ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image
논문링크: https://arxiv.org/abs/2310.17994
Abstract
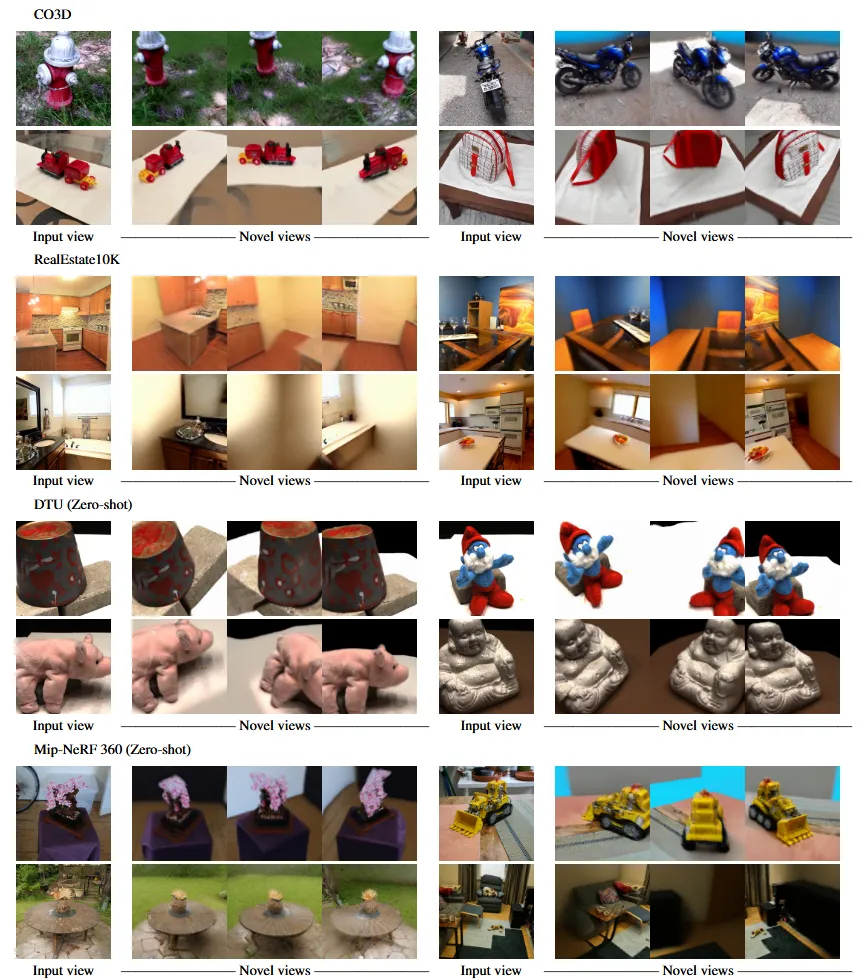
single-image novel view synthesis 모델인 ZeroNVS 모델을 소개합니다.
기존에 존재하는 모델들은 하나의 객체만을 이용해서 3D를 나타냈습니다. 하지만 ZeroNVS에서는 배경을 포함한 다양한 객체들을 이용해서 3D 형태로 나타낼 수 있습니다. 이는 실내, 실외, 물체중심의 다양한 이미지로 학습을 했기 때문에 가능한 것입니다.
새로운 카메라 파라미터와 normalization scheme를 통해서 depth-scale ambiguity 문제를 해결할 수 있습니다.
Introduction
이전 모델들은 일반적으로 배경이 없는 하나의 물체에 대해서 새로운 뷰 혹은 3D를 생성하도록 설계되었다. 또한 Objaverse-XL 데이터를 통해서 conditional diffusion 모델을 활용한 Scor Distillation Sampling(SDS) 방식으로 3D 데이터를 학습할 수 있었습니다.
이전 모델들이 물체 중심적인 학습을 한것과 다르게 2가지 방식을 사용해서 ZeroNVS는 더 잘 학습될 수 있었습니다.
- a new camera parameterization and normalization scheme for conditioning(diverse scene datasets)
- SDS anchoring: improving the background diversity over standard SDS
학습한 데이터는 mixed dataset으로서 CO3D + RealEstate10K + ACID로 학습해서
위의 내용들을 요약한 논문의 Contribution을 정리하면 아래와 같습니다.
- 배경을 포함한 full-scene NVS from real images
- 새로운 카메라 파라미터와 scene normalizaion scheme를 이용한 현실적인 장면 학습
- CO3D + RealEstate10K + ACID의 다양한 데이터의 학습으로 strong zero-shot generalizaiton
- SDS anchoring의 개발로 기존의 단조로운 배경의 학습에 대한 문제 완화
- DTU데이터셋의 LPIPS zero-shot에서 SOTA 달성
Related Work
3D generation
DreamFusion에서는 SDS를 이용해서 text prompt를 diffusion모델을 이용해서 NeRF에 적용시킬 수 있었습니다.
이후 GAN 기반 모델들도 등장했지만, 해당 모델들은 single object를 학습한다는 점에서 제한적이었습니다.
Single-image novel view synthesis
PixelNeRF와 DietNeRF는 NeRF를 활용한 sparse view 데이터 학습을 연구했습니다. 하지만 단일 이미지로부터 새로운 각도의 장면을 생성할 때 비현실적으로 생성된다는 한계가 존재했습니다.
최근에 diffusion 기반 모델들은 2계의 stages로 나눔으로써 성능을 크게 계선했습니다. 첫번째로 diffusion 모델이 학습되고, 두번째로 SDS 방식으로 적용되는 방식입니다.
GENVS 모델은 소화전에 특화되어 360도 카메라 모션을 학습할 수 있었습니다.
위의 모델들과 다르게 다양한 데이터의 360도 카메라 모션을 학습할 수 있는 모델이 ZeroNVS입니다.
Approach
기존 모델들의 접근 방식과 비슷하게 diffusion 모델을 학습한 후, 이를 3D SDS distillation을 적용하는 방식을 사용합니다. 단 기존 모델들은 object에 집중했다면 ZeroNVS에서는 background에 집중합니다. 하지만 카메라 파라미터와 scene normalization scheme의 변경, SDS anchoring를 사용한다는 점이 해당 논문의 새로운 방법입니다.
일반적인 표기 방법들에 대해서 먼저 설명해드리도록 하겠습니다.
- S: scene
- X = : 이미지들의 집합
- D = : depth maps
- E = : 카메라 외부 파라미터(extrinsics)
- : roatation과 translation으로 구성되어 있습니다.
- f: 시야각(shared field-of-view)
동일한 inrinsics를 사용합니다. 즉, 같은 장면 안에서는 모든 이미지가 동일한 카메라 내부 파라미터를 가진다는 것을 의미합니다. 추가적으로 카메라 이미지에 왜곡이 없고, principal point(주점)이 이미지의 중심에 위치합니다. 이는 계산을 단순화해주는 역할을 합니다.
Diffusion 모델에 입력 이미지외에 추가적으로 들어가는 정보를 설명해드리겠습니다.
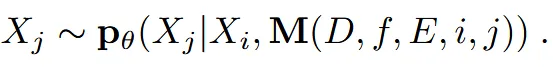
추가정보: D(depth maps) + f(시야각) + E(카메라 외부 파라미터) + i,j(입력과 출력 시점의 인덱스)
즉 입력이미지 에 condition 을 이용해서 목표 이미지인 를 생성하는 확률 분포 를 샘플링하는 방법입니다.
Representing Objects for View Synthesis
이 단락에서는 Zero123와의 차이점을 기반으로 왜 더 많은 정보들을 사용했는지 나타냅니다.
Zero123는 3개의 자유도(dof)를 갖습니다. elevation(고도, θ), azimuth(방위각, φ), radius(반경, z)로 이루어져있고 (3차원 공간상의 이동)으로 projection 됩니다.
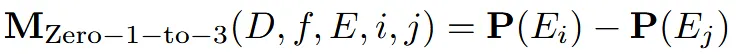
위의 수식은 Zero123의 수식입니다. 두 시점 간의 차이를 계산하는 방식으로 조건부 정보를 사용합니다.
개인적으로 자유도를 3을 나타내는 값은 E에 대한 정보(고도, 방위각, 반경)인데, D와 f도있으니까 총 5가 아닌가라는 의문이 있었는데, 여기서 말하는 자유도는 카메라의 위치와 방향을 나타내는 방식이고 D와 f는 카메라 위치와 방향을 타나내는 요소와 관련이 없기때문에 자유도에 포함되지 않습니다.
돌아와서 자유도3이라는 정보는 single object에는 적절한 방식입니다. 왜냐하면 객체는 원점에 맞춰져있고 배경이 없기 때문입니다. 하지만 일반적인 이미지나, 배경이 있는 이미지인 경우 이는 한계가 존재합니다. 왜냐하면 현실에서는 카메라가 단순히 각도를 바꾸는 것뿐만 아니라 위치도 자유롭게 이동할 수 있기 때문에 더 복잡한 표현이 필요합니다.
현실 세계에서는 6개의 자유도(Translation을 포함해서)가 필요합니다.
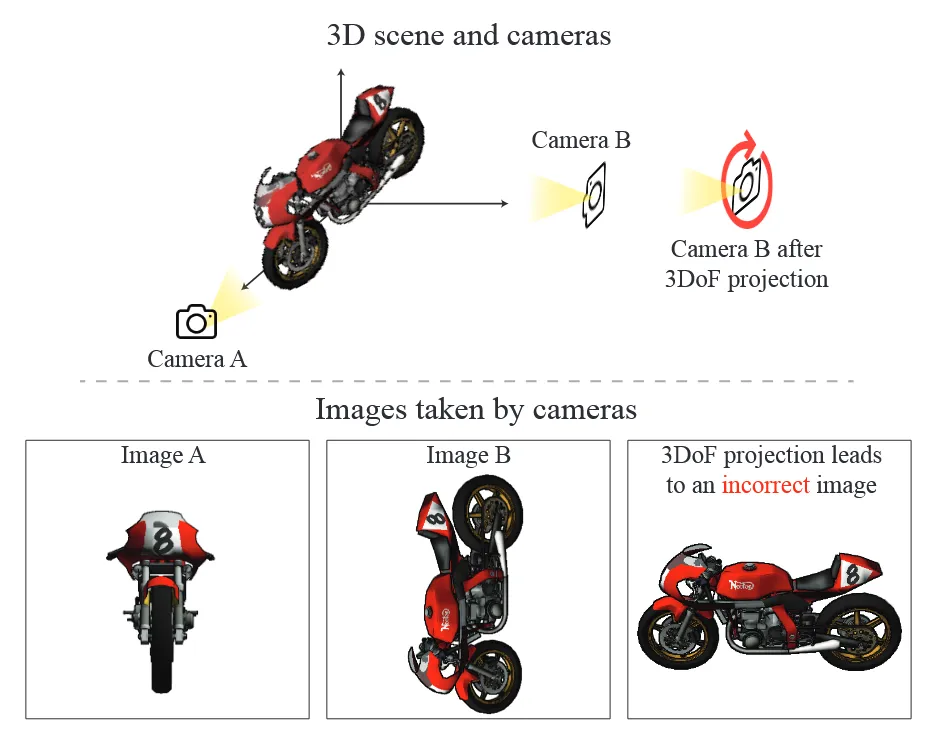
위의 그림에서 ImageA와 ImageB는 6Dof의 렌더링 결과로서 위치와 회전을 고려했기 때문에 실제 위치와 방향을 제대로 반영한 이미지를 생성합니다. 이에 반해 오른쪽 마지막 이미지는 3Dof를 사용했기 때문에 객체의 회전이나 다양한 이동을 반영할 수 없어 왜곡된 이미지를 생성합니다.
Representing Scenes for View Synthesis
ZeroNVS는 따라서 위와같은 이유로 6개의 자유도를 갖는 카메라 파라미터를 사용합니다. 기존에 zero123에서는 고도, 방위각, 반경과 같은 translation만 사용했다면 rotation 정보를 추가한 것입니다.
translation과 rotation외에도 f(시야각)을 추가했습니다. 이를 “6DoF+1”로 정의했습니다.
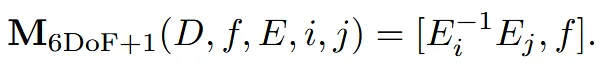
6Dof+1은 rigid transformation(물체의 형태나 크기는 그대로 유지)에 대해서는 불변입니다. 즉 장면을 어떤 방식으로 이동시키거나 회전시키더라도 이 표현은 동일하게 유지됩니다.
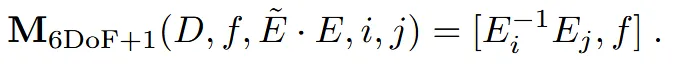
위와 같은 수식은 COLMAP이나 ORBSLAM(둘다 카메라의 위치를 파악하는 알고리즘)을 사용할 때 유용합니다. 장면 자체가 변하지 않기 때문에 카메라의 위치를 측정하기가 용이하다는 것입니다.
Rigid transformation을 통해 카메라 포즈를 추정할 수 있지만, 크기에 대해서는 일관되지 않는다는 문제가 발생합니다.같은 장면이라도 데이터셋이나 환경에 따라 크기 정보가 다르게 추정 될 수 있습니다.
일관되지 않는 크기는 normalize를 통해서 해결할 수 있습니다.
: 카메라 외부 파라미터(E)와 스케일링 값(λ)을 입력으로 받아 새로운 카메라 외부 파라미터를 변환하는 함수입니다. 이를 자세히 설명하면 아래와 같습니다.

s는 카메라 위치들의 평균 거리로서 수식은 위와 같습니다. 거리는 카메라 위치의 평균을 원점으로 했을 때 각 카메라 위치가 평균으로부터 얼마나 떨어져 있는지를 나타냅니다.
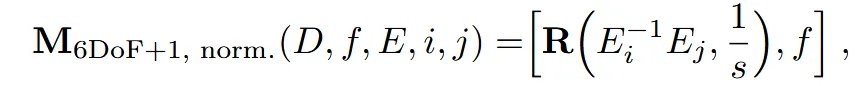
위의 수식에서 이전과 다르게 로 normalized된 것을 확인할 수 있습니다.
Addressing Scale Ambiguity with a New Normalization Scheme
위에서 설명한 카메라 위치들의 평균 거리를 이용한 normalization 하는 방법은 일관된 크기를 가질 수 있도록 하는 역할을 수행했습니다.
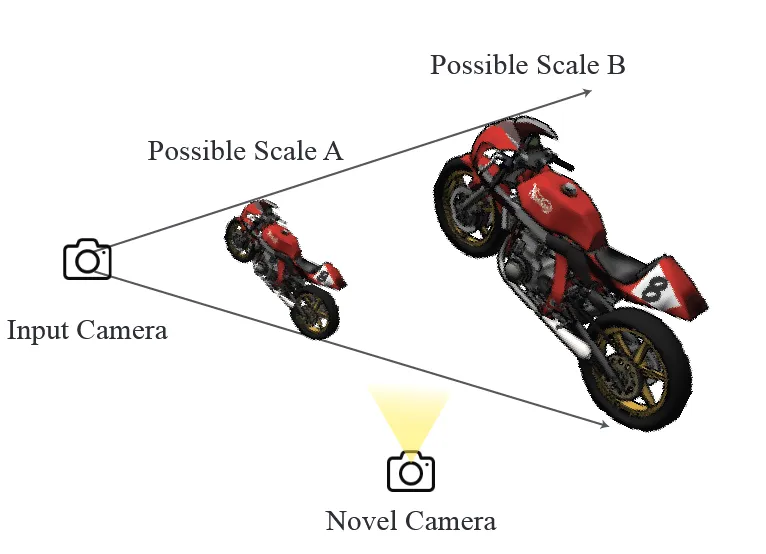
하지만 위의 사진처럼 단조로운 하나의 입력 이미지에 대해서는 여러가지 Scale이 존재할 수 있습니다. 이때문에 새로운 카메라가 생겼을 때 어느 Scale을 참고할지 문제가 발생합니다.
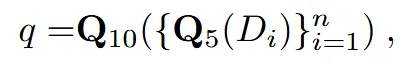
이러한 문제점을 해결하기위해 depth map을 적용했습니다. Stereo Magnification 방식에서 사용된 방법을 참고해, depth map(D)에서 5번째 quantile(분위수)를 구하고, 그 값을 10번째 quantile로 다시 집계해 장면의 크기로 사용했습니다.
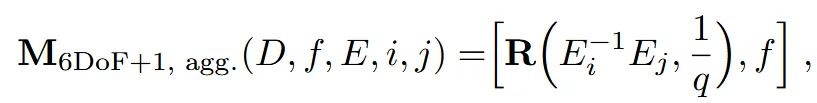
기존에 s로 scaling한 값을 q로 교체함으로서 scene의 크기를 고려한 normalization이 가능해졌습니다. 하지만 여전히 2가지 문제점이 존재합니다.

첫번째 문제는, 집계 과정의 모호성입니다. quantile이라는 것이 모든 시점에 대해서 몇번째의 값을 가져오기 때문에 카메라가 추가되면 해당 값이 변할 수 있습니다. 따라서 카메라가 추가됨에 따라 크기가 바뀌는 모호성이 존재합니다. 위의 사진에서 Setup2에서 카메라 C가 추가됨에 따라 Scale이 작아지는 것을 확인할 수 있습니다. 이는 집계 과정을 제거하고 각 카메라 시점에서 개별적으로 깊이 정보를 사용함으로서 문제를 해결할 수 있습니다.
두번째 문제는, ORBSLAM과 COLMAP이 서로 다른 depth map을 생성한다는 것입니다.이를 해결하기 위해 off-the-shelf depth estimator(기존에 학습된 깊이 추정 모델)를 사용합니다. off-the-shelf depth estimator는 depth map의 빈 부분을 채우는 방법으로 depth map을 더 조밀하게 만듭니다.
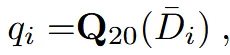
기존에 모든 시점의 depth map을 집계해서 q를 계산했지만, 이제는 off-the-shelf depth estimator로 더 정교한 depth map을 얻었기 때문에 해당 시점의 depth map에서 20번째 quantile 값을 사용하도록 수정했습니다. 이에 따라 카메라가 추가되어 생기는 모호성을 해결할 수 있습니다.
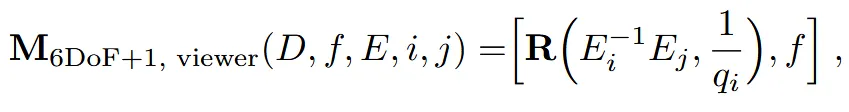
Improving Diversity with SDS Anchoring
SDS distillation은 mode collapse 현상이 발생한다는 단점이 있습니다. Mode collapse는 다양한 결과를 생성해야 하는 상황에서 모델이 하나의 특정한 결과만 생성하는 문제입니다. SDS가 목표 이미지와 오차를 줄이는 과정에서 특정 모드로 수렴해서 발생하는 것입니다. 이러한 문제는 특히 background와 관련해서 나옵니다. 우리가 보지 못하는 영역에 대해서 단조럽거나 회색의 결과를 내는 현상입니다.
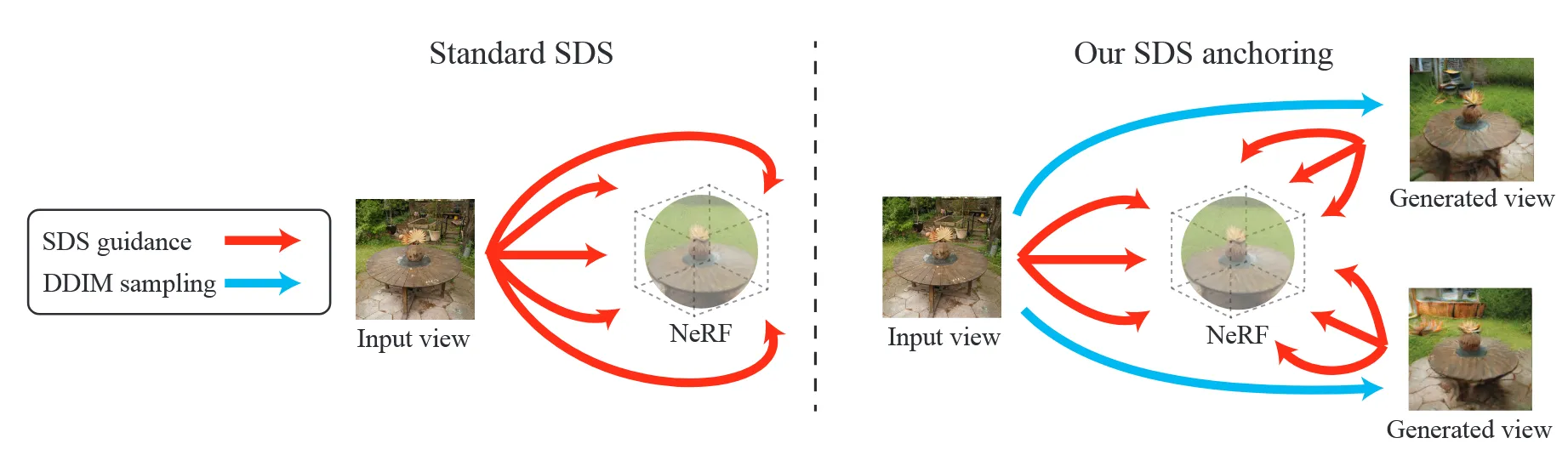
이를 극복하기 위해서 SDS anchoring을 사용합니다.SDS Anchoring은 기존에 하나의 시점에서만 SDS를 적용하는 방식에서 DDIM을 이용해서 여러 시점에서 SDS를 적용함으로써 mode collapse를 해결 한것입니다.
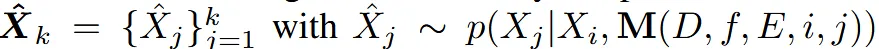
우선 k개의 새로운 시점의 이미지를 생성합니다. 새로운 시점들은 최대한 장면 전체를 커버할 수 있도록 방위각을 기준으로 고르게 배치된 포즈에서 샘플링됩니다. 이때 새로운 시점의 이미지는 DDIM을 이용해서 나타냅니다. DDIM은 다양한 경로를 통해 샘플링할 수 있기 때문에 mode collapse 문제를 해결할 수 있습니다. 또한 mode collapse를 완화하기 위해 SDS를 최적화할 때 input view가 아닌 인접한 view를 최적화합니다.
Experiments
Setup
Datasets: CO3D + ACID + RealEstate10K
- 256 x 256 resolution & center-cropping
- 각 이미지에 대해서 필요한 경우 카메라 내부 파라미터(intrinsic)를 조정
Main Results
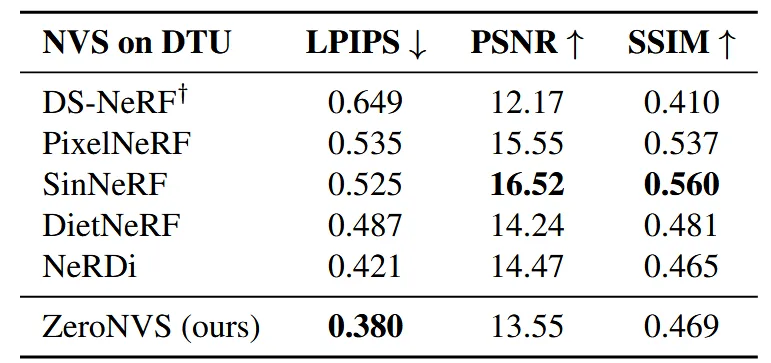
위의 표는 ZeroNVS만 zero-shot 결과이고 나머지 모델들은 학습된 후 성능을 평가했습니다. 그럼에도 불구하고 ZeroNVS는 LPIPS 부분에서 SoTA를 달성했습니다. 하지만 PSNR과 SSIM은 낮게 나왔습니다. 이는 두가지 평가지표가 novel view synthesis에서는 적절하지 않기때문입니다. PSNR은 픽셀 단위의 절대적인 차이만 측정하고 시각적으로 중요한 특성(모양, 구조, 세부 묘사)을 반영하지 못하고, SSIM은 두 이미지 간의 local 구조와 명암을 비교하는데 중점을 두고 전반적인 이미지의 품질이나 다양성 평가에는 한계가 있습니다. 반면 LPIPS는 이미지 패치 간의 시각적 유사성을 평가하기 때문에 딥러닝 모델을 사용해 추출한 feature를 비교함으로 더 다양한 정보를 평가할 수 있습니다.

위의 그림은 맨오른쪽 PixelNeRF에서는 아무 결과도 나오지 않았지만 PSNR과 SSIM이 3번째 그림보다 높게 나왔습니다. 이처럼 해당 논문에서는 PSNR과 SSIM은 novel view synthesis에서 적절하지 않은 평가지표라고 설명하고 있습니다.

위의 사진은 시각적으로 각 모델들을 비교한 것입니다.
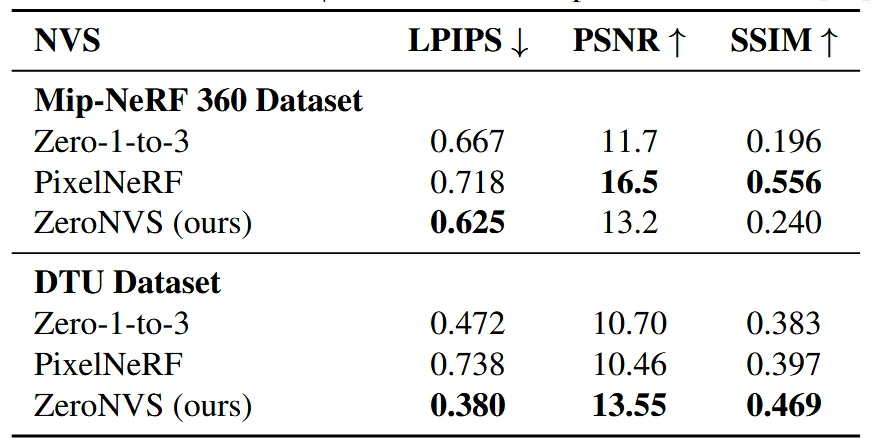
다른 모델들도 Zero-shot결과로 비교할 때 Mip-NerF360데이터를 사용할 때 여전히 LPIPS에서 SoTA를 달성하고, DTU 데이터셋에서는 PSNR과 SSIM역시 가장 좋은 결과를 나타냈습니다.
SDS와 SDS anchoring의 성능 비교를 위해 21명의 사용자에게 Realism, Creativity, Overall Preference를 조사했습니다. SDS anchoring이 Realism(78%), Creativity(82%), Overall Preference(80%)로 더 좋은 선호도를 나타냈습니다.

그림은 시각적으로 SDS와 SDS anchoring을 비교한 것입니다. SDS anchoring이 더 다양한 배경을 생성한 것을 알 수 있습니다.
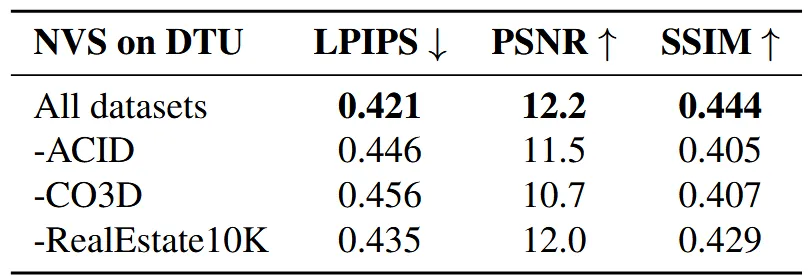
위의 표는 다양한 데이터셋을 사용할수록 성능이 좋아진다는 것을 보여줍니다.
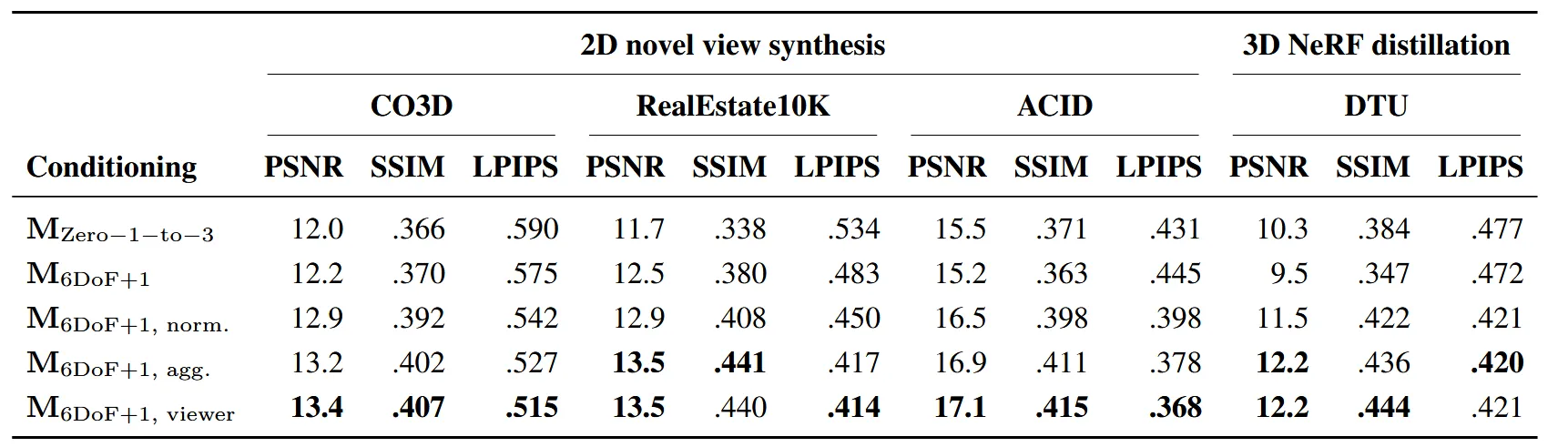
Method에서 사용한 여러가지 conditioning 방법을 비교하면서 결론적으로 마지막 방법인 6DoF+1에 viewer를 적용한 방법을 사용할 것을 권고했습니다.
Code 결과


배경을 제거하지 않은 결과와 제거한 결과를 각각 나타낸 것입니다. 뒷부분이 조금 부족하기는 하지만 어느정도의 입체감있는 결과는 나온 것을 알 수 있습니다.
