ASR Study
1.[ASR Study] # 1 Intro
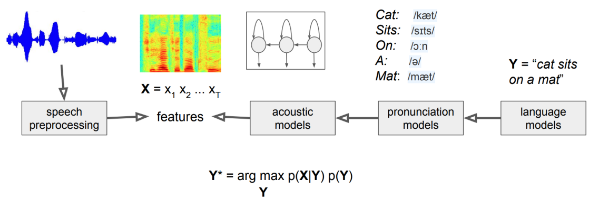
오늘은 https://ratsgo.github.io/speechbook/ 에 나와있는 내용을 공부하고 내가 이해한 대로, 정리하고자 한다종류음향 모델(Acoustic Model) => 기존에는 히든 마코프 모델(Hidden Markov Model)과 가우시안
2.[ASR Study] # 2-1 Phonetics

오늘도 이어서 https://ratsgo.github.io/speechbook/docs/phonetics/acoustic 를 참고하여 공부한다 !!사람 말소리에 대한 이해 !!언어학 => 말 소리 체계적인 설명 위해음성학 (Phonetics)말의 실체에 물리적
3.[ASR Study] # 2-2 Korean Phonology
오늘도 이어서 https://ratsgo.github.io/speechbook/docs/phonetics/phonology를 공부해본다 !!음운론: 사람 머리에 있는 말소리에 대한 지식을 체계적 기술/설명하는 분야개별 언어에서 쓰이는 말의 특질, 지식 다룸심리
4.[ASR Study] # 2-3 Recognition by Human
오늘도 이어서 https://ratsgo.github.io/speechbook/docs/phonetics/humans를 정리해본다정의: 사람은 음성을 단어 단위로 인식= 말소리를 단어 단위로 인식frequency: 사람은 빈도 높은 단어를 빠르게 인식paral
5.[ASR Study] # 3 Feature Extraction
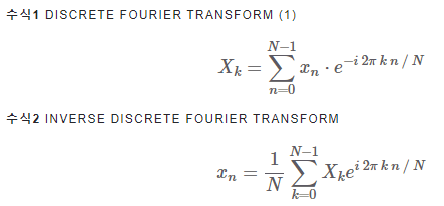
Mel-Frequency Cepstral Coefficients(MFCC)를 추출하는 방법MFCC - 음성 인식과 관련해 불필요한 정보는 버리고 중요한 특질만 남긴 것음성 도메인의 지식과 공식에 기반한 추출 방법음성 입력이 주어지면 피처가 고정된(deterministi
6.[ASR Study] # Paper. WAV2VEC: UNSUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION
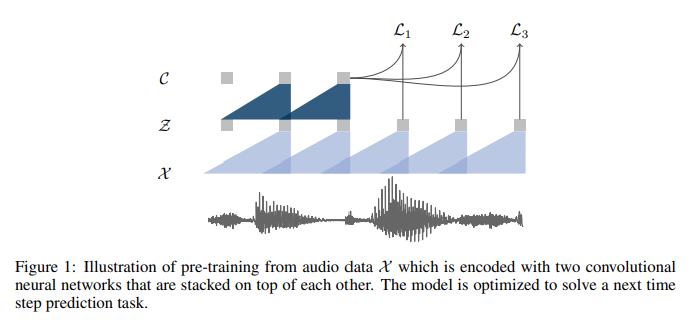
발표는 아니어서 논문 전체를 읽지는 않지만, 그래두 공부해보기 !!!!!!! 논문 정리하기 !!!!Neural Acoustic feature extraction 관련 논문이다raw audio의 representation을 학습하여 -> unsupervised pre-t
7.[ASR Study] # Paper. SPEAKER RECOGNITION FROM RAW WAVEFORM WITH SINCNET
IEEE SLT 2018 https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8639585
8.[ASR Study] # Basic Content. 음향 모델(Acoustic Model)
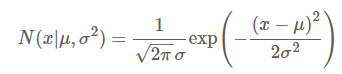
https://ratsgo.github.io/speechbook/docs/am 이 홈페이지를 참고해서 공부 !!한 내용들을 간단하게 적어보려고 한다음향 모델(Acoustic Model)상태, 관측치를 모두 아는 경우 -> 은닉마코프모델을 학습하기가 상대적으로
9.[ASR Study] # Paper. PASE: Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
IEEE SLT 2018에 게재된 SincNet 논문(https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8639585)에서 1D convolution의 연산 원리https://www.popit.kr/
10.[ASR Study] # Paper. Listen, Attend and Spell
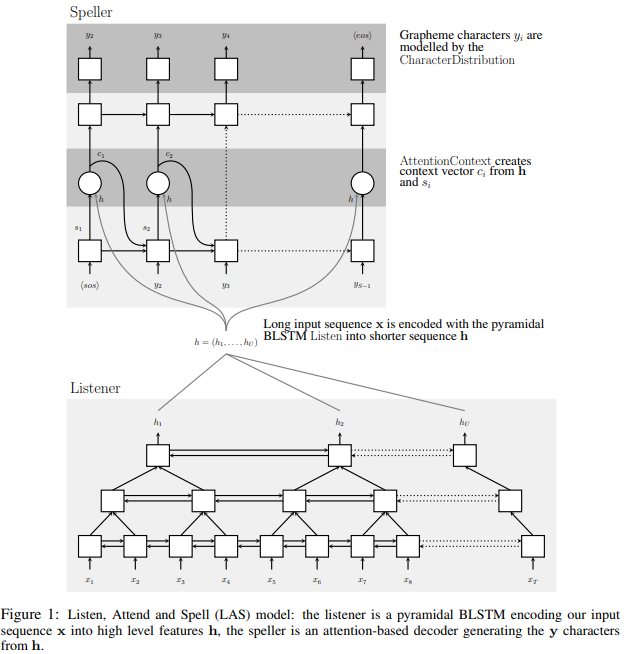
다른 참고하면 좋을 관련글:https://ratsgo.github.io/speechbook/docs/neuralam/lashttps://hyungjung-lee.github.io/ai-ml/listen-attend-and-spell/Neural Aco
11.[ASR Study] # Basic Content. 음향 모델(Acoustic Model) part2
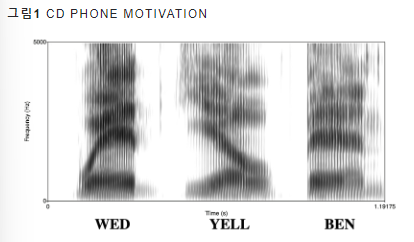
오늘은 https://ratsgo.github.io/speechbook/docs/am/cdam 여기에 나온 부분들을 읽고 공부해보고자 한다.Context-Dependent Acoustic Model: 주변 음소 정보까지 모델링에 고려
12.[ASR Study] # Paper. Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin
Paper: https://proceedings.mlr.press/v48/amodei16.pdfEnglish or Mandarin Chinese 이해에 end-to-end 딥러닝 방법 쓰는 것의 효율성을 입증함그 방법이 뉴럴네트워크로 hand-engineere
13.[ASR Study] # Paper: Speech Model Pre-training for End-to-End Spoken Language Understanding
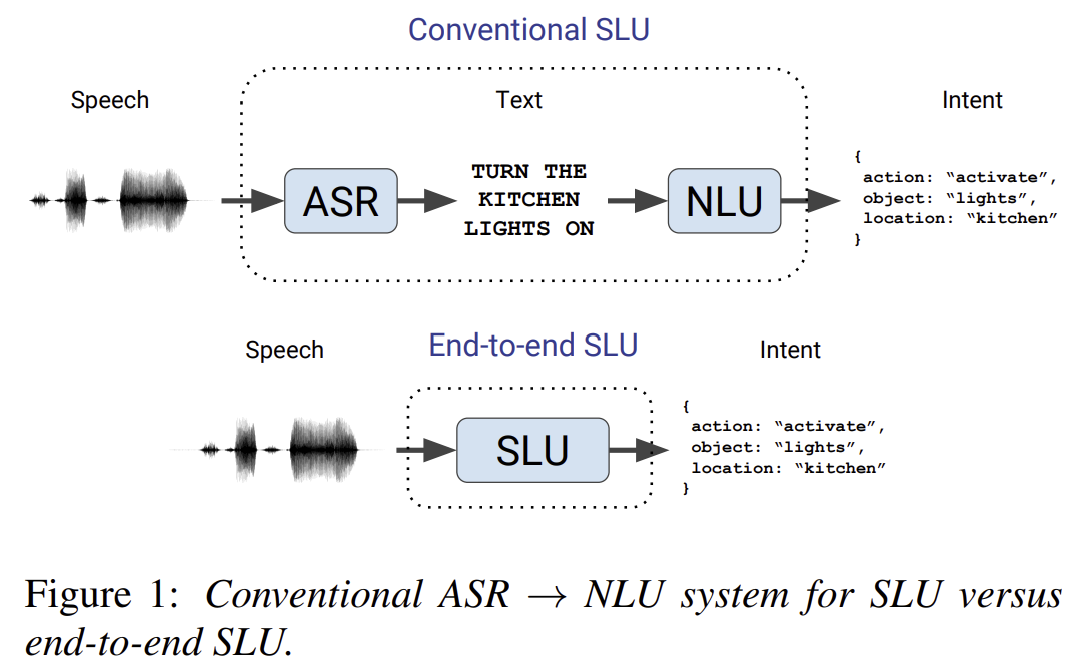
https://arxiv.org/pdf/1904.03670.pdf기존의 spoken language understanding (SLU) 시스템은 speech를 map해서 text로 만들고 text를 intent로 만들지만 end-to-end SLU 시스템은 s
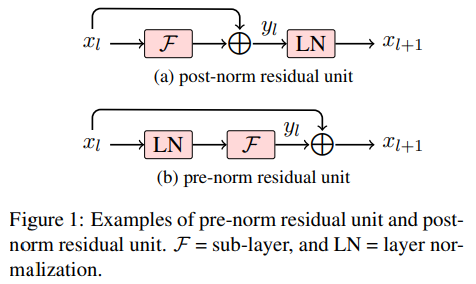
14.[ASR Study] # Paper: Conformer: Convolution-augmented transformer for speech recognition
Interspeech 2020에 나온 논문 (http://www.interspeech2020.org/uploadfile/pdf/Thu-3-10-9.pdf)이다. 논문에 나와있지 않은데 이해가 어려운 내용은 아래 "블로그 포스팅"을 참고했다. https://rimiye