코드링크 in Jupyter notebook
위 링크는 주피터노트북에서 실행시킨 코드입니다.
전체적 개요
-
문제 정의
-
데이터 불러오기
-
데이터 시각화
-scatterplot 및 heatmap -
모델 training
-support vector machine -
모델 평가
-confusion_matrix -
모델 성능 개선
-parameter 조정 ( gridsearch )하이라이트된 부분의 개념을 중점적으로 파헤처 보겠습니다. 기본적인 내용들은 원본 코드를 확인 해주세요.1. Scatterplot & Pairplot
-
Scatter plot
시각화 라이브러리 중 하나인 seaborn의 산점도 그래프를 볼 수 있는
scatter plot에 대해 다루어 보자. 변수간의 상관관계를 찾을 수 있다.sns.scatterplot(x = 'mean area', y = 'mean smoothness', hue = 'target', data = df_cancer) x = 'x축' y = 'y축' data = '데이터'Hue = 두가지 변수를 입력받아 점이 2차원 배열로 나타내어질 때 다른 변수에 따라 색칠하며 한가지 차원을 추가할 수 있다.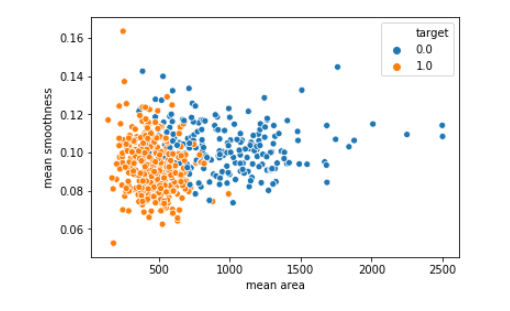
위 사진 처럼 target = 0 은 blue target = 1 은 orange로 분류되어 나타내어 진다.
- Heatmap
각 특성들의 상관관계를 블럭의 색 및 수치로 확인할 수 있습니다.
plt.figure(figsize=(20,10))
sns.heatmap(df_cancer.corr(), annot=True)annot = true 설정을 했을 시 각 블럭 내 수치를 기입해서 수치까지 확인가능하다.

위 상관관계 그래프를 확인하여 어떤 feature가 target과 깊은 상관이 있는지 알 수 있으며 또한 (feature 서로 간 상관관계가 높은 특성) 다중 공선성을 의심할 수도 있다.
2. Support Vector Machine
SVM 이란?
서포트 벡터 머신(이하 SVM)은 결정경계, 즉 분류를 위한 기준 선을 정의하는 모델이다. 그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해 분류 과제를 수행할 수 있다.
결국 이 결정경계(Decision Boundary) 를 어떻게 정의하고 계산하는지 이해하는게 중요하다.
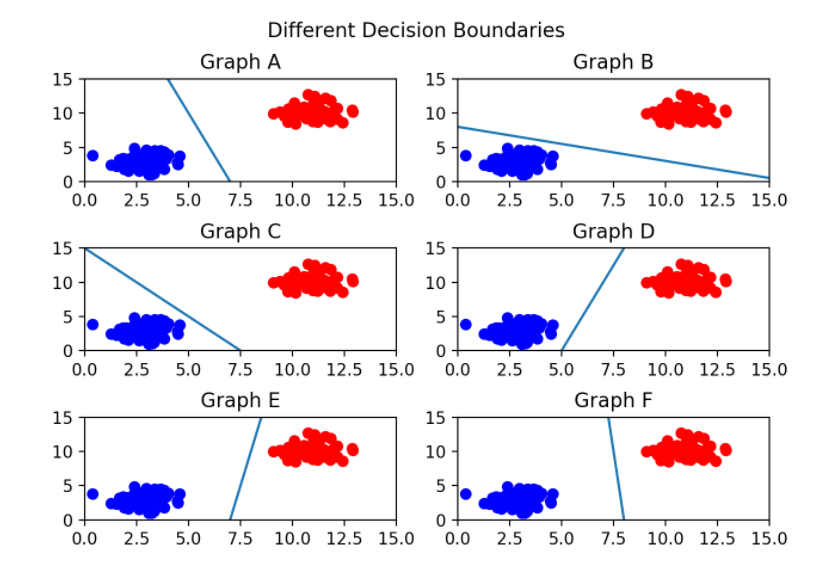
이 그림으로 확인 해보면 그래프C는 선이 너무 파란색 그룹에 가까워 위태로워 보입니다..
그렇다면 어떤 경계가 가장 알맞은지 직관적으로 본다면 무엇일꺼 같은가요?
네 당연히 F라고 확인 할 수 있겠습니다. 두 분류 사이에서 거리가 가장 멀기 때문입니다.
기본적으로 이렇게 결정 경계는 데이터 군집으로 부터 멀리 떨어져 있는것을 직관적으로 알았다.
이것을 용어로 바꿔 설명한다면 결정경계에서 가장 가까운 데이터들의 거리 즉 margin이 최대가 되는 결정 경계가 바로 최적의 결정 경계라고 할 수 있다.
코드를 통해 svm을 활용한 fitting을 해보자.
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size = 0.2, random_state=5)
svc_model = SVC()
svc_model.fit(x_train, y_train)3. Confusion_matrix
confusion matrix(오차행렬)은 training을 통한 predction 성능을 측정하기 위해 예측 value와 실제 value를 비교하기 위한 표 이다.

- 정확도(accuracy)는 전체 모델이 바르게 분류한 비율로써
TP+TN이다. FN을 제 1종오류,FP를 제 2종오류 라고 부른다.
유방암 데이터를 이용하여 코드를 작성하고 그 결과를 확인해 보자.
heatmap 함수를 사용하여 오차행렬을 나타내 보자.
from sklearn.metrics import confusion_matrix
y_predict = svc_model.predict(x_test)
cm = confusion_matrix(y_test, y_predict)
sns.heatmap(cm, annot = True)
행은 predcit , 열은 true를 나타내는 상황해서 제1종오류 7건을 제외하고 모두 올바르게 분류한 모습이다.
4. Gridsearch
모델 성능을 향상 시키기 위해 parameter 조정을 해보려한다. 그러기 위해선 최적화 할 svm의 핵심 파라미터를 알고 있어야 한다.
-
c parameter( 기본값 = 1 ): controls trade-off between classifying training points correctly and having a smooth decision boundary ( 한마디로 패널티 ) small c : 적은 패널티로 완만한 경계선. large c : 큰 페널티로 오분류의 비용이 매우크다. 어떤 지점이라도 오 분류시 경계선이 크게 구부려 진다. -> overfitting 위험성
-
gamma parameter : controls how far the influence of a single training set reaches ( 한마디로 데이터 포인트의 영향 범위를 지정하는 것) small gamma : far reach (more generalized solution) large gamma : close reach (closer data points have high weight ) -> overfitting 위험성
-
방사 기저 함수 (RBF)
이 RBF 커널은 2차원의 점을 무한한 차원의 점으로 변환한다…… 그래서 시각화하는 건 어렵고… 커널이 이 작업을 수행하는 방법에 대해서도 이해하기 어렵다. 상당히 복잡한 선형대수학이 사용된다는 것만 알고 넘어가자.
이 파라미터를 어떻게 최적화?? how optimizing?? --> grid search!
param_grid = {'C' : [0.1, 1, 10, 100], 'gamma' : [1, 0.1, 0.01, 0.001], 'kernel' : ['rbf']}
from sklearn.model_selection import GridSearchCV
gird = GridSearchCV(SVC(), param_grid, refit=True, verbose=4)
grid.fit(x_train_scaled, y_train)
grid.best_params_
grid.best_estimator_- refit : 디폴트가 True이며 True로 생성 시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 esitmator 객체를 해당 하이퍼 파라미터로 재학습 시킨다.
- verbose : 하이퍼 파라미터 메시지 출력

유방암 데이터로 데이터 시각화 부터 gridsearch까지 다양한 ML기법들을 알아봤습니다.
맨 위 링크된 코드와 같이 GRIDSEARCH까지 수행하니 SVM의 분류가 조금 더 정확도가 높아진걸 확인 할 수 있었네요!!
