현재 인공지능 상황은 2000년대 초 인터넷이 폭발적으로 발전하는 상황이랑 비슷하다.
배경 지식
자료구조 : 큐, 스택, 이진트리
확률과 통계 : 확률 변수, 기댓값, 평균-분산-표준편차
선형대수학 : 매트릭스와 벡터의 사칙 연산
정의
머신러닝은 명시적인 프로그래밍이 없어도 컴퓨터가 어떤 동작을 학습할 수 있게 하는 것이다.
경험(학습)을 통해 어떤 일에 대한 기계 성능을 높이는 것이다.
지도 학습과 비지도 학습
지도 학습은 레이블이 있는 데이터(input, output이 있는 데이터)를 학습해서 어떤 input에 대한 적절한 output을 예측하는 것이다.
비지도 학습은 레이블이 없는 데이터(input만 있는 데이터)를 학습해서 주어진 input에 적절한 의미를 부여하는 것이다.
강화 학습
해결 방법 개수가 무한대일 때 최적의 방법을 찾아내는 방법이다. 모델이 예측한 결과를 측정해서 좋은 결과면 보상(reward signal)을 주고 나쁜 결과면 벌을 준다.
Regression과 Classification
Regression은 모델이 예측하는 output이 연속적이다. (e.g. 실수)
Classification은 모델이 예측하는 output이 이산적이다. (e.g. 정수)
모델 설계 과정
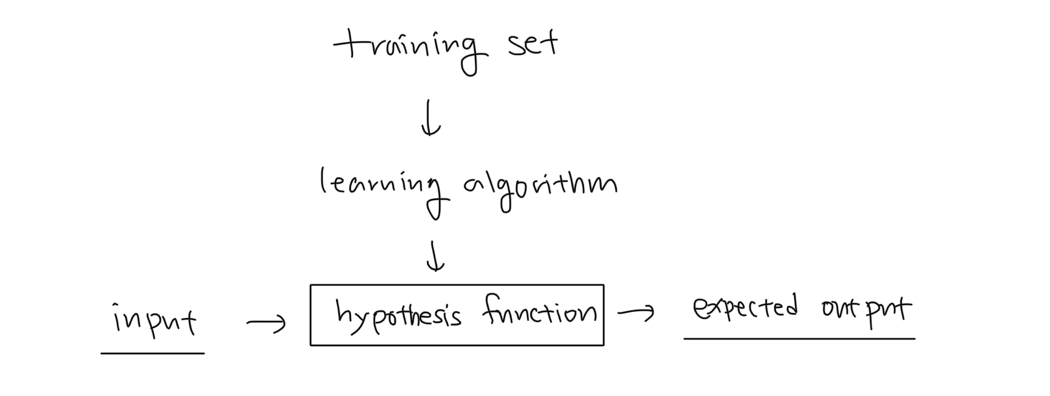
- 데이터를 얼마나 수집할까 (데이터 개수)
- 어떤 학습 알고리즘을 사용할까
- 학습 횟수는 얼마나 할까
- 어떤 종류의 데이터를 수집할까
- 더 빠른 GPU를 구매할까 (당연)

이유와 방법을 알려주는 메모장 겸 블로그 (Frontend, AI, 경제, 책)