◎ Deque(디큐, 덱)
-
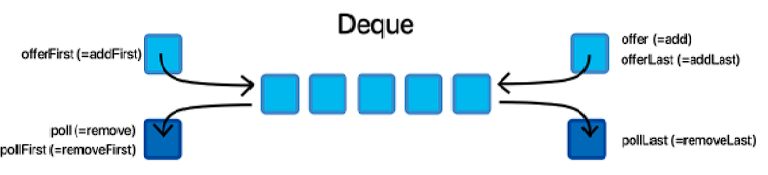
Deque
- Double Ended Queue의 양방향 대기열
- Stack과 Queue의 특징이 혼합되어 있다.
- 비유) 실의 양쪽에 구슬을 꿰어 넣는 구조
-
Deque 특징
- Stack과 Queue의 특징이 혼합되어 있다.
- LIFO, FIFO와 같은 순서에 구속되지 않는다.
- 추가와 삭제를 양쪽에서 제어할 수 있어서 여러 형태로 사용할 수 있다.
- 첫 번째, 한쪽만 추가, 양쪽에서 제거
- 두 번째, 양쪽에서 추가, 한쪽만 제거
- 이외, 양쪽에서 추가, 삭제도 가능
- 양방향 끝에서 데이터 추가, 삭제가 용이
- 양방향 끝이 아닌 임의의 데이터만 추가하거나 삭제하는 건 불가능
-
참고 자료 : https://st-lab.tistory.com/185
◎ Linked List
-
Linked List
- 선형으로 그룹화된 데이터의 집합
- 데이터와 다음 데이터의 주소를 포함하고 있는 하나의 노드가 선형으로 연결된 자료구조
- ex) 반 전체 학생 이름이 적힌 종이로 제비를 뽑아 마니또를 정한 상태 (일일히 다음 번호를 물어보고 다녀야함)
-
Linked List의 구조
- 연속된 공간이 아니라 흩어져 있는 공간에 노드들의 연결로 이루어진 자료구조
- 하나의 노드에는 데이터와 다음 노드의 주소가 담겨있다.
- 연속된 메모리 주소가 아니기 때문에 직접 주솟값을 가지고 있어야 다음 노드로 접근할 수 있다.
- 마지막 노드는 다음을 가리킬 곳이 없으므로 새로 추가되기 전까지는 null을 가리킴
-
Linked List의 특징
- 노드의 추가와 삭제가 쉽고 빠르다.
- 일반 배열에서는 인덱스 삽입 제거시, 한칸씩 밀거나 땡겨야하므로 시간 복잡도가 O(1) ~ O(n) 이다.
- Linked List에서는 특정 노드의 주소값만 바꿔주면 되서 어떤 위치에 추가, 삭제해도 시간 복잡도가 O(1)이다.
- 노드의 값을 찾으려면 최대 전체를 순회해야 한다. (힘듦)
- 배열은 인덱스값을 계산하기가 쉬우므로 어느 위치의 인덱스인지 관계없이 데이터에 접근하는데 O(1)의 시간복잡도를 가진다.
- Linked List는 필요한 값이 있는지 확인하려면 head node에 연결된 다음 노드로 접근해야 하고, 접근한 노드에 원하는 값이 없다면 다시 다음 노드로 이동, O(1) ~ O(n) 의 시간 복잡도를 가짐
- 노드의 추가와 삭제가 쉽고 빠르다.
-
Linked List 실사용 예제
- 삽입과 삭제가 중요한 곳에 활용
- join, split method처럼 데이터 삽입 삭제가 중요한 메소드의 구현에도 활용할 수 있습니다.
- 동적 기억장소 관리 (dynamic storage management)
- 실행되는 작업에 필요한 크기만큼의 메모리를 할당하는 방법에 활용됩니다.
- Garbage collection
- 참조자료형의 데이터 타입을 관리하는 알고리즘 중 하나입니다.
- 삽입과 삭제가 중요한 곳에 활용
◎ Hash Table
-
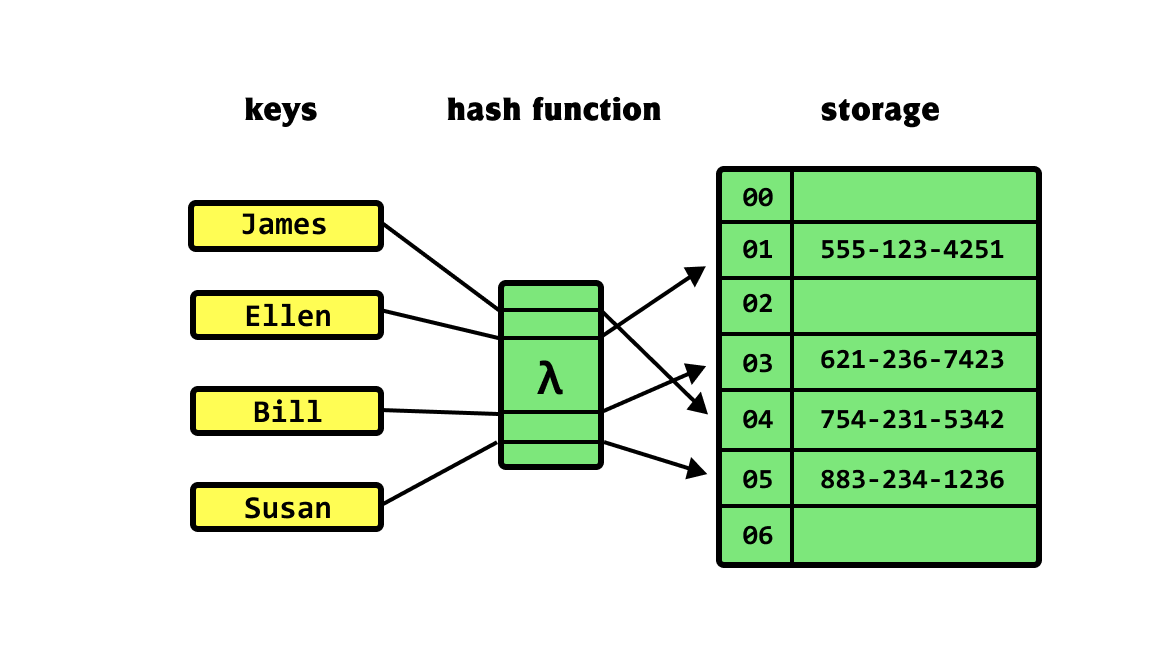
Hash Table
- 해시함수(hash function)를 사용하여 변환한 해시(hash)를 색인(index)으로 삼아 키(key)와 데이터(value)를 저장하는 자료구조
-
Hash Table의 구조
-
키(key) : 고유한 값으로 해시 함수의 입력값이 됨. 다양한 길이의 값이 들어올 수 있다. 해시 함수를 통해 변환하지 않은 상태로 저장소에 저장이 되면 다양한 길이만큼의 저장소를 구성해 두어야 하기 때문에 해시 함수로 값을 바꾸어 저장한다.
-
해시함수(hash Function) : 키(key)를 해시(hash)로 바꿔주는 역할을 합니다. 다양한 길이를 가지고 있는 키(key)를 일정한 길이를 가지는 해시(hash)로 변경하여 저장소를 효율적으로 운영할 수 있도록 도와준다. 다만, 서로 다른 키(key)가 같은 해시(hash)가 되는 경우를 해시 충돌(hash Collision)이라고 하는데, 해시 충돌을 일으키는 확률을 최대한 줄이는 것이 중요하다.
-
해시(hash) : 키(key)를 해시함수(hash function)를 사용하여 만들어진 결과물로, 저장소에서 데이터(value)와 매칭되어 저장된다. 변환된 값을 배열의 색인(index)과 같이 사용하게 된다.
-
데이터(value) : 저장소에 최종적으로 저장되는 값으로 색인(index)과 매칭되어 저장된다.
-
-
Hash Table의 특징
- 저장, 삭제, 검색 과정
- 해시 함수(hash function)에 키(key)값을 넣어 해시(hash)값을 만들고, 이후 만들어진 해시(hash)값과 일치하는 색인(index)을 찾아 저장하거나 삭제, 검색한다. ( 기본적인 해당 작업들의 시간복잡도 : O(1) )
- 해시함수(hash function)를 거쳐 해시(hash)값을 찾아내는데 걸리는 과정은 고려하지 않는다.
- 해싱 충돌이 발생할 경우 저장소의 모든 색인(index)(삽입) 혹은 데이터(value)(삭제, 검색)를 찾아봐야 하기 때문에 O(n)이 된다.
- 대표적인 해시 알고리즘
- Division Method : Number type의 키(key)를 저장소의 크기로 나누어 나온 나머지를 색인(index)으로 사용하는 방법. 이때 저장소의 크기를 소수(Prime Number)로 정하고 2의 제곱수와 먼 값을 사용하는 것이 효과가 좋습니다. 예를 들어 Key 값이 23일 때 테이블 크기가 7이라면 index는 2가 된다.
- Digit Folding : 키(key)의 문자열을 ASCII 코드로 바꾸고 그 값을 합해 저장소에서 색인(index)으로 사용하는 방법. 만약 이때 색인(index)가 저장소의 크기를 넘어간다면 Division Method를 적용할 수 있다.
- Multiplication Method : 숫자로 된 Key 값 K와 0과1 사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같이 계산한 값을 사용한다. index = (KA mod 1)m
- Universal Hashing : 다수의 해시함수를 만들어 특정한 장소에 넣어두고, 무작위로 해시함수를 선택해 해시(hash)값을 만드는 기법이다.
- 저장, 삭제, 검색 과정

장비를 정지합니다.