오늘은 https://ratsgo.github.io/speechbook/docs/am/cdam 여기에 나온 부분들을 읽고 공부해보고자 한다.
Context-Dependent Acoustic Model
주변 음소 정보까지 모델링에 고려
음소
하나의 소리로 인식되며, 단어의 뜻을 구별해주는 말소리의 최소 단위
자음과 모음처럼 소리의 경계가 나누어지는 분절음운
예) 사과 => 사, 과
1. Motivation
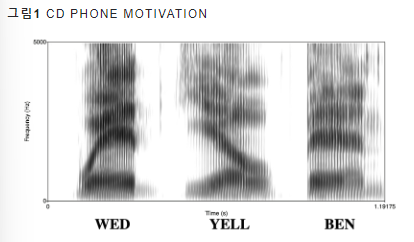
그림1. 모음 "eh"의 스펙트럼
문제 상황
그림 1에서 처럼 같은 모음 "eh" 이지만 앞뒤(context)에 어떤 음소가 오느냐에 따라 그 특징이 확실히 달라짐
이처럼, 동일한 음소라도 그 특징이 크게 다르다면 인식 품질이 낮아지게 됨
그래서 실제로, 기존의 은닉 마코프 모델(Hidden Markov Model) 기반 음성 인식 모델에서는 상태(state)를 음소보다 작은 단위인 subphone으로 모델링하기도 했었음
subphone
그림 1에서는 음소 하나를 3개(0, 1, 2 이런식으로)의 subphone으로 나눔
-> 이는 음소의 음성 패턴과 관계가 있음 (어떤 음소의 경우 동일해도 시간의 변화에 따라 스펙트로 그램이 달라짐, 그래서 하나로 모델링하기 보다 이렇게 여러 개로 나누어서 모델링한다면 음성 인식 성능 향상에 도움이 될 수 밖에 없음)

해결책
앞 뒤 컨텍스트를 반영하자는 "Context Dependent Phone(CD Phone)"를 도입
예1) YELL = y-eh+l
예2) WED = w-eh+d
예3) BEN = b-eh+n
=> 서로 구별이 가능해짐
CD Phone을 모델링할 때 기준 음소를 포함해 그 앞뒤 음소 총 3개를 고려하는 triphone을 일반적으로 사용
CD Phone은 subphone과 대비되는 개념
-> CD Phone 모델링시 음소보다 작은 단위의 subphone을 쓸 수 있지만 그걸 했다고 CD phone이 되는 것은 아님.
=> CD Phone을 모델링한다는 것은 '앞 뒤 컨텍스트를 고려한다'에 초점이 두어져있기 때문
CD Phone과 대척되는 개념으로는 Context-Independent Phone(혹은 monophone(단일 음소))가 있음
-> 이는, 음소 모델링 시 앞뒤 컨텍스트를 고려하지 않고 독립적으로 본다는 것을 뜻함
2. Subphone Clustering
문제 상황
하지만 이런 식으로 CD Phone을 단정하게 되면 고려해야 하는 경우의 수가 폭증한다는 문제가 있음
만일 50개의 음소가 있는 언어이고, CD phone을 총 3개(triphone)으로 모델링한다면, 50^3=125000개가 필요함.
50^3: 기준 음소, 앞 뒤 음소 각각을 고려하므로, 가능한 조합의 수는 음소의 수를 세 번 곱한 값이 됨
해결책
이런 상황에서 비슷한 특징을 가지는 CD Phone을 하나로 합쳐 고려하는 Subphone Clustering이 제시됨
이는 비슷한 특징을 가지면 동일한 상태로 간주해 계산량을 줄이는 기법임
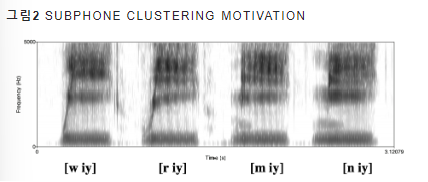
(해당 그림 2에서 iy와 같이 비슷한 특징을 가지는 경우 하나로 합쳐짐)
=> 좀 더 자세히 Subphone Clustering이 필요한 이유를 다시 살펴보자!!!!!
기존의 음성 인식 시스템에서는 방출 확률 함수를 가우시안 믹스처 모델로 모델링함
이 때 상태 개수 만큼의 가우시안 믹스처 모델이 필요함
하지만 CD Phone을 단정하면, 학습해야 하는 가우시안 믹스처 모델이 기하급수적으로 많아지게 됨
이럴 때 Subphone Clustering을 통해 그림 3과 같이, 비슷한 특징을 가지는 CD Phone을 묶어서 가우시안 믹스처 모델도 공유할 수 있는 장점이 있음
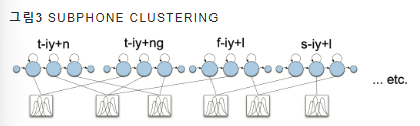
- 주어진 상태에서 관측치(특징 벡터)가 발생할 확률
- 은닉된 상태로부터 관측치가 튀어나올 확률
클러스터링 절차 살펴보기
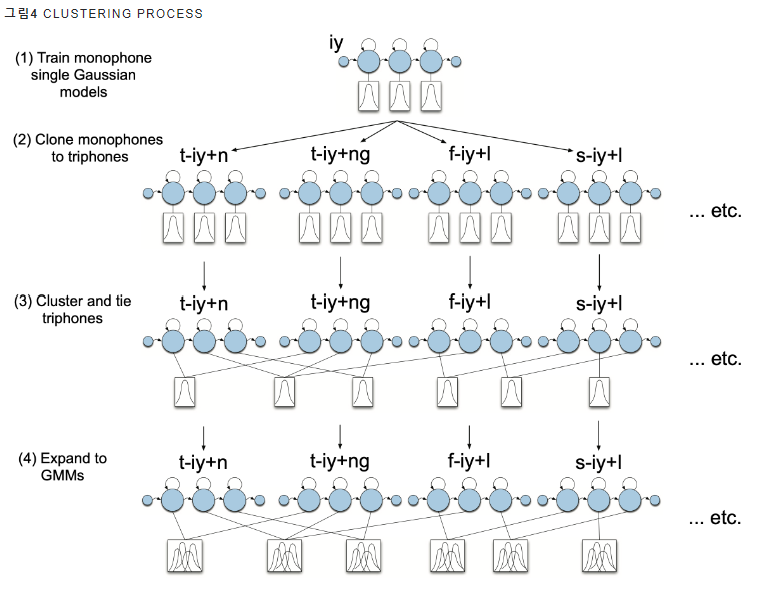
(그림 4. iy를 CD Phone으로 모델링할 때 클러스터링 절차를 도식적으로 나타낸 것)
(1) iy를 Context-Independent Phone으로 보고 은닉마코프모델(Hidden Markov Models, HMMs) + 가우시안 믹스처 모델을 학습함
(2) iy를 CD Phone으로 모델링한 은닉마코프모델 + 가우시안 믹스처 모델을 구축함 (실제 그림을 보면 triphone으로 되어져있음),
또한 iy와 관련된 모든 CD Phone에 대응하는 가우시안 믹스처 모델의 초기값으로 (1)에서 학습한 가우시안 믹스처 모델의 파라미터(평균, 공분산)를 줌
(3) 비슷한 특징을 가지는 CD Phone끼리 클러스터링을 진행하고, 결과에 따라 가우시안 믹스처 모델 파라미터를 공유할지/말지 결정함
(4) (3) 결과를 바탕으로 은닉마코프 + 가우시안 믹스처 모델을 다시 학습함
은닉마코프 + 가우시안 믹스처 모델
은닉 마코프 모델은 숨겨진 상태 간의 전이를 모델링하고, 가우시안 믹스처 모델은 관찰된 데이터의 확률 분포를 모델링함.
음성 인식에서는 보통 음소나 발음을 은닉 마코프 모델로 모델링하고, 각 음소나 발음에 대한 특징 벡터의 분포를 가우시안 믹스처 모델로 모델링함.
3. Decision Tree
의사결정 나무: Subphone Clustering에 사용되는 군집화 알고리즘
음성 피처 (MFCC)가 주어졌을 때 은닉마코프모델 + 가우시안 믹스처 모델의 우도(likelihood)가 높아지면 split 하도록 학습함
높은 우도: 모델이 관측된 데이터를 더 잘 설명한다
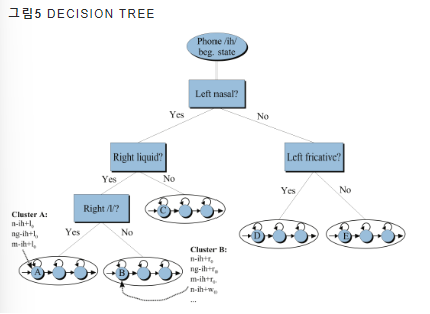
(학습된 의사결정나무 모델의 예시를 나타낸 그림)

이때, 의사결정나무 분기 조건으로 그림 6처럼 음운론/음성학 전문가들이 추출해 둔 음성 특징을 기준으로 함


공유 감사합니다. 다시 읽어보니 궁금한 건데 비슷한 특징을 갖는 CD Phone 은 어떻게 계산하나요?