Wonder3D: Single Image to 3D using Cross-Domain Diffusion & Wonder3D ++ 논문 리뷰

Zero123가 새로운 시점의 RGB 이미지만을 생성해준다면, Wonder3D는 새로운 시점의 depth map까지 생성해주는 논문입니다. 이를 이용해서 3D를 생성하게 되면 빠르고 정확한 3D asset을 생성할 수 있다고 언급했습니다. 그러면 어떻게 새로운 뷰에서 depth map을 생성하고, 이를 이용해서 3D를 만들 수 있는지 알아보도록 하겠습니다.
Method
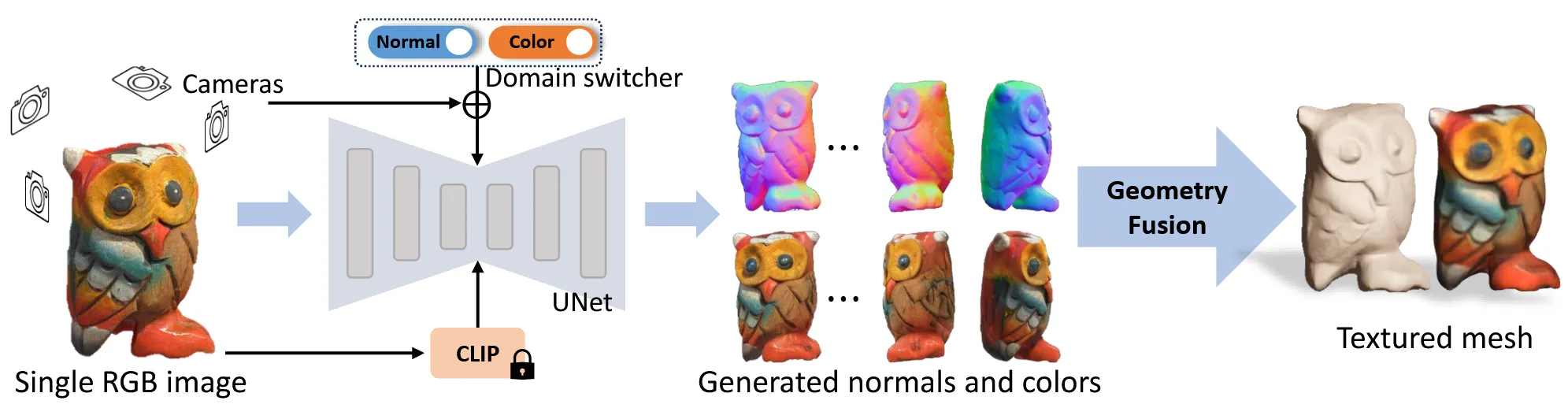
Consistent Multi-view Generation
Zero123의 논문 같은 경우 출력값으로 카메라 시점에 해당하는 한장의 이미지만 생성합니다. 이와 달리 SyncDreamer나 MVDream 같은 논문들은 여러개의 출력 이미지를 생성하도록 설계해서, 다른 뷰끼리의 attention mechanism을 진행해서 뷰끼리 정보 교환을 할 수 있도록 설계 되었습니다.
Wonder3D에서도 여러장의 이미지를 생성하고 U-net의 self-attention을 cross-attention으로 변환해서 서로 다른 시점끼리 정보를 교환할 수 있도록 설계합니다.
Cross-Domaion Diffusion
현재 모델의 설계상 Diffusion 모델은 rgb image와 depth map 2가지를 생성합니다. 하지만 일반적인 Diffusion 모델은 rgb 이미지만을 생성하기 때문에 이를 수정하는 방법이 필요합니다.
단순히 Diffusion 모델이 출력하는 이미지가 3차원이기 때문에 여기에 차원을 추가해서 depth를 예측하게 할 수 있지만, 이렇게 된다면 가중치를 사용할 수 없기때문에 좋지 않은 결과가 나옵니다.
아니면 2개의 Diffusion 모델을 사용해서 depth map을 생성한 후, 이를 condition으로 이용해서 rgb 이미지를 생성할 수 있지만 이렇게 될 경우 계산 비용이 증가하고, 성능도 좋지 않다고 합니다.
Domain switcher
따라서 논문에서는 domain switcher라는 방법을 사용했습니다. Domain switcher는 다른 도메인을 레이블링 해주는 1차원 벡터입니다. 레이블링된 정보는 positional encoding(nerf에서 사용된 방법)을 한 후 time embedding 값을 concate해서 U-net에 입력됩니다.
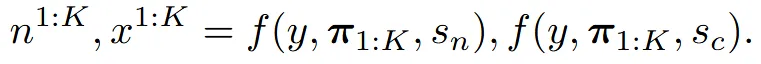
위의 수식에서 가 카메라 시점 정보이고, s가 domain swticher이고, y가 이미지입니다. 따라서 이미지가 들어가고, 특정시점의 카메라 정보와 normal인지 image인지에 대한 레이블 정보를 이용해서 normal과 image를 예측합니다. Domain swticher는 1차원 벡터의 가벼운 정보이기 때문에 사전 학습된 가중치를 사용하는데 큰 영향을 주지 않고 좋은 성능을 낼 수 있습니다.
Cross-domain attention
Domain switcher로 normal과 image를 생성할 수 있게 됐지만, 생성되는 결과끼리의 기하학적으로 일치하는 결과는 아닙니다. 따라서 normal과 image끼리의 정보교환이 일어날 수 있도록 2개의 domain에 대해서도 cross-attention을 진행하게 됩니다. 이 방식이 cross-domain attention입니다.
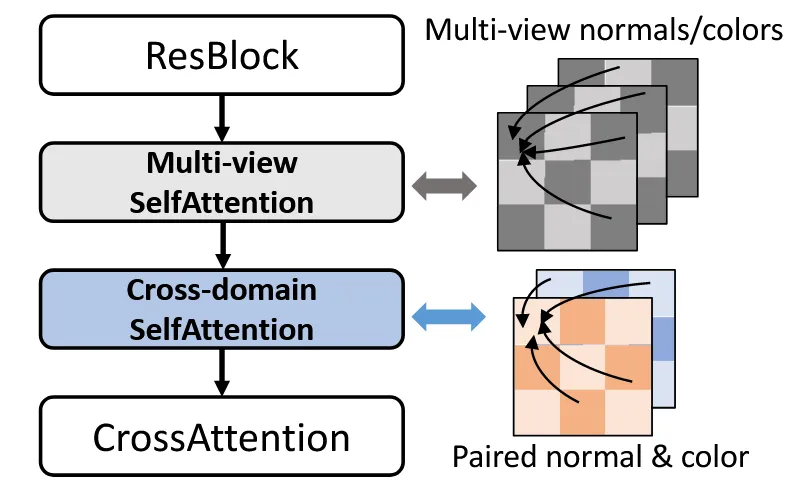
U-Net 모델에서 우선 서로 다른 시점 정보를 공유하기 위해서 multi-view self attention을 진행하고, 그다음에 서로다른 도메인의 정보를 공유하기 위해서 cross-domain self attention을 진행하고 마지막으로 방금 진행한 2가지 정보를 합치기 위해서 cross attention을 진행합니다.
Textured Mesh Extraction
SDF(signed distance field) : https://en.wikipedia.org/wiki/Signed_distance_function
들어가기에 앞서 제가 SDF 개념을 잘 몰라서 해당 개념을 간단히 설명하고 넘어가도록 하겠습니다. 자세한 설명은 위의 위키피디아 링크를 참조하시면 됩니다.
SDF는 물체의 표면 안쪽에 존재할수록 더 작은 음수 값을, 물체 표면의 바깥일수록 더 큰 양수값을 갖습니다. 이를 통해서 3D 공간에서 특정 점이 객체 표면에서 얼마나 멀리 떨어져 있는지를 나타낼 수 있습니다.
Neus에서는 2D정보를 이용해서 3D를 생성하기 위해서 처음에 SDF(signed distance field)를 사용해서 point cloud를 얻었습니다. SDF를 이용해서 3D를 생성하는 Neus 방법을 그대로 사용하려면 많은 시점의 이미지가 필요하고, 현재 sparse한 뷰의 정보만 갖고있는 상태에서 이는 적절하지 않은 방법입니다. 따라서 새로운 방식의 geometric-aware optimization scheme를 제시합니다.
Optimization objectives
이전단계에서 얻은 normal maps(), color images(), 그리고 segmentation model을 이용해서 얻은 object mask()를 이용해서 픽셀 기반 업데이트를 하는 방식을 선택합니다(mask는 normal map과 color images 둘다에서 왔다고 하는데 어떤걸 이용해서 생성한지는 안나와 있습니다). 무작위로 샘플링한 픽셀과 이에 대응되는 world space상에서의 ray를 이용해서 수식 를 만듭니다(g:normal, h: color, m:mask, v: ray direction)
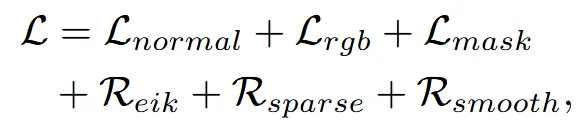
이제 위에서 구한값들을 이용해서 loss function을 구합니다.
: 추후에 설명
: 렌더링된 픽셀 색깔 와 간의 MSE loss
: 렌더링된 마스크 와 간의 binary cross-entropy loss
: Unit length의 SDF gradient를 조정해주는 eikonal regularization
: SDF의 floater를 피하기 위한 sparsity regularization
: 3D 공간상에서 SDF의 grdient를 수정하기 위한 smoothness regularization
MSE loss와 binary cross-entropy loss는 아는데, 나머지 3개의 loss는 처음들어봐서 간단히 정리해보도록 하겠습니다.
Eikonal Regularization
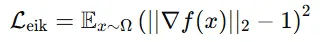
SDF는 객체 표면에서의 거리를 나타내기 때문에 gradient는 항상 1이어야합니다. 따라서 기울기를 1로 만들기 위한 역할을 elikonal regularization이 해줍니다.
왜 객체 표면에서의 거리를 나타낼 때 gradient가 1이어야 할까?(아래 예제 참조)

Sparsity Regularization
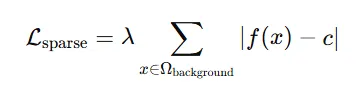
객체 외부의 영역은 양수 값을 가져야하는데 간혹 음수 혹은 0을 갖는 경우가 있습니다. 이러한 경우 floater가 발생하는데 이를 방지하기 위해서 특정 양수 혹은 양수 값을 갖도록 설정해주는게 sparsity regularization입니다.
Smoothness Regularization
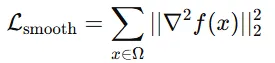
SDF의 표면이 너무 거칠어지는 현상을 방지하기 위해서 변화가 급격하지 않도록 라플라시안 연산으로 부드러운 변화를 유도합니다.
여기서 라플라시안(Laplacian) 연산은 함수의 이차 미분의 값을 구하는 것입니다. 2차 미분의 값이 크다면 해당 위치에서 변화가 심하고, 작다면 해당 위치의 변화가 부드러워집니다.
이제 다시 돌아와서 normal loss를 구해보도록 하겠습니다.
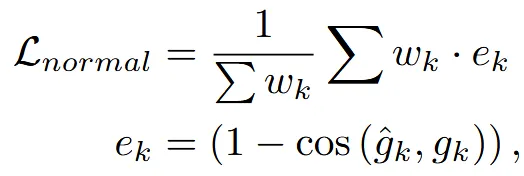
일반적으로 SDF의 normal값은 1차 gradient값을 통해서 나타냅니다. 비록 Eikonal Regularization 로 인해서 모든 값들이 1의 크기를 갖지만, 방향은 다르기 때문에 normal로 사용할 수 있습니다. 위의 수식을 보시면 cos함수를 사용해서 방향이 중요한 것을 알 수 있습니다.
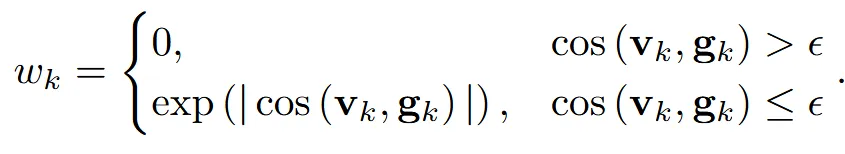
가중치를 나타내는 는 ray direction과 noraml의 cos 함수 결과를 이용해서 위와 같이 나타낼 수 있습니다. 값은 0에 가까운 음수입니다. 이렇게 에 따라서 가중치를 나눈 이유는 실제로 view direction은 물체를 향하기 때문에 안쪽으로, normal은 물체의 바깥으로 향합니다. 따라서 2개의 각도가 90도가 넘어야 일반적인 경우입니다. 하지만 90도 이내로 각도가 형성된다면 2개의 벡터중 한개가 잘못됐기 때문에 가중치를 0으로 줍니다.
그리고 가중치를 나눈 두번째 이유는, 뷰에 따라서 동일한 픽셀의 normal vector가 다르게 계산 될 수 있습니다. 이렇게 서로다른 normal vector를 단순 평균으로 구하지 말고, view direction과의 각도에 따른 가중치를 두어서 계산하면 최종 결과의 정확도가 높아집니다.
추가적으로 각 loss(color, depth, mask)를 내림차순으로 정렬한 다음에, 미리 정해둔 범위 안에서 위에서부터 몇개의 error는 제거하는 ouliner-dropping loss를 실행합니다.
Experiments
dataset: objaverse 30000+
view: front, back, left, right, front-right, front-left [Blenderproc]Model: Image Variations(Zero123에서 사용한 것)Size: Image:256x256, Batch:512, Steps: 30000GPU: A800 8개로 3일
3D Reconstruction: Instant-NGP based SDF
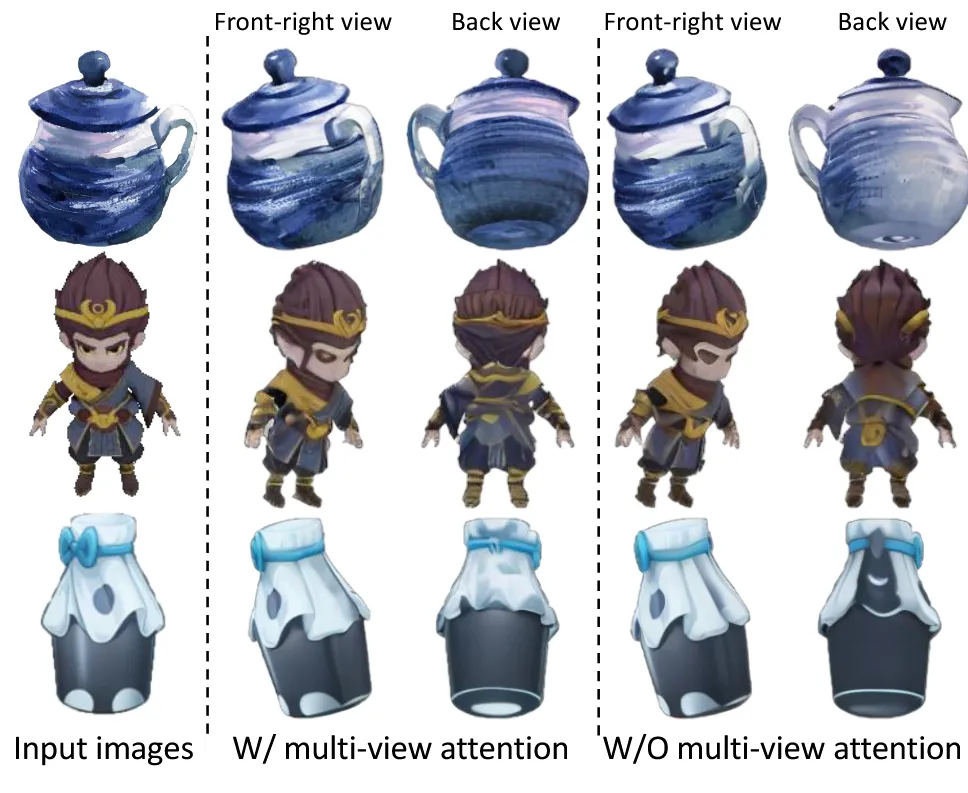
위의 결과는 뷰끼리의 정보를 주고받는 multi-view attention의 유무를 나타내는 결과입니다. 확실히 view consistency는 multi-view attention을 적용했을 때 좋습니다.
Limitations
- 6개의 view만을 생성할 수 있다는 점
- 하지만 적은 cost만을 이용해서 6개를 생성했다는 점에서 잘하기도 했다…(?)
Wonder3D ++
Wonder3D Github에 들어가면 Wonder3D ++코드와 논문이 존재합니다. 2025년 2월기준 1달전 공개이니 아주 따끈따끈한 논문입니다. 논문을 전부 읽지 않고 수정된 부분을 위주로 읽어보도록 하겠습니다.
Cross-domain Attention
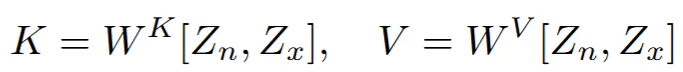
기존에는 cross-domain attention 부분에 대한 설명이 빈약해서 query가 하나의 domain, key와 value가 다른 domain으로 cross-attention을 통해서 학습하는줄 알았는데 위의 수식처럼 2개의 domain이 하나로 concate되서 self-attention을 통해서 학습을 진행한다고 설명했습니다.
Camera Type Switcher
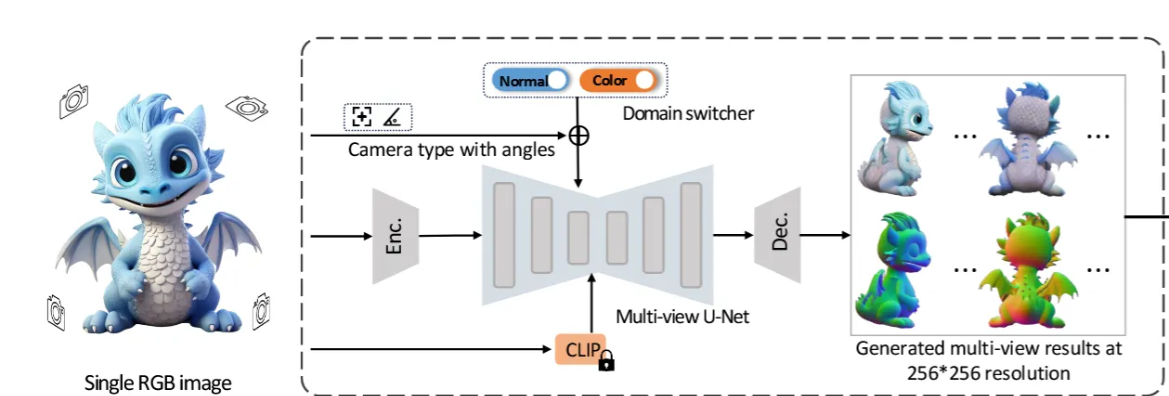
기존의 Wonder3D와 다르게 Camera type이라는 말이 들어가 있는 것을 확인할 수 있습니다. 입력 이미지로 들어오는 종류가 실사, 2D 생성 이미지 처럼 다양한 형태로 들어올 수 있고, 이러한 다양한 형태의 카메라를 정의하기 위해서 camera type switcher라는 개념을 사용합니다. 여기서 정의하는 라벨링은 perspective projection vs orthogonal projection입니다. 원근감을 반영하는 실제사진의 경우 perspacetive projection이고 2D diffusion 모델을 통해서 생성되는 이미지들은 orthogonal projection입니다. domain swither랑 동일하게 1D vector를 이용해서 나타냅니다.
사용자가 어떤 종류의 이미지인지 지정을 한다음에 생성하게 됩니다.
Multi-Stage Training Scheme
이전에는 학습을 어떻게 진행할지에 대한 구체적인 설명이 없었는데 여기서는 순차적으로 학습하는 방법을 제시했습니다.
- Multi-view attention만 학습
- Image → Novel view image, Normal → Noval view normal
- Domain switcher fine-tuning
- Image → Novel view image or Normal
- Cross-Domain Alignment fine-tuning
- 이전 단계는 freeze하고 cross-domain attention layer 학습
- Image → Novel view image and Normal
Cascaded 3D Mesh Extraction
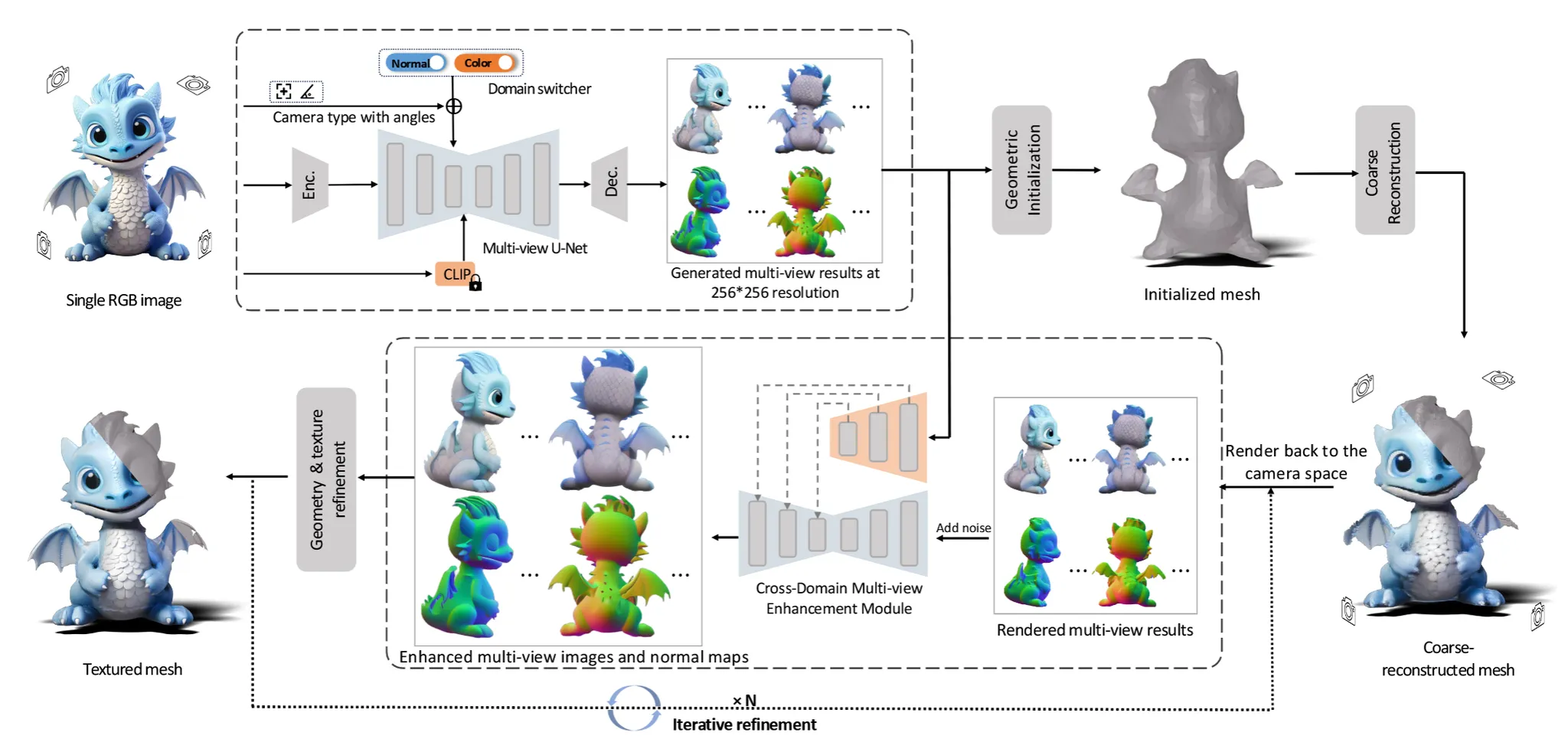
위의 그림처럼 2D상에서의 변화보다는 3D 상에서 더 복잡한 변화들이 많아진 것을 확인할 수 있습니다. 그러면 3D 상에서 어떤 변화들이 있었는지 확인해보도록 하겠습니다.
Geometric Initialization

초기에 3D mesh를 initialization 할 때 대부분 sphere를 사용합니다. 하지만 sphere를 사용하면 디테일한 요소들을 반영하지 못하기 때문에 depth의 front와 back을 이용해서 initialized mesh를 생성합니다. 이때 Poisson reconstruction 방법을 사용해서 3D mesh를 생성합니다.
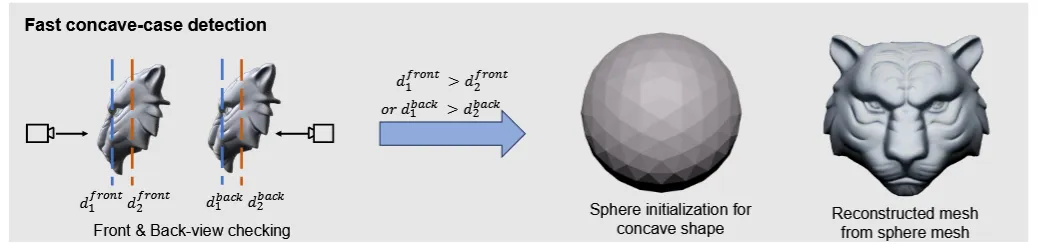
하지만 위의 그림처럼 적절하지 않은 depth map의 경우 오목한 결과가 나오기도 합니다. 이를 방지하기 위해서 depth map의 전체 평균 와 물체의 중심의 depth 을 비교해서 이 더 크면 오목한 형태로 판단해서 Sphere를 이용해서 initialization 하게 됩니다.
Coarse Reconstruction
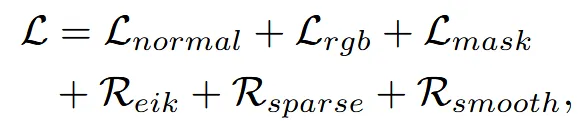
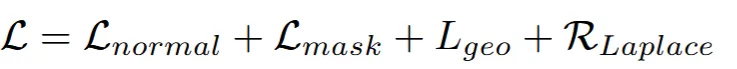
위의 수식이 Wonder3D의 loss 수식이고, 아래 수식이 Wonder3D++ loss 수식입니다.
- 첫번째로 rgb 이미지에 대한 MSE loss가 제거 됐습니다.
- normal과 mask loss가 모두 L2 loss로 바꼈습니다.
- smooth loss가 이름만 Laplace로 바꼈습니다.
- eik + sparse가 제거되고 geometry-aware normal loss가 추가 됐습니다.
Geometry-aware Normal Loss
새로 추가된 Geometry-aware Normal Loss 부터 살펴볼건데 기존의 normal loss의 가중치를 계산하는 방식과 유사한 방법이 사용됩니다.
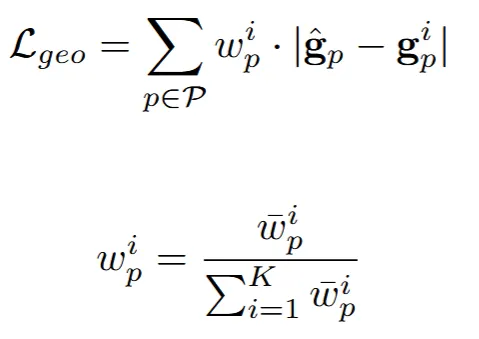
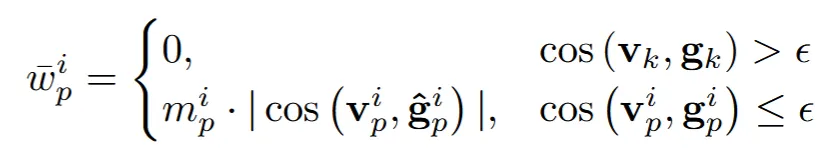
위의 3개의 수식이 Wonder3D++에서 사용하는 geo loss부분입니다.
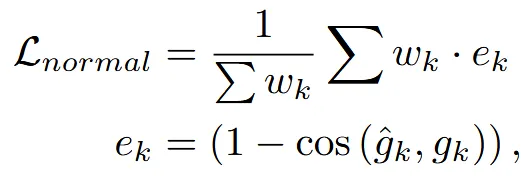
위의 수식이 Wonder3D의 normal loss 부분인데, normal끼리 코사인 함수를 사용해서 계산 하는 방식을 L2 loss로 수정하고 가중치 w를 결정하는 값은 완전히 동일한 것을 확인할 수 있습니다.
UV-based Texture Generation
기존에는 texture 정보가 mesh의 vertices에 저장되어있었지만, 더 좋은 퀄리티를 위해서 Wonder++에서는 UV map에 저장하도록 했습니다. 2-stage를 통해서 더 좋은 결과를 얻도록 설계했습니다.
첫번째 stage에서는 하나의 픽셀에 대한 색깔을 결정하기 위해서 여러 시점의 rgb image정보를 종합합니다. 이때 단순 종합이 아니라 가중치를 이용한 로 색깔을 정합니다. 제한적인 시점으로 몇개의 픽셀은 업데이트 되지않는데 이때는 평균 값을 이용해서 채워진 픽셀을 이용합니다.
두번째 stage에서는 첫번째 stage의 결과를 UV space로 펼칩니다. 이후 다시 모든 시점에서의 이미지를 UV space로 projection해서 업데이트하고 마지막으로 dillation 과정을 통해서 빈 픽셀들을 채워 넣습니다.
Iterative Refinement
UV-based Texture Generation을 통해서 texture refinment 과정은 진행했지만 아직 3d mesh는 적절하지 않을 수 있기 때문에 이에 대해서 업데이트 하는 과정도 필요합니다.
우선 ControlNet안에 cross-domain attention을 추가해서 두 도메인간에 정보 교환을 하면서 image와 normal의 refine과정을 진행합니다. 이후에 해상도를 2배늘리는 upsampling과 IP-adpater를 적용해서 textural 정보의 질감을 향상시킵니다. 여기서 정확히 입력과 condition을 설명하지 않았는데 아마도 입력으로 이미지와 normal을 concate하고 condition을 IP-Adapater를 이용해서 설정하지 않을까 싶습니다.
이렇게 향상된 정보가 지금 mesh에 반영되지 않은 상태입니다. 따라서 mesh의 렌더링된 이미지에 대해서 마지막으로 controlnet의 condition으로 방금 향상된 이미지를 넣고 학습을 시켜서 최종적인 mesh를 업데이트 하게 됩니다. 추가적으로 렌더링된 이미지와 normal을 바로 쓰는게 아니라 gaussian noise를 추가해서 DDIM inversion을 진행한다음에 controlnet의 입력으로 들어가게 됩니다.
