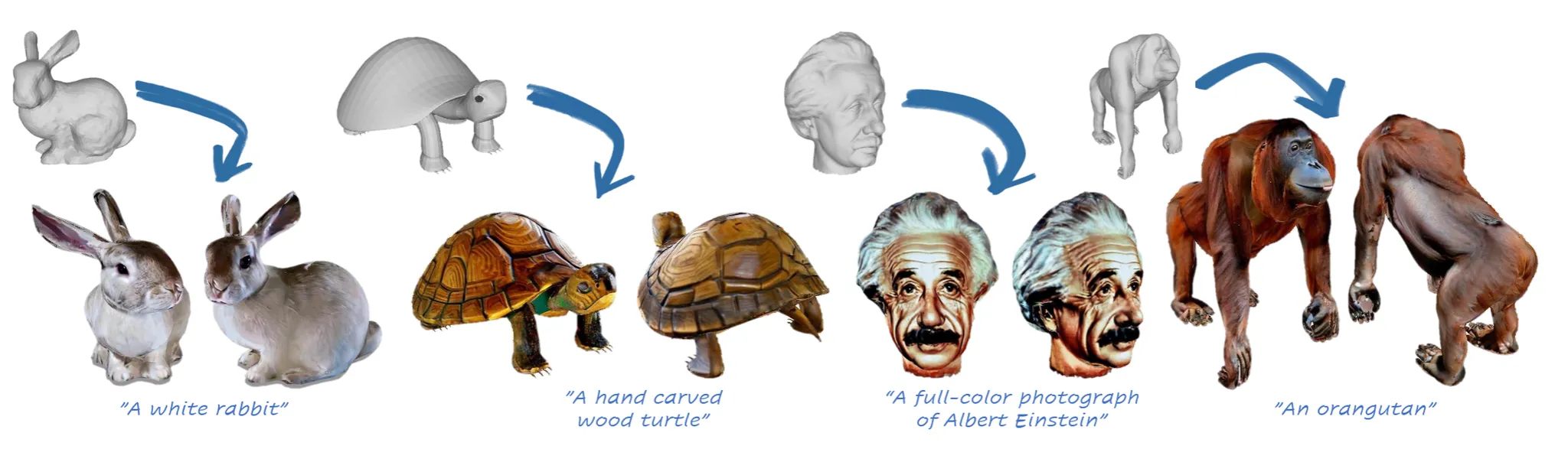
TEXture는 23년도에 나온 논문이지만 꾸준히 3D를 생성할 때 texture를 만드는 과정에서 사용됩니다. 빠른 시간과 좋은 성능 2마리 토끼를 모두 잡은 TEXture를 리뷰해보도록 하겠습니다.
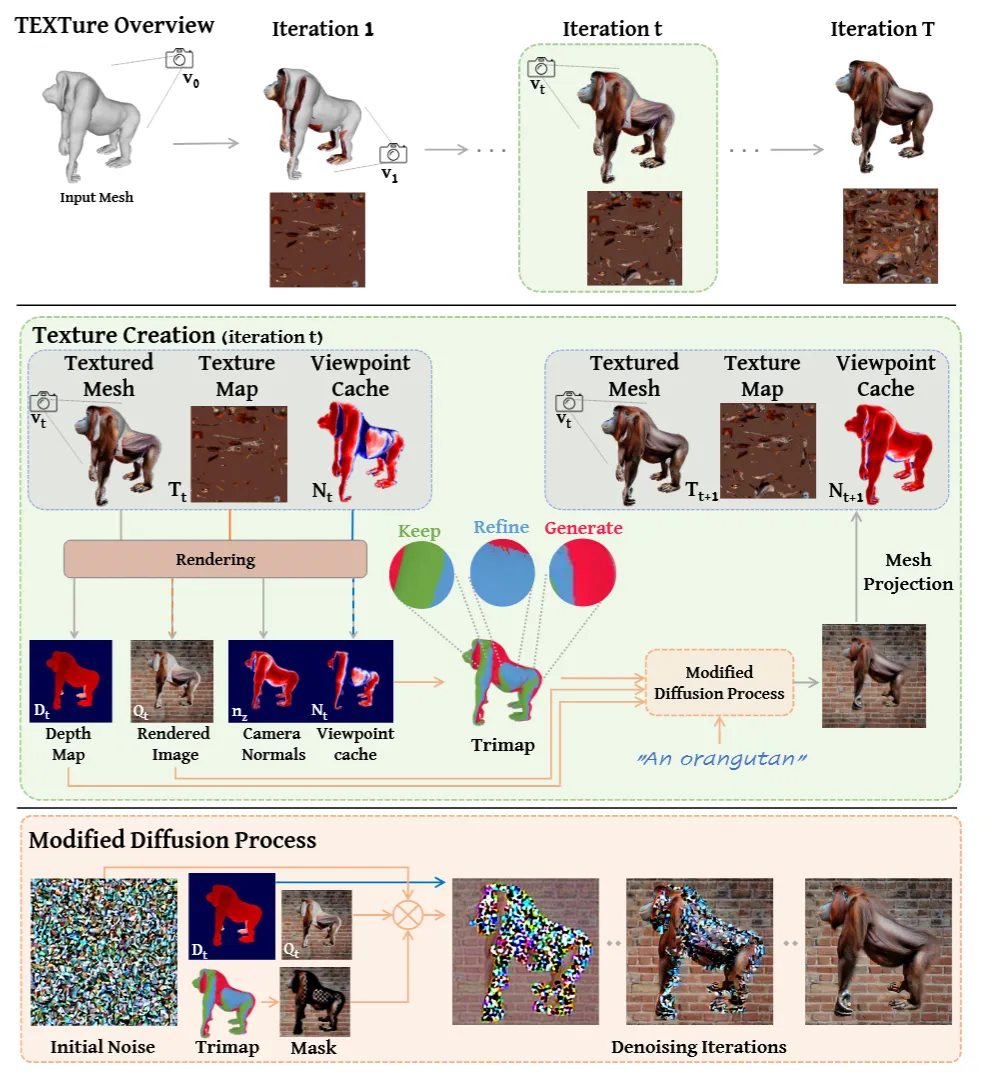
전체적인 아키텍처는 위와 같습니다. 자세히 어떻게 진행되는지 하나씩 살펴보기 전에 간단히 사전 개념들을 먼저 설명해드리겠습니다.
UV map
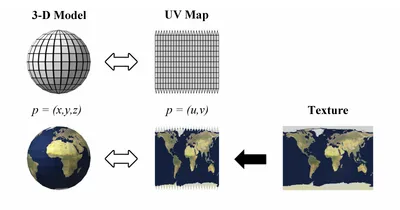
2차원 그림을 3차원 모델로 만드는 3차원 모델링 프로세스입니다. 조금 더 풀어서 설명해드리면 3D Mesh(위의 그림에서는 구)에 색칠을 하려고하는데 어떻게 색칠할지에 대한 정보가 UV Map에 존재하고 이를 씌우면 구에 texture가 입힌 형태가 됩니다. 어디에 어떤 색깔이 들어갈지는 다 매핑 정보로 저장되어 있습니다.
3D Mesh를 효율적으로 UV Map으로 변환해주는 과정은 XAtlas 라이브러리를 이용해서 자동화할 수 있습니다.
Text-Guided Texture Synthesis
Using Depth Diffusion Model to generate UV Map
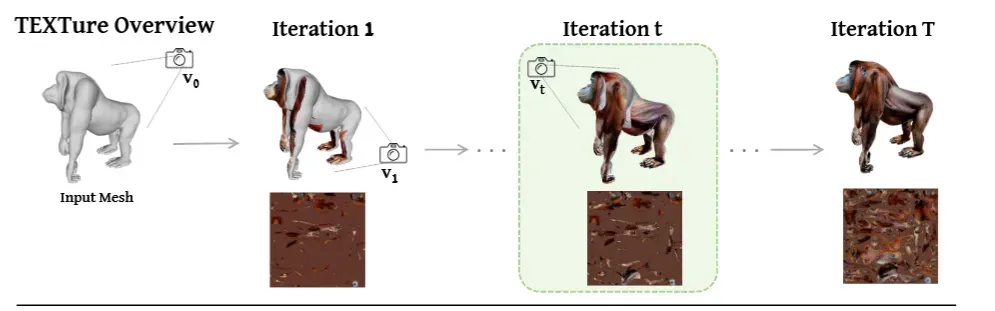
처음에 입력으로 들어간 Mesh를 이용해서 texture를 생성하기 위해서는 depth-to-image diffusion model()와 inpainting diffusion model() 2가지가 사용됩니다. 2가지 모두 stable diffusion 모델을 기반으로 만들어져있고, latent space를 공유하는 형태입니다. 생성 과정에서 UV Map은 XAtlas에 의해서 생성됩니다.
맨왼쪽의 시작 시점 은 r=0, =0, =60 입니다. 즉 구면 좌표계를 사용했는데 반지름은 0 위치에 대한 정보는 각각 0과 60입니다. 해당 시점에서의 depth map을 condition으로 넣어서 색칠된 이미지 를 생성합니다. 이렇게 생성된 시점에 해당하는 Color 정보인 를 UV Map에 대응시키기 위해서 다시 projection해서 atlas를 이용해서 를 생성합니다.
이렇게 특정시점에서 렌더링한 depth map을 이용해서 UV Map을 업데이트 하는과정이 T번 반복하게 됩니다. 하지만 각 시점에서 업데이트 한 결과가 일치하지 않기 때문에 global한 정보와 local한 정보를 consistency하게 하는 역할이 필요합니다.
Trimap Creation
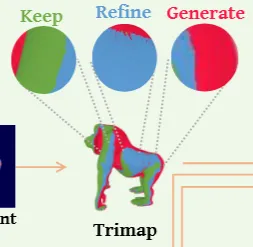
시점 가 주어지면 렌더링된 이미지를 3가지 영역(keep, refine, genreate)으로 나눕니다. 렌더링된 이미지에서 texture가 존재하지 않으면 generate, 존재하면 keep 또는 refine영역입니다. Texture가 존재하지 않은 영역은 생성하면되니까 generate는 문제 없이 texture를 생성. 만약에 texture가 존재한다면 이를 그냥 둘건지 아니면 업데이트 해야될지 정해야됩니다. 이때 keep은 그냥두는거, refine은 texture를 업데이트 하는 것입니다.
그러면 refine과 keep을 나누는 기준은 무엇일까요? 카메라 좌표계에서 삼각형의 face normal인 의 넓이입니다. 의 값이 클수록 화면과 수직에 가까워 고해상도로 텍스처링이 가능하고, 그러면 해당 시점에서 더 좋은 텍스처링이 가능하기 때문에 업데이트 하면됩니다. 따라서 의 값이 크면 refine, 작으면 keep이 됩니다.
- genreate: 텍스처링이 없는 부분으로 텍스처 생성
- 텍스처링이 있는 부분
- refine: 텍스처를 update
- keep: 텍스처를 그냥 둡니다.
Masked Generation
방금 keep 부분은 텍스처를 수정하지 않는다고 했으므로, 부분적으로 수정하기 위해서 Blended diffusion 모델을 사용합니다.
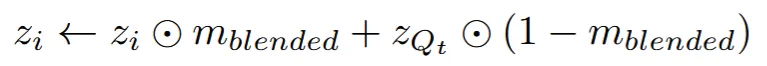
keep부분에 대해서 값을 0으로 설정해서 수정되지 않도록 하고, 나머지 refine과 generate 부분만 생성할 수 있습니다.
Consistent Texture Generation
Keep부분은 그대로 두고 generate 부분만 업데이트하다보니 같은 시점의 이미지라고 하더라도 전체적인 이미지가 일치하지는 않을 것입니다. 예를들어 원숭이의 오른쪽에서 텍스처를 업데이트한 부분이랑 원숭이의 위에서 텍스처를 업데이트한 부분은 다를 것이기 때문입니다. 이러한 부분을 막기 위해서 처음에 설명한 inpainting diffusion model()를 사용합니다. 해당 모델을 사용하면 전체적인 텍스처가 일치하는 경향이 많다고 합니다.
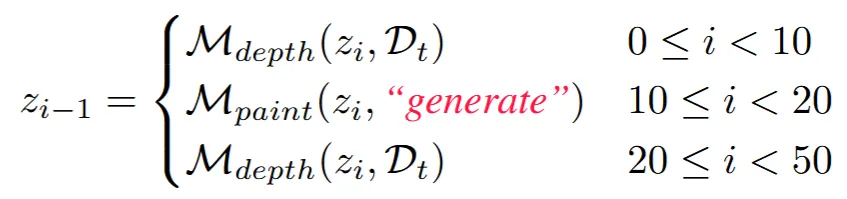
depth 기반 모델()와 inpainting 모델()의 이점을 모두 살리고자 섞어서 사용하게 됩니다. 주의해야 될 점은 inpainting 모델은 generate만 해당하고, refine에는 해당하지 않습니다. 왜냐하면 inapinting 모델은 텍스처를 수정하는데는 적합하지 않기 때문입니다.
Refining Regions
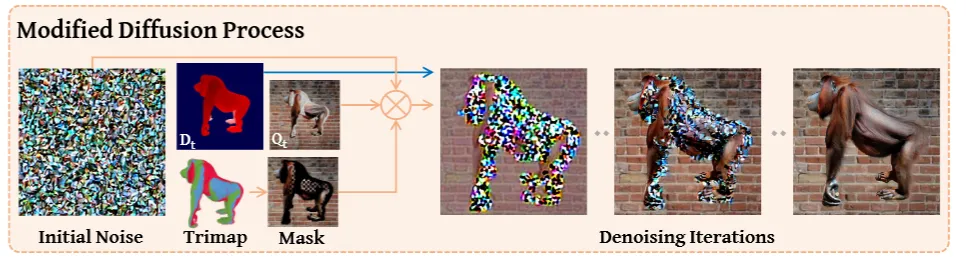
Refine영역을 업데이트 할 때 체커보드 마스크를 기반으로 업데이트 하면서 더 정밀한 업데이트를 할 수 있습니다. 우리가 refine하고자 하는 영역을 체커보드의 격자 형태로 나누고, 이 수많은 격자중에서 어떤 부분은 업데이트를 하고, 어떤 부분은 업데이트를 하지 않음으로써 기존 텍스처와 너무 달라지지 않게 업데이트를 할 수 있습니다. 위의 그림에서 오른쪽 부분에 노이즈가 들어간 많은 픽셀 중에서 몇몇 부분들은 업데이트 되고 몇몇 부분은 안되는 것을 확인할 수 있습니다.

위의 수식을 통해서 keep과 generate는 0과 1이라는 것을 확실히 알 수 있고, refine은 초기에는 방금 설명한 것처럼 부분적인 업데이트 방식인 checkerboard를 25 step 이후에는 모든 부분을 업데이트 하도록 설계 되었습니다.
Texture Projection
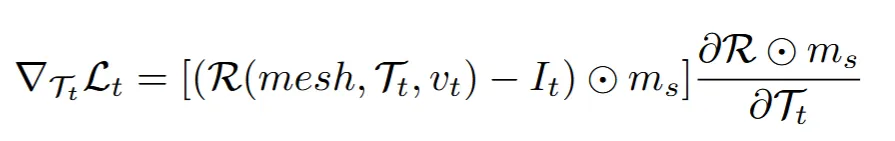
처음에 생성한 컬러 이미지 를 atla 와 일치시키기 위한 과정을 설명합니다. 위의 수식을 보시면 texture와 mesh를 이용해서 해당시점에 렌더링된 결과와 생성한 컬러 이미지 와의 차이를 최소화하는 것을 볼 수 있습니다.
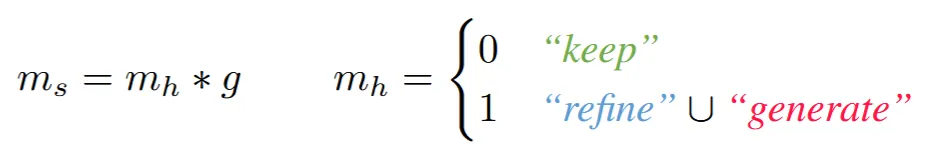
이 과정에서 텍스처가 매끄럽게 표현되기 위해서 mask 를 사용했는데 수식은 위와 같습니다. keep일 때는 업데이트 하지 않으니까 0이고, 매끄러움을 표현하기 위해서 2D Gaussian(g)를 추가했습니다.
Texture Transfer
이전에는 text prompt를 기반으로 UV map을 어떻게 잘 생성하는지에 대해서 설명했었다면, 이부분에서는 UV map이 이미 존재하는 mesh가 존재할 때, 이 텍스처를 어떻게 새로운 mesh에 적용할 수 있을까, 즉 texutre transfer을 어떻게 할 수 있을까를 설명하는 부분입니다.
Spectral Augmentations

입력으로 들어오는 메쉬는 텍스처가 입혀진 형태이고, 이를 다양한 기하학적 변형(deformation)을 통해 텍스처와 mesh의 기하학적 구조를 분리하고, 일반화된 텍스처 표현을 학습하려고 하는 것입니다. 위의 그림을 보시면 입력으로 들어온 소가 오른쪽처럼 변하는 것을 확인할 수 있습니다.
Laplacian Matrix 설명: https://ysg2997.tistory.com/36
변형 과정을 수행하기 위해서는 Laplacian Spectrum을 사용합니다. Laplacian Spetrum은 vertex나 edges와 같은 기하학적 정보를 수학적으로 표현한 행렬로서 주파수 구성요소는 eigen value와 eigen function입니다. 일반적으로 저주파는 mesh의 전반적인 정보를, 고주파는 mesh 표면의 미세한 세부 특징을 담고 있습니다. 논문에서는 물체의 디테일한 부분은 변경하지 않고 큰 부분만 변경하면서 다양한 mesh에서의 텍스처를 학습하고 싶다고 말씀하셨습니다. 따라서 저주파 고유함수를 랜덤하게 선택하고, 선택된 고유함수의 값에 비례하여 메쉬의 각 점을 팽창 또는 수축시킨다. 이 변형은 부드러운 곡률 변화를 유지하도록 설계된다.
Texture learning
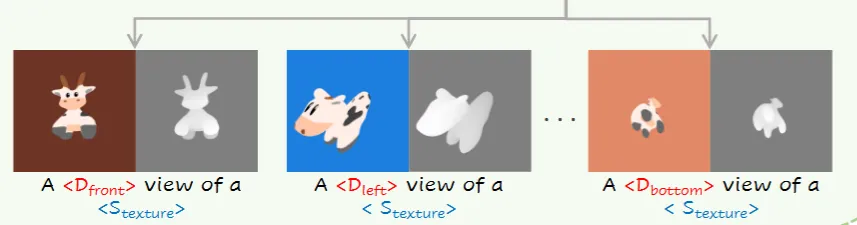
위에서 변형된 mesh들에 대해서 texture를 학습하는 단계입니다. 이때 6개의 viewpoints(left, right, overhead, bottom, front and back)에 대해서 해당 시점의 이미지와 depth map을 사용합니다. 텍스트 프롬프트를 “a <> photo of a <>”로 입력해서 는 6개의 시점에서의 텍스처 정보, 는 해당 텍스처에 대한 유니크한 정보를 학습하게 됩니다.
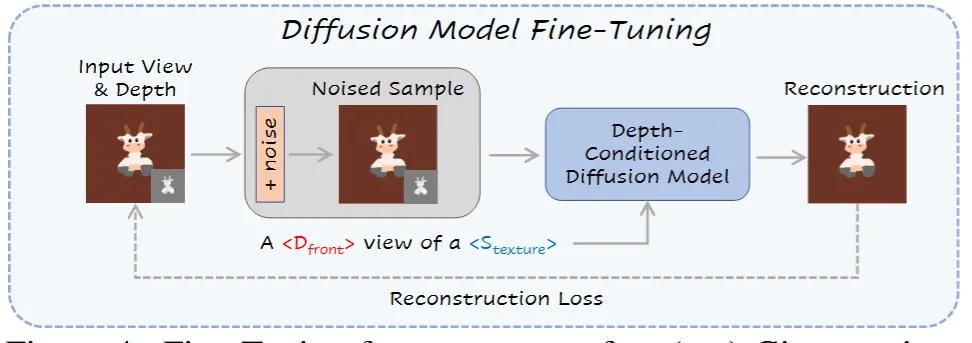
Dreambooth에서 사용한 방식으로 diffusion모델을 fine-tuning 하게 되는데 여기서 타겟팅 하는 토큰이 이전에 말한 와 가 됩니다.
Texture from Images
한장의 입력 이미지를 기반으로 mesh의 텍스처를 생성하는 Task에 대한 설명입니다. 사전 학습된 saliency network를 이용해서 이미지의 배경을 제거하고, scale과 crop augmentation을 적용해서 랜덤 색상을 갖고 있는 배경에 붙입니다. 이렇게 학습을 하면 explicit reconstruction 없이 텍스처를 잘 학습해서 3D에 적용할 수 있다고 합니다.
Limitations

- Global consistency 문제
오른쪽 그림을 보면 물고기의 앞면과 뒷면의 결과가 불일치하는 것을 확인할 수 있습니다. 예를들어서 눈의 크기 비닐의 색감 등이 다릅니다. 모델자체가 뷰끼리의 일치를 하도록 설계 되긴했지만 완전히 반대편에서의 텍스처링은 문제가 되고 있습니다.
- 부족한 view point
8개의 고정된 view point만 사용했기 때문에 이는 복잡한 기하 구조를 갖는 mesh에 적절한 텍스처를 입히기 어려울 수 있습니다.
- Detph conditiong model의 한계
왼쪽 그림과 같이 깊이 정보와 생성된 이미지가 일치하지 않을 경우, 텍스처 투영이 불완전하며 이후 수정이 어렵습니다.
