Style3D: Attention-guided Multi-view Style Transfer for 3D Object Generation[2024 arXiv]

3D 분야에서 style과 content image를 이용해서 3D를 생성하는 연구를 많이 못 봤는데, 이번 기회에 제대로 정리해보도록 하겠습니다.
3D Stylization
ARF, UPST-NeRF, StyleRF, 3DStyleNet, StylizedGS 등 다양한 3D style transfer 연구들이 나왔지만, 여전히 속도가 느리고 추가적인 학습이 필요합니다. 해당 논문에서는 빠르고 추가적인 학습이 필요없는 새로운 style transfer 방법을 3D에 적용했다고 했습니다. 어떤 방법들을 이용했는지 확인해보도록 하겠습니다.
Method
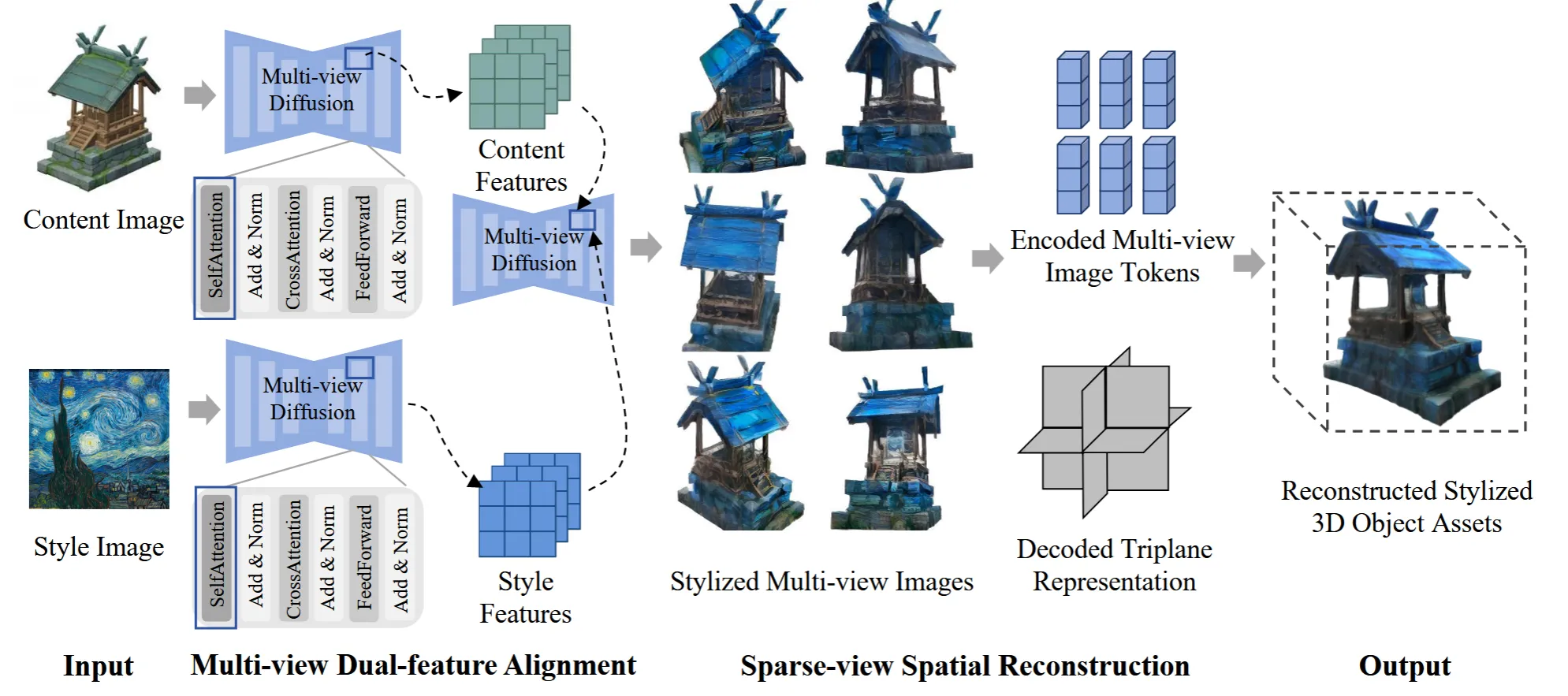
Multi-View Dual-Feature Alignment

우선 Multi-view Diffusion 모델로서 Zero123++를 선택했습니다. Zero123++는 어떤 시점 이미지가 들어가면, 특정 시점 6개의 이미지를 생성하는 모델입니다. 자세한 설명은 https://velog.io/@guts4/Zero123-a-Single-Image-to-Consistent-Multi-view-Diffusion-Base-Model-논문-리뷰 링크를 참조하시면 됩니다.
위의 그림을 보시면 2개의 diffusion 모델을 사용하는데, 위의 메인 모델은 기하학적인 특징을 학습해서 새로운 시점의 이미지를 생성하고, 아래의 diffusion 모델은 style을 학습하기 위한 보조적인 역할이라고 보시면 됩니다.
여기서 개인적으로 신기하면서 참신하다고 느낀게 Style같은 경우 그냥 encoding을 통해서 feature를 뽑을거 같았는데, Zero123++를 통해서 content image랑 동일하게 feature를 생성하는 방식을 나타냈다는 점입니다. 논문에서는 이렇게 동일한 방법으로 feature를 뽑을 경우 두 feature의 alignment가 좋아진다고 말했습니다.
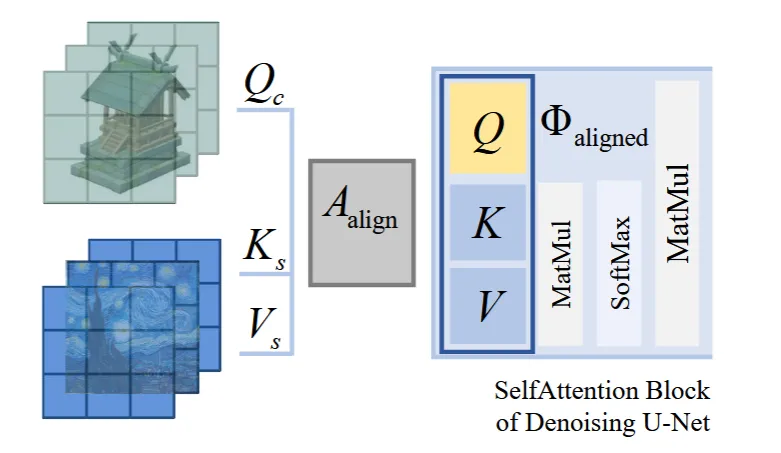
Content image에 대해서 생성된 초록색 위의 feature를 Content Features라고 하고, Style image에 대해서 생성된 파란색 아래의 feature를 Style Features라고 합니다. 이후에 content feature가 query로, style feature가 key와 value 값으로 돼서 selfattention을 진행합니다.
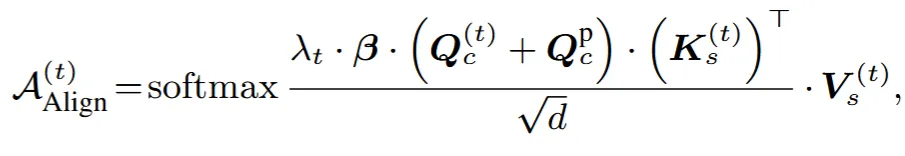
이때 일반적인 attention이 아니라 Content의 영향을 크게 줄지, Style의 영향을 크게 줄지 결정할 수 있도록 설계 했습니다. 로서 가 커질수록 content의 영향이 커지고, 가 커질수록 이전 스텝의 정보인 의 정보가 커지면서 content의 영향보다는 style의 영향이 더 커지게 됩니다.
Sparse-View Spatial Reconstruction

DINOv2Encoder
Style이 반영된 여러개의 이미지를 3D로 변환하기 위해서는 우선 encoding 작업을 진행해야합니다. 이때 OpenLRM처럼 transformer-based 아키텍처를 사용했습니다. DINOv2로 학습된 Enocder를 사용해서 Image token을 생성합니다.
Triplane Decoder
Encoder를 통해서 동일한 latent에 6개의 style이 적용된 이미지가 생성됐습니다. 이를 Triplance 공간으로 옮기기 위해서 Triplane Decoder를 사용합니다. Triplane은 X-Y, Y-Z, Z-X처럼 3개의 2D 평면을 통해서 3차원을 나타내는 방식입니다. Triplane에서 자연스럽게 3D 기하학적인 특성을 잡을 수 있고, 멀티뷰 정보를 통합하기에 용이합니다. 이에따라 카메라 위치나 좌표계를 정하지 않고도 다양한 시점에서 일관된 3D 스타일 적용이 가능하게 됐습니다.
FlexiCubes Intergration
Triplane에 멀티뷰를 통합한 정보를 mesh로 바꾸기 위해서 FlexiCubes 프레임워크를 사용합니다. SDF기반의 FlexiCubes를 활용하여 Marching cubes의 방법보다 더 정확한 기하학적인 결과와 style이 반영된 디테일한 요소들을 표현할 수 있습니다.
Mesh reconstruction의 결과를 증진시키기 위해서 추가적인 MLP를 사용해서 FlexiCUbes가 원하는 형태의 결과(SDF, Color, Weight)를 예측합니다.
Geometric Supervision
렌더링된 Depth map과 Normal 값이 실제 값들과 일치하도록 추가적인 학습을 진행합니다. 이를 통해 더 정교한 3D Representation 결과가 생성됩니다.
Regularization
FlexiCubes의 가중치와 deformation에 정규화를 적용해서 불필요한 왜곡을 방지합니다.
Experiments
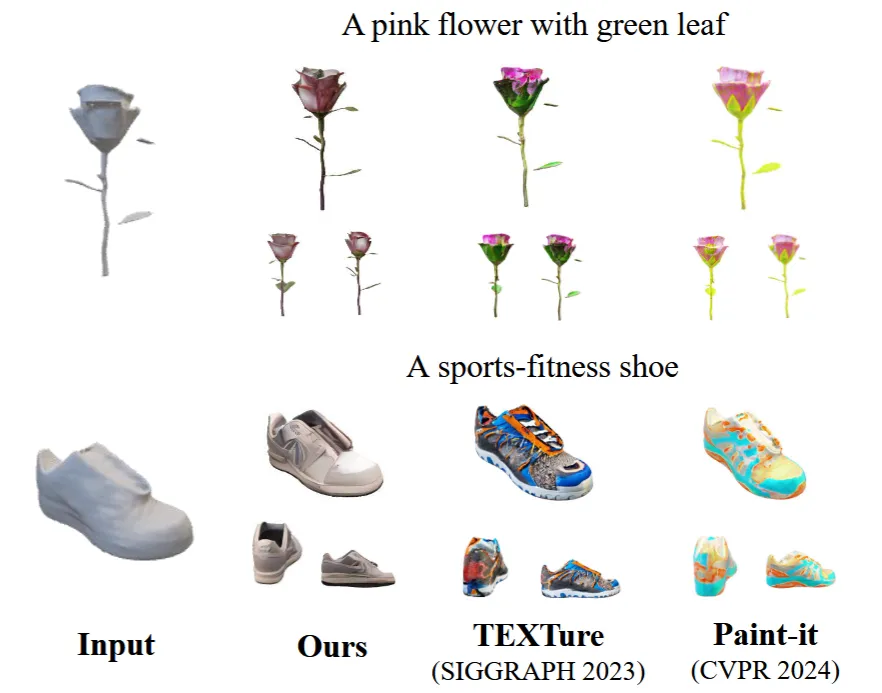
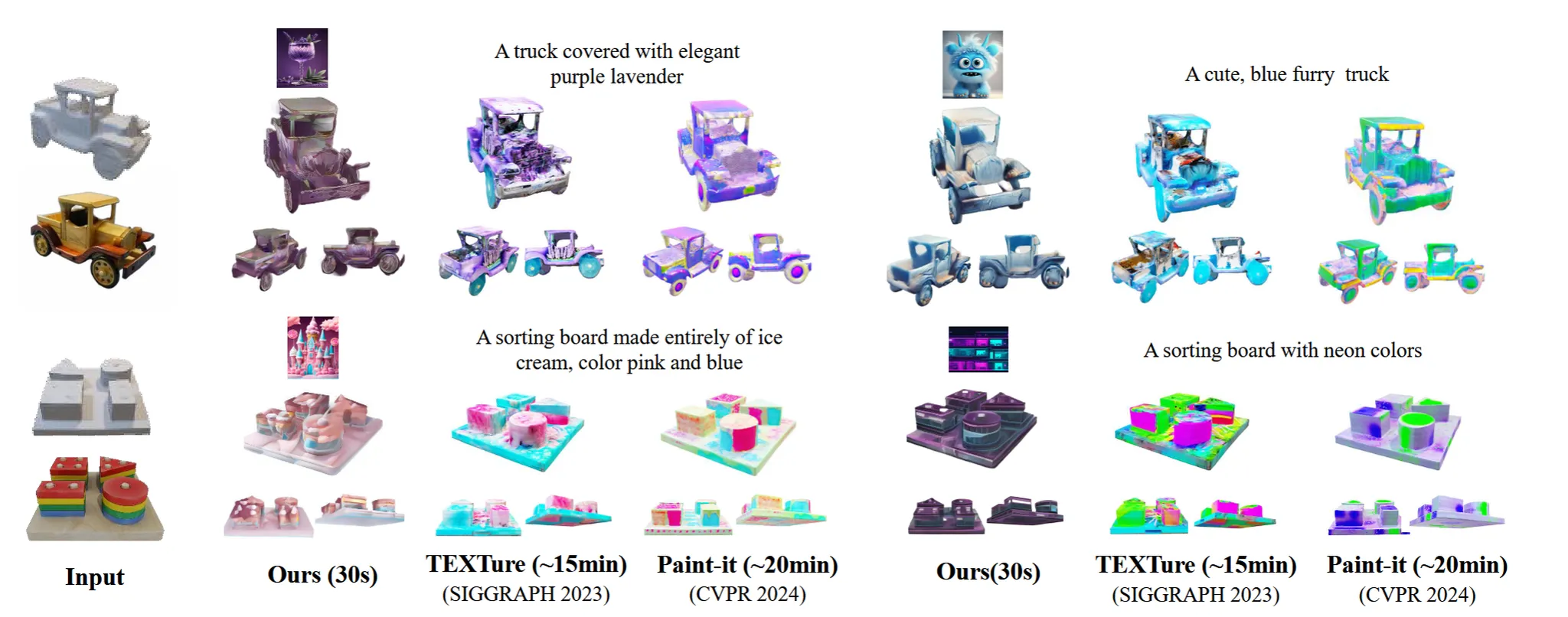
3D Mesh의 정면 사진을 Content image로, text prompt로 생성한 이미지를 style image로 생성해서 기존 Texturing 논문들과 비교했습니다. 결론적으로 조금 더 text prompt와 잘 대응되는 무난한 결과를 얻을 수 있었습니다. 하지만 위의 핑크색이 옅은 느낌은 있습니다.