- 다른 참고하면 좋을 관련글:
- Neural Acoustic Model과 관련된 2015년도 논문 : https://arxiv.org/pdf/1508.01211.pdf
Abstract
1. Listen, Attend and Spell (LAS)의 특징
-
Listen, Attend and Spell (LAS): transcribe speech utterances 를 charcaters로 학습하는 neural network
-
기존의 DNN-HMM models과 달리, speech recognizer의 모든 구성요소를 jointly하게 학습
-
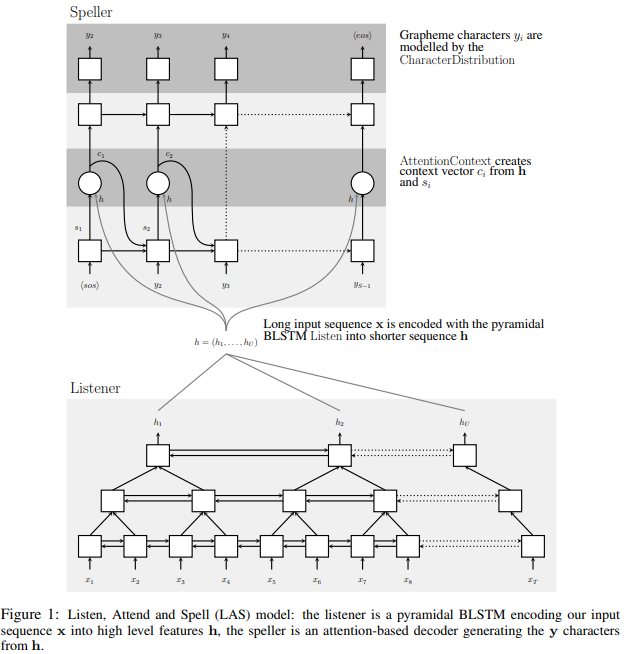
두 구성요소: listener & speaker
- listner: pyramidal recurrent network encoder로서 filter bank spectra를 input으로 받아들임
- speller: attention-based recurrent network decoder로서 characters를 output으로서 emit 함
2. 실험 결과
- 네트워크는 characters 사이에 어떠한 independence assumptions도 만들지 않고 character sequence를 생성함 -> 이는 이전의 end-to-end CTC model에 대비 LAS의 엄청난 향상임
- Google voice search task의 일부에서 LAS는 14.1%의 WER 성취 -> dictionary/언어모델 없이도
- 언어모델있을 때는 10.3 % 성취 -> top 32 beams에 대해서
- state-of-the-art CLDNN-HMM model은 WER 8% 성취
CTC? Connectionist Temporal Classification (CTC) ([참고])(https://ratsgo.github.io/speechbook/docs/neuralam/ctc)
입력 음성 프레임 시퀀스와 타겟 단어/음소 시퀀스 간에 명시적인 얼라인먼트(alignment) 정보 없이도 음성 인식 모델을 학습할 수 있는 기법
1 Introduction
1.1 기존 Method
-
speech recognition에서 Deep Neural Networks (DNNs)이 성능 향상 보임
-
1] 음향 모델 (acoustic modeling)을 위해 hybrid DNN-HMM speech recognition systems에서 사용되었으며,
-
2] pronunciation models(발음 모델, map words to phoneme sequences)에서 엄청난 gain을 보임
-
3] 언어모델 (language model)에서는 recurrent models이 n-best lists를 재점수해서 speech recognition 정확도를 올린다고 함
-
재점수해서 정확도를 올린다??
단어 시퀀스의 출현 확률을 부여하는 모델. 기존 시스템에서는 통계 기반의 n-gram 모델이 이 역할을 수행. ?? 이런 뜻인건가??? -> argmax해서 가장 높은 값을 beam search의 값으로 선정함 ! (언어모델에 도움을 받아 다음에 뭐 나올지 시퀀스 상으로 도움 받는 방법)
-
전통적으로 이 구성요소 (acoustic, pronunciation language models)들은 각자 다른 목적으로 훈련되었음 (각각 따로 학습되니까, 훈련 때 alignment가 disjoint되는 문제가 생김)
-
이 분야의 최근 연구들은 end-to-end로 훈련되는 모델들을 디자인에서 (speech -> transcripts) 생기는 disjoint training issue를 바로잡으려고 했음
-
최신 연구들이 제안한 해결책의 두 가지 주요 구성 요소는 (i) Connectionist Temporal Classification (CTC) , (ii) sequence to sequence models with attention로 둘 다 한계점이 있었음
- (i) CTC는 label output이 서로서로 conditionally independent 임을 가정함 (출력되는 레이블이 각각 조건부 독립임을 가정해서 -> 성능 이슈가 있음)
- (ii) sequence to sequence approach는 speech recognition을 위해 phoneme sequences에만 적용되었고(음성에서 음소로 end to end 로 적용하지는 않았음), end-to-end에는 훈련 X
-> 이런식으로 기존에 한계 있던 두 방법을 둘다 보완+결합해보자!!
1.2 Listen, Attend and Spell (LAS)
- audio sequence signal을 word sequence로 transcribe하는 방법을 배움
- 이전 방법들과 달리, LAS는 label sequence에서 independence assumption을 하지 않으며 HMMs에 의존하지 않음
- LAS는 sequence to sequence learning framework with attention 에 기초를 둠
- encoder recurrent neural network (RNN)으로 구성되어져 있는데 ->이걸 listner라 명명하고, decoder RNN -> speller로 명명
- (i) listener는 pyramidal RNN로서 low level speech signal을 higher level feature로 변환
- (ii) speller는 high level features를 output utterance로 변환 (확률분포를 정의하면서, 어텐션메커니즘을 사용해서)
1.3 본 논문 key
- pyramidal RNN model 을 listner로 써서 -> 어텐션 모델이 관련된 정보를 빼내야 하는 time step의 수를 줄인다
- Rare and out-of-vocabulary (OOV) words는 자동으로 다루어지는데 -> 이는 모델이 character sequence를 한 번에 one character로 output하기 때문
OOV가 자동으로 모델에서 다루어지는 이유??? 구체적인 설명 -> 한번에 one character로 반환한다는게 무슨 뜻인지 (한번에 one charcater로 변환하는데 왜 아래 triple a에서는 Beam search로 여러 개의 결과를 반환하는 건지??) => 알파벳을 개별로 추출한다 (이전 연구와 달리 사전같은 것 안썼다)
“triple a” 는 t, r, 이런싟으로 하나씩 뽑기?
- modeling characters as outputs의 또 다른 이점은 -> network가 multiple spelling variants를 자연스럽게 생성하는 것이 가능하다는 것임
- 예) “triple a” 를 모델은 “triple a” , “aaa” 모두 생성함
- CTC 같은 모델은 이런 다양한 transcripts를 같은 발음으로 생성하는데 어려움을 겪음 -> frames 간의 conditional independence 때문에 (결과물에 조건부 독립이 있으면 다양하게 반환하는 것을 어려워한다)
modeling characters as outputs가 무슨 뜻인지 -> 결과물로 "character"를 반환한다
실험 결과
1. attention mechanism 없이 -> 모델은 training data를 overfit 함
2. 인코더 내의 pyramid structure 없이 -> 모델은 너무 천천히 수렴함
3. speller의 오버피팅을 줄이고자 -> training 동안 sampling trick 사용
논문 리뷰 발표 후기
Intro
Listen Attedn Spell 순서대로 작동 !!
언어모델들을 통해 한 번더 변환하는 것이 기존 모델들의 형태이었더라면, LAS는 세 가지를 한 번에 합쳐서 end-to-end를 하는 모델임 (최초)
CTC + sequnece~~ (언어모델) => 융합해서 쓰자,
CTC: 예시로 ASR 쪽으로 생각해보면, 음성 주파수랑 스크립트 길이 다를때 쓰이는 모델
음성 신호를 한 번에 한 단어씩 변환해서 -> 시퀀스를 만든다
Model
x가 음성, y가 텍스트
Listen & AttendANdsSPeel 함수를 각자 만들어서 사용
- Listener
bi-lstm 사용
음성 시퀀스가 차례대로 input이 되고, 앞뒤 상관관계를 확인하고자 bi-lstm 사용함
피라미드로 쌓는건 -> 시간 단축 + 에러률 줄이기
실험
SOTA보다 성능이 좀 안좋지만, 다 합쳐서 우수하다는 식으로 논문을 기술!! 신기하네~~
어텐션으로 POS하는 과정은 필요 없다 -> 어텐션 벡터 값을 2차 평면으로 나타낸 이미지, 어텐션 벡터가 시퀀스랑 유사한 애들이 출력이 되더라, contents 만 사용해도 위치 정보 알아서 파악해서 출력하기 때문에 pos는 필요가 없는 것 같다
Beam width
Oracle ? -> 빔서치 중에서 확률이 높은 것을 고를 때, "빔서치에 최적인 값을 골랐을 때" = "oracle"
발화의 길이에 따른 error rate
발화가 길어질 수록 deletion 현상이 많이 나타난다 -> deletion 현상???이 뭔지 (말이 중간에 끊기거나 / 아니면 뒤에 안나오거나), Insetion은 NLP의 hallucination 같은 느낌 !!!
단어 횟수와 recall간의 관계
많이 쓴 단어는 recall이 상대적으로 더 높았다
한 번 나온 단어 -> recall 100% (단어가 특징적이 크면, recall이 좋게나오더라)
