📌 Decision Tree (결정트리)
-
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것
-
룰 기반의 프로그램에 적용되는 if, else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘으로 이해해 볼 수 있다.
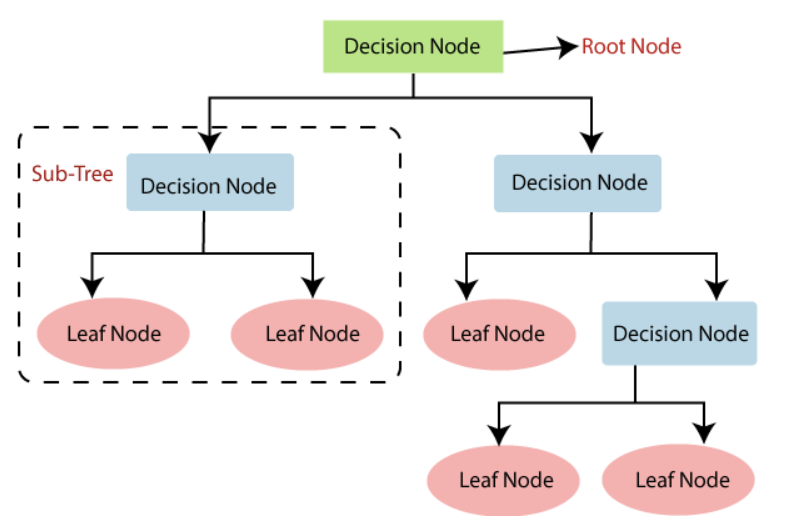
- 규칙 노드(Decision Node): 규칙 조건
- 리프 노드(Leaf Node): 결정된 클래스 값
- 서브 트리(Sub Tree): 새로운 규칙 조건마다 생성
✅ 트리 분할 기준: 균일도
-
트리의 깊이(depth)가 깊어질수록 과적합으로 이어지기 쉽다.
-
따라서 가능한 한 적은 결정 노드로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 한다.
- 최대한 균일도(데이터 세트 내 레이블이 동일한 정도)가 높은 데이터 세트를 구성할 수 있도록 분할하는 것이 중요
(1) 정보 이득
- 엔트로피(주어진 데이터 집합의 혼잡도) 개념 기반
- 계산식: (1 - 엔트로피 지수)
- 정보 이득 지수가 높을수록 균일도가 높음
(2) 지니 계수
- 경제학에서 불평등 지수를 나타낼 때 사용하는 계수
- 0이 가장 평등하고, 1로 갈수록 불평등을 의미
- 지니 계수가 낮을수록 균일도가 높음
정보 이득이 높거나 지니 계수가 낮은 조건을 찾아서 자식 트리 노드에 거쳐 반복적으로 분할한 뒤, 데이터가 모두 특정 분류에 속하게 되면 분할을 멈추고 분류를 결정한다.
✅ 특징
| 장점 | 단점 |
|---|---|
| 쉽고, 직관적 | 과적합으로 알고리즘 성능이 떨어짐 |
| 피처 스케일링, 정규화 등 사전 가공 영향도가 크지 않음 | 트리의 크기를 사전에 제한하는 튜닝 필요 |
| 시각화로 표현 가능 |
✅ DecisionTreeClassifier 파라미터
-
min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수, 과적합 제어 -
min_samples_leaf: 리프 노드가 되기 위한 최소한의 샘플 데이터 수, 과적합 제어 -
max_features: 최적의 분할을 위해 고려할 최대 피처 개수-
int형으로 지정 -> 개수 / float형으로 지정 -> 퍼센트
-
Default: 모든 피처를 사용
-
sqrt 또는 auto: sqrt(전체 피처 개수)
-
log: log2(전체 피처 개수)
-
-
max_depth: 트리의 최대 깊이, 과적합 제어 -
max_leaf_nodes: 리프 노드의 최대 개수
✅ 시각화
export_graphviz()decision_tree: 학습이 완료된 Estimatorout_file: output 파일명class_names: 결정 클래스의 명칭feature_names: 피처의 명칭filled: 클래스별 노드 색상 구분 여부
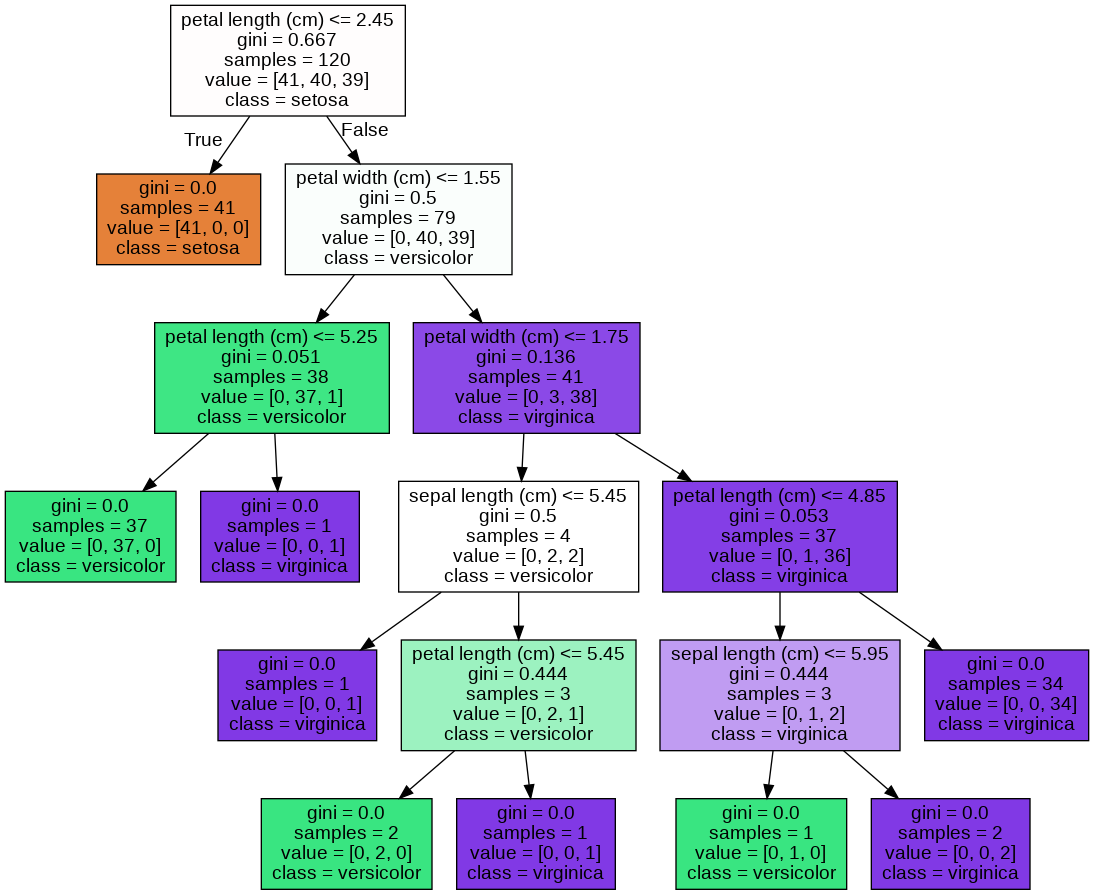
from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import export_graphviz import graphviz import warnings warnings.filterwarnings('ignore') # DecisionTree Classifier 생성 dt_clf = DecisionTreeClassifier(random_state=156) # 붓꽃 데이터를 로딩, 학습/테스트 데이터 세트 분리 iris_data = load_iris() X_train , X_test , y_train , y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11) # DecisionTreeClassifer 학습 dt_clf.fit(X_train, y_train) # 그래프 형태로 시각화할 수 있는 tree.dot 파일 생성 export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, feature_names=iris_data.feature_names, impurity=True, filled=True) # 위에서 생성된 tree.dot 파일을 graphviz를 호출해 시각화 with open("tree.dot") as f: dot_graph = f.read() graphviz.Source(dot_graph)
(1) 자식 노드를 만들기 위한 규칙 조건, 조건이 없을 경우 리프 노드
(2) gini: 지니 계수
(3) samples: 현 규칙에 해당하는 전체 데이터 개수
(4) value: 클래스 값 기반의 데이터 개수
(5) class: 데이터 개수가 가장 많은 클래스 값
- 각 노드의 색깔은 레이블 값을 의미
- 색깔이 짙어질수록 지니 계수가 낮고, 해당 레이블에 속하는 샘플 데이터가 많다는 것을 의미
- 주황색: Setosa(0)
- 초록색: Versicolor(1)
- 보라색: Virginica(2)
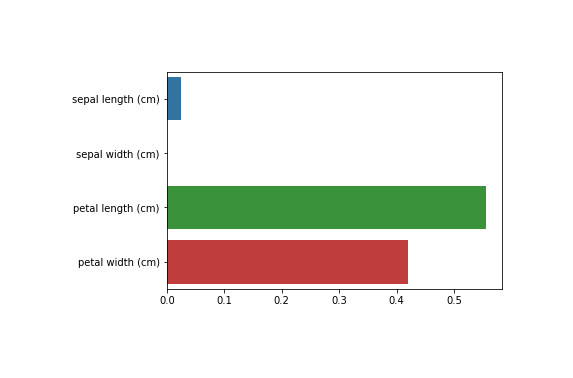
✅ 피처 중요도
-
중요한 몇 개의 피처가 명확한 트리 규칙을 만드는 데 크게 기여하며, 좀 더 간결하고 이상치에 강한 모델을 만들 수 있다.
-
사이킷런은 결정 트리 알고리즘이 학습을 통해 규칙을 정하는 데 있어 피처 중요도를 DecisionTreeClassifier 객체의
feature_importances_속성으로 제공 -
feature_importances_: 피처 순서대로 값을 할당하여 ndarray 형태로 반환- 값이 높을수록 해당 피처의 중요도가 높음
import seaborn as sns import numpy as np %matplotlib inline # feature importance 추출 print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3))) # feature별 importance for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_): print('{0} : {1:.3f}'.format(name, value)) # feature importance 시각화 sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)
✅ 과적합 (Overfitting)
visualize_boundary(): 머신러닝 모델이 클래스 값을 예측하는 결정 기준을 색상과 경계로 나타내 모델이 어떻게 데이터 세트를 예측 분류하는지 이해를 도와준다.
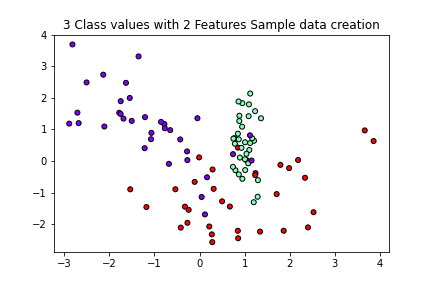
# 1. 분류를 위한 데이터 세트 생성 from sklearn.datasets import make_classification import matplotlib.pyplot as plt %matplotlib inline plt.title("3 Class values with 2 Features Sample data creation") # 2차원 시각화를 위해서 feature는 2개, 결정값 클래스는 3가지 유형의 classification 샘플 데이터 생성 X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2, n_classes=3, n_clusters_per_class=1,random_state=0) # plot 형태로 2개의 feature로 2차원 좌표 시각화, 각 클래스값은 다른 색깔로 표시 plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, cmap='rainbow', edgecolor='k')
# 2. Classifier의 Decision Boundary 시각화 함수 import numpy as np def visualize_boundary(model, X, y): fig,ax = plt.subplots() # 학습 데이터 scatter plot으로 나타내기 ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k', clim=(y.min(), y.max()), zorder=3) ax.axis('tight') ax.axis('off') xlim_start , xlim_end = ax.get_xlim() ylim_start , ylim_end = ax.get_ylim() # 호출 파라미터로 들어온 training 데이터로 model 학습 model.fit(X, y) # meshgrid 형태인 모든 좌표값으로 예측 수행 xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200)) Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # contourf()를 이용하여 class boundary를 visualization 수행. n_classes = len(np.unique(y)) contours = ax.contourf(xx, yy, Z, alpha=0.3, levels=np.arange(n_classes + 1) - 0.5, cmap='rainbow', clim=(y.min(), y.max()), zorder=1)
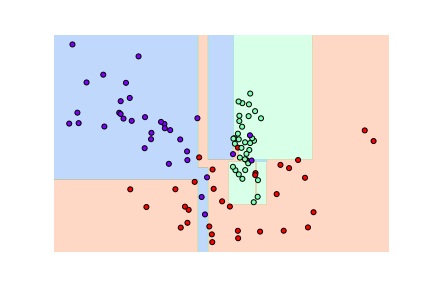
# 3-1. DecisionTreeClassifier - 하이퍼 파라미터 디폴트 from sklearn.tree import DecisionTreeClassifier dt_clf = DecisionTreeClassifier().fit(X_features, y_labels) visualize_boundary(dt_clf, X_features, y_labels)
- 결정 트리의 기본 하이퍼 파라미터 설정은 리프 노드 안에 데이터가 모두 균일하거나 하나만 존재해야 하는 엄격한 분할 기준을 적용한다.
따라서 결정 기준 경계가 많아지고 복잡해진다.
- 복잡한 모델은 학습 데이터 세트의 특성과 약간만 다른 형태의 데이터 세트를 예측하면 예측 정확도가 떨어진다.
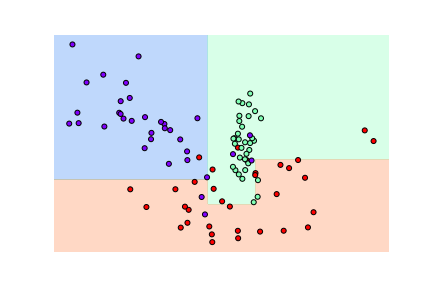
# 3-2. DecisionTreeClassifier - min_samples_leaf=6 dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(X_features, y_labels) visualize_boundary(dt_clf, X_features, y_labels)
- min_samples_leaf=6을 설정해 6개 이상의 데이터는 리프 노드를 생성할 수 있도록 리프 노드 생성 규칙을 완화
- 첫번째 모델보다 좀 더 일반화된 규칙에 따라 분류되었으며, 다양한 테스트 데이터 세트에 대한 예측 성능이 더 뛰어날 가능성이 높다.
[참고]
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html
