Jupyter notebook 에서 실행한 코드링크
✍마지막 부분이 에러가 났습니다. 공부를 해서 수정해봐야겠어요.
< 본문으로 들어가 봅시다! >
세계 패션 산업은 3조 달러의 규모로 세계 GDP 2%차지하고 있습니다.
패션 산업은 새로운 컴퓨터 비전과 ML, DL 기술을 받아들이며 극적인 변화를 격고 있는데요.
이번 사례 연구에서는 고객의 인스타그램이나 페이스북 이미지를 살펴보고, 고객이 착용한 가방, 드레스, 바지 등의 패션 카테고리를 분류하는 가상 스타일리스트 어시스턴트 역할입니다.
✨가상 어시스턴트는 업체가 패션 트렌드를 감지하고 예측해 목표한 마케팅 캠페인을 시행하도록 도와주죠 이번 연구에서는 패션 MNIST 데이터를 사용해보겠습니다.
패션MNIST 데이터는 가방, 신발, 드레스의 이미지를 포함하고 있는 데이터 세트입니다.
저는 딥 네트워크에 이들을 10개 클래스로 분류하도록 요청해보겠습니다.\
- 요약
요약하자면 우리가 만들고자 하는 건 이미지를 보고 그 이미지에 정확히 어떤 카테고리가 있는지 알려주는 앱, 즉 모델입니다. 이게 반바지인지 티셔츠인지 모자인지 말입니다. 이러한 정보들은 마케팅 에 유용하게 사용 될 것 같습니다.
제가 구축하려는 것의 아주 대표적인 예시는 바로 Amazon echo look style assistant입니다.
아래 링크로 간단히 확인해 보세요!
Amazon echo look style assistant : Alexa
1.이미지 데이터는 어떻게 표현 되는 걸까?
minst 데이터들은 28*28 픽셀의 흑백 사진으로 구성 되어있습니다.
아주 간단하게 설명드리자면
이와 같은 사진은 28*28의 아주 작은 네모 픽셀로 이루어져 있으며 숫자 255는 하얀색 0은 검은색으로 표현 됩니다.
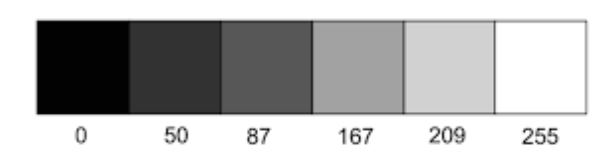
이런식으로 말이죠. 제가 다운받은 csv 파일은 사진들이 각 28*28 = 784개의 데이터들이 0~255로 표현이 되어있습니다! 즉 행 하나가 한 이미지 인것이죠!!
2. 컨벌루션 신경망(CNN)
이번 모델학습에서는 컨볼루션 신경망을 사용하여 학습해봤습니다.
그렇다면 신경망은 무엇인가?
-> 인간은 어떻게 학습할까요? 인공 신경망 설계의 전체 아이디어는 인간 두뇌가 작동하는 방식을 모방하는 것입니다. 인간의 뇌가 학습하는 방식을 수학적으로 표현한 것이라고 합니다...!!
인간은 뉴런 사이의 결합 강도를 적응적으로 변화시키면서 학습하는데, 이것이 바로 우리가 수학적으로 구현하고자 하는 것입니다.
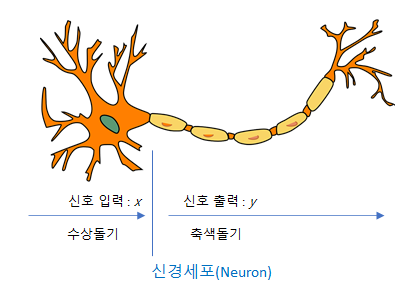
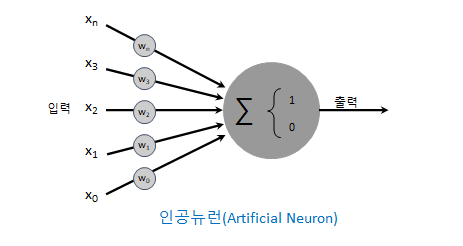
인간의 뉴런을 수학적으로 표현한 것입니다. 이런 뉴런이 수백, 수천개가 생겨서 학습을 한다면???
축하합니다! 미니 두뇌를 만들었어요! 이러한 미니두뇌로 어떤 것이든 학습할 수 있습니다.
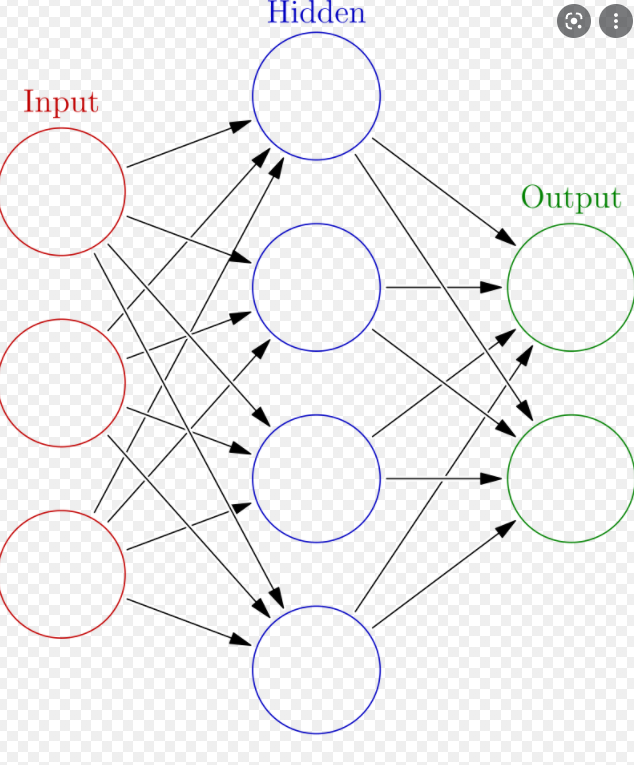
컨볼루션 신경망이란? (CNN)
그렇다면 이제 28*28 픽셀 이미지를 Input으로 넣어 신경망을 학습시켜버리면 되겠네요? 라고 한다면 끔찍한 결과를 초래할 것입니다.
핵심은 일반적인 방식으로 신경망을 처리할 수 없다는 것입니다.
우리가 특성이나 데이터 샘플을 다루는 것과 같은 방식으로 이미지를 처리할 수 없습니다.
이미지를 다룰 때에는 픽셀 간의 공간 의존성을 보존해야 합니다.
이러한 이유로 그전에 다른 과정을 수행해야 합니다.
모든 픽셀을 신경망에 직접 공급하기 전에 컨볼루션이라는 것을 적용해야합니다.
따라서 이것이 컨볼루션 신경망입니다!
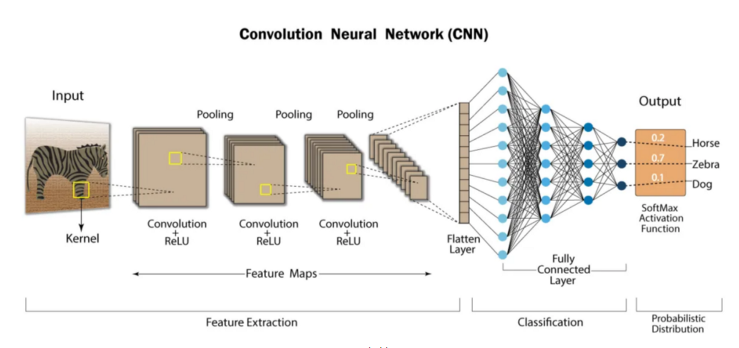
각 계층은 해당 데이터만이 갖는 특징을 학습하기 위해 데이터를 변경하는 계산을 수행합니다. 가장 자주 사용되는 계층으로는 컨벌루션, 활성화/ReLU, 풀링이 있습니다.
컨벌루션은 각 이미지에서 특정 특징을 활성화하는 컨벌루션 필터 집합에 입력 이미지를 통과시킵니다.ReLU(Rectified Linear Unit)는 음수 값을 0에 매핑하고 양수 값을 유지하여 더 빠르고 효과적인 학습을 가능하게 합니다. 이때 활성화된 특징만 다음 계층으로 전달되기 때문에 이 과정을 활성화라 부르기도 합니다. 특징 맵에 비선형을 추가합니다. 이는희소성과 특징의 산포 정도를 강화합니다.풀링은 비선형 다운샘플링(신호처리에서 사용하는 의미는 혼신없는 대역폭축소를 의미한다)을 수행하고 네트워크에서 학습해야 하는 매개 변수 수를 줄여서 출력을 간소화합니다. 한 마디로 해여 차원은 축소시키며 가장 두드러지는 값, 눈에 띄는 값을 즉 특징을 보존한다라고 할 수 있습니다.
이러한 작업이 수십 개 또는 수백 개의 계층에서 반복되어 각 계층이 여러 특징을 검출하는 방법을 학습하게 됩니다.
아래 링크에서 convolution 적용 과정을 확인해 보세요!
컨벌루션 feature detector & reature map 관련
