오늘은 https://ratsgo.github.io/speechbook/ 에 나와있는 내용을 공부하고 내가 이해한 대로, 정리하고자 한다 (모든 이미지와 글들은 해당 블로그에서 가져왔다)
Introduction
Automatic Speech Recognition
- 종류
- 음향 모델(Acoustic Model) => 기존에는 히든 마코프 모델(Hidden Markov Model)과 가우시안 믹스처 모델(Gaussian Mixture Model)
- 언어 모델(Language Model) => 통계 기반 n-gram 모델
Problem Setting
- ASR: 음성 신호를 단어, 음소 시퀀스로 변환하는 시스템
- 사람 말 => 텍스트 (Speech to Text)
- 입력 음성 신호에 대해 -> 가장 그럴 듯한 음소/단어 시퀀스 추정
- 목표: P(Y|X)를 최대화하는 음소/단어 시퀀스 Y 추론
- Challenge
- 같은 음소/단어 -> 사람마다 발음 양상 다름 (e.g., 화자의 성별)
- 음성 신호의 변이형을 모두 커버하는 모델 만들기 어려움
- 베이즈 정리
- P(X) => evidence (Y의 모든 경우의 수에 해당하는 X의 발생 확률 -> 추정 어려움)
- 추론 (inference) 때, 입력 신호 X는 Y에 관계 없이 고정
- 추론 때, P(X)를 계산에서 생략 가능
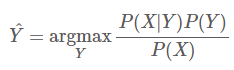
- 추론 때, P(X)를 계산에서 생략 가능
- 만약, Y의 후보 시퀀스가 Y1, Y2 뿐이라면, 예측결과(Y1)을 만들 때 분자만 고려하면 됨
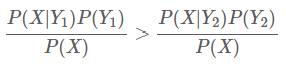
- 음성 인식 모델은 => 두가지로 구성
- P(X|Y) 음향 모델, ‘음소/단어 시퀀스’와 ‘입력 음성 신호’가 어느 정도 관계를 맺고 있는지 추출
- p(Y) 언어모델, 해당 음소/단어 시퀀스가 얼마나 자연스러운지 확률값 형태로 나타냄
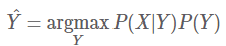
Architecture
자동 음성 인식 모델 전체 아키텍처
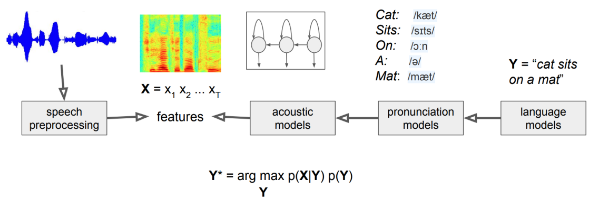
-
음향 모델 => P(X|Y) 반환
- 음소(단어) 시퀀스 Y가 주어지면, 입력 음성 신호 시퀀스 X가 나타날 확률 부여
- = 음성신호와 음소와의 관계를 표현
- 예) 히든 마코프 모델, 가우시안 믹스처 모델의 조합
-
언어 모델 => P(Y) 반환
- 음소 시퀀스에 대한 확률 분포
- = 음소 시퀀스 Y가 얼마나 그럴듯한지에 대한 정보인 P(Y)를 반환
- 예) 통계기반 n-gram 모델
-
딥러닝의 등장으로 -> 해당 기법들이 딥러닝 기반으로 대체 중
- 예) 음향 특징 추출, 음향 모델, 언어 모델 등
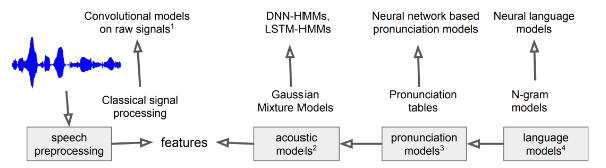
- 예) 음향 특징 추출, 음향 모델, 언어 모델 등
최근 동향
- 딥러닝 기반에서 더 나아가, P(Y|X)를 바로 추정하는 엔드트엔드 자동음성인식모델 제안 중
- => 여기서 P(Y|X)는 자동음성인식 모델의 목표로, 얘를 바로 추정하는 모델을 구축하는 것이 가장 이상적임 (옛날에는 그게 안되어서 베이지안을 썼는데, 이제는 엔드투엔드로 한번에 한다는 느낌인것같다)
Acoustic Features
음향 특징 추출 기법
-
MFCC
-
딥러닝 기반 (e.g., SincNet )
-
MFCCs(Mel-Frequency Cepstral Coefficients)
- 기존의 자동 음성 인식 모델의 주요 구성요소인 'HMM + GMM'이 사용하는 음향 특징 (Acoustic Feture)
- 히든 마코프 모델(Hidden Markov Model, HMM) / 가우시안 믹스처 모델(Gaussian Mixture Model, GMM)
- => 사람이 잘 인식하는 말소리 특성은 부각하되, 아닌 부분은 생략/영향력 감소시킨 "피쳐"
- 사전에 정의한 수식에 따라 피처가 만들어짐
- 기존의 자동 음성 인식 모델의 주요 구성요소인 'HMM + GMM'이 사용하는 음향 특징 (Acoustic Feture)
MFCC 추출과정
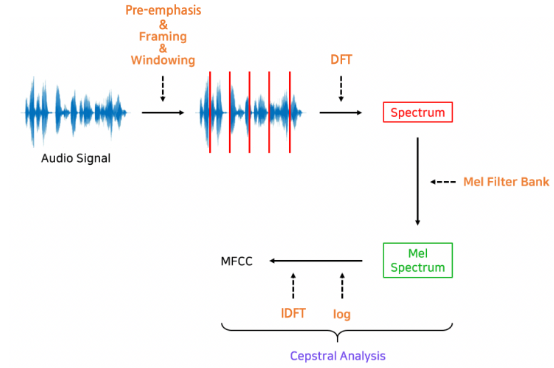
- 최근에는 음향 특징 추출도, 딥러닝 기반으로 변화하는 중
- 예) Wav2Vec, SincNet 등
딥러닝 기반, 음향 특징 추출 예시) SincNet
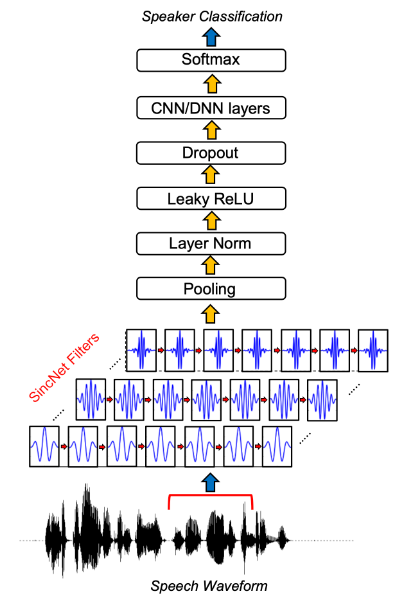
- 입력 음성 신호에 여러 싱크 함수를 통과해, 문제 해결 도움되는 주파수는 부각, 나머지는 버림
- 학습 대상
- 주로 각 싱크 함수가 관장하는 주파수 영역대
- 규칙에 기반한 피쳐인 MFCC는 과정이 "확률적"인데,
- 딥러닝 기반의 음향 특징 추출 기법들은 "결정적"임
