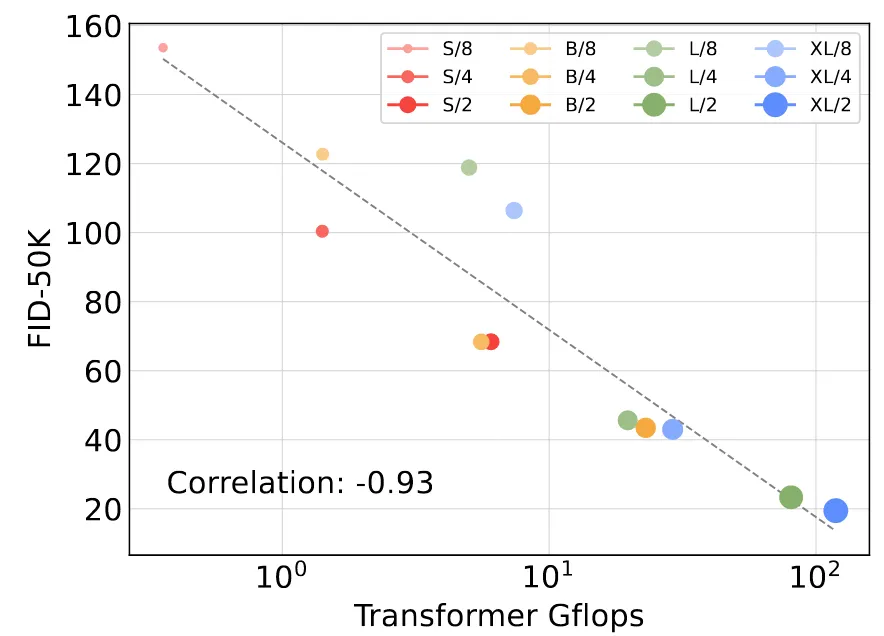
Gflops와 성능의 관계를 더 자세히 알아보기 위해서 2개의 관계를 위의 그림처럼 표시했다. 결과는 Gflops가 커질수록 성능도 증가한다는 것이다.
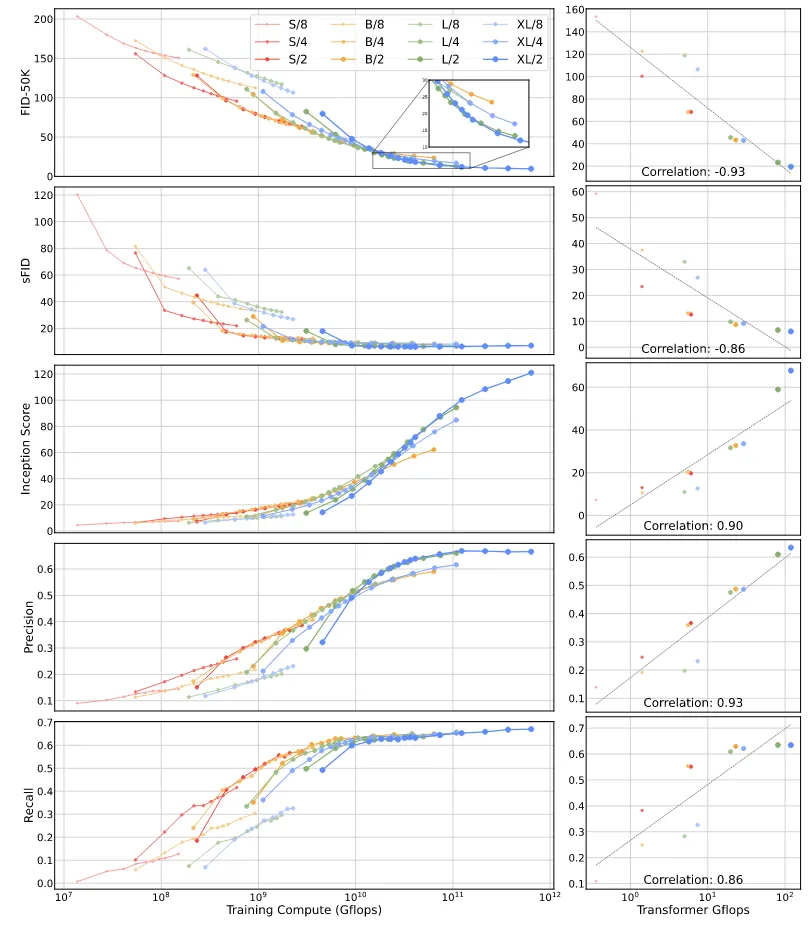
지금까지는 성능 증가는 FID에 대해서만 관계성을 나타냈는데, 다른 지표들에 대해서도 동일한 추세를 갖고 있음을 appendix의 그림을 통해서 확인할 수 있다.
Larger DiT models are more compute-efficient
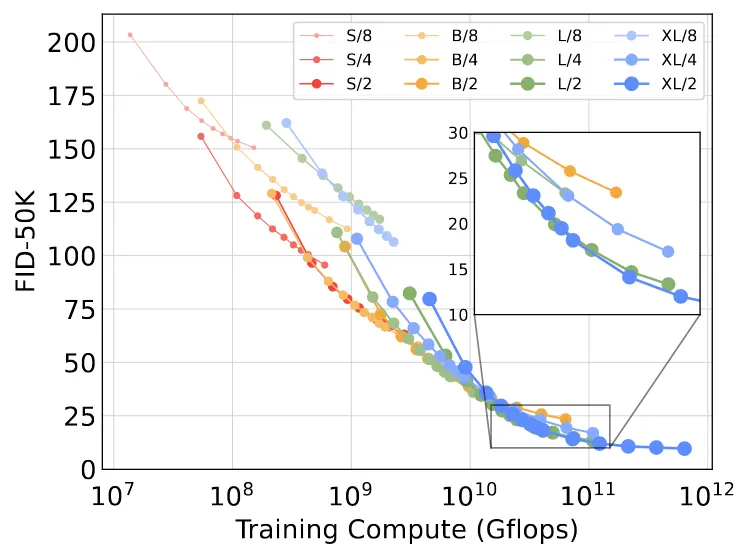
DiT 모델의 모든 경우에 대해서 모델과 패치를 하나의 표로 나타낸 것이다. 위의 표를 통해서 하고싶은말은 큰 모델이 더 계산이 효율적이라는 것이다. 위의 표에서 가로축 Training Compute는 Gflops X batchsize X training steps X 3의 값이다. 여기서 3은 backward pass가 forward pass에 비해 연산량이 2배 들기 때문에 대략적으로 3이라고 했다. 네모친 부분을 집중적으로 보면 학습이 길어질수록 결국 동일한 Training Compute에서 큰 모델이 더 좋은 성능을 나타내는 것을 알 수 있다.
Visualizing scaling

State-of-the-Art Diffusion Models
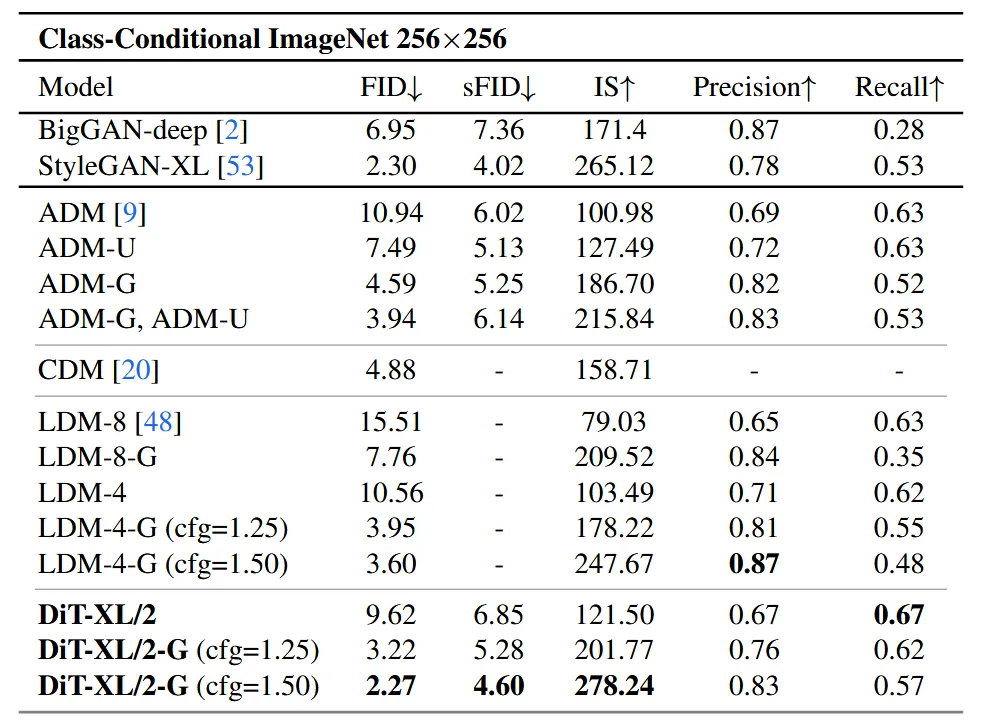
ImageNet 데이터셋의 256 해상도의 이미지에 대한 결과는 위의 표와 같다. 기존 Diffusion 모델들과 성능을 비교했을 때 가장 큰 모델을 썼을 때 성능이 가장 좋다. 참고로 G가 붙어있는건 Guidance를 사용한 결과이다.
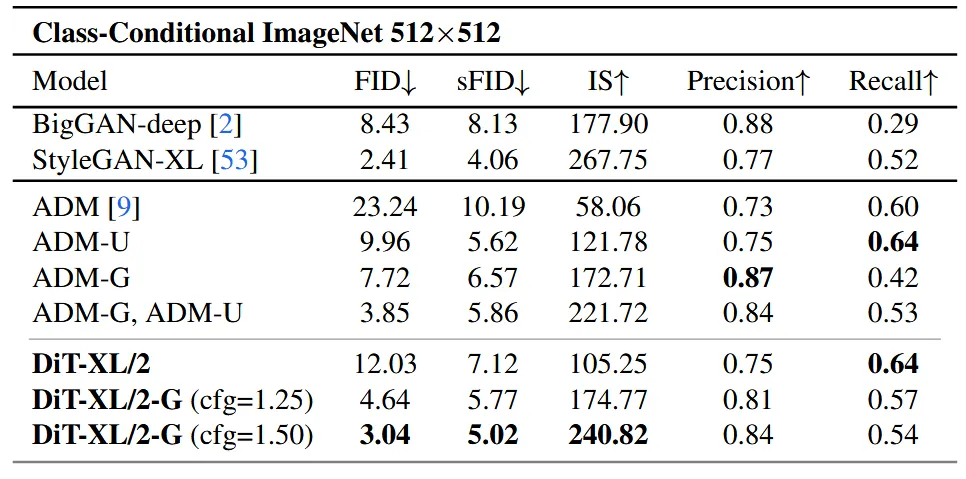
ImageNet 데이터셋의 512해상도에 대한 결과는 위와 같은데 동일하게 가장 좋은 성능을 기록했다.
Scaling Model vs. Sampling Compute
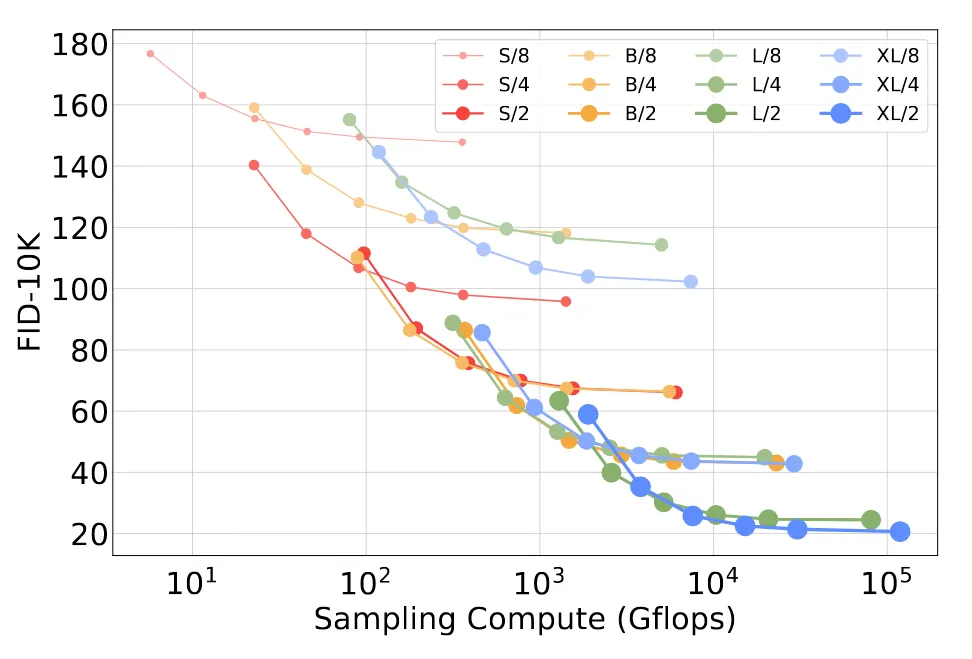
작은 모델에 대해서 더 많은 sampling step을 진행하면 큰 모델의 성능을 이길 수 있다는 것을 알려주는 부분이다.
Conclusion
결론적으로 해당 논문에서는 Diffusion 모델에 Transformer를 적용한 Diffusion Transformers(DiTs)를 제시했고, 이는 기존 모델들보다 적은 연산량으로 더 좋은 성능을 낼 수 있음을 증명했다. 추후 해당 모델은 Diffusion 모델에 적용되는 하나의 툴로 사용 되었기 때문에 알아두면 좋은 논문이다.
Code 실행 결과
DiT model은 Condition으로 label을 넣고 LDM 모델은 text prompt를 condition으로 넣기 때문에 DiT model에서 사용한 label의 class를 text prompt로 LDM에 넣어서 결과를 비교하도록 하겠습니다. 첫번째가 DiT이고 두번째가 LDM 결과이고 해상도는 512로 진행했습니다.
- A mascaw(Class 88)
Code 실행 결과
DiT model은 Condition으로 label을 넣고 LDM 모델은 text prompt를 condition으로 넣기 때문에 DiT model에서 사용한 label의 class를 text prompt로 LDM에 넣어서 결과를 비교하도록 하겠습니다. 첫번째가 DiT이고 두번째가 LDM 결과이고 첫번째 세트가 256해상도, 두번째 세트가 512 해상도입니다.
- A mascaw(Class 88)


- Golden Retriever (Class 207)


- Sports Car (Class 817)


- Pizza (Class 963)


- Volcano (Class 980)


생각보다 U-Net을 사용하는 LDM 모델이 더 좋아보인다.
