


Input mesh를 target prompt에 맞게 deformation하면서 색을 입히는 논문입니다. 2022년에 나온 논문이지만 이 분야에서 거의 base가 되는 논문이기 때문에 읽어보게 됐습니다.
Method
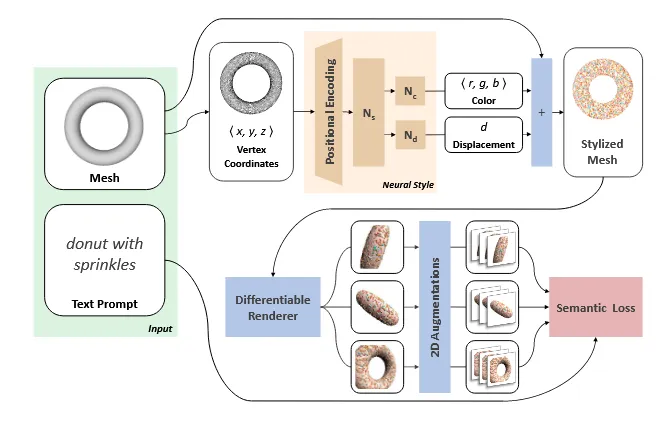
3D Mesh의 형태는 고정해 두고, 색상과 표면의 작은 변형을 text에 맞게 변형하는 과정입니다.
조금 더 자세히 설명하자면, 입력으로 들어오는 3D mesh의 각 정점들과 face는 고정됩니다. 최종적으로 학습하는 건 Neural Style Field(NSF)로서 메시 표면의 각 점의 RGB 색상 값과 normal의 displacement를 예측합니다. NSF를 학습하는 방법은 NSF가 생성한 mesh 를 여러 view에서 렌더링 하고, augmentation을 진행해서 target text prompt와 clip similarity를 계산해서 높이는 것입니다.
Neural Style Field Network
오른쪽 위의 Stylized mesh를 렌더링 할 때 triangle의 개수를 늘릴수록 렌더링 되는 해상되는 높아지고, 여력이 된다면 이 값은 쉽게 늘릴 수 있습니다. 논문에서는 180K triangles를 선택 했습니다.
NSF는 mesh의 각 정점에 대해 색상과 미세한 변형을 예측하는 MLP입니다. MLP는 3개로서 는 전체 스타일 latent 표현을 생성하고, 는 displacement (-0.1,0.1 사이의 값을 갖도록 설정)를 예측하고, 는 생상 를 예측합니다.
참고로 MLP에 들어가기 전에 각 정점들은 (0,1)사이의 값을 갖도록 normalization을 진행합니다.
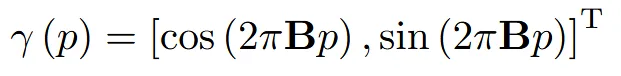
MLP가 섬세한 스타일을 배우기 어렵다는 점 때문에 Fourier positional encoding을 사용합니다.

실제로 위의 사진에서 -FFN 부분이 positional encoding을 안한 결과인데 차이가 많이 나타나는 것을 알 수 있습니다.

예측한 는 위와 같이 각 점에 약간의 변형을 가합니다. 이후 예측한 를 통해서 해당 점의 색상을 칠합니다.
Text-based correspondence
Text2Mesh는 stylized mesh를 여러 각도에서 2D로 렌더링하고, 여기에 augmentation을 적용한 후 CLIP 임베딩 공간에서 텍스트와 유사도를 비교합니다. 이를 통해 스타일이 텍스트에 가까워지도록 학습합니다. 색상과 지오메트리 성분을 따로 loss에 반영해 균형 잡힌 학습을 유도합니다.
조금 더 자세히 설명하자면 정해진 뷰로 렌더링할 때 색깔 정보가 있는 Mesh()로부터 를 렌더링하고, 색깔 정보가 없는 Mesh()로부터 를 렌더링 합니다.
이후에 2D augmentation을 에는 global(회전등), local(crop등) 2가지로 진행하고, 에는 local 1가지만을 진행합니다.
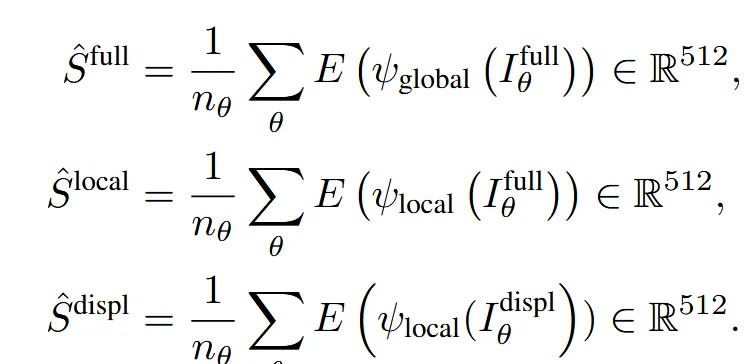
위와 과정을 모두 진행하면 최종적으로 3가지 Embedding 값을 얻게 됩니다.

Text prompt도 마찬가지로 CLIP을 이용해서 임베딩 값을 생성합니다.

마지막으로 렌더링 이미지 임베딩의 평균과 text 임베딩을 consine similarity를 통해서 학습하게 됩니다.
참고로 3가지 임베딩을 생성하는 부분에서 과 결과는 를 모두 학습시키고 은 만 학습하도록 합니다. 당연히 색상정보가 없기 때문입니다.
Viewpoints and Augmentations
우선 Uniform한 view로부터 렌더링한 후 각 렌더링 값과 text prompt와의 CLIP similarity를 구합니다. 이후 가장 높은 값을 anchor view로 선택합니다. Anchor view를 기준으로 주변 각도에서 (=5)개 시점을 랜덤하게 샘플링합니다.
Augmentation global: random perspective transformation
Augmentation local: both a random perspective and a random crop that is 10% of the original image
Experiments


Ablation

Positional Embedding

Image Target

Limitations
Text2Mesh는 메시의 geometry과 텍스트 스타일 사이에 자연스러운 연결이 있다고 가정합니다. 하지만 만약 서로 너무 관련 없는 스타일을 적용하면, 원래 메시의 형상이 무시되거나 사라질 수 있습니다. 이럴 땐, 텍스트에 객체 카테고리도 포함시키는 것이 도움이 됩니다.
