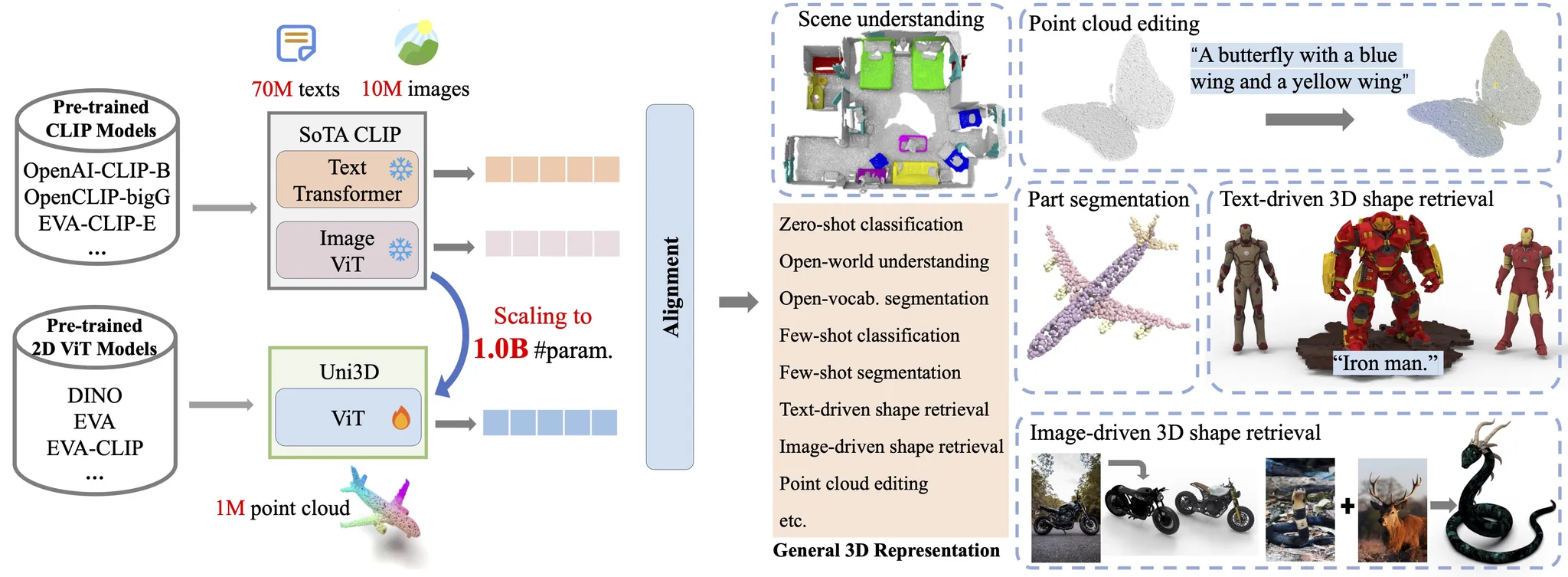
2024년 ICLR spotlight 논문으로서 3D에서 Retrieval을 할 때 사용되는 모델입니다. 어떻게 2d 임베딩과 3d 임베딩을 매칭시켜서 retrieval에 사용되는지 궁금해서 논문을 읽게 됐습니다.
Method
UNIFIED 3D REPRESENTATION
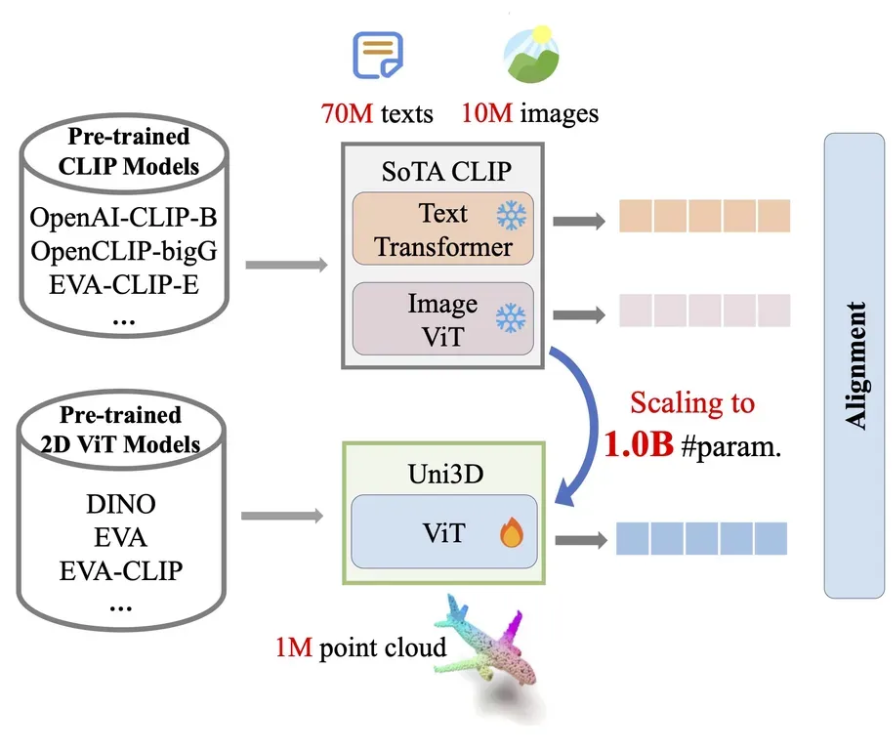
Uni3D는 기존 2D ViT 구조를 그대로 활용해 3D 데이터에 적용 했습니다. ViT가 이미지를 입력으로 받기 때문에 이미지 패치를 사용하는데, Uni3D는 Point Cloud를 입력으로 받기 때문에 Point Tokenizer를 사용합니다.
Point Tokenizer는 farthest point sampling(FPS) 방식으로 점들을 고르고, kNN을 이용해서 각 중심점 주위로 k개의 이웃점을 묶고, 그 패치를 작은 pointNet을 사용해서 하나의 토큰 벡터로 바꿉니다. 이렇게 나온 토큰 벡터가 이미지 패치 역할을 하면서 Transformer에 들어가게 됩니다. 해당 방식은 PointBERT에서 사용한 방식을 그대로 사용한 것입니다.
Scaling Up Uni3D
과거 3D Representation 학습은 대부분 소규모 데이터셋에 의존하고, 특정 태스크에 최적화된 3D 전용 구조를 설계하는 데 집중되었습니다. 하지만 이러한 구조들은 복잡한 연산이 필요해 모델 크기를 키우기 어려웠습니다.
Uni3D는 2D Vision Transformer(ViT) 구조를 그대로 사용함으로써 구조적 단순성과 일관성을 유지하고, 2D/NLP 분야에서 입증된 확장 전략을 그대로 활용할 수 있어 Tiny부터 Giant까지 손쉽게 확장 가능합니다. 이 덕분에 대규모 이미지-텍스트-포인트 데이터셋을 활용한 학습이 가능해졌습니다.
Initializing Uni3D
기존 3D 모델은 모델 크기가 커질수록 오버피팅과 수렴 불안정 문제가 발생했습니다. 이를 완화하기 위해 3D 전용 사전학습 방법이 사용되지만, 계산 비용이 크고 3D 데이터가 부족하다는 한계가 있습니다.
반면, Uni3D는 ViT와 동일한 구조를 사용함으로써, 2D나 멀티모달 도메인에서 사전학습된 대형 모델의 가중치를 그대로 초기화에 활용할 수 있어, 학습 안정성과 효율성이 크게 향상됩니다
MULTI-MODAL ALIGNMENT
Uni3D는 Point Cloud, Image, Text를 동시에 align하는 멀티모달 학습을 수행합니다.
Datasets
Data: OpenShape에서 정의한 방식을 그대로 사용(Objaverse, ShapeNet, 3D-FUTURE, ABO)
- Data process
Point Cloud: Mesh → 10,000개 point 추출(RGB 포함)Image: 10개 시점 이미지 렌더링Text: 3D 객체를 설명하는 Text label 생성
Objective
CLIP을 통해서 Image feature(fI)와 Text feature(fT)는 잘 학습되어 있기 때문에 Point Cloud feature(fP)만을 학습하는 것을 목표로 합니다. Contrastive loss를 통해서 Point-Image-Text representation이 가까워지도록 하는것을 목표로 합니다.
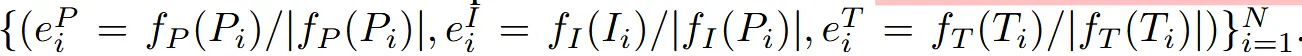
전체적인 수식은 CLIP에서의 수식과 동일합니다. 우선 feature들을 정규화 시킵니다.
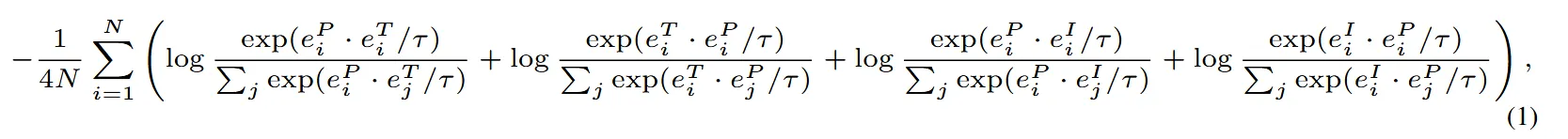
이후 앞에 2개의 수식은 Point와 Text의 align, 나머지 2개 수식은 Point와 Image의 align이 전부입니다.

여기서 앞에 2개는 머가 다른거야? 싶을 수 있는데 분모의 값을 보면 첫번째 항은 모든 Text에 대해서 곱하기 때문에 Anchor가 Point이고, 이러면 Point가 Text를 닮도록 학습됩니다. 반대로, 두번째 항은 모든 Point에 대해서 분모가 나타나 있기 때문에 Anchor가 Text이고, Text가 Point를 닮도록 학습됩니다.
쉽게 말해서 그냥 방향성이 있기 때문에 양방향성을 고려하도록 모델을 설계 했습니다.
참고로 τ는 learnable temperature입니다.
Uni3D는 CLIP을 기반으로 학습되기 때문에 CLIP의 성능이 높아질 경우 자연스럽게 Uni3D의 성능도 높아집니다.
Experiments
zero-shot shape classification
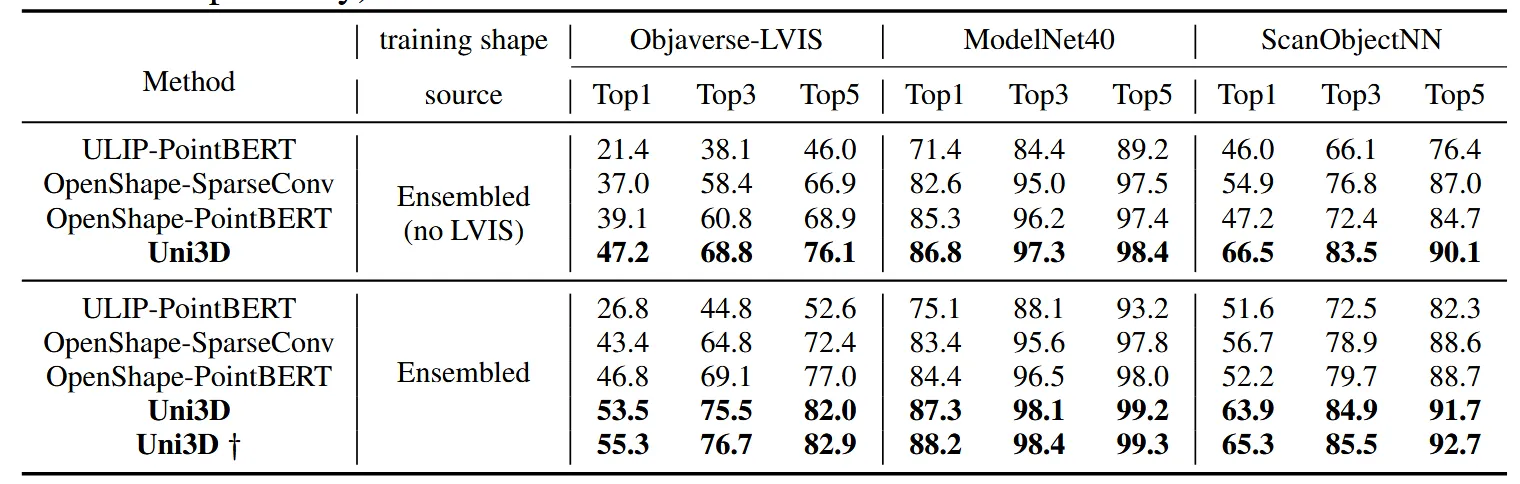
Dataset: ModelNet(10,000개, 무색), ScanObjNN(2,048개, 무색), Objaverse-LVIS(10,000개, 컬러 있음)
실험설정: Ensembled: 4개 데이터 모두 사용(테스트하는 카테고리는 제외), Ensembled(no LVIS): Objaverse-LVIS 데이터셋 제외
3가지 데이터셋에 대해서 zero-shot classification 성능을 비교했습니다. 실험 결과를 보면 Uni3D가 압도적으로 좋은 것을 알 수 있습니다. Ensembled에서 Uni3D가 서로다른 성능인 이유는 언급하지 않았는데 아무래도 어떤 ViT를 쓰느냐에 따라 성능이 달라질 수 있을 것입니다.† 기호가 붙은게 최고 성능을 나타냅니다.
OPEN-WORLD UNDERSTANDING

Uni3D는 실제 3D 스캔 데이터로 학습하지 않았음에도 불구하고, 다양한 SoTA 방법들을 뛰어넘는 성능을 보여주며, open-world에서의 제로샷 인식 성능이 매우 우수함을 입증했습니다.
POINT CLOUD PAINTING

Uni3D는 단순히 3D 객체를 인식하는 데 그치지 않고, 텍스트에 맞게 3D 포인트 클라우드의 색을 입히는 Point Cloud Painting 작업도 수행할 수 있습니다. 이는 Uni3D가 실제로 텍스트 의미와 연결된 3D 개념들을 학습했다는 강력한 증거입니다.
CROSS-MODAL RETRIEVAL

Uni3D는 이미지나 텍스트를 기반으로 가장 유사한 3D 모양을 찾아낼 수 있는 cross-modal retrieval 능력을 갖추고 있습니다.
사용 방법은 각 3D 객체에 대해서 Uni3D를 이용해서 임베딩 값을 미리 추출해둡니다.
Query
- CLIP Image Embedding
- CLIP Text Embedding
- Two CLIP Image Embedding Mean
Query와 미리 저장한 임베딩 값들 사이의 cosine similarity로 top-k개 3D 모양을 kNN 방식으로 검색합니다.
